머리말
본문은 개발/설계등에 대한 정리..라기 보다는 개발기(잡소리)에 가까운 블로깅이라 보면 좋을 것 같다. 기술적인 내용이 크게 적용될 만한 내용은 없는 프로젝트 였지만, 생각나는 대로 당시 생각하거나 본 페이지에 기술하지 못한 이슈들에 대해 추가는 할 예정이다.
입사
지난 네트워크 장비 제조사를 퇴사한 후, N 모사에 입사할 수 있는 기회가 생겼다.
추후에 듣기로는 "네트워크 이론을 아는 사람" + "개발을 할 줄 아는 사람" 의 밸런스가
가장 맞았다나 뭐라나... 지금도 마찬가지지만 나처럼 애매한 경력자도 없지 않을까 싶다.
경력이라 불러도 될지도 참 의문 스럽기도 하다.
여튼 그렇게 입사를 하였다.
첫 업무
입사 후 첫 업무(임무?!)는 Loadbalancer as a Service 의 Verion 2 개발이었다. v2 인 이유는 당연히 v1 이 있기 때문(ㅋ)
N 사는 다수의 Loadbalancer 장비를 사용 중이었고, 해당 장비에 설정하는 VIP 를 모든 장비에 들어가서 확인할 수 없으니 이를 하나의 솔루션에서 확인하고자 하여 Web service 형태로 "조회"를 위한 v1 이 이미 개발되어 있었다. 하지만 v1 에도, 당시 운영상에도 큰 문제점이 있었는데, 이는 운영 자동화가 아에 없는 LB 도 있고, 있어도 자동화 솔루션 버전(Openstack 의 Horizon 이었다)에 따른 민감성이 너무 커 함부로 LB 의 OS 의 버전을 업그레이드 할 수가 없었다.
나에게 내려진 임무는 이러한 민감도를 없애 별개로 운영가능하게 하며, VIP 의 조회, 설정등을 자동으로 할 수 있는 솔루션에 대한 개발을 요청 받았다.
근데 코로나가 뙇 !!?!
입사한지 얼마 안되 코로나가 터졌다. 개인적으로는 휴식기간 없이 이직한 것이라 코로나 시절의 재택근무가 약간의 리프레시 역할을 해주었긴 했지만, 이직 후 거의 바로 이러한 생활을 하게 되서 그런가.. 팀에 녹아 들어가는데 조금 힘들기는 했던 것 같다. 하지만, 뭐, 개발은 재택 가능하지... 그렇지?
시스템 및 구현
Frontend
Frontend 는, 부서에서 사용하는 언어 및 Framework 를 활용하기로 하였다. 본 부서에서는 Vue.js 를 이용하고 있었다. HTML 은 간단한 Tag 만 써보고, javascript 에 대해서는 전부한 나에게는 다소 난이도가 있었다. (지금도 어렵다)
약간, 상업 빌딩에 자리 한켠 전세 받아 장사하듯, 별도의 메뉴 하나를 받고 해당 메뉴 내에서 우리끼리 지지고 볶고 할 수 있도록, 해당 Framework 개발 부서에서 많이 도와주셨다.
기획 및 개발
순수 개발의 첫 스타트는 같이 개발 업무하는 담당자가 진행하였다. 그 친구는 Frontend 개발의 경험이 조금은 있었기에.. 그 친구가 나에게 원한 것은 개발 Backlog/Task/Issue 관리였던 것 같다. 관련해서는 적절히 조정하면서 진행하였다.
Frontend의 기획적인 부분은 그 친구의 의견을 많이 수렴했다. 아무래도 나는 Loadbalancer 라는 장비도 처음이고, VIP 운영도 처음이고, 그 친구는 v1 개발자이고, VIP 운영자이기도 하니..
