머리말
N사 입사 초기에, 회사내 IDC 인프라가 꽤 방대하게 구축되어 있지만,
구축되어 있는 내용에 대해서는 전혀 알지 못 하였다.
대부분의 내용이 엔지니어의 머리속에 존재하거나 개발 엑셀파일로 있어,
이 데이터에 대한 확인을 하는 것은 직접 묻거나, 파일을 받아야 하였다.
다행히(?) 서버에 대해서는 데이터가 웹상에 존재하긴 했지만,
그 마저도 검색을 불편하게 하여(정확히는 권한이 없..) 네트워크 엔지니어가
서버의 상태를 같이 확인하며 유기적인 트러블 슈팅을 하기 어렵게 하고 있었다.
그래서 나는 이 회사에서 일단 먼저 있는 서버 데이터 보다는,
현재 수집을 하지 않고 있는 네트워크 데이터를 수집하는 것이 우선이라 생각하게 되었다.
보안상 제작한 코드 내용 상세나 제작물에 대한 스냅샷등은 포함하지 않습니다. 양해 부탁 드립니다.
CMDB 시작
Network CMDB
네트워크 CMDB 의 주 목적은, 운영중인 네트워크 장비에 대한 데이터 수집이었다.
데이터는 크게 "기본" 데이터 와 "운영" 데이터를 나눠 생각하게 되었다.
-
기본 데이터
네트워크 자산 자체에 대한 데이터, OS 정보, 인터페이스 정보 등을 담았다. -
운영 데이터
ARP, MAC, Route 등 Data Plan 관련 데이터를 담았다.
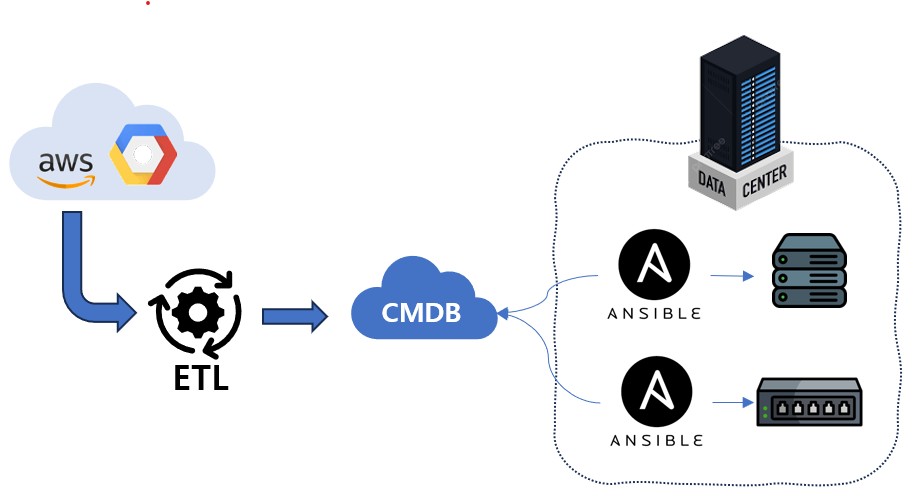
전체적인 구조는 아래와 같이 잡았다.
Frontend
기존 서버의 CMDB 서비스를 제공하고 있던 웹 UI 에 Network 관련된 데이터를 추가하였다. Vue2.js + Bootstrap 을 기반으로 하고 있었다. Code 는 엄연히는 Backend 역할을 하는 API 서버와는 분리되어 있었으며, axis 를 통하여 Django Backend 와 통신할 수 있도록 코드를 구성하였다.
Backend
크게 두 가지 파트로 나뉘어진 구조로 되어 있었다.
