산술 연산 사용해보기
SQL에서도 사칙연산(+, -, *, /)을 사용할 수 있습니다!
SELECT customer_id, price * quantity -- price와 quantity를 곱해서 총 주문 금액을 조회
FROM food_orders;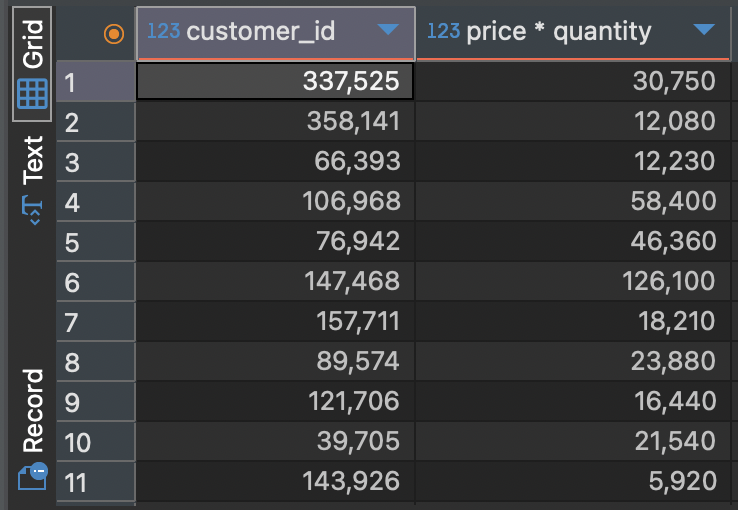
그런데, 가만 보니 SELECT 문에 작성한 연산이 그대로 컬럼명으로 들어가있습니다. 이전에 배웠던 컬럼에 별명붙이기(Alias)를 이용해서 조금 더 깔끔하게 출력을 해볼 수 있을 것 같네요!
SELECT customer_id, price * quantity as total_price
FROM food_orders;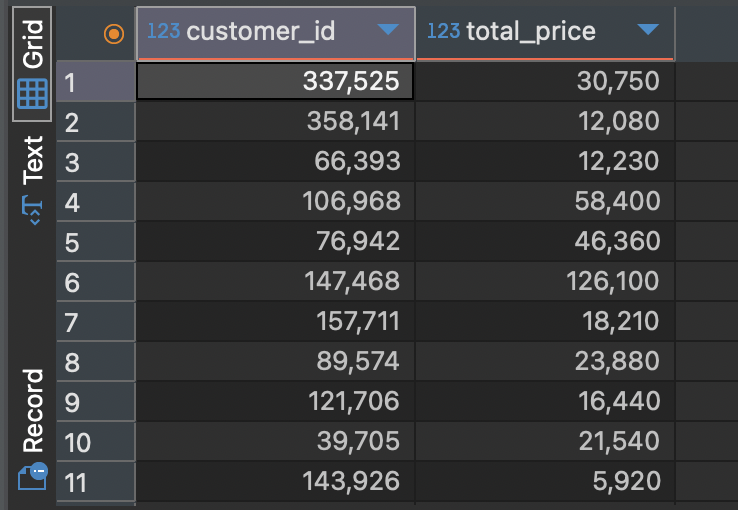
그리고 where 문에도 산술연산을 활용해서 데이터를 필터링 할 수도 있습니다.
SELECT customer_id, price, quantity
FROM food_orders
WHERE price * quantity < 30000 -- 총 주문 금액이 30000원 미만이라는 조건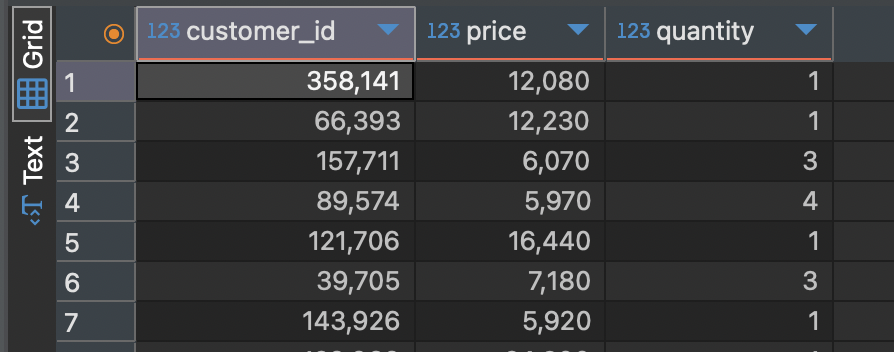
집계 함수
여러 개의 데이터 정보를 하나로 모아서 표현하는 함수입니다. 대표적인 것들을 표로 정리해보겠습니다.
| 함수 | 의미 |
|---|---|
| AVG | 평균 |
| SUM | 합계 |
| MIN | 최솟값 |
| MAX | 최댓값 |
| COUNT | 개수 |
이 함수들은 SELECT와 나중에 알아볼 HAVING 절에 사용할 수 있습니다.
