데이터 전처리의 필요성과 핵심방법
불균형 데이터 문제 해결 능력
범주형 데이터 인코딩 기법
피처 엔지니어링 기법
결측치, 이상치, 불균형 데이터를 제대로 처리하고, 의미 있는 파생 변수를 생성하여 모델의 성능을 높일 수 있다
총 정리
1️⃣ 결측치와 이상치를 올바르게 처리하는 것은 모델의 기초
2️⃣ 불균형 데이터 문제를 해결하지 않으면 소수 클래스(불량)을 놓칠 수 있음
3️⃣ 범주형 변수는 원-핫 인코딩, 레이블 인코딩 등으로 적절히 변환
4️⃣ 피처 엔지니어링을 통해 데이터에서 추가 정보(패턴)을 추출하거나, 중요하지 않은 변수는 제거해 모델 효율과 성능을 높임
데이터 전처리 개요
원시(raw) 데이터에서 불필요하거나 손실(노이즈)이 있는 부분을 처리하고, 분석 목적에 맞는 형태로 만드는 과정
머신러닝을 하기 전에 데이터 전처리부터 해야한다.
필요성
모델 정확도 및 신뢰도 향상
이상치나 결측치가 많은 상태로 학습하면 예측 성능이 크게 떨어짐
효율적인 데이터 분석과 모델 훈련을 위해 필수적인 단계
사례 - 마케팅, 금융, 제조업
결측치 처리
발생원인 : 센서고장, 측정오류, 환경적 문제, 누락(수기입력)
-
삭제
: 결측치가 있는 행(row) 또는 열(column)을 제거
→ 간단하지만 데이터 손실이 발생
→ 결측치가 전체 데이터에서 매우 소수일 때 적합 -
대체
- 평균 또는 중앙값으로 대체
→ 수치형 데이터에서 많이 사용, 데이터 분포 왜곡이 비교적 적음- 최빈값으로 대체
→ 범주형 데이터에서 사용 - 예측 모델로 대체
→ 회귀/분류 모델을 이용해 결측값을 예측
- 최빈값으로 대체
-
예시
- 제조업: 센서데이터 특정시간 누락- 금융: 시계열 데이터(주가, 거래량), 고객 데이터(신용도, 소득, 자산) 결측치, 간헐적 결측값
- 마케팅: 캠페인 반응(클릭률, 전환율), 고객 설문/프로필 정보, 정기적 누락 채널/시점
결측치 처리 코드
삭제 - dropna()
대치 - fillna(대치값)
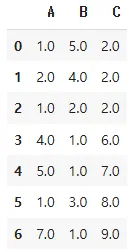
import numpy as np
import pandas as pd
# 1) 가상 데이터 생성
# - 일부 값들을 np.nan으로 지정해 결측값을 만듭니다.
data = {
'A': [1, 2, np.nan, 4, 5, np.nan, 7],
'B': [5, 4, 2, np.nan, np.nan, 3, 1],
'C': [2, np.nan, np.nan, 6, 7, 8, 9]
}
df = pd.DataFrame(data)
df
# 2) 결측치 제거 (결측이 하나라도 있으면 해당 행을 제거)
df_drop = df.dropna()
df_drop
# 3) 평균값으로 대치
df_mean = df.copy()
df_mean = df_mean.fillna(df_mean.mean(numeric_only=True))
df_mean
# 4) 중앙값으로 대치
df_median = df.copy()
df_median = df_median.fillna(df_median.median(numeric_only=True))