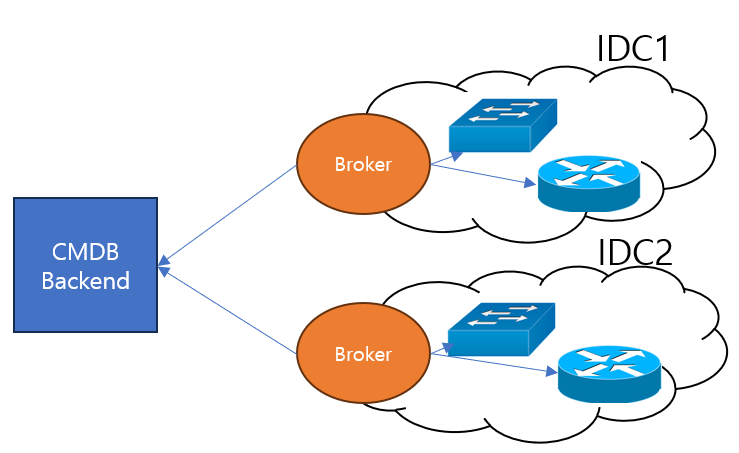
Broker

TextFSM: https://github.com/google/textfsm
textfsm 활용 예시: https://github.com/mybeang/networking/blob/master/textfsm_sandbox.py
IDC 가 크게 2개로 운영되고 있었는데, 시범적 운영을 위해 각 IDC 를 다른 형태로 Broker 를 운영하였다. 단, 기본적인 데이터 수집 방식은 Ansible 과 TextFSM 을 이용한 수집 방법을 활용 하였다.
- AWX
AWX (https://github.com/ansible/awx)는 Ansible Playbook 을 실행 관리 해주는 툴 정도로 이해 해도 무방하다. 유료 버전인 Ansible Tower 도 있지만, 비용절감(..)을 위해 무료 버전인 AWX 를 활용하게 되었다. AWX 에 있는 Inventory 의 Slicing 기능, 실행되는 Playbook 에 대한 병렬/직렬적 실행 및 실패된 Playbook 에 대한 관리 등의 기능을 주로 활용하였다. - Kubernetes Cronjob
Kubernetes 에는 Cronjob POD 가 존재한다. 이는 리눅스의 Crontab 의 그것을 Container 방식으로 돌리는, 어떻게 보면 단순한 기능이다. (물론 Container 화 하여 돌린다는 것과 이에 대한 관리를 해주는다는 것이 너무도 좋지만!). 파이썬코드로 Inventory를 유동적으로 생성할 수 있는 코드를 추가하여, AWX 처럼 많은 Inventory Host 에 대한 Sicling 을 구현하였고, 필요한 Node 에서 돌아가도록 Node select 를 통해 원하는 Broker Node 에서 실행되도록 설정하였다. 특이점이라면.. 모든 Container 가 Best Effort 로 동작하고, Broker 가 처리하는 데이터 크기를 가늠하기 어려워 가끔 Memory 가 모자른 에러가 발생하기도 하였다. 이는 Scale out 이나 Scale Up 으로 대처하였다.
CMDB 업그레이드(를 빙자한 새로 만들기?!)
왜 갑자기?

기존 CMDB 는 나름 인프라 운영 부서에서 잘 활용하고 있었지만, 그래도 문제점은 있었다.
내가 생각한 문제점 중 가장 큰 것은, 검색이 매우 불편하다! 인 것이다. 서버와 네트워크, 그리고 자산정보를 한번에 볼 수 없고 모두 각기 따로 봐야 했다. 뿐만아니라 이를 연결 짓기 위해서는 (당연한 것이지만) API 를 통해 데이터를 긁어와서 외부에서 따로 조합해주어야 했다.
데이터의 형태는 1차원 JSON 형태였다. 그리고 필드명은 가끔 알기 어려운 단어로 되어 있어서 뭘 뜻하는지 잘 모르는 케이스도 많았고, 필드를 추가하는 것도 꽤 어려웠다.
외부 이야기로는, 점점 데이터를 열람하는 속도가 느려졌다고 한다. 뭐.. 솔직히 내가 처음 썼을 때부터 느린 편이라 얼마나 느려진 건지 알 턱이 없었다. 그리고 기본 Framework 인 Django version 이 낮은 버전을 사용하고 있었으며, 사용하지 않는 모듈이 많아 군살이 참 많은 친구였다.
이왕 고칠거 새로 만듭시다! 로 의견이 다수가 되어 새로 만들게 되었다. 사실, 구버전을 뜯어 고치는 것 보다는 새로 만드는 것이 더 나을 경우도 꽤 많기 때문에...
