
본 내용은 내일배움캠프에서 활동한 내용을 기록한 글입니다.
💻 기술 면접 질문 답변
📌 [Language - Javascript]
✏️ var, let, const 에 대해 설명해주세요.
-
var는 변수를 선언하기 위한 방식으로 같은 이름의 변수를 재선언 가능합니다.
-
let 역시 변수를 선언하기 위한 방식이지만 var과 다르게 같은 이름으로 재선언이 불가능합니다.
-
const는 상수를 선언하기 위한 방식으로 선언된 상수는 변경이 불가합니다.
-
변수와 상수는 메모리 영역의 수정 여부로 구분합니다.
✏️ Promise란 무엇인지 설명해주세요.
-
비동기 작업을 관리하기 위한 자바스크립트 객체입니다.
-
비동기 작업을 관리하기 위해 사용하던 콜백함수로 인해 콜백 지옥이 발생했습니다.
-
이러한 콜백 지옥을 해소하고 더 나은 가독성을 위해서 Promise를 사용합니다.
✏️ async/await 이란 무엇인지 설명해주세요.
-
async/await는 자바스크립트의 비동기 작업을 더 쉽고 직관적으로 작성하게 도와주는 문법입니다.
-
Promise 기반의 코드를 작성할 때 작성하는데, async는 그 함수의 앞에 붙이고 그 함수 내부에서 await 를 사용합니다.
-
이 때, await가 붙은 비동기 작업은 동기적으로 동작해서 작업이 끝날 때까지 기다립니다.
-
이를 통해서 비동기 작업을 마치 동기 작업처럼 동작시킬 수 있습니다.
✏️ Hoisting이란 무엇인지 설명해주세요.
-
호이스팅은 자바스크립트에서 변수나 함수의 선언 부분이 코드의 최상단으로 올려지는 현상을 말합니다.
-
호이스팅은 이러한 변수나 함수의 정보를 수집하는 과정을 이해하기 위한 가상 개념입니다.
-
변수 선언은 호이스팅되지만, 변수 할당은 호이스팅되지 않습니다.
-
함수 선언은 함수 전체가 호이스팅됩니다.
-
함수 표현식은 변수와 마찬가지로 선언 부분만 호이스팅되고 할당 부분은 호이스팅되지 않습니다.
✏️ Arrow Function 이란 무엇인지 설명해주세요.
-
화살표 함수는 자바스크립트에서 함수 표현식을 더 간결하게 사용하기 위한 방식입니다.
-
그리고 this 바인딩과 관련해서 일반적인 함수 표현식과 다르게 적용됩니다.
-
일반적인 함수 안에서의 this는 전역을 가르키지만 화살표 함수에서의 this는 상위 스코프의 this를 가르킵니다.
✏️ Express란 무엇이고 왜 필요하며 대안은 무엇이 있는지 설명해주세요.
-
Express는 가장 널리 사용되는 Node.js 웹 프레임워크입니다.
-
Express는 주로 간단한 웹 서버 구축을 통해 빠르게 웹을 개발하기 위해서 사용됩니다.
-
Express의 경우 별도의 라이프 사이클이 없고 미들웨어로 개발자가 구현해야 하는 문제가 있습니다.
-
그리고 Express는 자바스크립트 기반이기에 타입에 의한 런타임 에러가 많이 발생합니다.
-
그래서 이에 대한 대안으로 저는 대표적으로 Nest.js가 있다고 생각합니다.
-
Nest.js는 타입스크립트를 기반으로 해서 타입에 대한 런타임 에러를 줄일 수 있습니다.
-
그리고 Nest.js에는 가드, 인터셉터, 파이프 등과 같은 라이프 사이클이 존재하기 때문에 개발자는 그 라이프 사이클에 맞춰서 개발을 진행하면 됩니다.
✏️ 깊은 복사와 얕은 복사의 차이는 무엇이고 JS에서 각각을 구현하는 방법은 어떻게 되는지 설명해주세요.
-
얕은 복사는 참조형 타입에서 바로 아래 단계의 값만 복사하는 방법입니다.
-
자바스크립트에서 얕은 복사는 Object.assign()과 스프레드 연산자를 활용해서 구현이 가능합니다.
-
깊은 복사는 모든 참조를 끊고 값들을 복사하는 방법입니다.
-
자바스크립트에서 깊은 복사는 JSON.parser(JSON.stringify(obj))와 재귀함수를 활용해서 구현이 가능합니다.
✏️ JWT에 대해 설명해주세요. 구체적으로 JWT를 어디서 처리하는지, 어떠한 방식으로 검증하는지, 재발급 방식과 주기는 어떻게 처리하는지, 다른 API 서비스 호출 시 어떻게 잡아서 인증 처리하는지 말씀해주세요.
-
JWT는 클라이언트와 서버 간의 통신에서 인가 수단으로 사용됩니다.
-
인증된 클라이언트가 로그인하면 서버로부터 발급받습니다.
-
그리고 인가가 필요한 작업을 요청할 때는 헤더에 JWT를 포함해서 서버에 전달하면 서버에서 그 JWT를 검증하고 유효성을 확인합니다.
-
JWT는 헤더, 페이로드, 시그니처로 구성되는데 시그니처를 통해서 토큰의 무결성을 확인합니다.
-
보통 JWT는 Access Token과 Refresh Token으로 나누는데, 이 때 Access Token은 비교적 짧은 유효기간을 가지고, Refresh Token은 긴 유효기간을 가집니다.
-
만약 Access Token가 만료되면 재발급을 위해서 Refresh Token을 통해서 새로운 토큰을 발급합니다.
-
다른 API 서비스에서 호출 시 클라이언트가 기존에 발급받은 JWT를 헤더에 포함시켜서 전송합니다.
-
서버는 헤더를 통해 받은 JWT를 비밀키를 통해서 검증해서 인가 여부를 판단합니다.
✏️ Node.js는 single-threaded 기반 JS 런타임입니다. 이에 대해 아는 만큼 설명해주세요.
✏️ Node.js는 non-blocking, asynchronous 기반 JS 런타임입니다. 이에 대해 아는 만큼 설명해주세요.
-
Node.js는 자바스크립트 런타임 환경으로, 서버에서 자바스크립트를 실행할 수 있게 해줍니다.
-
가장 큰 특징 중 하나는 싱글 스레드로 동작한다는 점입니다.
-
싱글 스레드 기반으로 동작하기 때문에 멀티 스레드 환경에서 발생할 수 있는 데드락같은 동시성 문제를 피할 수 있고,
개발자가 스레드 간의 동기화를 고민할 필요가 없어 코드가 간단해집니다. -
그리고 또 다른 큰 특징은 Node.js가 논-블로킹과 비동기 방식을 채택해 비동기적으로 I/O작업을 처리합니다.