왜 WHERE 절에는 사용이 불가능한가?
WHERE 절은 기본적으로 데이터 각각을 필터링하는 조건을 제시합니다! 하지만, 집계 함수의 특징은 여러 개의 데이터 정보를 하나로 모은다는 것에 있습니다. 데이터 하나하나를 필터링하는 곳에 여러 개의 데이터 정보를 모아서 결과를 낸다는 것 자체가 모순인 셈입니다.
AVG 함수의 사용 예시
SELECT AVG(age) -- 손님의 나이 평균
FROM customers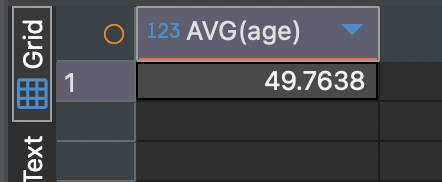
SUM 함수의 사용 예시
SELECT SUM(food_preparation_time) -- 음식 준비 시간의 총합
FROM food_orders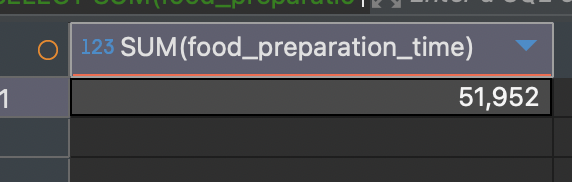
MIN 함수의 사용 예시 && MAX 함수의 사용 예시
SELECT MIN(price * quantity), MAX(price * quantity) -- 총 주문 금액의 최소, 최대
FROM food_orders
-- 이 예시처럼 함수 안에 산술 연산 또한 충분히 사용할 수 있습니다!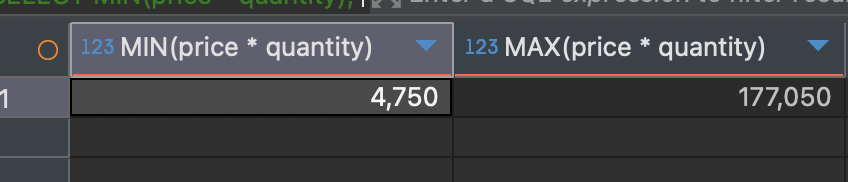
COUNT 함수의 사용 예시
어떤 테이블에 들어있는 데이터의 총 개수를 표시하고 싶을 때에는 COUNT(*) 또는 COUNT(1)을 사용합니다.
SELECT COUNT(*) -- food_orders 테이블에 들어있는 데이터의 총 개수
FROM food_orders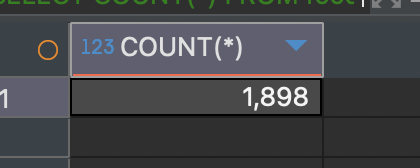
DISTINCT
만약 음식을 주문한 손님의 수, 즉, 같은 손님이 주문한 여러 개의 음식을 한 건으로 간주하고 싶을 때에는 DISTINCT라는 키워드를 사용하면 됩니다.
SELECT COUNT(DISTINCT customer_id)
FROM food_orders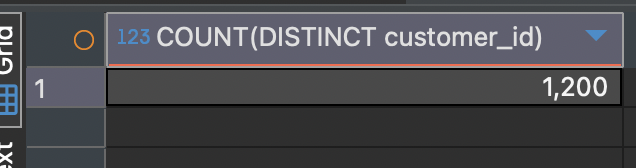
위에 출력된 COUNT(*)의 결과보다 더 작은 것을 보니 중복이 성공적으로 제거된 것 같네요.
SELECT에 집계함수를 사용할 때, 다른 컬럼은?
지금까지 배운 SQL 기본 구조의 SELECT 에서는 집계함수를 사용할 때 집계함수를 사용한 컬럼이 아닌 다른 컬럼은 사용할 수 없습니다. 이 또한 WHERE 절에 집계함수를 사용할 수 없는 이유와 동일합니다. SELECT customer_id를 적게 된다면, 조건에 맞는 각각의 데이터들의 customer_id가 출력이 될 것입니다. 하지만 집계함수는 여러 개의 데이터를 하나로 모은 것이므로 오류가 발생하게 됩니다.
