SQL이란?
SQL(Structured Query Language)은 데이터베이스와 대화하기 위한 언어!
여기서 Query Language라는 것은 질의 언어로, 말 그대로 질의를 하기 위해 만들어진 언어입니다.
그럼 여기서 Structured 는 무엇을 의미하는가?
관계형 데이터베이스 시스템(RDBMS)에서 사용되는 질의 언어를 의미하기 위해 붙었습니다. 이에 대해서는 데이터베이스의 개념 부분에서 조금 더 알아보겠습니다.
데이터베이스의 개념
데이터베이스란?
: 데이터가 저장되어 있는 곳
데이터베이스와 테이블의 관계?
: 데이터 베이스가 폴더라면, 테이블은 데이터를 확인할 수 있는 파일에 해당!
위에서 말한 관계형 데이터베이스란?
- 관계형 데이터베이스란, 릴레이션(= 테이블)의 모임입니다. 그리고 관계형 데이터베이스에서 테이블은 데이터를 key - value 페어로 매핑하여 저장하는 집합입니다. 또한 각 테이블들은 관계를 가질 수도 있고, 관계형 데이터베이스는 이를 보장하기도 합니다.
- 테이블은 하나의 집합이기 때문에, 각각의 데이터들은 유일하며, 이 유일함을 표시해주는 것이 key의 역할입니다.
- 우리가 다루는 것은 관계형 데이터베이스에서 사용하는 질의 언어이므로 앞으로 나올 데이터베이스들은 모두 데이터가 key - value 형태로 매핑되어있는 관계형 데이터베이스라고 생각하면 될 것 같습니다!
테이블
엑셀 파일과 유사하게 생겼습니다.

여기서 테이블의 각 열을 컬럼 또는 필드 라고 부릅니다.
테이블들의 예시
-
테이블 목록
food_orders: 음식 주문 정보 테이블
customers: 고객 정보 테이블
payments: 결제 정보 테이블 -
food_orders 테이블의 컬럼 목록
order_id: 주문 번호 -- 이 컬럼이 위에서 말한 데이터의 key 값이 될 것입니다.
customer_id: 고객 번호 -- 음식을 주문한 고객을 표시하는 컬럼일 것입니다.
restaurant_name: 음식점 이름
... -
customers 테이블의 컬럼 목록
customer_id: 고객 번호 -- 이 컬럼 또한 데이터의 key 값이 될 것입니다.
name: 고객 이름
email: 이메일 주소
...
위 예시 food_orders 테이블의 customer_id 컬럼에 대하여
- 관계형 데이터베이스에서 테이블들이 관계를 가질 수 있다고 하였습니다. customer_id가 그걸 보여주는 컬럼입니다. customers 테이블의 컬럼 목록에도 동일한 이름의 컬럼이 존재하는 것을 볼 수 있습니다. 즉, customer_id로써 food_orders 테이블이 customers 테이블을 참조하는 구조인 것입니다.
- 이렇게 food_orders에서 customer_id를 참조할 때 이 컬럼을 외래키(foreign key) 라고 부릅니다.
외래키(foreign key)가 왜 필요한가?
- 나중에 학습을 하겠지만, SQL에는 조인(join)연산이라는 것이 있습니다. 그냥 이름만 같게하고 조인 연산 때려버리면 되지 왜 굳이 외래키라는 이름까지 붙여서 지정을 하냐~ 라는 의문이 들 수가 있습니다.
만약 단순히 조인 연산을 하게 된다면, 정상적인 데이터베이스 가정 하에 당연히 정상적으로 쿼리가 수행이 될 것입니다. 근데 이건 단순히 조회를 하는 기능이지, 관계의 존재 자체를 정의해주지는 않습니다!- 관계형 데이터베이스는 각 테이블들은 관계를 가질 수 있는데, 이 관계를 보장을 해주는 특징이 있다고 하였습니다. 외래키는 이 관계를 보장해주는 역할을 합니다.
데이터베이스와 관련된 목차라서 데이터베이스에 대한 내용 또한 조금 담아보았습니다.
하지만 당장 공부하는 것은 SQL이라는 언어이므로 더 자세한 내용은 따로 관계형 데이터베이스에 대한 게시글로 작성해보겠습니다.
SQL의 데이터 조회
SQL의 기본 구조(SELECT, FROM)
SQL의 가장 기본적인 구조는 SELECT와 FROM 입니다.
- SELECT: 데이터를 가져오는 기본 명령어입니다. 데이터를 조회하는 Query에 사용이 됩니다.
- FROM: 데이터를 가져올 테이블을 특정해줍니다.
아래와 같이 작성이 됩니다.
SELECT column1, column2, ...
FROM table_name위를 토대로, food_orders 테이블의 order_id, restaurant_name 컬럼을 조회하는 SQL 문은 아래와 같이 작성할 수 있습니다.