-
이벤트 루프를 통해서 비동기 작업을 처리하며, 이를 통해 I/O작업을 기다리지 않고 다른 작업을 계속 수행할 수 있습니다.
-
또한, 콜백, 프로미스, async/await 구문을 통해 비동기 작업을 관리하고, 코드의 흐름을 간결하게 유지하면서도 효율성을 높일 수 있습니다.
✏️ Node.js의 이벤트 루프란 무엇이고 왜 필요하며 어떻게 작동하는지 아는 만큼 설명해주세요.
-
이벤트 루프는 Node.js에서 비동기 작업을 처리하기 위해 사용하는 구조입니다.
-
Node.js는 싱글 스레드 기반이지만 이벤트 루프를 통해서 비동기 I/O 작업을 효율적으로 하기 위해서 사용합니다.
-
이벤트 루프의 구조는 크게 호출 스택, 이벤트 큐, 백그라운드, 이벤트 루프로 나눌 수 있습니다.
-
만약 비동기 작업이 실행되면 해당 작업의 콜백 함수는 백그라운드로 보내져서 실행되고 그 결과를 이벤트 큐에 추가합니다.
-
그리고 이벤트 루프는 호출 스택이 비어있는지 확인하고 이벤트 큐에서 대기 중인 콜백 함수를 호출 스택으로 가져갑니다.
📌 [알고리즘]
✏️ BigO에 대해 설명해주세요.
-
빅오 표기법은 알고리즘의 성능을 평가하는 방법 중 하나입니다.
-
주로 알고리즘의 시간 복잡도, 공간 복잡도를 표현하기 위해서 사용합니다.
-
시간 복잡도는 알고리즘이 실행되는 데 걸리는 시간을 의미하고, 공간 복잡도는 얼마나 많은 메모리를 사용하는지를 나타냅니다.
-
시간 복잡도를 예로 O(1)은 언제나 같은 시간이 소요된다는 것을 의미합니다.
-
그리고 O(n)은 입력의 크기와 비례하게 시간이 늘어난다는 것을 의미하고, O(n^2)은 입력이 2배가 늘어나면 시간이 4배 늘어난다는 것을 의미합니다.
✏️ 다음의 정렬을 설명하고 본인이 가장 편한 언어를 사용하여 로직을 구현해주세요.
- 버블 정렬(Bubble Sort)
- 시간 복잡도 : O(n^2)
- 인접한 두 요소를 비교해서 큰 값을 뒤로 보내는 방식 (1회전 후 가장 큰 값이 맨 뒤에 있음)
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
# 예시 사용
print(bubble_sort([64, 34, 25, 12, 22, 11, 90]))- 선택 정렬(Selection Sort)
- 시간 복잡도 : O(n^2)
- 가장 작은 요소를 찾아서 맨 앞의 요소와 교환하는 방식 (1회전 후 가장 작은 값이 맨 앞에 있음)
def selection_sort(arr):
for i in range(len(arr)):
min_index = i
for j in range(i + 1, len(arr)):
if arr[j] < arr[min_index]:
min_index = j
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr
# 예시 사용
print(selection_sort([64, 25, 12, 22, 11]))- 삽입 정렬(Insertion Sort)
- 시간 복잡도 : O(n^2)
- 1번 인덱스부터 시작해서 앞에 있는 요소들과 비교해서 현재 인덱스의 값보다 작은 값을 만나면 그 작은 값의 뒤에 삽입하는 방식
def insertion_sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
# 예시 사용
print(insertion_sort([12, 11, 13, 5, 6]))- 병합 정렬(Merge Sort)
- 시간 복잡도 : O(nlogn)
- 배열을 반으로 나눠서 재귀적으로 정렬 후, 나눠진 배열을 병합하면서 최종 정렬을 만듦 (배열의 길이가 1이 될 때까지 나눔)
def merge_sort(arr):
# 배열의 길이가 2보다 작으면 이미 정렬된 상태이므로 그대로 반환
if len(arr) < 2:
return arr
# 중간 인덱스 계산
mid = len(arr) // 2
# 배열을 두 개의 하위 배열로 나누고 재귀적으로 정렬
left = merge_sort(arr[:mid]) # 왼쪽 하위 배열
right = merge_sort(arr[mid:]) # 오른쪽 하위 배열
# 두 개의 하위 배열을 병합하기 위한 배열 초기화
merged_arr = []
l = r = 0 # 왼쪽과 오른쪽 하위 배열의 인덱스 초기화
# 두 하위 배열을 비교하여 정렬된 배열을 만듭니다
while l < len(left) and r < len(right):
if left[l] < right[r]:
merged_arr.append(left[l]) # 왼쪽 배열의 요소를 추가
l += 1 # 왼쪽 인덱스 증가
else:
merged_arr.append(right[r]) # 오른쪽 배열의 요소를 추가
r += 1 # 오른쪽 인덱스 증가
# 남은 요소가 있을 경우 추가
merged_arr += left[l:] # 왼쪽 배열에 남은 요소 추가
merged_arr += right[r:] # 오른쪽 배열에 남은 요소 추가
return merged_arr # 병합된 배열 반환- 퀵 정렬(Quick Sort)
- 시간 복잡도 : O(nlogn)
- 기준이 될 피벗을 선책하고 피벗보다 작은 값은 왼쪽에, 큰 요소는 오른쪽에 배치하는 방식
def quick_sort(arr):
# 배열의 길이가 1 이하인 경우, 이미 정렬된 상태이므로 그대로 반환
if len(arr) <= 1:
return arr
# 피벗(pivot) 설정: 배열의 중간 요소를 피벗으로 선택
pivot = arr[len(arr) // 2]
# 피벗보다 작은 요소들로 이루어진 배열 생성
left = [x for x in arr if x < pivot]
# 피벗과 같은 요소들로 이루어진 배열 생성
middle = [x for x in arr if x == pivot]
# 피벗보다 큰 요소들로 이루어진 배열 생성
right = [x for x in arr if x > pivot]
# 재귀적으로 왼쪽, 중간, 오른쪽 배열을 정렬하고 병합하여 반환
return quick_sort(left) + middle + quick_sort(right)
# 예시 사용
print(quick_sort([3, 6, 8, 10, 1, 2, 1])) # 출력: [1, 1, 2, 3, 6, 8, 10]- 힙 정렬(Heap Sort)
- 시간 복잡도 : O(nlogn)
- 완전 이진 트리를 이용한 최대 힙이나 최소 힙 트리 구조를 활용해 정렬하는 방식
- 배열로부터 최대 힙 구성 => 루트(가장 큰 값)에 배열 마지막 요소를 넣고 다시 최대 힙 구성
def heapify(arr, n, i):
largest = i # 현재 노드의 인덱스
left = 2 * i + 1 # 왼쪽 자식 노드의 인덱스
right = 2 * i + 2 # 오른쪽 자식 노드의 인덱스
# 왼쪽 자식이 현재 노드보다 큰 경우
if left < n and arr[i] < arr[left]:
largest = left # largest를 왼쪽 자식으로 업데이트
# 오른쪽 자식이 현재 largest보다 큰 경우
if right < n and arr[largest] < arr[right]:
largest = right # largest를 오른쪽 자식으로 업데이트
# largest가 현재 노드가 아닌 경우
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i] # swap
heapify(arr, n, largest) # 재귀적으로 heapify 호출
def heap_sort(arr):
n = len(arr) # 배열의 길이
# 배열을 힙으로 변환 (최대 힙 생성)
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
# 힙에서 요소를 하나씩 꺼내어 정렬
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # 최대 요소를 배열의 끝으로 이동 (swap)
heapify(arr, i, 0) # 남은 힙을 다시 힙화
return arr # 정렬된 배열 반환
# 예시 사용
print(heap_sort([12, 11, 13, 5, 6, 7])) # 출력: [5, 6, 7, 11, 12, 13]✏️ DFS와 BFS의 차이를 말해주세요.