하지만, 뒤에서 배울 GROUP BY와 사용한다면 이를 예외적으로 허용할 수 있습니다.
그룹화(GROUP BY)
만약 한국 음식의 총 주문 금액을 알고 싶다면 SQL문은 아래와 같이 작성할 수 있을 것입니다.
SELECT SUM(price * quantity) as total_price
FROM food_orders
WHERE cuisine_type = 'Korean'그런데, 만약 한국 음식 뿐만 아니라 다른 음식들의 총 주문 금액도 알고 싶어진다면 어떻게 해야할까요?
WHERE 절을 수정하는 것은 매우 번거로울 것이고, 결과도 하나하나 나오기 때문에 음식별 총 주문 금액을 한눈에 비교하기에는 좋지 않은 방법일 것입니다.
이럴 때 GROUP BY를 사용한다면, 이 문제를 해결할 수 있습니다. GROUP BY는 아래와 같은 형식으로 작성할 수 있습니다.
SELECT ...
FROM table_name
WHERE <optional>
GROUP BY column1GROUP BY라는 것은 직역 그대로 그룹을 묶는 것입니다. 예를 들어서 age로 그룹화 한다면 동일한 나이의 사람들이 하나의 그룹으로 묶일 것입니다.
위의 코드에서는
위에서 언급했던 것처럼 음식별 총 주문 금액을 출력하기 위해서는 cuisine_type으로 그룹화를 하면 될 것입니다.
SELECT cuisine_type, SUM(price * quantity) as total_price
FROM food_orders
GROUP BY cuisine_type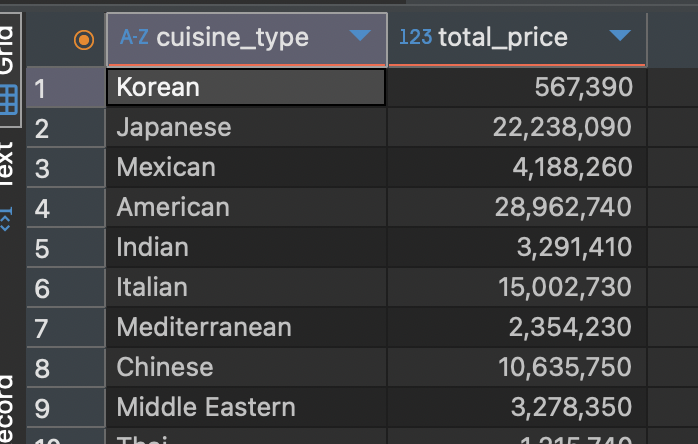
그룹의 조건문(HAVING)
GROUP BY를 한 이후 조건을 걸어줄 수 있습니다.
이는 그룹화된 데이터를 기준으로 동작합니다.
WHERE과의 차이?
| 구분 | WHERE | HAVING |
|---|---|---|
| 적용 | 그룹화 전 | 그룹화 후 |
| 집계 함수 | 사용 불가능 | 사용 가능 |
간단히 표로 나타내면 위와 같습니다. WHERE은 각각의 데이터에 대한 조건을 거는 것이었습니다. 그렇기 때문에 그룹화하기 전에 WHERE이 동작을 합니다.
즉, WHERE로 걸러진 데이터로 그룹화가 되는 것입니다.
HAVING은 그룹화된 이후에 동작을 하기 때문에 그룹화된 데이터들을 대상으로 조건을 작성하는 것입니다. 따라서 WHERE과 달리 각각의 데이터에 대한 필터링 작업은 하지 못하고, 그룹화된 데이터에 대한 필터링 작업을 할 수 있는 것입니다.
예시로, 수량이 한 개인 데이터는 제거하고 그룹화 함수로 음식 종류로 그룹화한 다음, 일정 금액 이상이 주문된 그룹만 출력하도록하는 SQL문을 작성해보겠습니다.