처음에는 팀장님께서 리드를 시작하셨지만 과도한 업무로, 자진해서 PL 을 하겠다 말씀드렸다.
방향성
자산 데이터 관리
자산의 데이터를 기존 1차원 데이터가 아니라 다차원 데이터로 하자는 의견을 앞세웠다. 1차원 데이터로 하면 너무 데이터가 많아지고, 자산간 연결성이나 중복된 이름등에 대한 처리가 너무 어려워지기 때문이다. JSON 데이터의 Depth 가 생기며 자연스럽게 데이터 구조에 대한 이야기는 스무스 하게 흘러가게 되었고, 결국 자산이 갖고 있는 데이터 계층을 어느 정도 그대로 따라는 것이 어떻냐는 의견에 모두 동의 해 주었다. 구조는 아래 자세히..
그리고 가장 중요한 것은, 상세한 자산 내용은 분리해도 괜찮지만 전체 자산을 하나의 API 로 검색 가능하도록, 즉 한곳에서 관리 좀 해달라는 부서장님의 간곡한 명령(!?)이 있었다.

Django
기존 CMDB 는 Django 버전이 꽤 낮은 편이었다. (정확히 기억은 안나지만 메이저 버전이 다른..) 그리고 Django 가 갖고 있는 Webframework 의 파워를 거의 무시하고 새로 쓰는 수준이었다. 뭐.. 과거 Django 는 속도도 좋지 않고, 무겁고, 복잡했다.. 하니 그렇구나 싶었다. 그래서 Django 에 대해 잘 공부하고 제대로 활용해보자 라는 취지가 이번에는 나름 강하게 이야기 되었다. (글을 다시 쓰는 오늘 2025-04-01 기준으로 5.1.4 가 최신인데, 2023년 개발시작 버전은 아마 4.x 로 기억한다..)
특히, Django 의 ORM 을 거의 쓰지 않는 구조였기 때문에, 이번에는 ORM 을 적극적으로 활용하고, 특히, Serializer 에 대한 활용을 적극적으로 하자는 의견이 많았다.
Data 구조
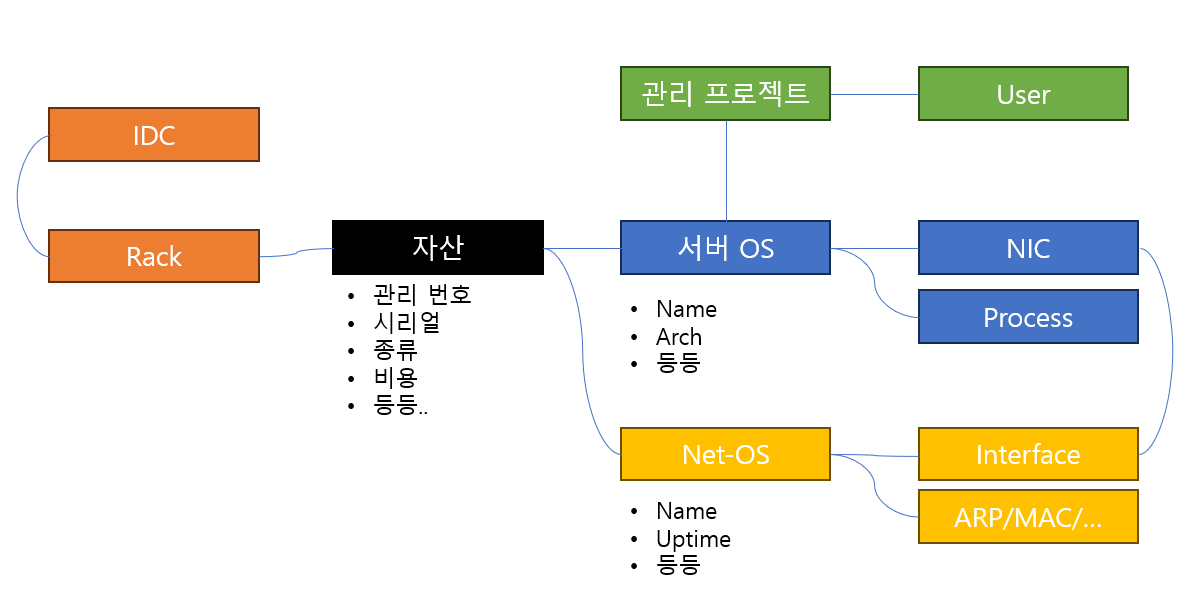
대략적은 구조이다. 자산을 관리하게 되며 해당 자산이 갖게 되는 데이터의 형태를 Layer 로 생각하고, 해당 Layer 에 맞게 Data 의 Depth 를 결정하였다. 이러한 과정에서 유리했던 것은 VM 들의 Host 와 Guest 의 관계성이었는데, 기존에는 CMDB 는 이를 검색하기 매우 까다로왔지만, 신규 버전에는 Host 에 어떤 Guest 가 있는지, Guest 는 어떤 Host 에서 구동 중인지 모두 표기가 됬으며, 이 또한 검색을 통해 확인할 수 있었다.