-
깊이 우선 탐색(Depth First Search, DFS)
- 가능한 깊게 탐색한 후 더 이상 갈 수 없는 경우에 다른 경로를 탐색하는 방식입니다.
- 주로 스택을 이용해서 구현하며, 현재 노드와 인접한 노드들을 스택에 넣고 하나씩 꺼내면서 해당 노드를 방문합니다.
- 그리고 다시 그 노드와 인접한 노드들을 스택에 넣고 하나를 꺼내어 탐색을 진행합니다.
- 메모리 사용이 상대적으로 적을 수 있으며, 모든 경로나 경우를 탐색할 때 유용합니다.
-
너비 우선 탐색(Breath First Search, BFS)
- 현재 노드의 모든 인접 노드를 먼저 탐색하고 다음 레벨의 노드들을 탐색하는 방식입니다.
- 주로 큐를 이용해서 구현하며, 인접한 모든 노드들을 큐에 추가하고 하나씩 꺼내어 탐색합니다.
- 가중치 없는 그래프에서 효과적이며, 최단 경로를 찾을 때 유용합니다.
📌 [Data structure]
✏️ Array과 LinkedList를 비교설명해주세요.
-
Array와 LinkedList는 모두 데이터를 저장하기 위한 자료구조입니다.
-
하지만 데이터 접근 방식이나 메모리 상에서의 구조 등에서 차이를 보입니다.
-
Array는 인덱스를 통해서 데이터에 빠르게 접근이 가능하고, 고정된 크기의 연속된 메모리에 데이터를 저장합니다.
-
LinkedList는 노드의 포인터를 통해서 삽입과 삭제가 빠르게 이루어지고, 필요에 따라 크기가 변할 수 있는 동적인 크기를 가집니다.
-
그렇기에 데이터의 접근 속도가 중요하다면 Array를, 동적 크기와 빈번한 삽입과 삭제가 필요하다면 LinkedList를 선택하는 것이 좋습니다.
✏️ Stack과 Queue를 비교설명해주세요.
-
Stack과 Queue는 모두 데이터를 저장하기 위한 자료구조입니다.
-
Stack은 FILO(First In, Last Out) 구조로, 가장 먼저 들어간 데이터가 가장 나중에 제거되는 방식입니다.
-
데이터를 추가할 때는 push() 메서드를, 삭제할 때는 pop() 메서드를 사용합니다.
-
Stack의 사용 예로 함수의 호출 관리나 Undo/Redo, 웹페이지 히스토리 등이 있습니다.
-
Queue는 FIFO(First In, First Out) 구조로, 가장 먼저 들어간 데이터가 가장 먼저 제거되는 방식입니다.
-
데이터를 추가할 때는 enqueue() 메서드를, 삭제할 때는 dequeue() 메서드를 사용합니다.
-
Queue의 사용 예로 프로세스 관리나 대기열과 같이 순서를 따질 필요가 있을 때 사용합니다.
✏️ 그래프(Graph)와 트리(Tree)를 설명하고, 둘의 차이점을 설명해주세요.
-
그래프는 정점과 간선으로 구성된 자료구조 입니다.
-
사이클이 존재할 수 있고, 정점과 정점을 간선으로 연결해서 연결된 정점 간의 관계를 표현합니다.
-
트리는 그래프의 일종으로, 하나의 루트 노드가 자식 노드를 가지는 형태의 자료구조 입니다.
-
계층적 구조를 가지며 사이클 없이 연결된 그래프입니다.
-
그래프와 트리의 가장 큰 차이점은 사이클의 유무이며 그래프는 복잡한 관계를 표현할 수 있는 구조이고, 트리는 명확한 계층 구조를 가진 구조입니다.
✏️ 이진트리, 이진 검색트리, 힙이 각각 무엇인지 설명하고, 차이점을 설명해주세요.
-
이진 트리는 각 노드가 최대 두 개의 자식 노드를 가질 수 있는 트리입니다.
-
이진 탐색 트리는 각 노드의 서브 트리는 해당 노드보다 작으면 왼쪽, 크면 오른쪽으로 구성된 트리입니다.
-
그래서 값의 검색, 삽입, 삭제 등의 연산에서 평균 O(log n)의 시간 복잡도로 수행됩니다.
-
힙은 완전 이진 트리의 일종으로, 부모 노드의 값을 기준으로 최대 힙, 최소 힙 구조를 가집니다.
-
최대 힙은 부모 노드의 값이 자식 노드의 값보다 크거나 같은 구조를 의미합니다.
-
최소 힙은 반대로 부모 노드의 값이 자식 노드의 값보다 작거나 같은 구조를 의미합니다.
-
즉, 이진 트리는 가장 기본적인 트리 구조고, 이진 탐색 트리는 데이터의 검색 및 정렬이 효율적인 트리 구조고, 힙은 주로 우선순위 큐나 정렬 알고리즘에서 사용되는 트리 구조입니다.
-
Red-Black Tree
-
이진 탐색 트리의 일종으로 삽입과 삭제 시 색을 통해 균형을 유지합니다.
-
각 노드는 레드 또는 블랙이라는 색을 가지고 다음과 같은 규칙을 따릅니다.
- 루트 노드는 항상 블랙입니다.
- 모든 리프 노드는 블랙입니다.
- 레드 노드는 연속적으로 연결될 수 없습니다. (즉, 레드 노드의 자식은 블랙이어야 합니다.)
- 모든 리프 노드부터 루트 노드까지의 경로에서 블랙 노드의 수가 동일해야 합니다.
