
AI 헬스케어 수업 일지 - 5일차: "정답 없는 세계" 비지도 학습(Unsupervised Learning)
👋AI 헬스케어 수업 5일차, 오늘은 드디어 비지도 학습(Unsupervised Learning)의 세계에 발을 들였습니다. 어제까지는 정답(레이블)이 있는 '지도 학습'을 배웠다면,
오늘은 마치 암호 해독가처럼 정답 없이 데이터 속에 숨겨진 진짜 보물을 찾는 법을 배우도록 하겠습니다!
"레이블 없이 배우기" 라는 이름처럼, 비지도 학습은 데이터의 패턴이나 구조를 발견하는 데 초점을 맞춥니다.
특히, 현실 세계처럼 데이터는 넘쳐나는데 일일이 정답을 달아주기 힘들거나 데이터가 너무 복잡해서 그 구조를 파악하고 싶을 때 최고의 무기가 됩니다.
오늘 배운 핵심 주제는 크게 두 가지입니다.
1. 차원 축소 (Dimensionality Reduction): 데이터의 복잡도를 줄여주는 마법!
2. 군집화 (Clustering): 비슷한 것끼리 자동으로 그룹 지어주는 기술!
자, 그럼 이 두 가지 핵심 개념과 그 속의 대표 알고리즘인 PCA와 K-Means, 그리고 계층적 군집화에 대해서 파헤쳐 봅시다!
.
.
.
.
오늘의 키워드를 말씀드리겠습니다.
- PCA (Principal Component Analysis)
- 고차원 데이터의 저주를 풀다
- K-Means Clustering
- 비슷한 것끼리 모이자
- 엘보우 기법(Elbow Method)과 실루엣 점수(Silhouette Score)
- Hierarchical Clustering
- 군집의 계층 구조를 파악
- Linkage Method와 Ward Linkage
- Dendrogram (덴드로그램)
- 계층적 군집화의 결과를 시각화로
1. 🔍 고차원 데이터의 저주를 풀다: PCA (Principal Component Analysis)
우리가 다루는 데이터는 종종 수백, 수천 개의 특성(Feature)을 가집니다.
이미지는 수만 개의 픽셀일 수 있고, 유전자 데이터는 수만 개의 유전자 정보가 있습니다. 이렇게 차원이 너무 높아지면 발생하는 문제가 바로 '차원의 저주(Curse of Dimensionality)'입니다. 이는 계산 비용이 폭발하며, 모델은 과적합되기 쉬워집니다. 그리고 무엇보다 우리 눈으로 시각화가 불가능해요! 이때 등장하는 구원투수는 바로 PCA(주성분 분석)입니다.
PCA (Principal Component Analysis)
: 고차원 데이터를 저차원으로 압축을 할때, 정보 손실을 최소화하면서
차원을 줄이는 최선의 방법입니다
PCA의 목표: 데이터가 가장 많은 정보를 담고 있는 방향, 즉 주성분(Principal Component)을 찾아 고차원의 데이터를 정보 손실을 최소화하며 저차원으로 압축하는 것입니다. 마치 3D 물체를 사진으로 찍을 때, 물체가 가장 잘 보이는 최적의 각도를 찾는 것과 같아요. 그 최적의 각도가 바로 '주성분'인 셈입니다.
🚀 PCA 작동 원리 (4단계)
- 데이터 표준화 (필수!): 각 특성을 평균 0, 분산 1로 맞춰 스케일 차이를 없앱니다.
- 공분산 행렬 계산: 특성 간의 관계와 데이터가 퍼져있는 방향을 파악합니다.
- 고유값/고유벡터 계산:
- 고유값은 그 방향으로의 분산(정보량) 크기입니다.
- 고유벡터는 주성분의 방향입니다.
- 상위 K개 선택: 고유값이 큰 순서대로(정보량이 많은 순서대로) 원하는 차원(K)만큼 주성분을 선택합니다.
여기서 주성분에 대해서 좀 더 자세히 알아보도록 하겠습니다.
주성분 (Principal Component)은 무엇인가요?
: 주성분은 데이터의 분산을 가장 효율적으로 포착하여 정보의 손실을 최소화하는 새로운 좌표축입니다.
중요한 성질
- 주성분들은 서로 직교 (perpendicular)
- PC1이 가장 많은 정보를 담음
- PC2, PC3, ... 순서로 정보량 감소
- 원래 차원 = 주성분 개수
예시
4차원 데이터 (Iris)
→ PC1: 73% 정보
→ PC2: 23% 정보
→ 두 개만으로 96% 설명!
📊 주성분 개수 선택의 기준:
Scree PlotPCA로 몇 차원까지 줄여야 할까요? 너무 많이 줄이면 정보 손실이 크고, 너무 적게 줄이면 차원 축소 효과가 미미합니다.
