TIL - 250511
대시보드
[대시보드 구축 프로세스]
- 대시보드 뷰어 및 목적 선정
- 누가 보는 대시보드일까요?
- 문제 정의
- 어떤 목적으로 쓰는 대시보드일까요?
- 필요한 데이터 선정 및 데이터 마트 구축
실무- 어떤 데이터가 필요할까요? (매출 데이터, 고객 데이터 등)
- 지표 선정
- 어떤 지표들을 선정해야할까요?
- 스케치
- 어떻게 대시보드 레이아웃을 구성할까요?
- 어떤 컬러로 강조를 해야할까요?
- 시각화
- 어떤 그래프를 활용해야할까요?
- 대시보드 완성!
- 대시보드에서 이끌어내는 액션
- 대시보드에서 어떤 의사결정과 액션을 수립할 수 있을까요?
- 완성된 대시보드 게시 또는 대시보드팀 뷰어 권한 부여
실무
메트릭 하이라키
비즈니스와 프로덕트를 연결하는 지표의 위계 질서 구조
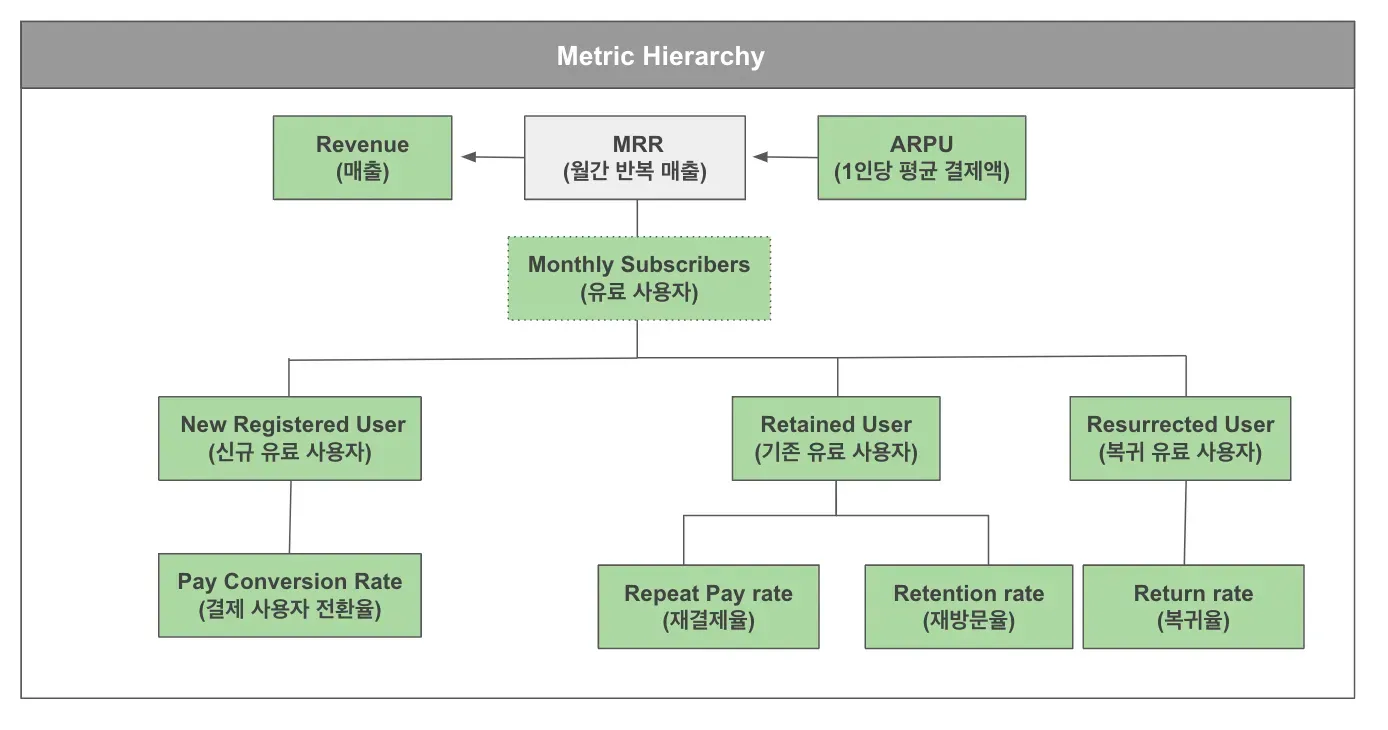
지표의 중요도를 위계질서로 나타내주는 하이라키 서비스
바둑판식 기능
컨테이너와 뷰가 서로 겹치지 않으며, 전체 대시보드 크기에 따라 크기가 자동 조정
부동기능
부동 기능을 선택하면 다른 뷰(컨테이너)와 겹치기 가능
피그마와 부동기능

대시보드 구성
대시보드 계층 구조화
상단과 하단으로 크게 섹션을 나누어 구성.