df_median
# 5) 최빈값으로 대치
# - DataFrame의 mode()는 각 열별로 최빈값을 반환합니다.
# - mode() 결과가 여러 개(동률)일 경우 첫 번째 행의 값을 취합니다.
df_mode = df.copy()
print(df_mode.mode()) # 확인용
mode_values = df_mode.mode().iloc[0] # 첫 번째 행(가장 상위 mode)만 취함
df_mode = df_mode.fillna(mode_values)
df_mode
기존데이터
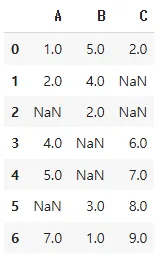
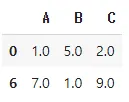
결측치 제거
결측치 평균값으로 대치
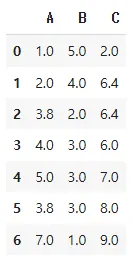
df_mean.mean(numeric_only=True)는 각 열(column)별 평균값을 계산.numeric_only=True는 숫자형 열에 대해서만 평균을 계산하겠다는 옵션
중앙값으로 대치
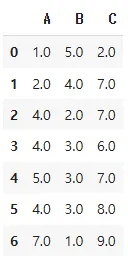
최빈값으로 대치
df.mode()

fillna(mode().iloc[0])
이상치 탐지 및 제거
이상치
정상 범주에서 크게 벗어나는 값으로 장비 오작동이나 환경적 특이 상황 등 원인이 다양함
탐지기법
-
통계적 기법
데이터가 정규분포를 따른다고 가정, 평균에서 ±3σ(표준편차, 약 99%) 범위를 벗어나는 값을 이상치로 간주
직관적이고 간단하나, 정규성 가정(정규분포라 가정했을 때만 성립. 아니면 안됨)이 틀릴 수 있다. -
박스플롯(Box plot)기준
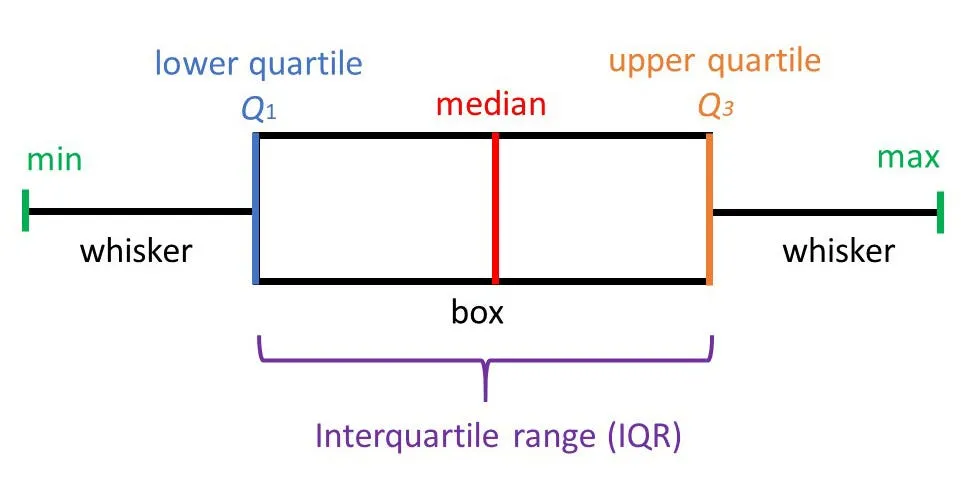
사분위수(IQR = Q3 - Q1)를 이용해 ‘Q1 - 1.5×IQR’, ‘Q3 + 1.5×IQR’를 벗어나는 데이터를 이상치로 간주
분포 특성에 영향을 적게 받는 장점 -
머신러닝 기반
이상치 탐지 알고리즘 (Isolation Forest, DBSCAN 등)
복합적 패턴을 고려가능
처리기법
-
단순제거
-
이상치 값 조정(클리핑, Winsorizing)
-
별도구분 -> 모델제외 or 다른모델(이상치 예측 모델)로 활용
이상치를 무조건 버리지 않고, 오히려 따로 떼어내서 다른방식으로 활용한다는 말.
