이번 글에서는 Application Layer에 대해 전반적으로 알아보도록 하겠다.
Application Architectures
어플리케이션 아키텍쳐에는 client-server 아키텍쳐와 P2P 아키텍쳐가 존재한다.
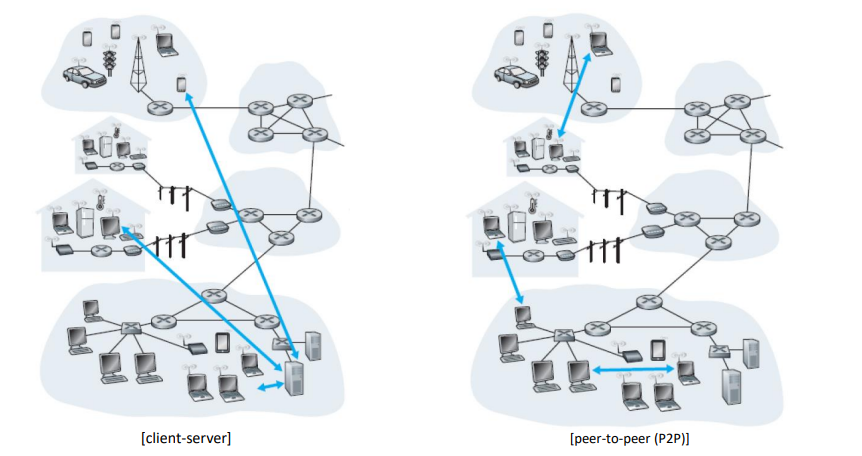
client-server 아키텍쳐는 일반적으로 사용되는 아키텍쳐로써, client들의 소통을 책임지는 중앙 서버가 존재하고, 이 서버를 통하여 통신하는 클라이언트들이 있는 구조이다. 서버의 ip주소는 영구적이고, 클라이언트의 ip 주소는 동적이라는 특징이 있고, 클라이언트는 서버를 통하지 않고는 (클라이언트 끼리는) 통신하지 않는다.
P2P 아키텍쳐는 클라이언트들을 관리하는 중앙 서버가 따로 없고, 클라이언트끼리 통신한다. 클라이언트들의 ip주소가 동적으로 변화하므로 관리가 어렵다는 단점이 있다.
HTTP
HTTP는 hypertext transfer protocol의 약자로써, 웹 서버와 클라이언트가 어떻게 정보를 주고받는지 정의된 프로토콜이다.
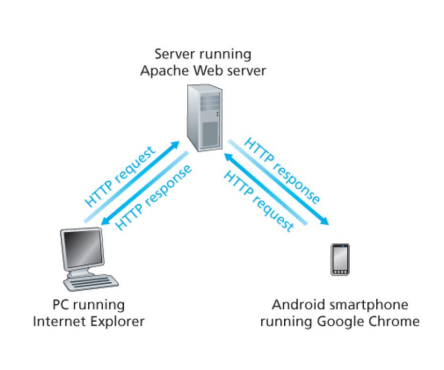
클라이언트는 웹 서버에게 HTTP request를 보내고, 웹 서버는 해당 request에 대한 HTTP response를 클라이언트에게 보낸다.
HTTP의 작동 과정은 간단히 이러하다.
- 클라이언트가 TCP 커넥션을 서버에게 요청한다
- 서버가 클라이언트로부터 온 TCP커넥션 요청을 수락한다.
- HTTP메시지가 서버와 클라이언트 사이에서 교환된다.
- TCP 커넥션이 종료된다.
HTTP connections
HTTP connection에는 Non-persistent connection 과 persistent connection이 존재하고, 개발자는 이 둘중에서 어떤 것을 사용할 지 선택해야 한다.
Non-persistent HTTP의 경우, 한 TCP 커넥션에 한 object만 전달되고, 커넥션이 종료된다. 따라서 여러 개의 object를 다운받으려면, 커넥션이 여러 개 필요하다.
persistent HTTP의 경우, 여러 개의 object들이 한 커넥션 안에서 교환될 수 있다.
Non-persistent HTTP를 차용하면, 한 개의 object를 보낼 때, (TCP connection의 RTT + HTTP request & response의 RTT)의 2RTT+@를 필요로 한다. 따라서 5 개의 object를 보낼 때 10RTT+@가 필요하다. 반면에, persistent HTTP를 차용하게 된다면 (TCP connection RTT 1회 + 5번의 HTTP request & response)로 총 6RTT+@가 필요하다.