추후에 들은 이야기지만, Scrum 운영도 그렇고, Sprint 완료 후 회고 시간도 그렇고, 프로젝트를 이끄는 것에 대해서는 큰 불만은 없었다 한다. (특히 회고 시간 갖는 것은 너무 좋았다 했다)
Backend

대부분의 프로세싱은 Python 으로 구현하는 것이 더 쉬웠기 때문에, Frontend 에서는 "데이터 의 형태" 까지만 잘 맞춰 던져주고, Backend 에서 이를 모두 처리하는 방식으로 구현되었다.
다만, 아직 Async 에 대한 구현 경험이 없고, 개념도 명확치 않았던터라 대부분의 모든 Logic은 Sync 방식으로 구현할 수 밖에 없던 것으로 기억한다.
목표 및 기획
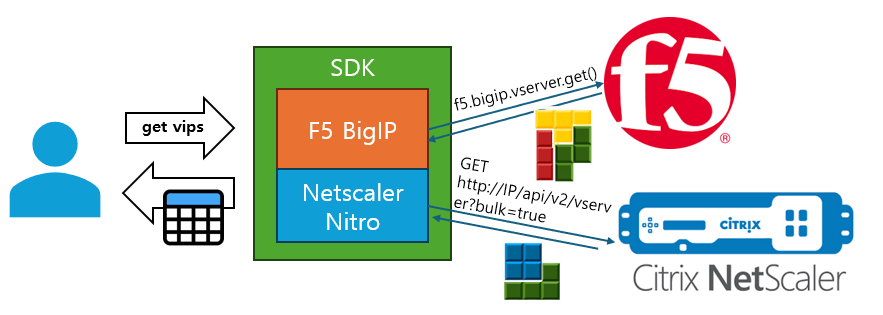
가장 큰 목표는 뭐니뭐니해도 여러 Loadbalancer 에 대한 추상화였다. F5의 BigIP 와 Netscaler 의 Nitro 에 대한 추상화가 필요하였다. 이 둘은 설정 개념 자체가 너무 달랐다.
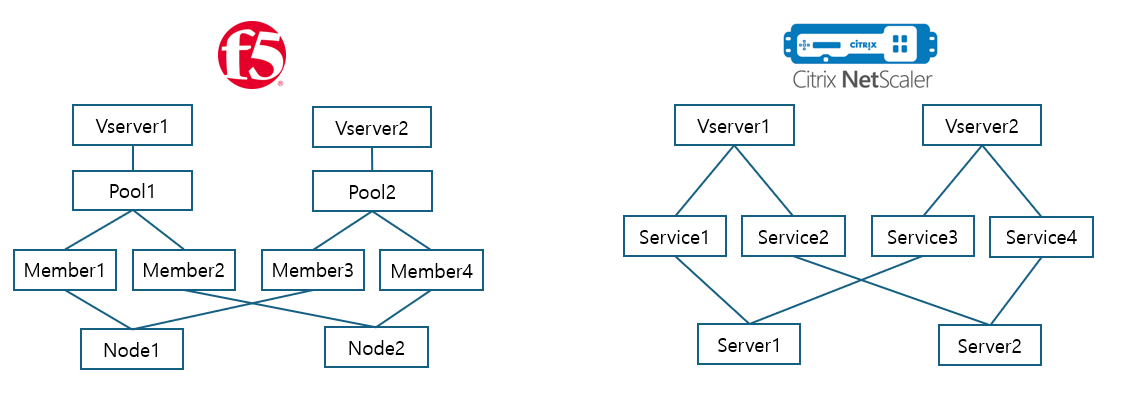
그리고 설정 관련하여, 최초 기획으로는 Loadbalancer 에 연결되는 Member Server 의 IP 대역에 따라 Loadbalancer 를 자동으로 선택하는 것, 데이터를 최소화 하는 것등 많은 부분을 사용자 입력없이 자동으로 추적/연산을 할 수 있게 기획 하고 있었다. (나중에 가서.. 결국 많은 부분이 사용자 입력으로 바뀌었다)