-
-
B+ Tree
-
일반적인 이진 탐색 트리와 다르게 하나의 노드가 여러 개의 자식을 가질 수 있습니다.
-
모든 데이터는 리프 노드에만 저장되고, 나머지 비 리프 노드들은 인덱스 역할을 합니다.
-
리프 노드끼리 연결되어 있어서 범위 데이터를 찾을 때 용이합니다.
-
그래서 주로 데이터베이스나 파일 시스템에서 많이 사용됩니다.
-
✏️ 해시테이블과 이진 검색트리를 비교하고 장단점을 이야기해주세요.
-
해시테이블은 키와 값의 쌍을 저장하는 자료구조로, 해시 함수를 통해 키를 고유한 인덱스로 변환해서 데이터를 저장합니다.
-
장점으로는 빠른 검색이 가능하고 해시 함수만 있으면 비교적 구현 자체는 간단하다는 점입니다.
-
단점으로는 해시된 키의 값이 충돌하는 문제가 생길 수도 있고, 정렬된 데이터가 필요할 때는 부적합하다는 점입니다.
-
이진 탐색 트리는 각 노드가 최대 두 대의 자식 노드를 가지는 트리 구조로, 왼쪽은 부모 노드보다 작고 오른쪽은 부모 노드보다 큰 값들로 구성한다는 특징이 있습니다.
-
장점으로는 데이터의 수가 바뀌어도 동적으로 크기 조정이 가능하고, 데이터의 순서가 바뀌어도 간단하게 정렬이 가능하다는 점입니다.
-
단점으로는 편향된 이진 탐색 트리가 될 수도 있고, 그래서 균형 이진 탐색 트리를 만든다면 구현 복잡성이 높아진다는 점입니다.
📌 [Database]
✏️ Primary Key, Foreign Key, ER 모델이란 무엇인가요?
-
Primary Key
- 기본키는 데이터베이스 테이블에서 각 행을 고유하게 식별하기 위한 컬럼입니다.
- 중복된 값을 가질 수 없으며, NULL 값을 허용하지 않습니다.
-
Foreign Key
- 외래키는 다른 테이블의 기본키를 참조하는 컬럼입니다.
- 두 테이블 간의 관계를 설정하며, 데이터의 무결성을 유지하는데 중요한 역할을 합니다.
- 여기서의 무결성은 참조 무결성으로, 외래키가 참조하는 기본키가 항상 존재해야 한다는 원칙입니다.
-
ER 모델
- ER 모델은 데이터베이스 설계를 위해 데이터베이스의 구조와 관계를 시각적으로 나타내는 방법입니다.
- 구성 요소는 엔티티, 속성, 관계로 구성되어 있습니다.
- 엔티티는 데이터베이스에서 관리할 객체를 의미합니다. 간단하게는 테이블 하나라고 생각해도 됩니다.
- 속성은 엔티티의 데이터 필드를 의미합니다. 간단하게는 테이블의 컬럼이라고 생각해도 됩니다.
- 관계는 엔티티 간의 관계를 나타냅니다.
✏️ 정규화에 대해서 말해보세요, 정규화의 목적은 무엇인가요?
-
정규화는 데이터베이스에서 데이터의 중복을 최소화하고 무결성을 유지하기 위한 일종의 규칙입니다.
-
정규화를 통해 동일한 데이터가 여러 테이블에 반복 저장되는 것을 방지할 수 있고, 데이터의 일관성을 높여서 데이터 무결성을 유지할 수 있습니다.
-
정규화에도 단계가 존재하는데, 일반적으로 제 3 정규화까지 진행하는 경우가 많다고 합니다.
-
제 1 정규화는 도메인이 원자값을 가져야 한다는 것을 의미합니다. 즉, 각 컬럼은 하나의 데이터만 가진다는 것을 의미합니다.
-
제 2 정규화는 부분적 종속이 없어야 한다는 것을 의미합니다. 즉, 현재 테이블의 주제와 관련없는 컬럼을 다른 테이블로 빼는 작업을 의미합니다.
-
제 3 정규화는 이행적 중속이 없어야 한다는 것을 의미합니다. 즉, 하나의 기본키에만 의존하도록 테이블을 분리하는 작업을 의미합니다.
✏️ 무결성에 대해 말해보시오.
-
무결성은 데이터베이스에서 데이터의 정확성, 일관성, 신뢰성을 보장하는 개념입니다.
-
무결성의 목적은 데이터의 품질을 유지하고 오류를 최소화하는 것 입니다.
-
그래서 무결성에도 몇 가지 종류가 있습니다.
-
참조 무결성은 외래키가 참조하는 기본키가 항상 존재해야 한다는 원칙입니다.
-
도메인 무결성은 각 필드의 데이터가 허용되는 값인지 확인해야 한다는 것을 의미합니다.
-
개체 무결성은 테이블의 기본키가 NULL 값을 가질 수 없고 고유해야 한다는 원칙입니다.
-
이렇게 3개가 가장 많이 사용되는 기본적인 무결성 유형입니다.
✏️ JOIN이 무엇인지 설명해주세요.
-
JOIN은 두 개 이상의 테이블을 결합해서 하나의 결과로 표현하는 SQL 연산입니다.
-
다양한 JOIN 유형이 존재하고 상황에 따라 다르게 사용할 수 있습니다.
-
INNER JOIN은 두 테이블의 공통된 데이터만 포함합니다. 즉, 두 테이블에서 조건에 맞는 행만 결과에 포함됩니다.
-
OUTER JOIN은 한 개의 테이블에만 데이터가 있어도 결과가 나옵니다. OUTER JOIN에는 LEFT, RIGHT, FULL OUTER JOIN이 존재합니다.
-
LEFT OUTER JOIN은 오른쪽 테이블에서 일치하는 값을 왼쪽 테이블에 포함시켜서 결과로 출력합니다. 이때 일치하는 값이 없으면 NULL로 표현됩니다.
-
RIGHT OUTER JOIN은 왼쪽 테이블에서 일치하는 값을 오른쪽 테이블에 포함시켜서 결과로 출력합니다. 이때 일치하는 값이 없으면 NULL로 표현됩니다.
-
FULL OUTER JOIN은 두 테이블의 모든 행을 포함시키면서 각 테이블에서 일차하는 값이 없으면 NULL로 표현됩니다.
✏️ NoSQL이란 무엇인가요? 기존RDBMS와 다른점도 설명해주세요.
-
NoSQL은
Not Only SQL의 약자로, RDBMS와 달리 테이블 간 관계를 정의하지 않습니다. -
주로 비정형 데이터 및 대규모 데이터 처리에 많이 사용됩니다.
-
데이터의 양이 증가할 때, 서버의 성능을 높이지 않고, 여러 서버를 추가해서 확장할 수 있습니다.