HTTP message
request
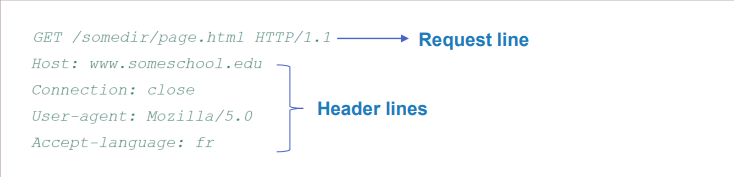
method/URL/version 순으로 되어 있다.
response

version/status code/phrase 순으로 되어 있다.
HTTP 메시지에 대해서는 다른 게시물로 자세히 다루도록 하겠다.
Cookies
HTTP 서버는 "stateless" 하다. 즉, 서버는 이전의 정보를 기억하지 못한다. 이러한 stateless한 상태는 서버의 구축을 좀 더 단순화시켜주고, 수행 능력을 향상시켜준다.
그렇지만, 유저 식별을 필요로 하는 웹 사이트도 존재한다. 해당 유저가 필요하는 contents를 제공하기 위해서이다. 그렇지만 말했듯 HTTP 서버는 stateless하기 때문에 유저의 정보를 기억할 수 없다.
이러한 상황을 타파하기 위해 등장한 것이 바로 "Cookie"이다.
Cookie의 작동 방식은 이러하다.
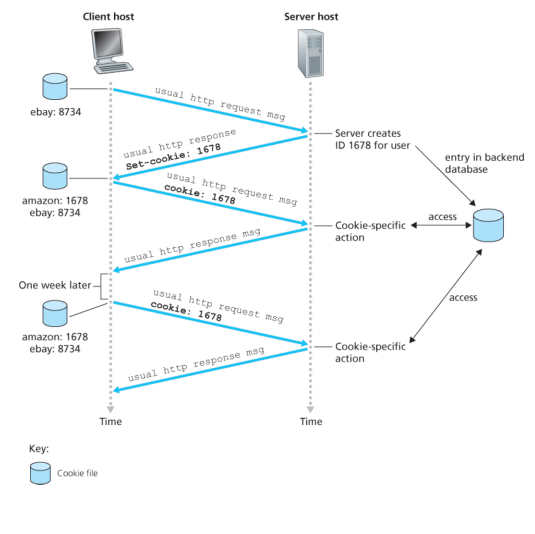
- 서버가 처음 접하는 클라이언트에게 http request 메시지를 받으면, 해당 클라이언트에게 랜덤으로 쿠키 번호를 생성하여 이를 http response 메시지에 넣어 보낸다.
- 웹 서버의 백엔드 데이터베이스에 쿠키 번호와 해당 정보를 저장한다.
- 클라이언트가 이 쿠키 번호를 저장하고, 다음에 해당 웹 서버에 http request를 보낼 때, 이 쿠키 번호도 함께 보낸다.
- 서버가 이 쿠키 번호를 수신하면, 백엔드 데이터베이스에 접근하여 정보를 얻고 Cookie-specific한 액션을 취한다.
이렇듯 쿠키를 이용하면 유저의 장바구니, 검색 기록 등을 알 수 있고, 이를 토대로 그와 관련된 광고 등을 송출할 수 있다.
Web caches (proxy server)
웹 캐시는 클라이언트와 웹 서버의 중간에 위치하여 웹 서버의 부담을 덜어주는 서버이다. 사람들이 자주 사용하는 정보들을 웹 캐시에 저장해두고 해당 정보와 관련된 http request 발생 시 original 서버까지 가지 않고 웹 캐시에서 request를 해결한다.
웹 캐시는 어떠한 원리로 오리지날 서버의 부담을 덜어줄 수 있는걸까?
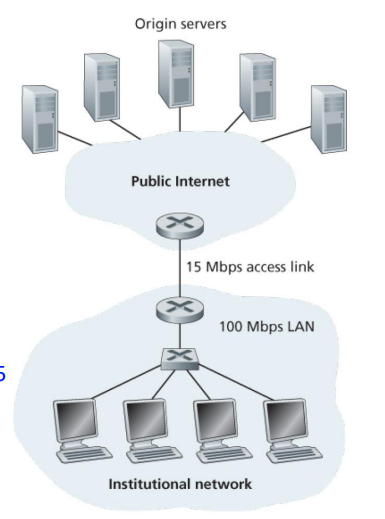
위 그림의 상황을 가정해보자.