데이터의 큰 컨셉에 대한 의견 및 확립은 내가 진행했지만, 상세한 구조는 다른 팀원이, 지표는 관련 엔지니어분들이 진행하셨다.
Backend
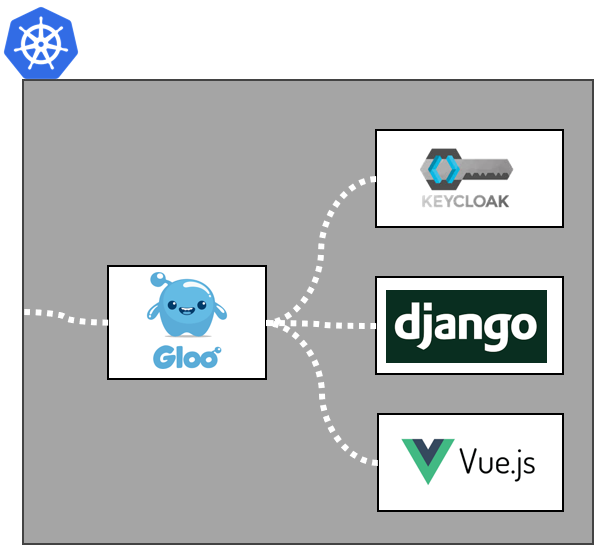
모든 서비스는 Kubernetes 기반에서 동작하게 되어 있었다. Django Backend 로 직접적으로 API 를 인가하는 경우는 없게 도록 하여 Gloo 에서 API Gateway 역할을 하며 동시에 인증 역할을 하도록 하였다. 인증은 Keycloak 에서 대리 담당하고 있었다. 권한은 API 및 Method 기반 시스템으로 별도로 구현하였다. (사실 Keycloak 을 잘 못 쓴다..) 뒤에 이야기 할 Frontend 또한 별도의 Container 로 관리되어, API Backend 와 Frontend 는 별도화 시켜 두 서비스가 잦은 패치로 인한 영향을 덜 받도록 하였다.
Data 입력 Rule
기존 CMDB는 Backend 에서 직접 원천 데이터를 획득해 오는 방식이었다. 이 방법이 옮지 않은 것은 아니지만, 그렇지 않아도 많은 기능과 데이터를 관리해야 하는 Backend 입장에서는 이는 너무 과부하가 아닐 수 없다

이에, 데이터 입력 Rule 을 정해 부서장님을 포함한 각 인프라 운영분들께 설득 및 전파를 하게 되었다. 요지는, 데이터를 CMDB 에서 원하는 형태로 정재하는 역할은 외부에 두고, CMDB는 데이터를 신뢰성 있도록 쌓아주자 라는 것이다. 사실 이는 ETL 의 기본이긴 하지만... 크흠..
각종 Data 입력
Manual
모든 Data 를 자동으로 획득하면야 좋겠지만, 그럴수는 없는 노릇이었다. 자동으로 얻기 위해서는 그에 따른 표준화와 IP 통신이 기본이 되어야 하는데, 그렇지 않은 경우도 많기 때문이다. 특히, 자산 입고의 경우가 그에 해당하게 된다.