-
그리고 데이터를 여러 서버에 분산해서 저장해서 가용성과 성능을 높입니다. 즉, 하나의 서버에 문제가 생겨도 다른 서버에서 데이터에 접근이 가능합니다.
-
반면에 RDBMS는 테이블 간의 관계를 통해 테이블 간의 복잡한 관계 처리를 할 때 사용됩니다.
-
주로 정확성과 정형화된 데이터 관리에 강점을 가지고 있습니다.
-
RDBMS는 주로 하나의 서버를 사용하기에 데이터의 양이 증가하면 서버의 성능을 높이는 방식이기 때문에 한계가 있습니다.
-
그래서 서버가 고장나면 데이터에 접근하지 못할 수 있습니다.
✏️ 트랜잭션이란 무엇인가요?
-
트랜잭션은 데이터베이스에서 일련의 작업을 하나의 단위로 묶어서 처리하는 것을 의미합니다.
-
이렇게 묶어서 처리하는 이유는 데이터의 일관성과 무결성을 유지하기 위해서 이러한 작업들을 모두 성공시키거나, 모두 취소되어야 합니다.
-
트랜잭션의 성질 (ACID 원칙)
- 원자성(Atomicity) : 트랜잭션 내의 모든 작업이 성공적으로 수행되거나, 하나라도 실패하면 트랜잭션 전체가 취소 되어야 한다는 원칙입니다.
- 일관성(Consistency) : 트랜잭션 수행 전과 후의 데이터베이스 상태가 유지되어야 합니다. 즉, 데이터베이스 규칙을 깨는 데이터가 들어 가는 등의 동작이 수행되면 안됩니다.
- 격리성(Isolation) : 여러 트랜잭션이 수행될 때, 다른 트랜잭션의 영향을 받지 않아야 합니다.
- 지속성(Durability) : 트랜잭션이 성공적으로 완료되면 그 결과는 영구적으로 저장되어야 합니다.
-
Lock은 트랜잭션 처리의 순차성을 보장하기 위한 기법입니다.
- Lock의 종류로는 공유 Lock과 배타적 Lock이 있습니다.
- 공유 Lock은 여러 트랜잭션이 동시에 데이터를 읽을 수 있지만, 수정할 수는 없습니다.
- 배타적 Lock은 한 트랜잭션만 데이터에 접근할 수 있으며, 다른 트랜잭션은 읽거나 수정할 수 없습니다.
- Lock을 적절히 사용하지 않으면 교착 상태에 빠지기 때문에 접근 순서 설정은 중요합니다.
-
그리고 트랜잭션을 사용할 때 주의할 점이 있습니다.
- 적절한 Lock을 사용해서 교착 상태를 피해야 합니다.
- 트랜잭션의 크기는 가능한 짧고 간단하게 유지되어야 합니다.
- 트랜잭션이 실패했을 때 적절한 에러 처리 로직을 통해서 데이터의 일관성을 유지해야 합니다.
📌 [OS, 운영체제]
✏️ 프로세스와 쓰레드에 대해서 설명하고 그 차이에 대해서 설명해주세요.
-
프로세스는 실행중인 프로그램을 의미합니다.
-
쓰레드는 프로세스 내에서 실행되는 작업의 단위입니다.
-
프로세스는 각자 독립적인 메모리 공간을 가지고, 쓰레드는 같은 프로세스 내에서 실행되기에 메모리 공간을 공유합니다.
✏️ 멀티프로세스와 멀티쓰레드의 특징에 대해 설명해주세요.
-
멀티프로세스는 여러 개의 프로세스를 동시에 실행하는 방식을 의미합니다.
-
각 프로세스는 독립적인 메모리 공간을 가지기 때문에 안정성과 성능을 제공합니다.
-
하지만 독립적이기에 자원의 소모가 크고 프로세스 끼리는 IPC라는 복잡한 방법을 통해 통신해야 합니다.
-
멀티쓰레드는 하나의 프로세스 내에서 여러 개의 쓰레드를 동시에 실행시키는 방식을 의미합니다.
-
모든 쓰레드가 같은 메모리 공간을 공유해서 빠른 데이터 교환을 통해 효율성은 높습니다.
-
하지만 하나의 쓰레드에서 오류가 발생하면 같은 프로세스 내의 다른 쓰레드에도 영향을 미칠 수 있습니다.
✏️ 동기와 비동기의 차이 설명해주세요.
-
동기는 작업이 순차적으로 진행되는 것을 의미합니다.
-
즉, 하나의 작업이 완료되어야만 다음 작업이 시작될 수 있습니다.
-
동기 방식은 직관적이고 간단하지만, 시간이 오래 걸리는 문제가 발생할 수 있습니다.
-
비동기는 작업이 독립적으로 진행되는 것을 의미합니다.
-
즉, 하나의 작업이 완료되지 않아도 다음 작업을 시작할 수 있습니다.
-
비동기 방식은 응답성을 높이고 병렬 처리를 가능하게 하지만, 구현이 복잡해질 수 있습니다.
✏️ Deadlock이란 무엇인지 설명해주세요.
-
Deadlock은 교착 상태를 의미합니다.
-
교착 상태는 두 개 이상의 프로세스가 서로 자원을 점유한 상태에서 상대방이 점유하고 있는 자원을 기다리며 무한히 대기하는 상태를 의미합니다.
-
즉, 어떤 프로세스도 다음 과정으로 진행할 수 없는 상황을 말합니다.
-
교착 상태가 발생하기 위해서는 다음과 같은 조건을 모두 충족하는 경우 발생합니다.
- 상호 배제 : 자원은 한 번에 하나의 프로세스만 사용할 수 있어야 합니다.
- 점유와 대기 : 최소한 하나의 프로세스가 자원을 점유하고 있고, 추가적인 자원을 요청하기 위해서는 대기 상태가 되어야 합니다.
- 비선점 : 이미 점유된 자원을 다른 프로세스가 강제로 빼앗을 수 없어야 합니다.
- 순환 대기 : 프로세스들이 서로 자원을 기다리는 순환 관계가 형성되어야 합니다.
-
이러한 교착 상태를 해결하기 위해서는 다음과 같은 방법이 있습니다.
- 예방 : 교착 상태의 조건 중 하나를 제거하는 방법입니다.
- 회피 : 교착 상태가 발생하지 않도록 시스템이 자원의 요청을 관리하는 방법입니다. 예를 들면 은행원 알고리즘을 사용해서 자원 할달이 안전한 상태인지 확인하고 안전하지 않다면 자원 요청을 거부합니다.
- 탐지 및 회복 : 시스템이 교착 상태를 탐지하고, 발생하면 이를 해결하기 위한 조취를 취하는 방법입니다.
📌 [네트워크]
✏️ TCP/UDP의 차이점을 설명하세요.