이때 필요한 것이 Scree Plot입니다.
Scree Plot은 각 주성분의 설명된 분산 비율(Explained Variance Ratio)을 그래프로 나타낸 것입니다.
- 해석: 그래프의 기울기가 급격히 꺾이는 지점(Elbow)을 찾습니다. 그 지점까지만 주성분을 선택하는 것이 일반적입니다.
- 일반적인 목표: 보통 85~95%의 누적 분산을 보존하는 선에서 주성분 개수를 결정합니다.
💻 PCA 실습 코드
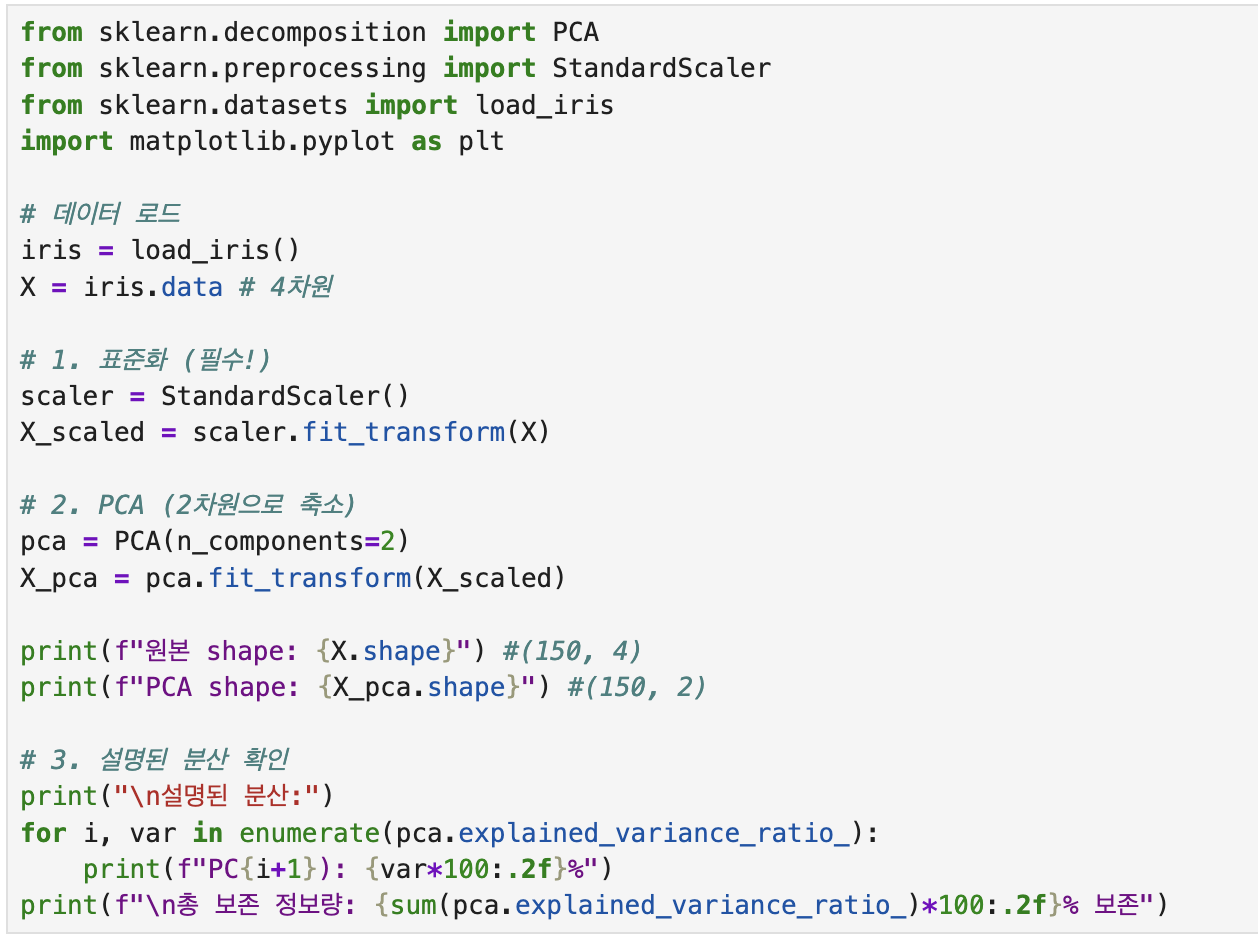
이걸 실행하면

이런 결과를 얻을 수 있습니다.