이상치는 평범한 데이터와는 다른 패턴을 가지니까, 다른 패턴을 예측하는 모델을 따로 만들 수 있다!- 📌 예시 1. 이상치 분류기 만들기 이상치만 따로 모아서, 어떤 조건일 때 이상치가 발생하는지를 학습하는 이상치 예측 모델을 만드는 거야. 👉 예: 제조업에서 센서 데이터 중 이상치를 고장 징후로 보고, 이상 패턴을 학습시켜 고장 예측 모델을 만드는 경우. - 📌 예시 2. 이상치 전용 모델 만들기 전체 데이터 → 정상 데이터 모델과 이상치 모델로 분리해서 각각 모델을 학습 예측 시, 입력 데이터를 먼저 판단해서 “이건 이상치 같다” → 이상치 모델 사용 “이건 정상 같다” → 정상 모델 사용 👉 예: 금융 사기 탐지 모델 평범한 거래 패턴 → 일반 모델 수상한 패턴 → 사기 탐지용 모델 따로 활용
이상치 제거 코드 예시
import pandas as pd
import numpy as np
# 예시 데이터프레임 생성
np.random.seed(42) # 재현성을 위해 시드 설정
normal_values = np.random.normal(loc=50, scale=5, size=30) # 평균 50, 표준편차 5인 정규분포에서 30개 값 생성
outliers = [150, 180, 200, 300] # 눈으로 봐도 이상치로 판단될 수 있는 큰 값들
# normal_values와 outliers를 합쳐서 하나의 리스트로 구성
all_values = np.concatenate([normal_values, outliers])
# 예시로 0~39 범위의 임의 날짜/시간 데이터를 간단히 만들기
dates = pd.date_range('2021-01-01', periods=len(all_values), freq='D')
df = pd.DataFrame({
'date': dates,
'sensor_value': all_values
})
df
# 이상치 제거 (간단하게 박스플롯 기준 적용 예시)
Q1 = df['sensor_value'].quantile(0.25)
Q3 = df['sensor_value'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df = df[(df['sensor_value'] >= lower_bound) & (df['sensor_value'] <= upper_bound)]
df정규화/표준화
모델(거리기반 알고리즘, 딥러닝)에 따라 특정 변수의 스케일이 큰 영향을 미칠 수 있다.
ex) 센서 A는 값 범위가 0~1000, 센서 B는 값 범위가 0~1이라면, A가 모델에 더 큰 영향을 줌
정규화(MinMaxSacler)
모든 값을 0과 1사이로 매핑하는 것
특징
- 값의 스케일이 달라도 공통 범위로 맞출 수 있음.
딥러닝(신경망), 이미지 처리 등에서 입력값을 0~1로 제한해야 하거나, 각 특성이 동일한 범위 내 있어야 하는 경우 자주 사용.
거리 기반 알고리즘(유클리디안 거리 사용)이나, 각 특성의 범위를 동일하게 맞춤으로써 계산 안정성을 높이고 싶을 때. - 최소값·최대값이 극단값(Outlier)에 민감. 만약 극단치가 있으면 대부분의 데이터가 [0, 1] 구간 내부 한쪽에 치우침.
- 새로운 데이터가 기존 최대값보다 커지거나, 최소값보다 작아지는 경우, 스케일링 범위를 벗어날 수 있어 재학습하거나 다른 처리가 필요.
표준화(StandardScaler)
평균을 0, 표준편차를 1로 만듦
특징
-
분포가 정규분포에 가깝게 변형됨
평균이 0, 표준편차가 1로 맞춰지므로, 정규분포 가정을 사용하는 알고리즘(선형회귀, 로지스틱회귀, SVM 등)에 자주 쓰임.
변환된 값들이 이론적으로 -∞ ~ +∞ 범위를 가질 수 있다. -
데이터가 특정 구간([0, 1] 등)에 고정되지x.
-
데이터 분포가 심하게 치우쳐 있으면, 평균과 표준편차만으로는 충분한 스케일링이 되지 않을 수 있습니다(로그 변환, RobustScaler 등 추가 고려).