-
TCP와 UDP는 전송 계층 프로토콜입니다.
-
TCP는 연결 지향 프로토콜로 신뢰성이 높고 패킷 구조가 복잡하며, 오류 검출과 재전송 기능이 있습니다.
-
UDP는 비연결 지향 프로토콜로 속도가 빠르지만 신뢰성으며, 패킷 구조가 간단합니다.
-
3-way handshake는 TCP 연결 설정 과정입니다.
-
클라이언트가 요청 신호(SYN)를 보내면 서버가 응답(SYN-ACK)한 뒤, 클라이언트가 잘 받았다는 의미로 응답(ACK) 신호를 보내면서 연결이 완료됩니다.
✏️ 브라우저에 네이버홈페이지 url을 입력했을때 일어나는 과정을 설명하세요.
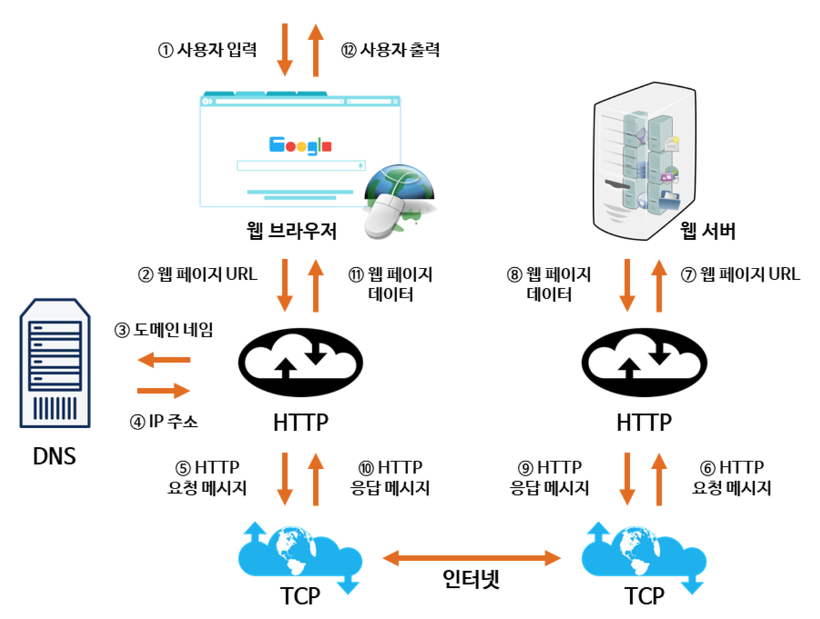
-
사용자가 브라우저 주소창에 URL을 입력합니다.
-
브라우저는 입력된 도메인 이름을 DNS에 요청해서 해당하는 IP주소를 가져옵니다.
-
얻은 IP 주소를 사용해서 웹 서버와의 연결을 위해 TCP 연결 설정을 합니다.
-
HTTP 프로토콜을 사용해서 서버에 요청을 합니다.
-
웹 서버는 요청을 처리한 후, 요청된 리소스를 포함한 HTTP 응답을 브라우저로 전송합니다.
-
수신한 HTML 문서를 해석하고 사용자에게 보여지는 페이지를 렌더링합니다.
✏️ OSI 7계층에대해 설명하세요.
-
OSI 7계층
- 물리 계층 : 실제 데이터 전송을 담당하며, 케이블과 같은 물리적 요소를 다룹니다.
- 데이터 링크 계층 : MAC 주소를 사용하고, 데이터의 오류 검출을 담당합니다.
- 네트워크 계층 : IP 주소를 통해 목적지를 지정하고, 패킷을 전달합니다.
- 전송 계층 : 데이터 전송의 신뢰성을 보장하고, 흐름 제어 및 오류 복구를 제공합니다.
- 세션 계층 : 두 장치 간의 세션을 설정하고 관리하여 통신을 유지합니다.
- 표현 계층 : 데이터 형식을 변환하고 암호화 및 압축 처리합니다.
- 응용 계층 : 웹 브라우저와 같이 사용자와 직접 상호작용하는 계층입니다.
-
리피터, 허브, 브릿지, 라우터
- 리피터 : 신호를 증폭해서 전송 거리를 늘리는 장치입니다.
- 허브 : 여러 장치를 연결해서 데이터를 브로드캐스트하는 장치입니다.
- 브릿지 : 두 개의 LAN을 연결하는 장치입니다.
- 라우터 : 서로 다른 네트워크 간의 패킷을 전달하고 최적의 경로를 선택하는 장치입니다.
-
L2, L3, L4, L7 스위치
- 스위치는 데이터의 흐름을 효율적으로 조절하기 위해서 사용합니다.
- L2 스위치 : 데이터 링크 계층에서 MAC 주소를 기반으로 프레임을 전송합니다.
- L3 스위치 : 네트워크 계층에서 IP 주소를 기반으로 패킷을 라우팅합니다.
- L4 스위치 : 전송 계층에서 TCP/UDP 를 기반으로 데이터의 흐름을 관리합니다.
- L7 스위치 : 응용 계층에서 HTTP, FTP 등과 같은 애플리케이션 레벨의 정보 기반으로 트래픽을 관리합니다.
✏️ RESTFul API 란 무엇인가요?
-
REST API는 HTTP Method를 통해 자원에 대한 CRUD를 적용하고 주소를 정하는 방법을 의미합니다.
-
즉, RESTFul API는 REST API 주소 체계를 이용하는 시스템을 의미합니다.
-
실제로 완벽한 RESTFul API는 구현하기 어렵기 때문에, 최대한 깔끔하고 이해하기 쉬운 주소 체계를 만드는 것이 중요합니다.
✏️ HTTP 프로토콜에 대해 설명해주세요.
-
웹에서 데이터를 주고 받는 서버-클라이언트 모델의 프로토콜을 의미합니다.
-
즉, 웹 브라우저가 서버와 통신하는 규칙을 말합니다.
-
서버-클라이언트 모델은 클라이언트가 서버에 요청을 보내면, 서버는 요청에 대한 응답을 반환하는 형태를 의미합니다.
-
그리고 HTTP 프로토콜에는 무상태(stateless)라는 특징이 있는데, 각 요청은 독립적이고 서버는 이전 요청의 상태를 기억하지 않는다는 특징이 있습니다.
✏️ HTTP와 HTTPS의 차이는 무엇인가요?
-
HTTP는 데이터를 암호화하지 않고 전송하지만 HTTPS는 SSL/TLS 프로토콜을 사용해서 데이터를 암호화합니다.
-
HTTP에서는 클라이언트와 서버간의 신회성을 보장하지 않지만, HTTPS는 SSL/TLS 인증서를 통해서 서버의 신원을 인증합니다.