따라서, 인프라 운영자들에 익숙한 Excel의 형식을 이용하여 데이터를 직접 입력하거나, 출력해 수정후 다시 입력 하는 형태의 서비스를 제공할 필요가 있었다. 이는 대부분 "물리 자산에 대한 데이터 Record 가 추가되는" 작업을 할 때 주로 많이 활용 되었고, 그것은 곧 자산 입고에 해당하여 해당 프로세스를 위한 기능을 추가 개발 하게 됬.. (개발거리가 누적이 되간다아)
Automation
마지막 확인한 서버 대수가 약 30K, 네트워크 장비는 약 8K? 정도로 기억한다. 이 데이터를 모두 수동으로만 입력하라고 하면.. 가능은 할 것이다. 한번에 입력하는 것이 아니라 업무진행에 맞춰 적게는 수대에서 많아야 몇십대 분량이니.. 다만, Public Cloud나 Private Cloud 의 Instance 는 다르다. Instance 또한 "논리 자산"으로 관리한다 라는 부서내 지침에 따라 해당 데이터를 CMDB에서도 다루게 되었는데, 이는 인프라 운영자들 모르게 생성될 수도, 혹은 삭제되거나 수정될 수도 있는 사항이었다. 이것을 매번 인프라 운영자들에게 수동으로 확인하여 데이터를 입력하라는 것은 지나친 과부하를 줄 수 있기 때문에 관련 부분은 자동화로 하며, 서버나 네트워크의 "운영 데이터" 또한 자동화로 가져오는 것이 바람직 할 것이다.
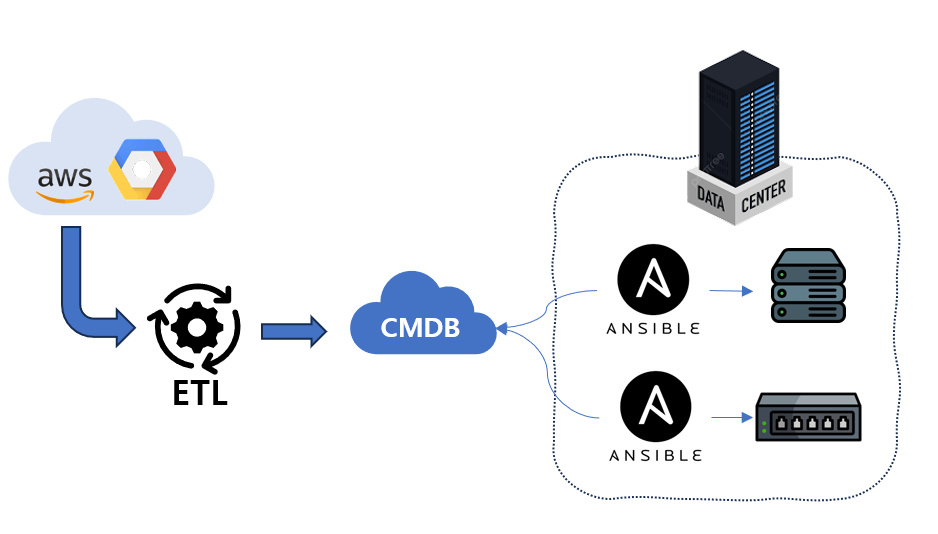
네트워크 운영 데이터는 기존 CMDB 에서 만든 모듈을 그대로 활용하였다. 서버 운영 데이터는 기존 CMDB 에서 서버 데이터 획득 자동화 담당자가 힘써주셨다. (고생하셨습니다)
Contribute Guide 와 API 표준화
기존 CMDB는 제대로된 Contribute Guide 없이 진행되어 코드가 보기 매우 어려웠다. 심지어, Directory 구조도 제각각이어서 메인이 되는 API 함수 찾는 것도 꽤 어려웠다. 이를 방지하기 위해 이번 CMDB부터 팀내에서 지켜야할 Contribute Guide 를 세웠다. 뭐 그렇다 해도 대부분 PEP8을 따르게 한 것에 불과하긴 하였다.