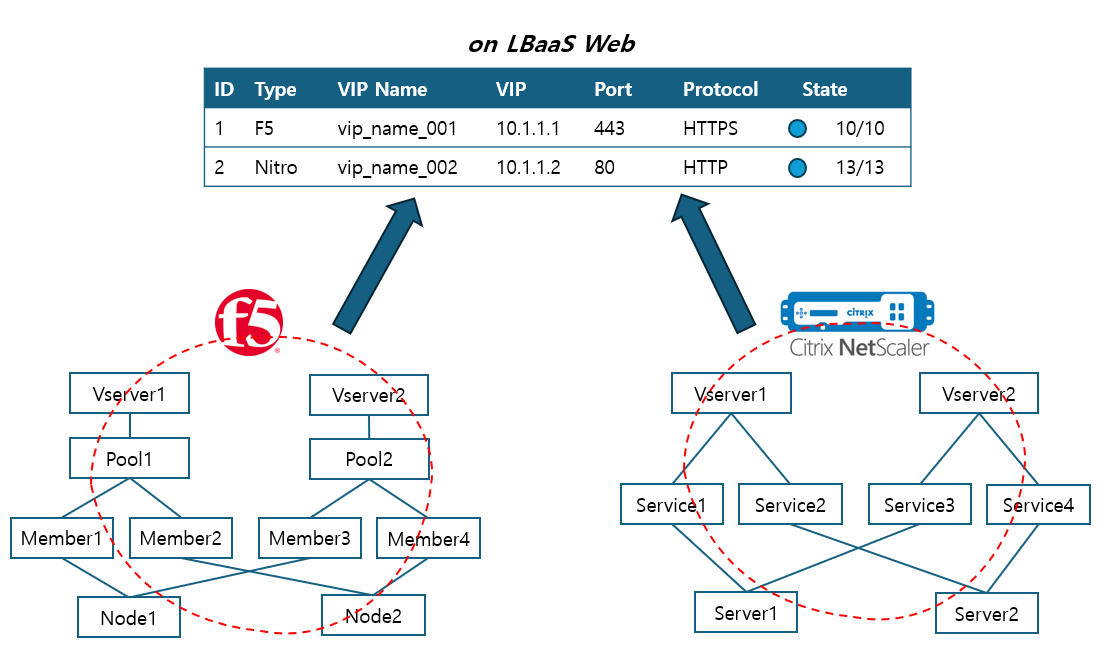
두번째 큰 목표는 "통합 조회"이다. v1 에서는 두 장비에 대해 따로 조회를 했어야 하여 하나의 VIP 를 찾는데 두 페이지를 동시에 접근하여 조회를 해야 했다. 이것을 통합하고 데이터를 하나의 형태로 보여주는 것이 또 하나의 목표였다.
개발

기본적인 Web Framework 는 Django 를 사용하였다. 회사 내에서도 Python 을 밀고(!?)있는 것도 있고, 개발 전문 팀에서도 해당 Web Framework 를 이용하고 있기 때문에 구태여 다른 언어 및 Framework 를 사용할 필요가 없었다. 또한 "보안"을 위해 API 접근 등에 대한 인증, 권한등에 대한 관리도 했어야 하는데, 이러한 기능에 대한 기반도 어느 정도는 잡혀 있었기 때문에 말 그대로 "잘 활용"만 하면 되었다. (나중에 이것도 그다지 좋은 방향이 아니어서 싹다 뜯어 고치긴 했지만..뉴비에게는 그저 감사할 따름..)
F5 장비는 Python SDK 가 이미 존재하여 해당 SDK 를 잘 활용하고, Netscaler 는 Nitro REST API 를 직접 활용하도록 하였다. 각 SDK 는 함수명을 동일 할지 언정, 이를 구성하는 Class 는 각 장비에 맞게 별도로 정의하였다. 지금와서는 그것도 그렇게 할 필요는 없었는데.. 5~6년전 개발력이니 지금보다는 당연히 좋진 않았을 것 같다.