-
그리고 HTTPS는 검색엔진에서 HTTP보다 더 높은 순위를 부여받는 경우가 많습니다.
✏️ HTTP method에 대해 설명해주세요.
-
GET : 서버 자원을 가져오려고 할 때 사용합니다.
-
POST : 서버에 자원을 새로 등록하고자 할 때, 또는 뭘 써야할지 애매할 때 사용합니다.
-
PUT : 서버의 자원의 전체 내용을 수정하려고 할 때 사용합니다.
-
PATCH : 서버의 자원의 일부만 수정하려고 할 때 사용합니다.
-
DELETE : 서버의 자원을 삭제하려고 할 때 사용합니다.
-
GET은 데이터 조회에 적합하고, POST는 데이터 전송 및 생성에 적합합니다.
✏️ Session과 Cookie 차이는?
-
둘 다 주로 사용자의 정보를 저장하고 관리하는 데 사용되는 기술입니다.
-
Cookie
- 로컬에 저장되는 키-값 형태의 작은 데이터입니다.
- 쿠키로 사용자 정보를 저장할 경우 중간에 정보를 탈취 당할 가능성이 높습니다.
- 쿠키는 브라우저를 종료해도 만료기간 동안 남아 있습니다.
-
Session
- 일정 기간동안 사용자의 상태를 유지시키는 기술입니다.
- 세션은 보통 쿠키를 이용해서 세션 ID만 저장하고 내부 상세 데이터는 서버에서 관리합니다.
- 그렇기 때문에 보안면에서 세션이 더 우수하다고 할 수 있습니다.
- 세션은 브라우저를 종료하면 삭제됩니다.
- 하지만 서버에 요청하는 사용자가 많아지는 경우 세션은 부하가 심할 수 있습니다.
📌 [ETC]
✏️ 좋은 코드란 무엇인가요?
-
좋은 코드에 대한 저의 생각은 간단하게 2가지로 말할 수 있을 것 같습니다.
-
첫째, 중복이 최소화 되어야 합니다. 중복이 되는 부분은 함수화, 모듈화를 통해 줄여야 합니다.
-
둘째, 다른 사람들이 봐도 이해하기 쉬워야 합니다. 변수명, 함수명, 코드 구조 등을 나만 알아볼 수 있으면 안됩니다.
-
셋째, 두 번째와 이어지긴 하지만 핵심 기능에 대해서는 간단한 주석이 필요하다고 생각합니다.
✏️ 객체 지향 프로그래밍이란 무엇인가요?
-
객체 지향
-
객체지향은 절차를 간소화하는 것이지, 결코 절차를 무시하는 것이 아닙니다.
-
데이터와 이를 처리하기 위한 기능들을 모듈 내부에 체계적으로 작성합니다.
-
자료구조와 이를 중심으로 한 모듈들을 먼저 설계한 다음에 이들의 실행 순서와 흐름을 짜는 방식입니다.
-
데이터의 무결성을 보장하고 코드의 재사용성이 높습니다.
-
-
절차 지향
-
절차지향은 전통적인 프로그래밍 방식입니다.
-
데이터와 이를 처리하기 위한 기능들을 별도로 분리해서 작성합니다.
-
프로그램의 순서와 흐름을 먼저 세우고 필요한 자료구조와 함수를 설계하는 방식입니다.
-
프로젝트의 규모가 커질수록 구성 요소들 간의 결합도가 높아지고 데이터의 무결성을 보장하기 어렵습니다.
-
-
객체 지향 프로그래밍
-
객체지향 프로그래밍은 데이터와 그 데이터를 처리하는 메서드가 같은 모듈 내부에 배치되는 프로그래밍 방식입니다.
-
코드의 좋은 가독성, 높은 재사용성, 쉬운 유지보수를 위해 사용합니다.
-
객체지향 프로그래밍 방식은 데이터와 기능이 밀접하게 연결되어 있기 때문에, 코드의 구조와 동작을 직관적으로 파악할 수 있습니다.
-
만약 어떤 문제가 발생하면 빠르게 문제를 인지하고, 어떤 코드에서 오류가 발생했는지 빠르게 찾아보며, 오류를 빠르게 고쳐 개발하는 시간을 최대한으로 줄이는 것을 위해 사용합니다.
-
✏️ 함수형 프로그래밍이란 무엇인가요?
-
함수형 프로그래밍은 프로그램을 함수의 조합으로 구성하여 문제를 해결하는 방식입니다.
-
외부 상태를 변경하지 않는 부수 효과가 없어야 합니다.
-
항상 동일한 입력에 대해서 동일한 결과를 반환해야 합니다.
-
여기서 함수는 1급 객체로 취급되어 변수에 담거나 매개변수로 사용할 수 있습니다.
✏️ 형상 관리를 잘못하면 어떤 문제가 발생하나요?
-
여러 개발자가 동시에 작업할 경우 코드 병합 중에 버전 충돌이 발생할 수 있습니다.
-
그래서 협업이 비효율적으로 진행되어 생산성이 떨어질 수 있습니다.
-
코드 변경 이력을 제대로 관리하지 못하면, 변경 사항 추적이 어려워 문제가 발생했을 때 원인 파악이 어렵습니다.
-
이러한 문제들은 프로젝트의 성공에 부정적인 영향을 미칠 수 있습니다.
✏️ TDD 란 무엇이며 어떠한 장점이 있나요?
-
TDD(테스트 주도 개발, Test-Driven Development)는 소프트웨어 개발 방법론 중 하나로, 코드를 작성하기 전에 먼저 테스트 케이스를 작성하는 방식입니다.
-
테스트 코드를 통해 예상대로 동작하지 않는 코드를 빠르게 찾을 수 있습니다.
-
코드 변경 시, 변경 후의 코드도 정상적으로 동작하는지 확인할 수 있습니다.
-
결과적으로 TDD는 높은 코드 품질, 버그 조기 발견, 유지보수 용이라는 장점이 있습니다.
✏️ 형상 관리를 잘못하면 어떤 문제가 발생하나요?
-
CI 지속적인 통합, CD 지속적인 배포라는 의미로, 애플리케이션 개발 단계를 자동화하여 애플리케이션을 보다 짧은 주기로 고객에게 제공하는 방법입니다.
-
CI/CD의 예로는 Gtihub Actions, Jenkins 등의 도구가 있습니다.
-
CI/CD를 사용할 때의 장점
- 빠른 배포를 통해 사용자에게 새로운 기능이나 수정 사항을 신속하게 제공할 수 있습니다.
- 기존에 직접 배포 서버에서 하던 작업을 자동화하기 때문에 개발자의 생산성을 증가시킬 수 있습니다.
- 사용자의 피드백을 빠르게 반영함으로써, 제품의 품질을 지속적으로 향상시킬 수 있습니다.