SELECT order_id, restaurant_name -- 조회할 column들을 나열
FROM food_orders;그럼 더 나아가서, 모든 컬럼을 조회한다고 하면 어떻게 될까요?
모든 컬럼을 조회하기 위해 모든 컬럼을 나열하는 것은 비효율적이고, 귀찮고, 불합리합니다. 이를 덜 귀찮게 하기 위해서 아래와 같이 SQL 문을 작성할 수 있습니다.
SELECT * -- 여기서 별표(*)는 대상 테이블의 모든 컬럼을 명세한다는 의미입니다!
FROM food_orders;컬럼에게 별명 붙여주기(Alias)
여기서, order_id, restaurant_name 컬럼을 조회하는 SQL의 실행결과를 살펴보겠습니다.
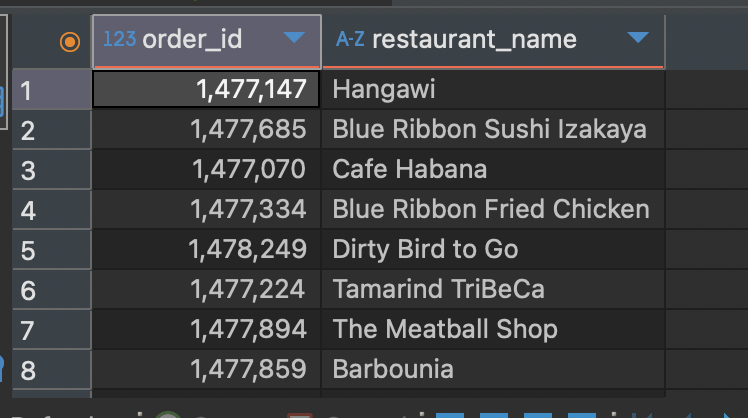
정상적으로 출력이 되고, 값도 잘 나오는데 보다보니 order_id와 restaurant_name이라는 이름이 마음에 안듭니다. 다른 이름으로 출력되게 하는 방법으로 두 컬럼의 이름을 바꿔서 출력을 해보겠습니다.
- 첫번째 방법
컬럼1 as 별명1 - 두번째 방법
컬럼2 별명2
SELECT 뒤에 나오는 컬럼들은 쉼표로 구분이 되기 때문에, 위와 같은 방식으로 컬럼에 별칭을 붙여 출력을 해줄 수 있습니다.
그리고 영어 또는 언더바(_)를 사용한다면 별명만 적어도 되고, 만약 특수문자 또는 공백, 한글을 사용할 것이라면 큰 따옴표(") 안에 적어주어야 합니다!
이를 참고하여 SQL 문을 작성하면 아래와 같습니다.
SELECT order_id as ord_no, -- 첫번째 방법으로 영어+언더바 별명 붙여주기
restaurant_name "식당 이름" -- 두번째 방법으로 한글+특수문자(공백) 별명 붙여주기
FROM food_orders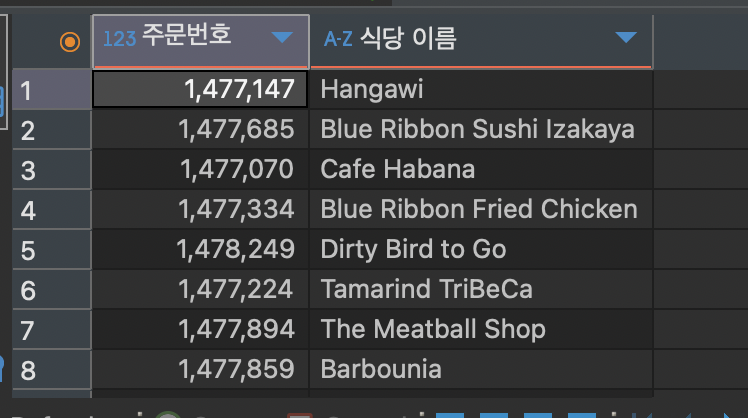
위처럼 컬럼명이 보기 좋게 출력이 되는 것을 확인할 수 있습니다!
기본 구조에 데이터 필터링 추가해보기
조건문으로 필터링을 해보자!
항상 모든 데이터만 필요한 것도 아니고, 질의를 하다보면 특정 조건을 만족하는 데이터를 얻어야 할 때도 있습니다. 그럼 특정 조건을 만족하는 데이터를 얻기 위해서는 어떻게 해야할까요?
정말 간단합니다! 위에서 사용했던 데이터 조회의 기본 구조 마지막에 WHERE 절만 붙여주면 됩니다.
SELECT column1, column2, ...
FROM table_name
WHERE <조건문>이제 예시를 들어서, 손님 중에 나이가 21살인 사람을 필터링하는 SQL문을 작성해보겠습니다.