2. 🤝 비슷한 것끼리 모여라: K-Means Clustering
K-Means는 가장 유명한 군집화(Clustering) 알고리즘입니다. 데이터에 정답이 없을 때, 비슷한 데이터끼리 군집을 만드는 것입니다. 마케팅의 고객 세분화나 이상 탐지 등 실제 활용도가 매우 높습니다. 가장 간단지만 강력한 알고지즘입니다.
K-Means의 목표
- 미리 정한 K개의 중심점(Centroid)을 찾아, 각 군집 내 데이터와 중심 간의 거리 합을 최소화하는 것입니다. 다시 말해, '군집 내부는 가깝게, 군집 간은 멀게' 만드는 것이죠.
비유하자면, 학교를 K개 지을 때, 모든 학생이 가장 가까운 학교에 배정되도록 학교 위치를 계속해서 이동하며 최적의 장소를 찾는 것과 같습니다.
🔄 K-Means 알고리즘 (4단계 반복)
-
초기화: K개의 중심점(Centroid)을 데이터 공간에 랜덤으로 배치합니다.
-
할당(Assignment): 모든 데이터를 가장 가까운 중심점에 배정합니다 (유클리디안 거리 기준).
-
업데이트(Update): 각 군집에 할당된 데이터들의 평균을 계산하여 새로운 중심점으로 이동시킵니다.
-
수렴 확인: 중심점의 위치가 더 이상 변하지 않으면 종료하고, 아니면 2단계로 돌아가서 반복합니다.
K-Means 수식
Minimize Σ Σ ||xᵢ - μₖ||²
xᵢ: i번째 데이터
μₖ: k번째 군집 중심
||·||: 유클리디안 거리
해석을 하자면
각 군집에서 데이터와 중심 간 거리의 제곱합으로 표현되며
Inertia이라는 관성이 있는데 이 값이 작을수록 군집이 잘 뭉쳐있습니다.
### 💻 K-Means 실습 코드 및 최적 K 찾기
<K-Means 실습 코드>
이 코드를 실행해보시면
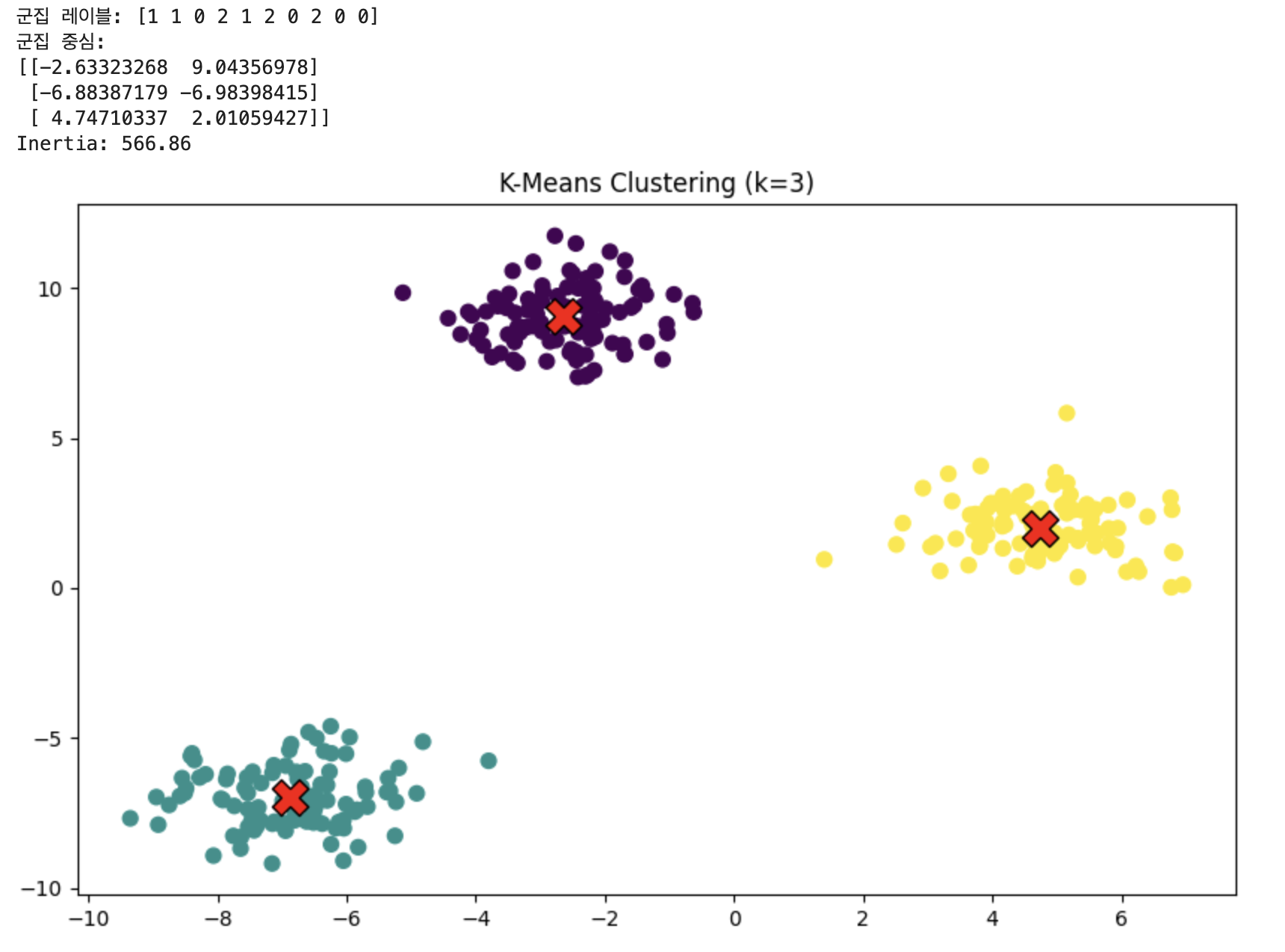
이러한 결과를 얻을 수 있습니다.