# 대략 이런 식이었다
import requests
from f5_sdk import BigIp # 실제 SDK와 다르다!
class NetworkSession(object):
def __init__(self, endpoint, user_id, user_pw):
self.endpoint = endpoint
self.user_id = user_id
self.user_pw = user_pw
def get_vips(self):
pass
class F5Session(NetworkSession):
def __init__(self, endpoint, user_id, user_pw):
super().__init__(endpoint, user_id, user_pw)
self.f5_sdk = BigIp(endpoint, user_id, user_pw)
def get_vips(self):
return self.f5_sdk.vips()
class NetscalerSession(NetworkSession):
def __init__(self, endpoint, user_id, user_pw):
super().__init__(endpoint, user_id, user_pw)
self.auth = (self.user_id, self.user_pw)
def get_vips(self): # 실제 Nitro 사용법과는 다르다!!!
return requests.get(self.endpoint+"PATH", auth=self.auth)뭐 이것이 틀리다 맞다는 아니지만.. 좀 더 Python 스럽게? 개발자 스럽게? 할 수 있던 방법이 있지 않았을까 싶다.
첫 경험(!?)
Mysql

기존 회사에서는 별도로 DB 를 운영하지 않았다. 정확하게는 운영할 필요성이 없었다. Test Case 에 대해 실행만 하면 되는 것이라.. Test Result 를 별도의 ElasticSearch 에 담기는 했지만, ElasticSearch 내 담긴 데이터를 다시 Code 에서 활용할 일이 없었다.
LBaaS 에서는 VIP 에 대한 관련 데이터를 모두 DB 에 저장해야 했다. "다행히도" Django 에서는 ORM 을 제공하기 때문에 별도의 SQL 을 짤 필요는 없었지만, 그래도 처음 써보는 DB 는 나름 흥미로운 내용이 아닐수 없었다.
이를 위한 Modeling.. 을 해야 했지만, 사실상, Table 에 대한 간략한 정의만 할 뿐, RDB 의 Power 를 제대로 활용하지는 못 했다. (특히 fk 는 전혀 사용을 안했다)
데이터 량도 그렇고, 사전 정의한 데이터 정책의 덕택으로 그나마 무리 없이 돌아가긴 했다만, 지금 생각해보면 꽤 부끄럽게 활용한 것 같다.
가령...
table name : tb_vip
| id | name |
---------------
| 1 | vip_a |
| 2 | vip_b |
| 3 | vip_c |
table name : tb_member
fk; vip_id->tb_vip.id
| id | name | vip_id |
-----------------------
| 1 | mem_1 | 1 |
| 2 | mem_2 | 1 |
| 3 | mem_3 | 2 |
| 4 | mem_4 | 2 |
| 5 | mem_5 | 3 |보통은 이렇게 괸리 되지만..
table name : tb_vip
| id | name | members |
-------------------------
| 1 | vip_a | 1,2 |
| 2 | vip_b | 3,4 |
| 3 | vip_c | 5 |
table name : tb_member
| id | name |
--------------
| 1 | mem_1 |
| 2 | mem_2 |
| 3 | mem_3 |
| 4 | mem_4 |
| 5 | mem_5 |이렇게 관리 되었다. (사실 members 도 tb_member 의 id 가 아니라 이름으로..)
그래도 unique key 나 primary key, index 관리 정도는 했...던 것 같다.
차기 버전에서는 RDB 스럽게 잘 사용하였다. (차기버전에서 언급하겠다)
Django

https://www.djangoproject.com/
전 회사에서는 Django 를 아주 맛보기로만 사용했지만, LBaaS 개발에서 부터는 나름 제대로 활용하였다. Web Framework 에 대한 사용도 처음이었고, API 서버를 개발하는 것도 처음이었다.