코드
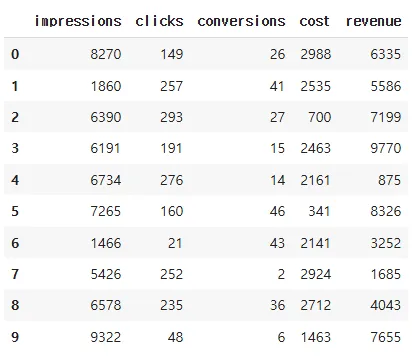
import pandas as pd
import numpy as np
# 난수를 재현하기 위해 시드 설정
np.random.seed(42)
# 예시 마케팅 지표 데이터 생성
data_size = 10
df = pd.DataFrame({
'impressions': np.random.randint(1000, 10000, size=data_size), # 광고 노출 횟수
'clicks': np.random.randint(0, 300, size=data_size), # 광고 클릭 횟수
'conversions': np.random.randint(0, 50, size=data_size), # 광고를 통해 구매한 횟수
'cost': np.random.randint(100, 5000, size=data_size), # 광고비 지출액
'revenue': np.random.randint(100, 10000, size=data_size) # 광고를 통해 발생한 매출
})
df
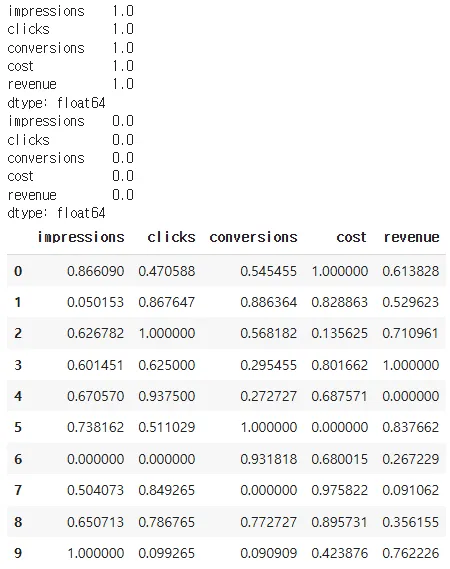
from sklearn.preprocessing import MinMaxScaler
# 스케일링을 적용할 컬럼만 선정
cols_to_scale = ['impressions', 'clicks', 'conversions', 'cost', 'revenue']
# MinMaxScaler 객체 생성(기본 스케일: [0,1])
minmax_scaler = MinMaxScaler()
# fit_transform을 통해 스케일링된 결과를 데이터프레임으로 변환
df_minmax_scaled = pd.DataFrame(minmax_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
print(df_minmax_scaled.max())
print(df_minmax_scaled.min())
df_minmax_scaled기존 데이터
- 정규화, MinMaxScaler()
:MinMaxScaler()를 만들어서scaler라는 이름으로 할당.
:fit_transform(df[['칼럼이름']])호출
1️⃣fit: 열을 살펴 최솟값과 최댓값을 찾습니다.
2️⃣transform: 찾은 최소·최대값으로 각 데이터를 0~1 범위로 바꿉니다.
scaler.fit(data) # 데이터를 보고 "학습" (예: 최솟값, 최댓값을 기억)
scaler.transform(data) # 학습된 기준으로 실제 데이터를 "변환"
# 두 코드 한번에 쓰면
scaler.fit_transform(data)df_minmax_scaled = pd.DataFrame(minmax_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
df[cols_to_scale] → 스케일링할 컬럼만 뽑고
fit_transform() → 최솟값/최댓값을 계산하고, 그걸로 변환까지 함
pd.DataFrame(..., columns=cols_to_scale) → 다시 원래 컬럼 이름으로 DataFrame 만들기
- 표준화, StandardScaler()
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체 생성
standard_scaler = StandardScaler()
# fit_transform을 통해 스케일링된 결과를 데이터프레임으로 변환
df_standard_scaled = pd.DataFrame(standard_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
print(df_standard_scaled.mean())
print(df_standard_scaled.std())
df_standard_scaled : StandardScaler()를 만들어서 standard_scaler라는 이름으로 할당합니다.