<최적 K 찾기>

이 코드를 실행해보시면
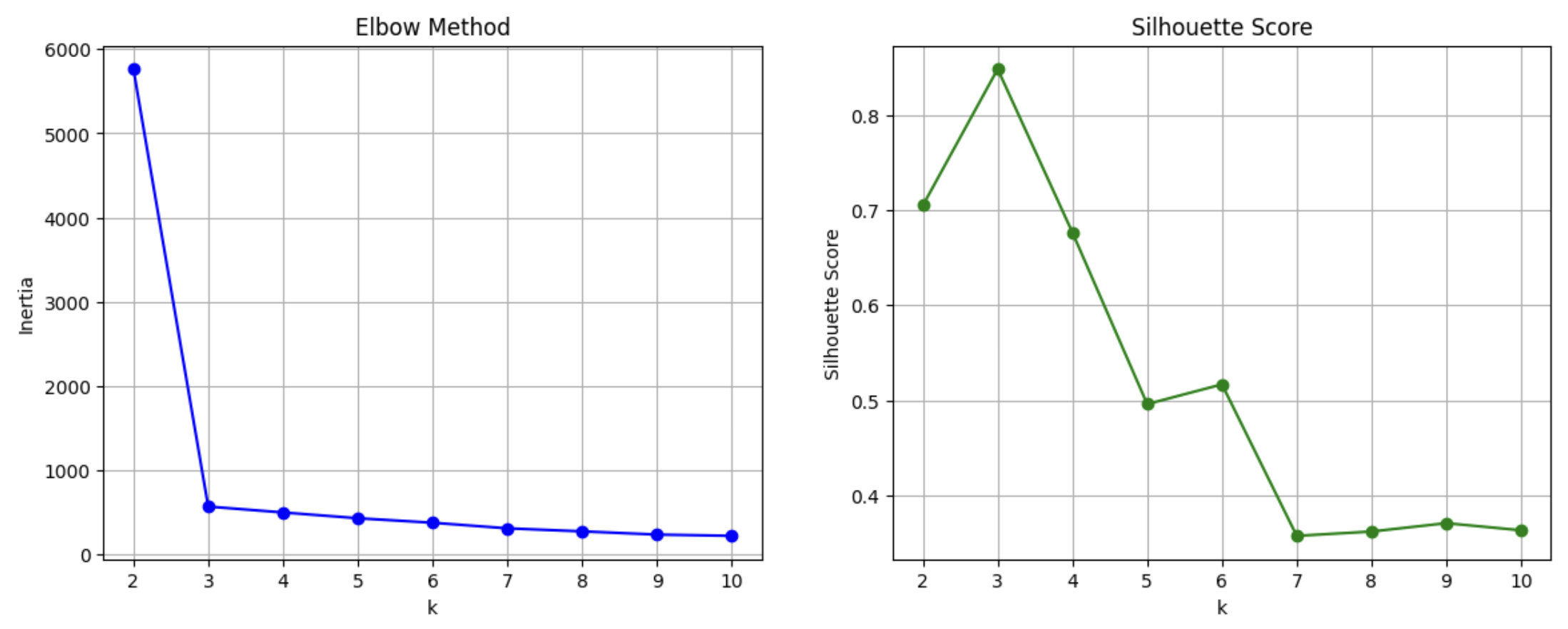
이러한 결과를 얻을 수 있습니다.