개인적으로는 Django 는 Python 을 시작하며 Web Framework 를 처음 접하는 뉴비들에게 참 적합한 모듈이라 생각한다. flask 도 있지만, flask 는 묘하게 db 쓰는게 어렵다고 해야할까.. 사실 ORM 이 가장 큰 요인이기는 하다. flask 에서도 orm 을 활용해서 개발이 가능하지만, orm 정의부터 엔진까지 스스로 개발해야하는데 반해 (왠지 plugin 이 있을 것 같긴 하지만) django 는 기본적으로 modeling 과 serializer 를 통한 data 화등도 제공하고 있고, rest-framework 를 같이 사용하면 REST API 화 하는 것도 어렵지 않다. 많은 plugin 이 존재하며, 문서화도 잘되어있고, 본인이 만든 API 서버에 대한 문서화를 돕는 plugin 도 많아 운영에도 장점이 많은 것 같다. 대신, 아무래도 flask 나 fast api 등보다는 많이 무겁다는 점이 있다.
Loadbalancer
기존 회사에서는 L2/L3 를 위주로 했으며 L4 는 ACL이나 Emulator 를 이용한 TCP 통신 테스트 등으로만 해보았다. 물론 Loadbalancer 에 대한 존재는 알고 있었지만, 사실상 처음 접하는 개념이기는 했다.
일반적인 Loadbalancer 장비는 Reverse Proxy 를 기반으로 하고 있다.
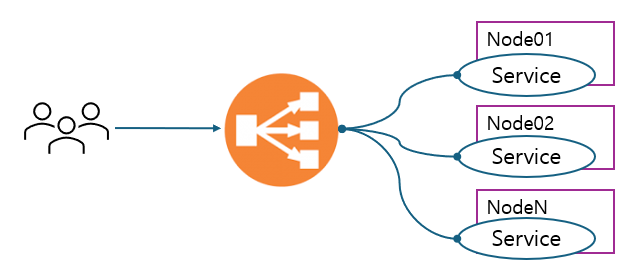
대표적인 모듈로는 nginx 가 있겠다. 동일한 서비스를 운영하는 여러 서버에 서비스를 분산하는 것을 주 역할로 하고 있다. 인프라적으로는 뭐.. one-arm mode 라던가.. inline mode 라든가, nat 를 해야한다거나 등.. 여러 가지를 알아야 하고, 내부 기능으로도 x-forwarded-for 등 기능이 다양하지만, 여러 인터넷 블로그에 잘 정리된 부분들이 많으니 굳이 여기서는 이야가 하지 않겠다 (잘 몰라서 그런게 아니야!..아마도..)
이슈들
Polling Model
가장 큰 Needs 중 하나가, LBaaS 를 통하지 않고 장비에 직접적인 설정을 하여도 설정된 내용이 화면에 잘 보이면 좋을 것 같다 <- 라는 것이었다. 이는 곧, 장비 설정 자체가 Origin Source 가 되고, 이를 바탕으로 데이터를 정형화 해야 한다는 이야기 이다. 자연스럽게 서비스는 Polling Model 을 이용하게 되었다.
Polling 주기는 5분으로 하여 VIP 의 State 에 대한 변화를 되도록 짧은 단위로 확인하려고 노력하였다. 그로 인해 5분마다 "모든 데이터"를 가져와야 하는 불상사(!?)가 생기게 되었다. 지금에 생각해서는 데이터를 가져오는 모듈을 여럿 만들어 데이터의 성격에 맞춰 시간을 달리 하면 보다 쾌적하지 않았나 싶지만.. 이러기엔 또 다른 이슈가 있긴 하다 (후에 다루겠다)
데이터를 획득하는데 있어서도 문제가 있었다. 장비에 많은 VIP 가 설정되어 있는 경우 데이터를 가져오는 시간이 꽤 걸린다는 점이다. 이것이 뭐가 문제인가? 아래 그림을 보면 쉽게 이해 된다.