: fit_transform(df[['칼럼이름']]) 호출
1️⃣ fit: 열의 평균과 표준편차를 구합니다.
2️⃣ transform: 각 값을 (x - 평균) / 표준편차로 변환해, 평균 0, 표준편차 1인 분포를 만듭니다.
pd.DataFrame(standard_scaler.fit_transform(df[cols_to_scale]),
columns=cols_to_scale)
fit
주어진 데이터를 보고 스케일링 기준 저장
정규화 - min/max
표준화 - 평균/표준편차
어떤 기준을 저장할지는 어떤 스케일러를 쓰냐에 따라 달라짐
scaler = MinMaxScaler() -> 정규화
scaler = StandardScaler() -> 표준화
minmax_scaler = MinMaxScaler()
standard_scaler = StandardScaler()
이렇게 객체 생성후 fit진행 -> 자동으로 값 저장
transform은 fit을 기준으로 값 변환
불균형 데이터 처리
불균형 데이터: 정상 99%, 불량 1%처럼 한 클래스가 극도로 적은 경우
모델이 극도로 적은 클래스를 거의 예측하지 못할 가능성이 큼(편향 발생)
해결기법
- Oversampling
📚 Random Oversampling
: 소수 클래스의 데이터를 단순 복제하여 개수를 늘림
📚 SMOTE(Synthetic Minority Over-sampling Technique)
: 소수 클래스를 "무작정 복사"만 하는 게 아니라, “비슷한” 데이터들을 서로 섞어서(Interpolation) 새로운 데이터 생성
즉, 소수 클래스(ex: 스팸) 안에서 가까운 데이터 둘(혹은 몇 개)을 고르고, 그 사이에 새 데이터 포인트를 만들어내어, 소수 클래스의 다양한 예시를 가상으로 늘리는 기법
ex)오렌지(소수 클래스)와 사과(다수 클래스)가 있는 과일 바구니
→ 사과는 90개, 오렌지는 10개뿐
→ "오렌지를 조금 더 만들어서(복사)" 갯수를 맞출 수도 있지만, 그러면 똑같은 오렌지가 여러 개 생길 뿐, 다양성 x.
→ SMOTE:“모양이나 맛이 비슷한 두 오렌지를 고른 다음, 그 중간 정도 되는 새로운 오렌지를 상상해서 만들어낸다” 같은 느낌
이렇게 하면 기존 오렌지랑 똑같지도 않고, 완전히 엉뚱하지도 않은 새 오렌지를 얻을 수 있음.
- Undersampling
다수 클래스 데이터를 줄이는 방식
데이터 손실 위험이 있지만, 전체 데이터 균형을 맞출 수 있음
- 혼합 기법
SMOTE와 언더샘플링을 적절히 섞어서 사용
코드
import numpy as np
import pandas as pd
# 난수 고정 (재현성)
np.random.seed(42)
# 불균형 데이터 크기 설정
# 예: 총 100개 중 defect=1(불량)인 샘플 10개, defect=0(정상)인 샘플 90개
size_1 = 10
size_0 = 90
# 정상 클래스 (defect=0) 데이터 생성
feature1_0 = np.random.normal(loc=10, scale=2, size=size_0)
feature2_0 = np.random.normal(loc=5, scale=1, size=size_0)
# 불량 클래스 (defect=1) 데이터 생성
feature1_1 = np.random.normal(loc=20, scale=5, size=size_1)
feature2_1 = np.random.normal(loc=10, scale=2, size=size_1)
# 배열 병합
feature1 = np.concatenate([feature1_0, feature1_1])
feature2 = np.concatenate([feature2_0, feature2_1])
defect = np.array([0]*size_0 + [1]*size_1)
# 데이터프레임 생성
df = pd.DataFrame({
'feature1': feature1,
'feature2': feature2,
'defect': defect
})
df
np.random.normal(평균, 표준편차, 개수)
from imblearn.over_sampling import SMOTE
# 불균형 데이터 처리 (SMOTE)
X = df.drop('defect', axis=1) # 결측치 처리, 이상치 제거, 인코딩 등 사전 처리 후
y = df['defect']
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resample(X, y)X = df.drop('defect', axis=1)
df데이터프레임에서defect컬럼(레이블)을 제외한 나머지를X(특징 행렬)로 사용합니다.