SELECT * -- 데이터의 모든 컬럼 선택
FROM customers -- customers 테이블에 존재하는 데이터
WHERE age = 21 -- 나이가 21살인 사람을 의미하는 조건문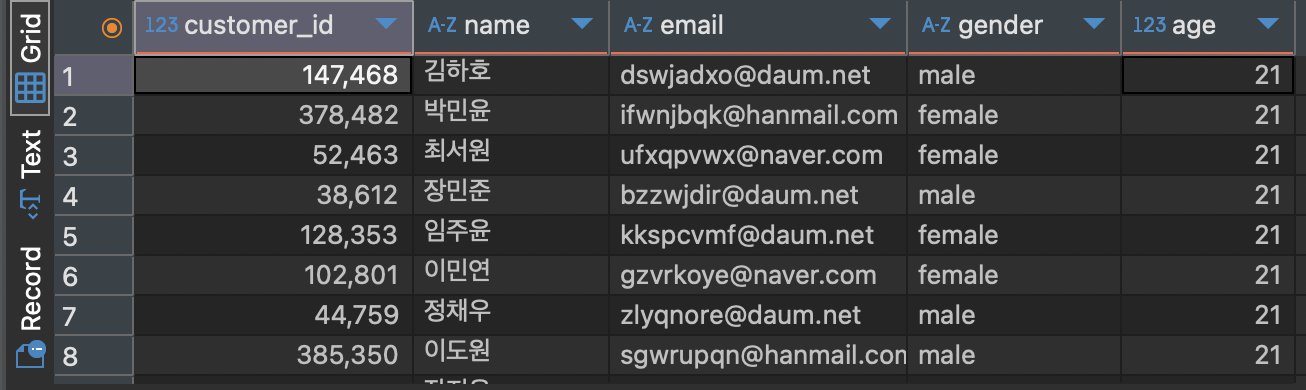
정상적으로 출력되는 모습입니다!
'='는 SQL에서 비교 연산을 수행!
- 다른 언어(c, c++, java, python 등)에서는 '='은 대입 연산자이고, '=='은 비교 연산자로 사용이 됩니다. 이와 다르게 SQL에서는 '='를 비교 연산자로 사용하고 있습니다!
- 데이터를 수정해야 할 때에는 다른 연산자가 아닌, UPDATE 문을 사용합니다.
그리고 위 예시처럼 숫자로도 필터링을 할 수 있지만, 문자로도 필터링을 할 수 있습니다!
다른 예시로 성별이 남성인 손님을 조회하는 SQL 문을 작성해보겠습니다.
SELECT *
FROM customers
WHERE gender = 'male'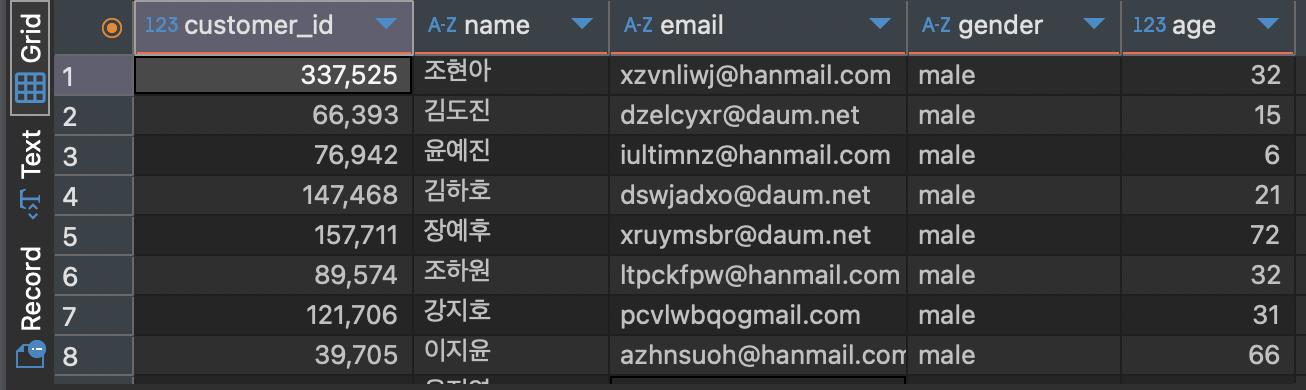
SQL에서 문자열은 작은 따옴표로!
컬럼의 별명 붙이기에서는 영어와 언더바(_)를 제외한 다른 문자(특수문자, 공백, 한글 등)을 사용하려면 큰 따옴표를 붙여야했습니다. 이와 다르게 조건문에 들어가 비교 대상이 되는 문자열은 작은 따옴표안에 넣어 주어야 합니다!