✏️ MVC 패턴이란 무엇인가요?
-
MVC 패턴은 소프트웨어 디자인 패턴으로, 애플리케이션을 모델(Model), 뷰(View), 컨트롤러(Controller)의 세 가지 구성 요소로 나누어 설계하는 방법입니다.
-
모델은 어떻게 데이터가 변경되고 조작되는지에 대한 애플리케이션의 비즈니스 로직을 관리하고
-
뷰는 프론트엔드와 같은 사용자 인터페이스를 담당하며,
-
컨트롤러는 모델을 통해 받은 데이터를 처리하거나, 결과 값을 뷰에 반환합니다.
✏️ HTTP와 HTTP2의 차이는 무엇인가요?
-
HTTP는 단순 요청-응답 방식이지만 HTTP2는 다중 요청을 동시에 처리 가능합니다.
-
HTTP는 요청-응답이 반복되면서 헤더의 크기가 커질 수 있지만, HTTP2는 HPACK이라는 헤더 압축 기술을 사용해서 헤더 크기를 줄여서 전송이 가능합니다.
-
HTTP는 기본적으로 보안 기능이 없지만, HTTP2는 TLS를 통해서 보안을 강화합니다.
✏️ apache와 nginx차이는 무엇인가요?
-
Apache
- 프로세스 기반 아키텍처를 사용하여 각 요청마다 새로운 프로세스를 생성합니다.
- 동적 컨텐츠 처리에 강점을 가지고 있습니다. (동적 웹사이트)
- 메모리 소비가 상대적으로 높습니다.
-
Nginx
- 이벤트 기반 아키텍처를 사용하여 비동기적으로 요청을 처리합니다.
- 동시 연결 처리에 최적화되어 있어서 정적 컨텐츠 제공 시 더 나은 성능을 보입니다.
- 메모리 사용이 적어 더 많은 동시 연결을 효율적으로 처리할 수 있습니다.
- 리버스 프록시 서버에 자주 사용되며, 로드 밸런싱 기능이 강력합니다.
📌 [본인의 프로젝트 관련 질문]
✏️ 어떤 역할을 맡았고, 무슨 기술을 썼으며, 어떤 어려움이 있었고 어떻게 해결했는지
-
이번 프로젝트에서 CI/CD 배포 역할을 맡았습니다.
-
CI/CD 배포는 가장 많이 사용되는 방법 중 하나인 Github Actions을 이용했습니다.
-
이번 프로젝트의 배포 서버는 AWS EC2 인스턴스를 사용했습니다.
-
CI/CD가 진행되던 도중 Github Actions에서 CD 과정이 Timeout이 발생했다고 에러가 떴습니다.
-
확인해보니 EC2 환경에서 실행시킬 프로젝트 서버를 준비하는 과정에서 CPU가 100%로 치솟는 문제가 발생해서 모든 작업들이 멈추고 EC2 인스턴스도 먹통이 되었습니다.
-
조금 더 정확한 원인을 찾아보니 EC2 SSH 접속을 도와주는 appleboy/ssh-action을 다운로드 하는 과정에서 CPU 점유율이 100%로 치솟고 타임 아웃이 발생해서 EC2 인스턴스 자체가 멈춰버렸습니다.
-
그래서 appleboy/ssh-action를 사용하는 방법이 아니라 직접 EC2에서 SSH 접속을 위한 설정을 명령어를 CD 파일에서 실행시켜서 SSH에 접속하는 방법을 사용했습니다.
✏️ 작성한 프로젝트의 보안은 어떻게 신경썼나요?
-
사실 이번 프로젝트에서 구체적인 보안까지 신경쓰기 정말 어려웠습니다.
-
그래도 소셜 로그인을 구현하면서 보안적인 문제를 보완해서 구현했습니다.
-
기존에는 카카오 로그인 백엔드 API를 호출하면 생성한 토큰을 URL에 넣어서 리다이렉트 진행했습니다.
-
이러한 방식은 사용자의 정보가 들어 있는 토큰이 노출된 상태로 클라이언트에게 전달되는 문제가 있습니다.
-
그래서 고안한 방법이 의미없는 코드를 만들어서 해당 코드를 키로 하는 사용자 ID를 레디스에 저장하는 방법입니다.
-
이 방법을 사용하면 클라이언트는 URL 상에서 해당 코드만 확인이 가능하기 때문에 정확한 사용자 정보를 확인할 수 없습니다.
-
그리고 클라이언트가 필요로 하는 토큰은 직접적으로 노출된 형태가 아니라 Body에 담겨서 클라이언트에게 전달되기 때문에 보안적으로 다소 향상되었다고 볼 수 있습니다.
✏️ 어떤 실패를 했고 어떻게 극복했고 어떤것을 얻었는지
-
ALB를 통해 대용량 트래픽 처리에 대한 테스트를 진행했습니다.
-
참고로 EC2 인스턴스가 프리티어 t2.micro를 사용했기 때문에 10초동안 5~6000개 정도의 트래픽으로 테스트 진행했습니다.
-
실제로 EC2 인스턴스를 늘리면 대용량 트래픽을 분산해서 처리할 수 있을까를 확인하기 위해서 진행했습니다.
-
하지만 인스턴스를 3개까지 늘리면서 진행했지만, 생각처럼 유의미한 결과가 나오지 않았고 Timeout을 40초까지 설정해야 정상적으로 에러없이 트래픽을 수용했습니다.
-
이는 사용자가 페이지 로딩까지 30~40까지 기다려한다는 것을 의미하기 때문에 실패한 테스트라고 생각합니다.
-
그래서 Auto Scaling을 통해서 트래픽 요청 수에 따라서 인스턴스를 자동으로 증가시켜서 클라이언트가 훨씬 원활한 요청을 할 수 있도록 이어서 진행했습니다.
-
똑같은 환경으로 테스트한 결과 Auto Scaling은 인스턴스를 4개까지 생성했고 이를 통해 사용자가 기다려야 하는 최대 시간이 15~20초로 절반정도 줄어들었습니다.
-
이 때는 최대 인스턴스를 4개까지라고 설정했지만 5개 이상으로 설정하면 사용자에게 더 나은 환경을 제공할 수 있다는 생각을 했습니다.
-
저는 이러한 테스트들을 통해서 대용량 트래픽 처리에 있어 인스턴스 관리와 클라이언트 간의 밀접한 관계를 이해하는 데 큰 도움이 되었던것 같습니다.
-
사실 이러한 인스턴스 서버와 사용자 트래픽에 대해서 간단하게라도 경험해볼 기회가 없었기 때문에 더욱 좋은 경험이었던 것 같습니다.
-
그리고 Auto Scaling과 같은 시스템의 확장성과 유연성을 높이는 방법을 고민하는 시간을 가져서 좋았습니다.