df에서 defect컬럼만 빼고 나머지 컬럼(axis=1)들만 남겨서 x에 저장
이때, 이미 결측치 처리, 이상치 제거, 범주형 인코딩 등의 사전 전처리를 마쳤다고 가정.
smote = SMOTE(random_state=42)
: SMOTE 객체를 생성
: SMOTE는 소수 클래스(예: 결함 사례)가 너무 적을 때, 기존 소수 클래스 데이터들을 바탕으로 유사한 새로운 예시를 만들어 데이터 개수를 늘려주는 기법
:random_state=42는 재현성(코드 실행 시 동일 결과)을 위해 난수 시드를 고정하는 역할.

몇 안되는 지피티가 외우라는 것.. 행0열1
X_res, y_res = smote.fit_resample(X, y)
:fit_resample을 통해 SMOTE 알고리즘이X, y를 바탕으로 소수 클래스 데이터를 자동 생성.
: 결과적으로, 오버샘플링된X_res, y_res에는 클래스 불균형이 개선된(1:1에 가깝거나 원하는 비율이 된) 상태가 됨.
fit(X, y)
→ y를 보고 소수 클래스가 뭔지 파악하고, X를 분석해서 유사 샘플을 어떻게 만들지 학습
y(타깃값)를 보고 클래스 비율 확인, 소수 클래스의 데이터를 X에서 찾아서 그 데이터들을 기준으로 "유사한 가짜 데이터"를 어떻게 만들지 판단
resample(X, y)
→ 분석 결과를 바탕으로, 소수 클래스 샘플을 새로 생성해서 X, y에 추가
근데 이걸 한 줄로 동시에 하게 만든 게 → fit_resample() 함수!
- X_res
- y_res
범주형 데이터 변환
원-핫 인코딩
-
범주형 변수를 각각의 범주별로 새로운 열로 표현, 해당 범주에 해당하면 1, 아니면 0
ex) 색상(‘Red’, ‘Blue’, ‘Green’) → ‘Red=1,Blue=0,Green=0’ / ‘Red=0,Blue=1,Green=0’ / … -
장점: 범주 간 서열 관계가 없을 때 사용하기 좋음
-
단점: 범주가 매우 많으면 차원이 커짐
import pandas as pd
import numpy as np
# 예시 데이터프레임 생성
data_size = 10
np.random.seed(42)
labels = ['apple', 'banana', 'cherry']
random_labels = np.random.choice(labels, data_size)
df = pd.DataFrame({
'id': range(1, data_size + 1),
'label': random_labels,
'value': np.random.randint(1, 100, data_size),
'another_feature': np.random.choice(['A', 'B'], data_size) # 또 다른 범주형 변수
})
df
# 범주형 변수 변환 (원-핫 인코딩 예시)
df = pd.get_dummies(df, columns=['label'])pd.get_dummies(df, columns=['칼럼이름'])
→열의 범주들(A, B, C 등)을 각각 별도 열로 만들어, 해당하는 행에는 1, 그렇지 않은 행에는 0을 넣어줍니다.
apple/namama/cherry열이 생김
참인 값 1 아니면 0
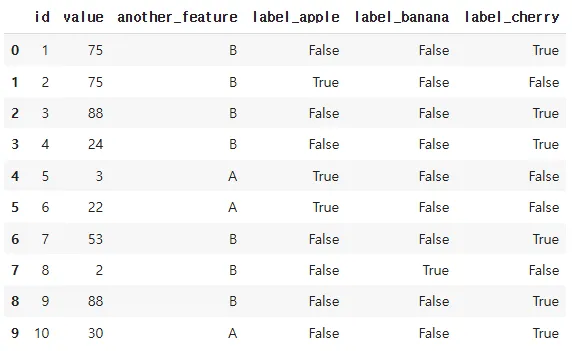
- pd.get_dummies(df, drop_first=True)
더미변수를 하나 제거해서 다중공산성 방지(선형회귀 자주 사용)
다중공산성: 여러 개의 독립변수(입력 변수)들이 서로 강하게 상관관계를 가질 때 발생하는 문제.