여기 최적의 K의 값을 찾을 때 엘보우 기법(Elbow Method)과 실루엣 점수(Silhouette Score)를 함께 보여주는 이유는 두 지표가 서로의 단점을 보완하여 가장 객관적이고 합리적인 값을 결정하기 위함입니다. 엘보우 기법은 직관적으로 보여주며 실루엣 점수로는 객관적보기 위함입니다.
엘보우 기법에서 최적의 K를 찾는 방법은 Inertia 값이 급격히 감소하다가 멈추는 지점, 즉 팔꿈치(Elbow) 모양이 되는 지점을 최적의 K로 선택합니다.
실루엣 점수의 범위는 -1 ~ 1 사이이며, 1에 가까울수록 군집 내 응집도가 높고 군집 간 분리도가 높다는 의미입니다. 이는 잘 군집되었다는걸 의미합니다.
두 지표를 함께 제시함으로써, '가장 직관적인 지점'과 '가장 객관적인 품질'을 모두 만족하는 값을 선정했다는 분석의 합리성을 강력하게 어필할 수 있습니다.
K-Means 장단점
장점
- 간단하고 빠름
- 확장성 좋음 (대용량)
- 구현 쉬움
- 해석 용이
단점
- K를 사전에 지정
- 초기값에 민감
- 구형 군집만 가능
- 이상치에 약함
- 크기 다른 군집 어려움
3. 🌳 군집의 계층 구조를 파악 : Hierarchical Clustering
K-Means는 K를 미리 정해야 하고 군집 모양이 구형(Spherical)일 때 잘 작동한다는 단점이 있습니다. 이러한 한계를 극복하고 싶을 때 계층적 군집화(Hierarchical Clustering)를 사용합니다.
계층적 군집화(Hierarchical Clustering)
군집의 계층 구조를 만들어가며 분류합니다.
K를 미리 정하지 않아도 되며 트리 구조로 전체가 파악이 되고, 원하는 수준에서 자르기 가능하다는 장점이 있습니다.
방식은 두가지가 있는데 Agglomerative(상향식)과 Divisive(하향식)으로 나뉩니다.
Agglomerative(상향식)
각 점을 하나의 군집으로
→ 가까운 것끼리 합침
→ 하나의 군집까지
Divisive (하향식)
모든 점을 하나의 군집으로
→ 멀리 있는 것 분리
→ 개별 군집까지
이 두가지 중에 가장 많이 쓰이는 것은 Agglomerative Clustering(상향식)입니다.
작동 순서는 4가지로 나뉩니다.
1단계: 초기화
각 데이터 = 하나의 군집 (n개)
2단계: 가장 가까운 군집 찾기
모든 군집 쌍의 거리 계산
가장 가까운 두 군집 선택
3단계: 합치기
두 군집을 하나로 병합
군집 개수 1개 감소
4단계: 반복
원하는 군집 개수가 될 때까지
또는 모두 하나가 될 때까지
이때, 군집 간의 거리를 어떻게 측정할 것인지를 Linkage Method라고 하는데, 군집 병합 시 분산 증가를 최소화하는 Ward Linkage가 크기가 비슷한 군집을 만들어서 가장 많이 추천됩니다.
Single Linkage
-
두 군집에서 가장 가까운 점 간 거리
-
긴 체인 형태 생성 경향
Complete Linkage
-
두 군집에서 가장 먼 점 간 거리
-
둥근 군집 생성 경향
Average Linkage
-
모든 점 쌍의 평균 거리
-
균형잡힌 결과
Ward Linkage
-
병합 시 분산 증가 최소화
-
크기 비슷한 군집 생성 (추천!)