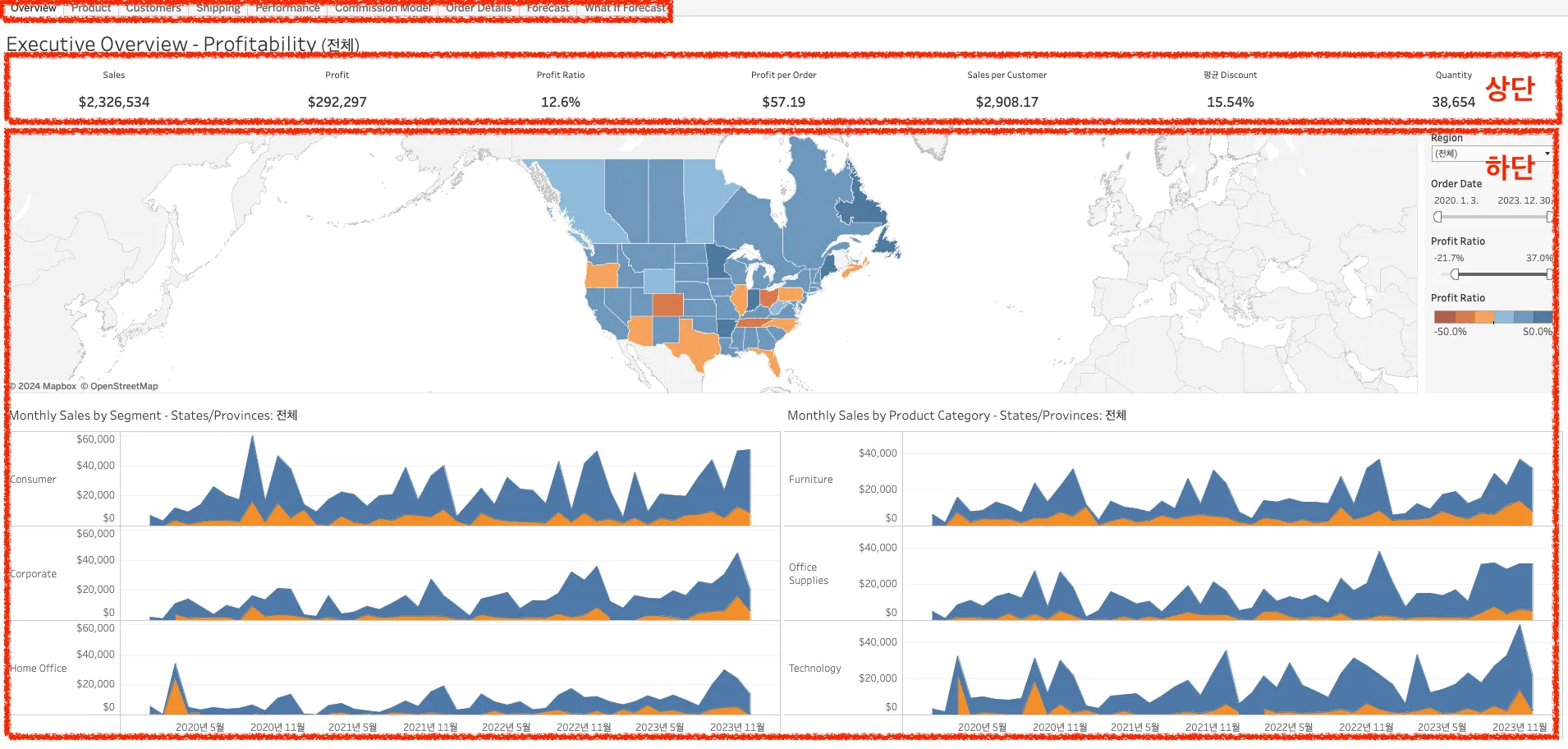
상단에는 주요 지표를 배치
- Z 패턴
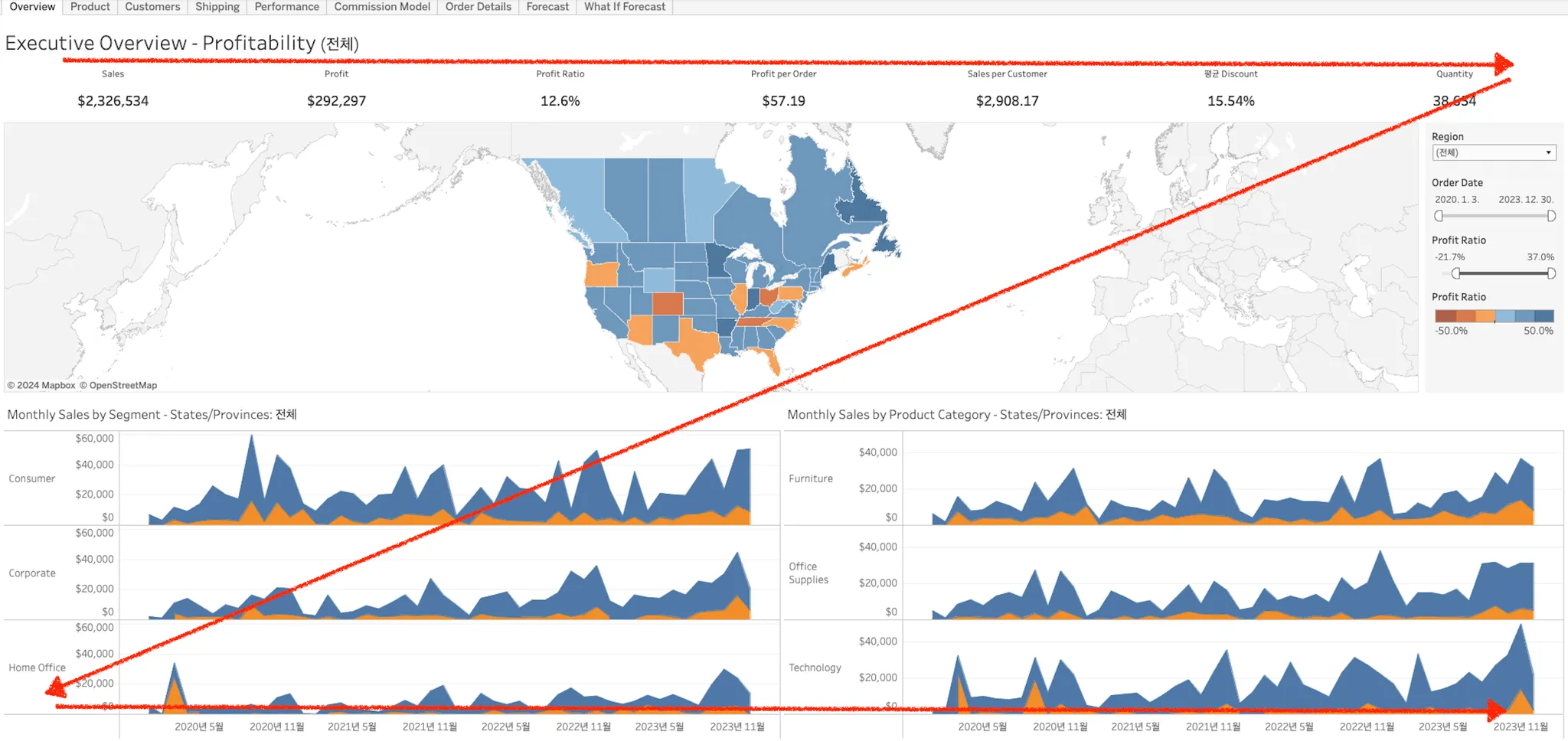
일반적인 대시보드 디자인 레이아웃은 Z패턴에 해당
대시보드 한 페이지를 볼 때 대시보드 사용자의 눈 초점이 Z 모양을 순서대로 이동하는 패턴을 의미.