당장에는 문제 없었지만, VIP 를 생성한 사람의 입장으로는 바로 확인하는 것이 아닌 최소 5분~10분 뒤에 확인해야 하는 "불편함"이 있었다. 물론 데이터 획득이 최소 2~3회 진행되면 데이터는 문제 없이 보이긴 했지만, 이는 VIP 를 설정하는 유저(엔지니어)가 적어서 그런 것일 뿐, 유저가 많아지면 심각한 문제를 초래할 수 있는 부분이기도 했다.
Session
LBaaS 를 운영하며 Netscaler 장비의 운영 방식이 변경되며, 장비 접속 Session 에 대한 이슈가 발생하였다. 기존에는 "default" partition 만 사용하다가, 이후 다수의 partition 을 사용하면서 이슈가 물위에 올랐다. 여기서 Netscaler 의 Partition 개념은 간단히는 Docker Container 와 비슷하다 보면 된다. Hardware Resource 는 공통적으로 사용하되 "VIP 설정"에 대한 리소스는 논리적으로 분리하여 사용하겠다 라는 이야기 이다. 장비별로 VIP 를 관리해야 하는 LBaaS 의 데이터 성격상, 모든 Partition 에 접근하여 VIP 설정을 받아와야 했는데, 이는 1대의 Loadbalancer HW 장비에 10개의 Partition 을 설정해 운영한다면 10개의 Session 을 이용하여 접근해야 한다는 것이다.
이것이 왜 문제가 되었는가? Netscaler 에서 한번에 열 수 있는 Session 개수가 정해져 있었다. 이는 Rest API, SSH 등에 상관 없이, TCP Session 개수에 기반하여 관리되고 있었다. 즉, 최대 12 session 이라 가정시, Partition 을 12개를 운영한다면 데이터 획득에만 모든 Session 을 소비해버려 데이터 획득 기간 동안에는 장비에 접근할 수 있는 방도가 없다는 것이다. 물론 데이터 획득 종료 후 사이사이에 접근하면 되지만, 그렇게 되면 데이터 획득을 할 수 없는 문제가 발생하였다.
다수의 Partition 을 활용하는 장비에 한해서는 데이터 획득을 위한 스케쥴링 조정을 통해 이를 해결하였다. 물론 이것은 궁극적인 해결방법은 아니었다.
제대로된 첫 서비스 (feat. Back-office)
기존 회사에서도 Test Automation 에 대한 서비스를 하려 노력 했지만, 사실 그 사용성이 좋지는 않아 많은 사람들이 사용하지는 않았다. 퇴사 후에도 간혹 들리는 이야기로는, 간간히 쓰기는 했지만 그다지 많이는 쓰지 않았다고... 반면에 LBaaS 는 사용하는 사람이 매우 많았다. 특히, VIP 를 설정하는 것은 엔지니어만 써서 사용률이 적긴 했지만, "조회"에 한해서는 거의 전사(라고 해도 인프라 담당자, 개발자만...)적으로 사용하고 있었다고 해도 무방하다. 개인적으로는 이러한 서비스를 해본 것이 처음이라 제대로 서비스를 올린 후 꽤 감격을 하였었다. (물론 이슈들은 빼고 말이다)
VIP 는 우리가 서비스하기 위한 목적으로 설정하는 IP 들이다. 이는 실제 유저에게 노출이 될 수도 있지만, 내부 서비스를 연결하기 위함 혹은 사용하기 위함으로도 사용 된다. 따라서 VIP 를 내부적으로 관리할 필요가 있기 때문에 이를 위한 Tool 이 필요하다. 이렇게 유저들에게 노출되지 않고 사내 운영자들이 보다 쉽게 운영하기 위해 서포트 하는 부서가 보통 Back-office 부서이다. 뭐 간단히 Role Playing 에서 힐러나 버퍼 같은 역할이라 보면 된다. 실질적으로 매출을 올리는 부서는 아니지만, 매출을 올리기 위한 여러 서포트를 하는 부서. 정도로만 이해하면 좋을 것 같다.