Hierarchical Clustering 실습
이 코드를 실행하시면
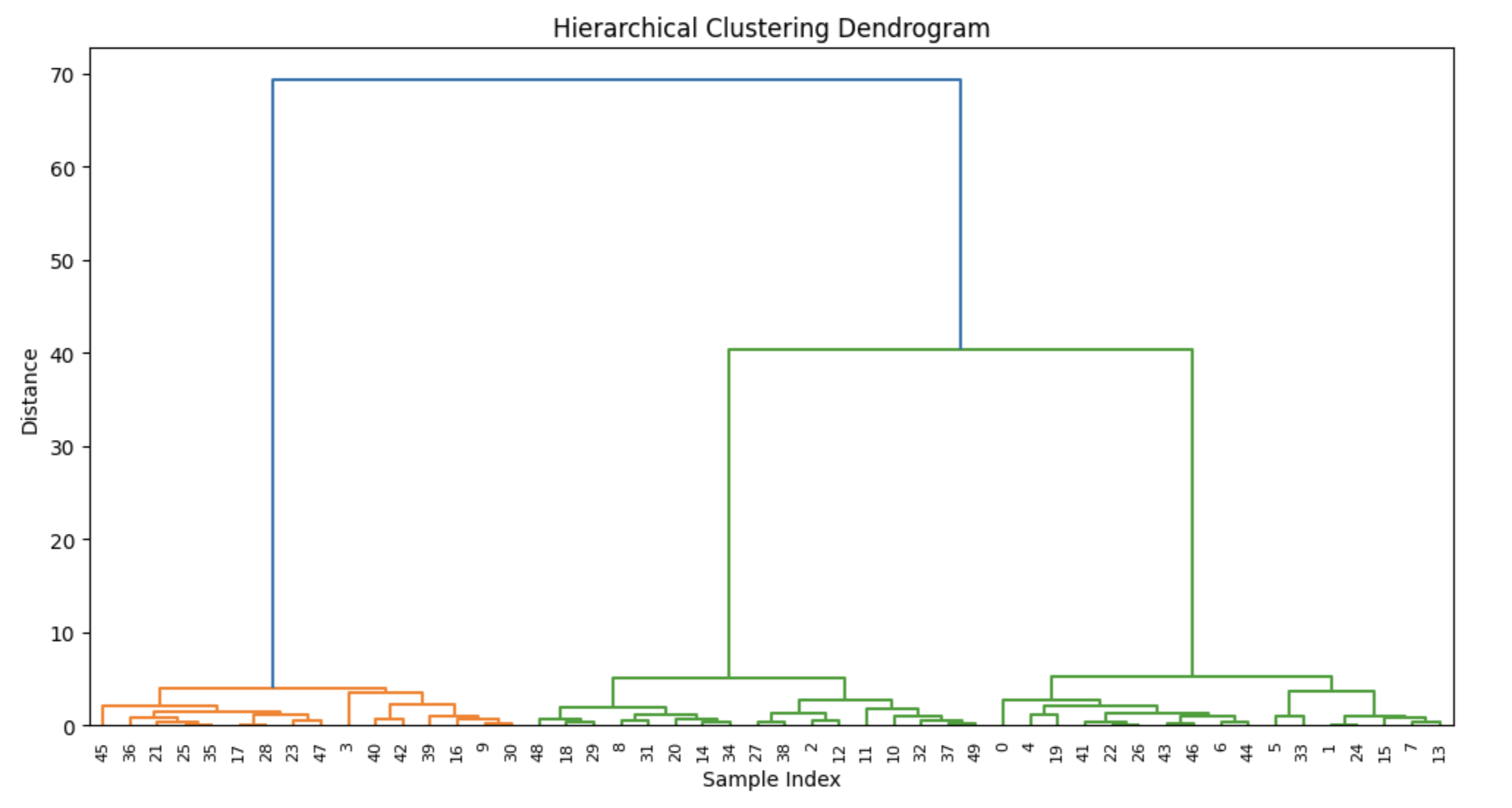
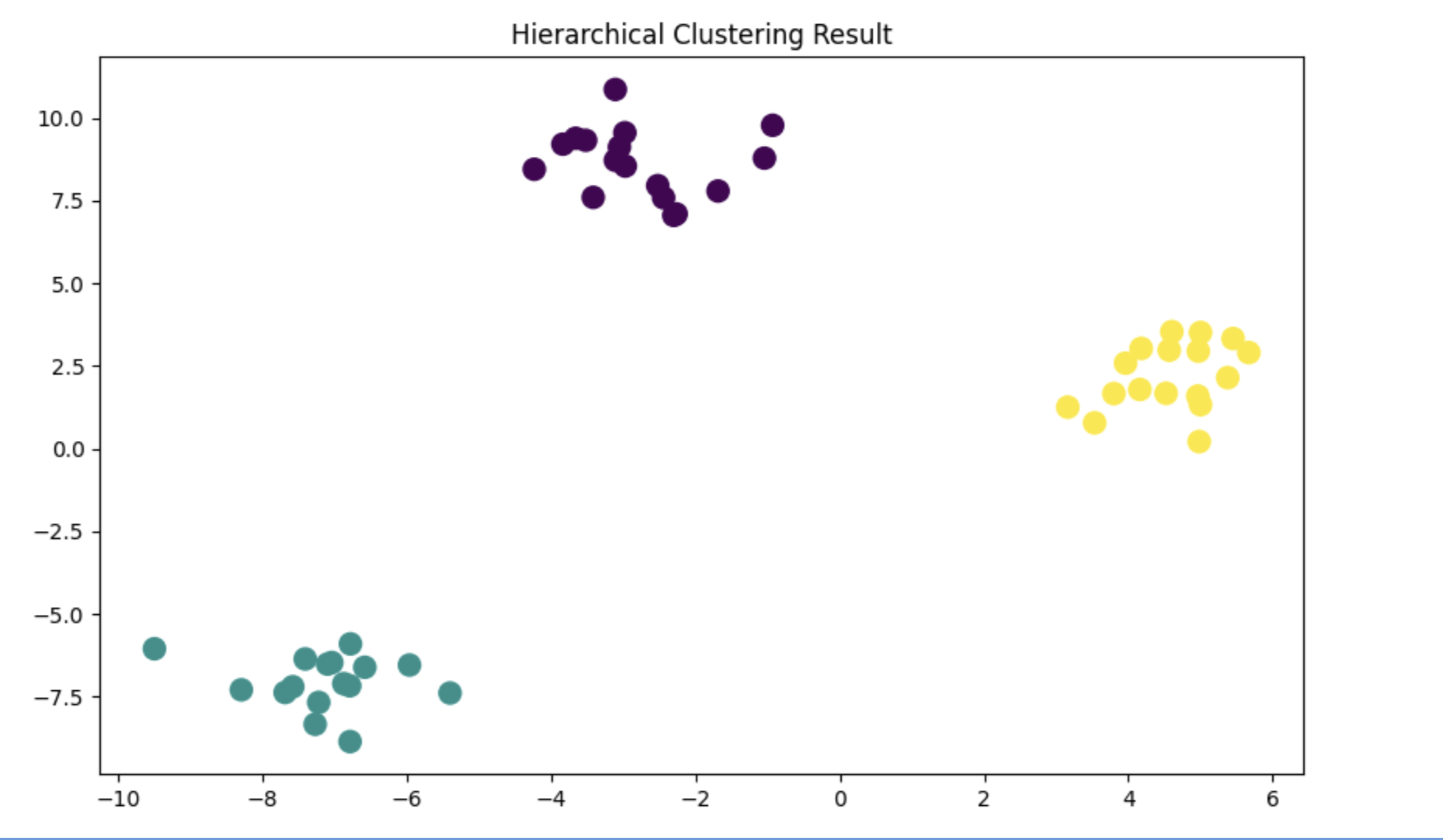
이런 결과를 얻을 수 있습니다.
Hierarchical 장단점
장점
- K를 미리 안 정해도 됨
- 계층 구조 파악 가능
- Dendrogram으로 시각화
- 다양한 모양 가능
- 결정론적 (재현 가능)
단점
- 느림 (O(n³))
- 메모리 많이 사용
- 대용량 데이터 어려움
- 잘못 합치면 되돌릴 수 없음
그럼 언제 사용해요?
• 데이터가 적을 때 (< 10,000)
• 계층 구조가 중요할 때
• K를 모를 때
🌲 Dendrogram (덴드로그램)
계층적 군집화의 결과를 시각화하는 핵심 도구이며
가로축: 각 데이터 포인트
세로축: 군집이 합쳐질 때의 거리 또는 유사도
가지 (branch): 군집이 합쳐지는 지점. 높을수록 멀리 떨어진 군집임
군집 개수 선택을 할때, 수평선을 그어 선과 만나는 수직선의 개수로 원하는 군집 개수(K)를 선택할 수 있으며 긴 수직선을 자르면 군집이 잘 분리된 지점을 찾을 수 있습니다.