더 다양한 필터링 방법
기본적인 비교 연산자
조건문에서 비교 연산자로 사용되는 연산자들은 기존에 사용하던 언어들과 같은 것도 있지만, 다른 것도 있습니다! 이들을 정리해보면 다음과 같습니다.
| 비교연산자 | 의미 |
|---|---|
| = | 같다 |
| <> | 같지 않다 |
| > | 크다 |
| >= | 크거나 같다 |
| < | 작다 |
| <= | 작거나 같다 |
위에서 언급했던 '='가 비교 연산자로 사용되는 점, 그리고 같지 않다는 의미의 비교연산자가 '<>'라는 점에서 생소하니... 많이 써보면서 익숙해져야겠습니다.
BETWEEN, IN, LIKE
이건 다른 언어에서는 들어보지도 못했던 것들입니다.
이에 대한 설명은 다음과 같습니다.
- column1 BETWEEN A AND B: column1에서 A와 B 사이 값
- column2 IN (value1, value2, ...): column2에서 괄호 안에 있는 값에 해당하는 것
- 여기서, 괄호를 list라고 생각할 수도 있을 것 같습니다. 여러가지 값들을 제시하고 list 안에 포함되어있는지 여부를 구하는 연산과 유사해보이네요!
- value에 문자열을 넣게 된다면 당연히 작은 따옴표안에 넣어야 할 것입니다! - column3 LIKE value: column3이 value에 해당하는가?
IN에 대하여
- 이 문법에서 괄호를 list라고 생각할 수도 있을 것 같네요. 여러가지 값들을 제시하고 list 안에 포함되어있는지 여부를 구하는 연산과 유사해보입니다!
- value에 문자열을 넣게 된다면 당연히 작은 따옴표안에 넣어야 할 것 입니다.
LIKE의 value에 대하여
LIKE는 보통 문자열의 패턴 매칭에 사용됩니다. 그래서 value에도 문자열을 넣습니다. 문자열의 패턴을 매칭하는 데에 있어서 와일드카드를 사용합니다.
- '%': 임의의 가변 문자열을 대표
- '_': 하나의 문자를 대표
각각의 예시를 들어보겠습니다.
-- BETWEEN
SELECT *
FROM customers
WHERE age BETWEEN 20 AND 23; -- 나이가 20살과 23살 사이 라는 조건
-- IN
SELECT *
FROM customers
WHERE name in ('조현아', '김하호'); -- 이름이 조현아 이거나 김하호 라는 조건
-- LIKE (% 사용)
SELECT *
FROM customers
WHERE name LIKE '김%'; -- 성이 김이라는 조건
-- LIKE (_ 사용)
SELECT *
FROM customers
WHERE name LIKE '김현_'; -- 이름이 김현X에 해당한다는 조건필터링 조건을 여러가지를 사용해야 한다면?
항상 조건 하나만 가지고 데이터를 필터링 하지는 않을 것입니다. 그렇기 때문에 여러가지 조건을 작성하는 방법을 알아야 할 것입니다.
여러가지 조건을 작성할 때에는 논리 연산을 통해서 조건들을 이어주어야 합니다. SQL에서 사용하는 논리 연산을 표로 정리해보겠습니다.
| 논리 연산자 | 의미 |
|---|---|
| AND | 그리고 |
| OR | 또는 |
| NOT | 아닌 |
이를 활용해서 나이가 22살이면서(!), 성이 김씨인 사람을 조회하는 SQL문을 작성해보겠습니다.
SELECT *
FROM customers
WHERE age = 22 AND name LIKE '김%' -- 나이가 22살이며 성이 김씨라는 조건
논리 연산자의 우선순위
우선순위는 NOT > AND > OR로 가지게 됩니다.
만약,
조건1 OR 조건2 AND 조건3 OR NOT 조건4
이런 식으로 조건을 작성하게 되었다면, 다음과 같은 순서로 처리가 될 것입니다.
1. NOT 조건4 => 결과1
2. 조건2 AND 조건3 => 결과2
3. 조건1 OR 결과2 => 결과3
4. 결과4 OR 결과1 => 최종결과왜 그럴까?
우선, NOT은 unary operation에 해당합니다. 연산 범위가 좁기 때문에 가장 높은 연산 순위를 가지게 됩니다.
AND와 OR에 대해서는, 수학적으로 접근해보면 알 수 있습니다.
AND는 곱하기 연산에 해당하고, OR은 더하기 연산에 해당됩니다.
수학적으로 곱하기가 더하기보다 더 높은 우선순위를 가지기 때문에 AND가 OR보다 더 높은 우선순위를 가지게 되는 것입니다.내 의도는 어떻게 반영할 수 있을까?
위에 예시로 들었던 조건문에서 나는 조건1과 조건2의 OR 연산을 먼저 취하고 싶다! 라면, 아래와 같이 괄호를 사용하면 됩니다.
(조건1 OR 조건2) AND 조건3 NOT 조건4
자료 및 코드 출처: 스파르타 코딩클럽