즉, 독립변수들끼리 서로 너무 비슷한 정보를 가지고 있어서 모델이 “누가 영향 주는 건지 헷갈려” 하는 상황
레이블 인코딩
- 범주를 숫자로 직접 맵핑(‘M’=0, ‘L’=1, ‘XL’=2 등)
단순하지만, 모델이 숫자의 크기를 서열 정보로 잘못 해석할 수 있음
import pandas as pd
import numpy as np
# 예시 데이터프레임 생성
data_size = 10
np.random.seed(42)
labels = ['apple', 'banana', 'cherry']
random_labels = np.random.choice(labels, data_size)
df = pd.DataFrame({
'id': range(1, data_size + 1),
'label': random_labels,
'value': np.random.randint(1, 100, data_size),
'another_feature': np.random.choice(['A', 'B'], data_size) # 또 다른 범주형 변수
})
dfnp.random.choice(labels, data_size)
선택할 값들의 목록(labels), 몇 개 뽑을지(정수, data_size)
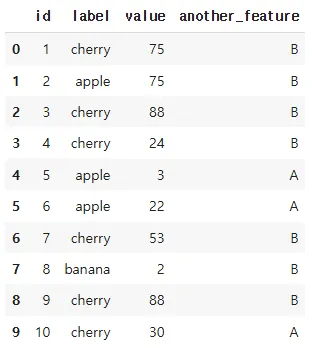
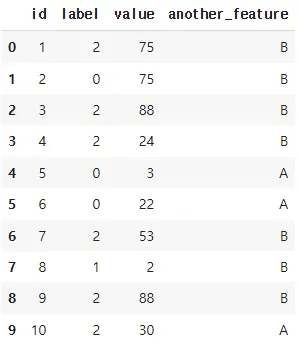
# 범주형 변수 변환 (레이블 인코딩 예시)
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df["label"] = encoder.fit_transform(df["label"])
dfdf["label"] = encoder.fit_transform(df["label"])df["label"]열(column)을 fit_transform 메서드에 전달하여,- fit: 데이터에 등장하는 범주를 학습
- transform: 학습한 매핑에 따라 데이터를 정수로 변환
- 변환된 결과(정수 라벨)를 다시
df["label"]에 덮어쓰기 ["red", "blue", "blue", "green"]같은 문자열 범주가 존재하면,- "blue" → 0
- "green" → 1
- "red" → 2와 같이 매핑될 수 있습니다(실제 순서는 데이터에 따라 달라집니다).