🌟 오늘 배운 비지도 학습, 언제 써야 할까요?
| 특성 | K-Means | Hierarchical |
|---|---|---|
| K 지정 | 필수 | 선택 |
| 속도 | 빠름 | 느림 (O()) |
| 확장성 | 대용량 OK | 소규모만 (데이터 < 10,000) |
| 군집 모양 | 구형 | 다양 |
| 계층 구조 | 없음 | 있음 |
| 재현성 | 랜덤 (n_init 필요) | 결정론적 |
| 시각화 | 산점도 | Dendrogram |
군집화 평가
1. Silhouette Score
군집 내부는 가깝고, 군집 간은 멀게
-1 ~ 1, 높을수록 좋음
2. Davies-Bouldin Index
군집 내 거리 / 군집 간 거리
낮을수록 좋음
3. Calinski-Harabasz Index
군집 간 분산 / 군집 내 분산
높을수록 좋음
4. 시각적 평가
실제로 그려보고 판단
비즈니스 관점에서 의미있는지
핵심 메시지
"레이블이 없어도 배울 수 있다"
비지도학습의 힘
- 숨겨진 패턴 발견
- 데이터 이해와 탐색
- 차원 축소로 시각화
- 자동 그룹화
오늘 전 사실 수업을 잘 듣지는 못했어요..(꾸벅)
왜냐면 제 몸안에서 전쟁같은게 일어났기 때문에
열이 펄펄나고 그랬습니다.