📍 왼쪽 상단: 가장 중요한 지표와 그래프
📍 오른쪽 상단: 두번째로 중요한 정보
📍 왼쪽 하단: 세번째로 중요한 정보
📍그외 세부적인 정보: 오른쪽 하단에 배치
전주의적 속성
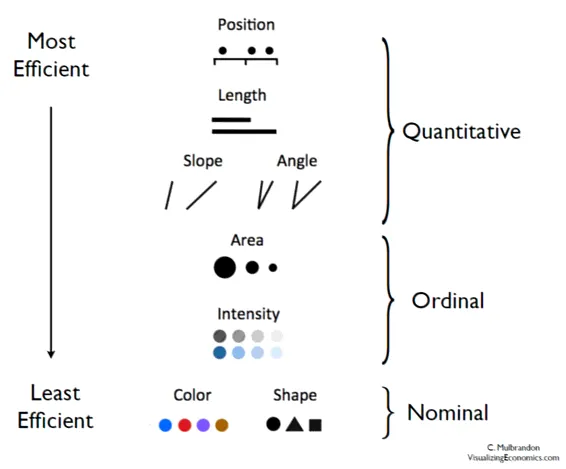
ADSP
3단원
1. R기초와 데이터마트
결측값과 이상값 검색
- EDA(탐색적 자료 분석)의 4가지 주제
저잔재현
저항성의 강조: 자료변동에 민감하지 않다
잔차계산: 값들이 주 경향으로부터 얼마나 벗어나 있는지 확인
자료변수의 재표현: 원래 변수를 적당한 척도로 변환
그래프를 통한 현시성: 시각화를 토앟여 효율적으로 파악
2. 통계분석
통계학개론
- 확률적 표본 추출 방법
- 계통추출법: 번호 부여하여 일정 간격으로 추출
- 집락 추출법(군집 추출법): 여러 군집으로 나눈 뒤 선택, 랜덤추출.
군집내 이질적, 군집간 동질적(apt) - 층화 추출법 (학년)
군집 내 동질적, 군집간 이질적. 같은비율로 추출시 비례층화 추출법
기초통계량
- 관계측면
- 공분산: 두 확률변수의 상관정도( 음의 무한 ~ 무한)
최소 최대값이 없어 강약판단 x - 상관계수: 상관정도를 -1 ~ 1 값으로 표현
- 공분산과 독립성의 관계: 두 변수가 독립 -> 공분산 0
but 공분산이 0이라고 두 변수가 독립인 것은 아니다.