SELECT cuisine_type,
SUM(price * quantity) as total_price,
MIN(quanity) as min_quantity -- WHERE 조건이 제대로 적용되었는지 확인하기 위한 집계함수
FROM food_orders
WHERE quantity > 1 -- 수량이 2개 이상인 데이터에 대해서만 그룹화 적용
GROUP BY cuisine_type
HAVING SUM(price * quantity) > 2000000 -- 200만원 이상이 팔린 음식 종류만 출력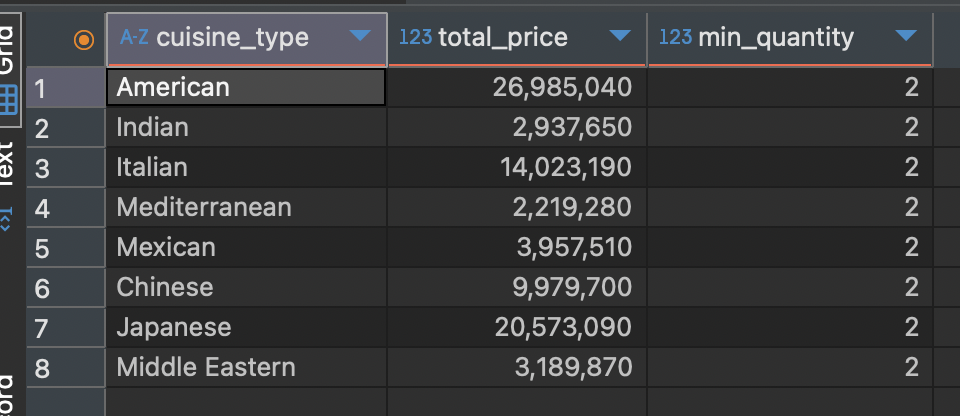
쿼리의 정렬(ORDER BY)
정렬이 필요할 때에는 ORDER BY를 이용하여 정렬을 할 수 있습니다.
정렬의 기준은 오름차순, 내림차순 두 가지가 있습니다.
| 구분 | 문법 |
|---|---|
| 오름차순 | ASC 또는 생략 |
| 내림차순 | DESC |
ORDER BY의 경우는 다음과 같이 작성하여 사용할 수 있습니다.
... -- 앞에 다른 구문을 먼저 작성한 다음 마지막에 작성합니다.
ORDER BY column1 (ASC / DESC) -- 정렬의 기준이 될 컬럼입니다.위에서 작성했던 쿼리를 오름차순으로 정렬하고 싶다라고 하면, 다음과 같이 작성할 수 있습니다.
SELECT cuisine_type,
SUM(price * quantity) as total_price,
MIN(quanity) as min_quantity
FROM food_orders
WHERE quantity > 1
GROUP BY cuisine_type
HAVING SUM(price * quantity) > 2000000
ORDER BY SUM(price * quantity) -- 아무것도 적지 않았을 시 ASC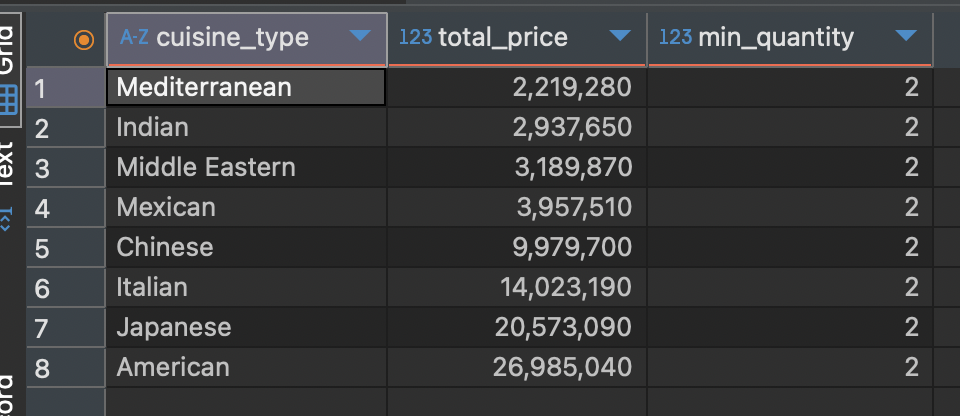
다중 정렬
어떤 컬럼을 기준으로 정렬을 하였는데, 같은 값의 결과가 나오는 경우가 있을 수 있습니다. 이 경우에는 다중 정렬을 이용하면 첫 번째 기준의 결괏값이 같았을 때 두 번째 기준의 결과로 정렬을 하게 됩니다.
ORDER BY column1 ASC, column2 DESC
예시로 위와 같이 작성을 해보았는데, column1이 오름차순으로 정렬이 되었는데, 그 결괏값이 동일할 때에는 column2를 기준으로 내림차순 정렬합니다.
자료 및 코드 출처: 스파르타 코딩클럽