API 또한 API 문서를 만들기 위해 많은 시간을 투자해야 하는 것에 대한 불편함이 있어, Model 과 Serializer 를 통하여 간단한 CRUD의 API Doc 을 Generate 할 수 있는 모듈을 개발하여 개발 시간을 단축시키고, CRUD 또한 비지니스 로직이 간단한 것들은 Model/Serializer를 파라메터로 받으면 정상적으로 동작할 수 있는 것을 만들어 반복적인 작업에 대한 시간과 실수를 줄이도록 하였다.
권한 개발
인프라 운영부서의 CMDB는 인프라 데이터를 갖고 있는 만큼 보안 등급이 낮지는 않다. 관련이 없는 사람이 검색하여 특정 데이터를 볼 경우 보안적으로 문제가 발생할 수 있기 때문이다. 이에, RBAC 에 대한 정의를 하고, API URL + Method 를 이용한 권한 제어 모듈을 개발하였다. 이는 사실 Keycloak 으로도 충분히 가능하지만, 일부 Keycloak의 퍼포먼스에 대한 불신(!?)이 좀 있어 Local 에서 관리하면 좋겠다는 뉘앙스가 있어 그렇게 진행하게 되었다. (그렇지만 사실, Keycloak 도 관리 관련 정치적인 이슈도 좀 있었다)
API URL + Method 는 API 가 개발되면 자동으로 해당 목록이 DB 에 추가되록 개발하여, 개발 및 배포자는 배포 후 관련 Role 에 해당 API+Method만 Mapping 해주는 것으로 추가 작업을 최소화 시켰다.
Frontend

검색창
CMDB의 가장 중요한 역할은 바로 적재된 데이터를 쉽고 빠르게 검색할 수 있게 하는 것이다. 특히 데이터를 빠르게 보여주는 것에 대해서는 크게 2가지 파트로 나눌 수 있을 듯하다. 첫째는 API의 속도, 두번째는 데이터 랜더링의 속도.
전 CMDB 는 API 도 그렇지만 데이터 랜더링 속도가 많이 좋지 않아 다른 솔루션을 찾게 되었다. 그러던 도중 팀원분 한분께서 제안한 모듈이 있었으니..

엄청 파워풀한 녀석이다. Frontend 는 사실 프로젝트 리딩과 일부 부분에 대해서만 개발하고 Core 부분은 Frontend 담당자가 진행하였는데, 어느 정도 Core 개발 후 전달 받는 이녀석은 내가 생각한 내용에 대해 대부분 기능 제공을 하고 있었다. (심지어 무료 버전이었는데!?).
DataCenter
Private Cloud 를 운영하는 회사들 혹은 대행 업체들은 모두 공감하는 부분 중 하나가, 검색한 자산이 도데체 어디에 붙어 있는 것인지 알기 너무 어렵다! 라는 것이 있을 것이다. 최근에는 DCIM 이 매우 발달하여 (3D 로 된 것도 봤다) 그런 이슈는 많이 줄었지만, 개인적인 의견으로는, 이러한 데이터는 최대한 심플하고 알기 편하게 하는 것이 좋다 생각한다.
기존 CMDB에서는 Rack 의 형태를 이미지화하여 각 Layer 마다 어떤 장비들이 실장되어 있는지 확인 가능하며, 각 Rack 별 Power 를 확인할 수 있었다. 비록 CMDB 가 새롭게 단장한다 하여도 갑자기 이런 데이터를 없애 업무에 지장을 주게 하면 본말전도가 되기 때문에, 이에 대한 개발을 진행해야 했다.