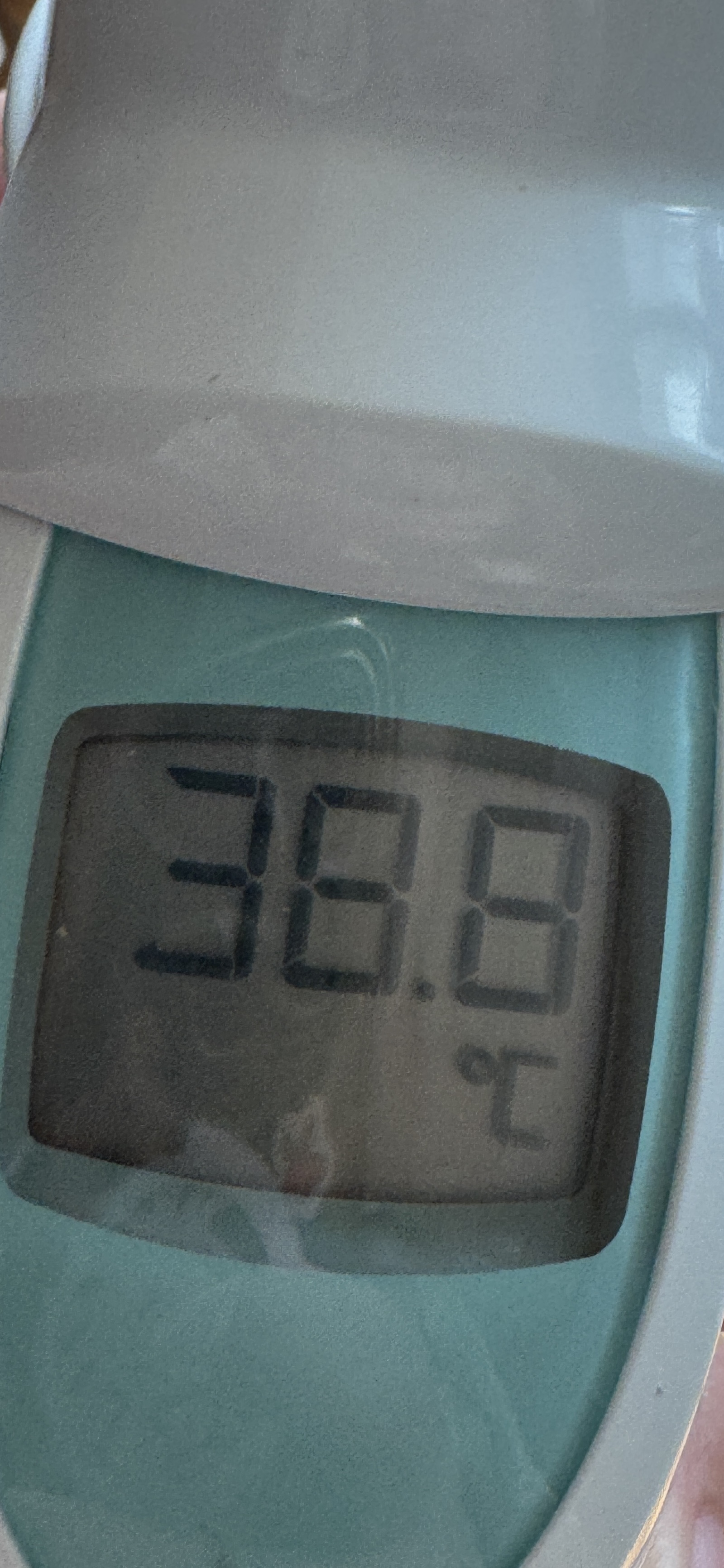
완전 TMI 사진이요. 저도 알아요.. 체온이 이게 말이되나 싶어서 머리골이 울리고 온몸이 쑤셔도 이건 찍어야된다 하고 사진 찍었습니다.. 그러고 약먹고 기절해버림
오후에 깨니 수업이 거의 끝나가더라구요
수업공간도 많이 바뀌어 있어서 깜짝 놀랐습니다. 크리스마스 느낌이 물씬~
저번 4일차 마지막에 보여드린 파워레인저 오늘부터 루돌프로 변신~ 다른 분들도 같이 찰칵 📸 (왼쪽 구석즈음에 찍힌 조교님 캐릭이... 예사롭지가 않다)
성탄절은 아직 한달도 더 넘게 남았지만 미리 크리스마스를 즐겨보는 것도 나쁘진 않은듯~

헉 완전 고열이었자나,,,??그럼에도 끝까지 남아서 블로그도 쓰고 진짜 대견해 당신... 아니 근데 그정도면 독감아니예여? ㅠㅠ