피처 엔지니어링
모델 성능 향상을 위해 기존 데이터를 변형, 조합하여 새로운 특성(피처)을 만드는 작업
복잡한 데이터 구조 안에 존재하는 패턴을 효과적으로 추출해 모델이 쉽게 학습하게 함
파생변수
- 날짜 파생변수
측정 시간이 ‘2025-02-24 10:35:00’이라면, ‘월(2)’, ‘요일(월=1)’, ‘시(10)’, ‘주말여부(0/1)’ 등으로 분해 - 수치형 변수 조합
‘온도’와 ‘습도’가 있을 때, 새로운 피처 ‘온도×습도(TEMP×HUMID)’를 추가
두 변수의 상호작용이 불량 발생에 영향을 줄 수 있음 - 로그변환, 제곱근 변환 등
분포가 매우 치우친 변수(오른쪽 꼬리가 긴 경우)에 로그 변환을 적용하여 정규성에 가까워지도록 조정
import pandas as pd
import numpy as np
np.random.seed(42) # 재현성을 위한 시드 고정
# 10개 데이터 샘플 생성
data_size = 10
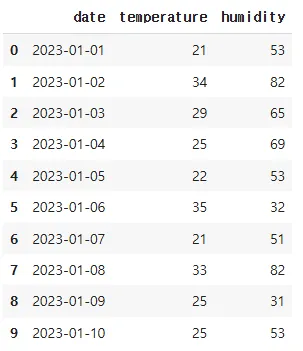
# 날짜/시간 컬럼(예시)
dates = pd.date_range(start="2023-01-01", periods=data_size, freq='D')
# 온도(°C) : 15 ~ 35 사이 정수
temperature = np.random.randint(15, 36, size=data_size)
# 습도(%) : 30 ~ 90 사이 정수
humidity = np.random.randint(30, 91, size=data_size)
df = pd.DataFrame({
'date': dates,
'temperature': temperature,
'humidity': humidity
})
df
# 피처 엔지니어링 (온도와 습도 간 상호작용)
df['temp_humid_interaction'] = df['temperature'] * df['humidity']
df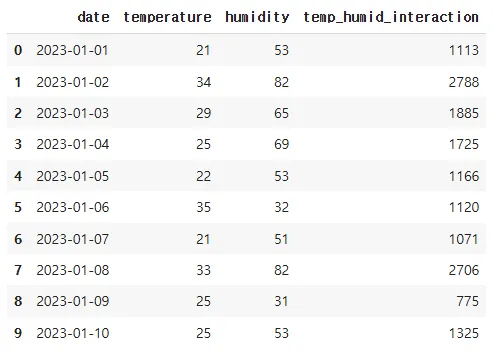
변수선택
-
상관관계
두 변수 간 상관도가 높은 상황인 경우 다중공선성 의심. 중복 정보가 클 수 있으므로, 하나만 남기거나 둘 다 제거 고려
- 다중공선성(multicollinearity)
회귀분석(집값 예측, 매출 예측 등)을 할 때, 여러 설명 변수(독립 변수)를 사용
그런데 이 변수들이 서로 너무 비슷한 정보를 담고 있어 (즉, 서로 강하게 상관이 있어) 모델이 헷갈리는 문제가 생김 = 다중공선성
다중공선성은 회귀계수(모델 파라미터)의 의미 해석과 모델 안정성을 해침
- ex) 집 크기(㎡)와 방 개수가 거의 정비례한다면, 둘 다 넣었을 때 겹치는 정보가 많아집니다.
- "방 개수"와 "평수(㎡)"라는 두 변수
방이 5개면 평수도 대체로 넓고, 1개면 대체로 좁음(둘은 서로 높은 상관 관계).
- 둘 다 회귀분석에 넣으면 모델 입장에서 "비슷한 정보가 두 번 들어온 셈"이라,어떤 변수가 집값에 얼마나 영향을 주는지(독립적 기여도)를 구분하기 어려움.
- 이런 경우, VIF가 높게 나타남. -
VIF
회귀분석에서 다중공선성 문제를 파악할 때 사용
VIF는 어떤 변수 하나가, 다른 변수들과 얼마나 겹치는지(상관이 큰지) 수치로 보여주는 지표
VIF가 일정 기준(예: 10 이상)을 넘으면 해당 변수를 제거하거나 비슷한 변수들을 합치는(변환) 등의 방법으로 문제를 해결 -
모델 기반 중요도(Feature Importance)
트리 기반 모델(랜덤 포레스트, XGBoost 등)을 훈련 후 중요도가 낮은 변수를 제거
변수간 상호작용 추가
- 다항식/교차 항 생성
- ex) 2차 다항식(Quadratic Features)
- 제조 공정에서 온도, 압력, 속도 등이 곱해져야 비로소 의미가 생기는 경우가 많음