첨도와 왜도
- 왜도: 자료 분포의 비대칭 정도(0이면 대칭)
평균값은 꼬리를 따라간다
왜도 < 0 : 최빈값 > 중앙값 > 평균값
왜도 > 0 : 최빈값 < 중앙값 < 평균값
기초 확률 이론
- 조건부확률: 특정 사건 B가 발생했을 때 A가 발생할 확률
백신을 맞았을 때 (b) 감기에 걸릴 확률 (a) - 독립사건: A,B가 서로 영향을 주지 않는 사건
- 배반사건: 사건 A,B가 동시에 일어나지 않는 사건
- 베이즈 정리: 두 확률변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리
확률분포
확률 변수의 개별 값들이 가지는 확률값의 분포
-
이산 확률분포
값을 셀 수 있는 분포, 확률질량함수
베포항항하
이산균등분포, 베르노이분포(결과 두개중 하나), 이항분포(n번중 k번), 기하분포(처음성공), 음이항분포(베르누이 r번 반복), 초기하분포(원하는 결과 k번), 다항분포, 포아송분포(단위시간 내 발생횟수) -
연속확률분포
값을 셀 수 없는, 확률밀도함수
- 정규분포
- t분포: 정규분포와 유사하지만 꼬리부분이 더 두껍고 긴 분포 (표본이 30개보다 작은 집단, 평균검정)
- 카이제곱 분포: 독립적인 정규분포를 따르는 변수들의 제곱합, 두 집단의 동질성검정, 단일집단의 모분산 검정
- f분포: 두 개의 서로 다른 카이제곱 분포의 비율, 두 집단의 분산 동질성 검정
- 점추정
- 추정량의 조건: 불효일충
불편성(편향이 0), 효율성(분산이 작은것), 일치성(크기가 크면 추정량 모수에 가까움), 충족성
- 가설검정
유의확률(p-value): 귀무가설을 지지하는 정도를 나타내는 확률
1종오류: 귀무가설이 실제로 사실인데 오류라고 판정하는 경우
대립가설(alternative hypothesis)
Is not equal => 같지 않다, 양측검정했다는 말.
단측은 크다/작다로 나옴
- 비모수검정
부호검정, 순위합검정, 만-휘트니 u검정, 크러스칼-윌리스 검정, 프리먼드검정, 카이제곱 검정
기초 통계분석
- 회귀분석
-
회귀계수 추정방법
최소제곱법(최소자승법): 잔차의 제곱합(SSE)이 최소가 되는 회귀계수와 절편을 구하는 방법 -
회귀모형 평가
R-square: 총 변동 중에서 회귀모형에 의하여 설명되는 변동이 차지하는 비율(0~1)
1이 가장 좋은 모델인 것.
- SST, SSE, SSR
- SST: 전체의 변동
- SSE: 모형에 의해 설명 x 변동, 잔차
회귀선과 관측값의 차이(RSS) - SSR: 모형에 의해 설명되는 변동(평균으로부터 회귀선의 차이, ESS)
- R^2 = SSR/SST = 1 - SSE/SST
- 선형회귀분석의 가정 선분정독
선형성, 등분산성(잔차의 분산 고르게 분포), 정상성(정규성), 독립성
- 회귀분석 종류
- 릿지회귀(L2규제): 유클리디안 거리
- 라쏘회귀(L1규제): 맨하탄 거리
- 교호항이 포함된 회귀: 독립변수들의 교호작용이 포함된 회귀모형
교호작용: 두 개 이상의 독립변수가 상호작용을 하여 종속변수에 영향을 미치는 경우
- 회귀분석의 분산분석(ANOVA)표
3개 이상의 그룹의 평균을 비교하는 검정(회귀모형의 유의성 분석시 활용)
- 회귀 모형의 검정
귀무가설: 모든 회귀계수는 0이다
p-value가 0.05보다 크면 채택
결정계수(R square): 모형이 설명력을 갖는가 판단.
다변량 분석
-
상관분석
피어슨: 연속형 변수, 선형관계 크기측정, 양적 척도
스피어만: 서열 척도, 순서형 변수, 선형/비선형적 관계
스피어만은 선형관계가 아니더라도 1/-1을 나타낼 수 있음 -
주성분 분석(PCA)
상관성 높은 변수들의 선형 결합으로 차원을 축소하여 새로운 변수
자료의 분산이 가장 큰 축(퍼진건 둔다)이 첫번째 주성분
70~90% 설명력을 갖는 수를 결정
cumulative proportion을 적용하여 전체 데이터의 약 80%를 설명
분해시계열
시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석
추운 계절의 순환이 불규칙하다.
1. 추세요인
2. 계절요인
3. 순환요인: 알려주지 않은 주기를 갖고 변화(경제전반, 특정산업)
4. 불규칙요인(위 3가지로 설명 불가한 요인)