LAN에서는 딜레이가 발생하지 않지만, access link에서는 딜레이가 발생할 확률이 높다. 이 문제점을 개선할 해결책 중 하나는, access link를 1Mbps로 향상시키는 것이다. 하지만 이 방법은 많은 비용을 요구한다.
이 상황에서 웹 캐시가 개설된다면,
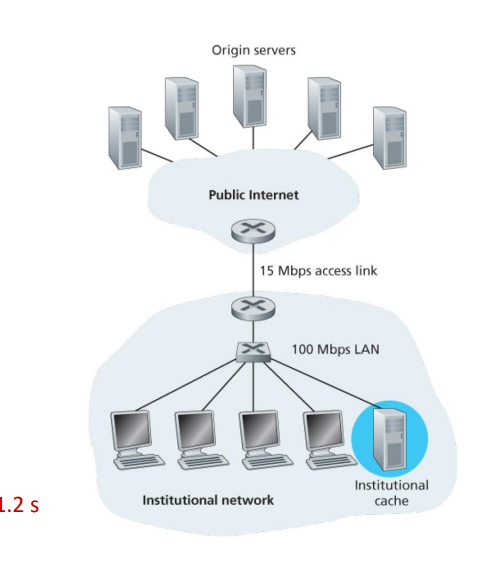
해당 웹 캐시가 전체 데이터 중 40%를 처리할 수 있다고 가정하였을 때, 해당 데이터들은 100Mpbs인 LAN안에서 처리가 가능하다. 하지만 웹 캐시가 전체 데이터 중 1%밖에 처리하지 못한다면, 효과는 미비할 것이다. 이러한 점에서 우리는 웹 캐시에 어떠한 정보가 들어가 있느냐가 institutional network 전체의 성능을 좌우한다는 것을 알 수 있다.
그렇다면 웹 캐시 안에 들어있는 정보는 어떻게 결정될까?
일단, 서버의 정보를 얻기 위해 캐시가 서버와 통신을 해야한다는 점은 당연하다. 이들 사이에서 통신을 할 때, 캐시는 http request 메시지에 가장 최근에 수정되었던 날짜를 첨부한다. 서버가 이 날짜를 수신하면, 해당 날짜 이후로 수정된 부분이 있는지 확인하고, 수정된 부분이 있다면 200 OK 메시지와 수정된 데이터를 전송한다. 수정된 부분이 없다면 304 Not Modified 메시지를 전달한다.
Electronic Mail
메일에 대해 본격적으로 알아보기 전, 메일의 구성 요소에 대해 설명하겠다.
메일은 메일이 오고 가는 것을 관리하는 'mail reader'의 역할을 하는 User agent, user로부터 오는 메일을 outgoing 큐에 넣고 메일을 전송하는 mail servers, 메일 전송 프로토콜인 SMTP로 구성되어 있다.
메일이 어떻게 전송되는지 알아보자. (SMTP또한 TCP를 이용한다.)
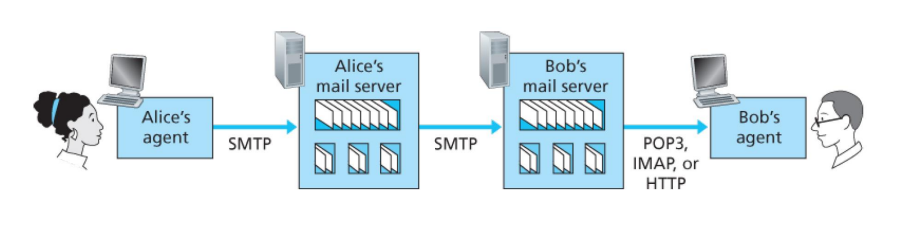
위 그림을 보면, 의문점이 생길 것이다. 왜 유저에서 유저로 직접적으로 메일을 전달하지 않는 것일까?
메일 서버는 수신자의 메일 서버가 응답할 때까지 반복적으로 메일을 전달할 수 있기 때문이다.
추가로, SMTP는 host에서 다른 곳으로 메일을 밀어넣도록 설계되었기 때문에 수신자의 서버에서 수신자의 agent로 데이터 전송 시에는 이용이 불가능하다.
이러한 이유로 해당 경로에서는 다른 프로토콜을 이용한다.