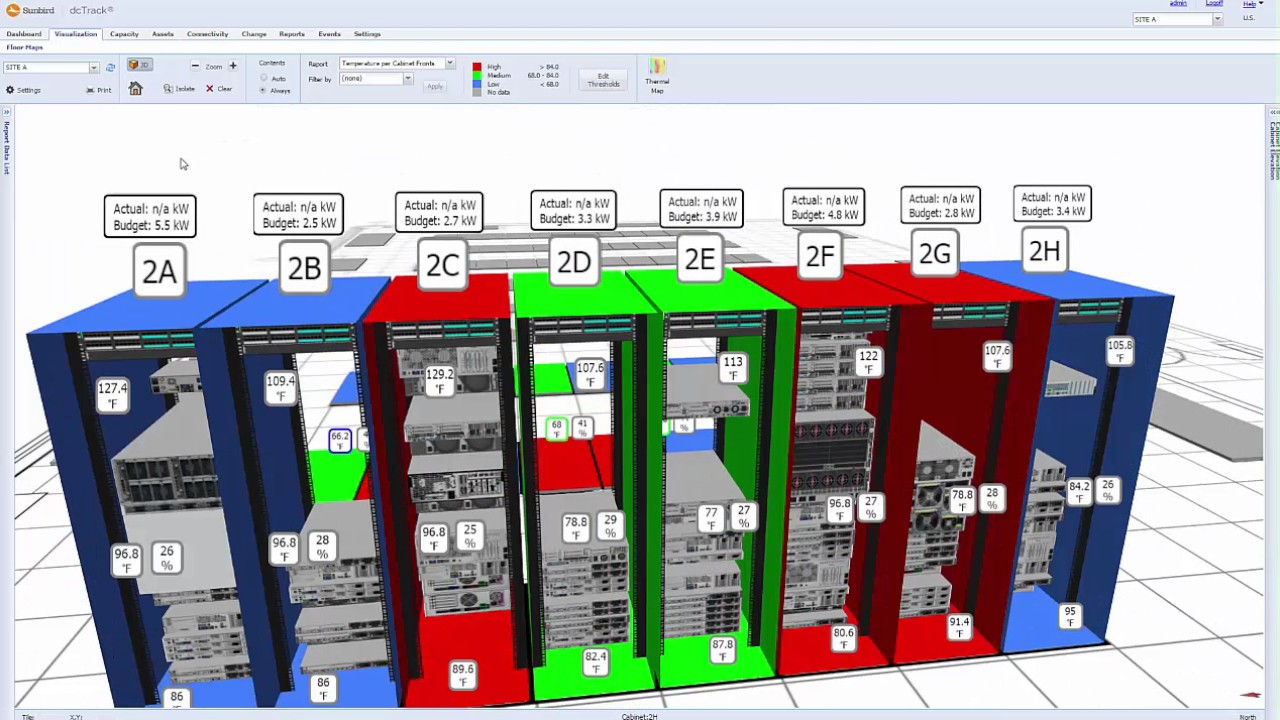
전문적인 UI/UX를 담당하는 분이 계시지 않아 공돌이들 머리속에 가장 좋다고 생각하는 이미지대로 만들어 배포하였지만, 솔직히 좋은 의견은 받지 못 하였다. 퇴사했던 그날까지 이 문제는 꽤 골머리를 썩다 해결하지 못 하고 나오게 되어 많이 아쉬운 상태이다.
결과
본 솔루션에 적응까지 꽤 긴 시간이 걸렸지만, 적응 후 인프라 운영자분들께서 해당 솔루션을 이용해 업무를 보거나, 별도 자신들만의 Script 에 CMDB의 데이터를 참고하는 경우가 많아지며 이용자(?)수가 많아졌다. 특히 장애 발생시 해당 서버/네트워크에 대한 검색이나 Backup 데이터에 대한 열람등은 많은 도움이 되었다고 전달받았다.
퇴사까지 최종 약 20K가 훨씬 넘는 서버수와 8K가 넘는 네트워크 장비의 데이터를 일 단위로 큰 문제없이 데이터 수집을 하는 나름 규모 있는 프로젝트 였다... 고 생각한다.
후기
전부 담을 수 없었던 내용인 만큼, 많은 일이 많았던 CMDB개발이었다. 직접 개발한 부분도 많고, 개발을 주도하거나 PR만 확인한 내용도 수두룩해 다시 혼자 만들어 볼 수 있을까 싶으면.. 할 수는 있겠지만 (더 잘 만들수도 있을수 있지만?) 부담스러운 부분도 많긴 하다. 처음에는 6명, 후기에는 3명정도를 이끌며 개발하며 프로젝트 리더로써 뭘 어떻게 해야하는지도 경험을 쌓은 좋은 기회였던 것 같다.
