보안이슈로 인하여 개발 코드 및 스냅샷을 추출할 수 없어 새로 그렸습니다. 이해 부탁 드립니다.
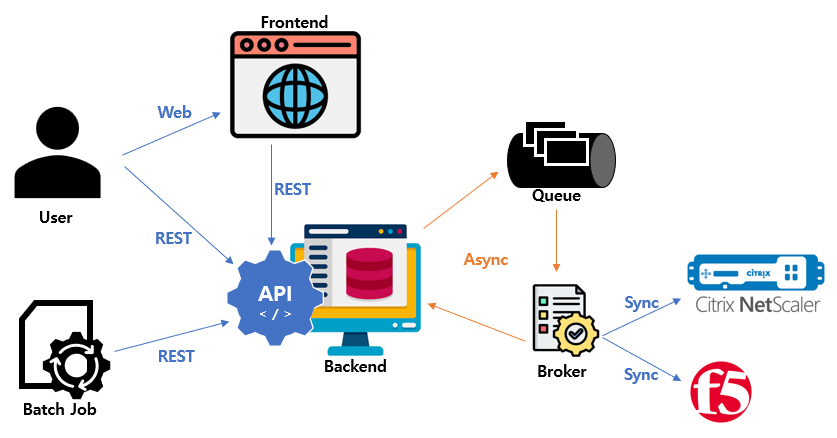
다시 시작한 LBaaS
회사에 입사 후 바로 시작했던 LBaaS v2 는 처음에는 미미했지만 점점 사용하는 유저수가 증가하였다. 당시 총 사원수가 4000명 정도였는데 약 800여명정도가 해당 서비스를 활용했다고 통계가 나왔으니, 나름 성과가 있다고 판단해도 좋을 정도였다. (라고 당시 실장님도 인정해 주셨다. 물론 통계를 뽑기 위한 추가 개발을 했지만..)
하지만 유저수가 많아지며 여러가지 문제가 나오게 되었다. 가장 큰 이슈는 VIP 상태 수집 주기와 서비스 퍼포먼스 였다.
문제점
VIP 상태 수집 주기는 5분 주기였다. 그럴게, VIP 데이터를 Polling 해오면 많은 정보를 획득하게 되는데, 장비에 부하가 많이 올라가기 때문에 데이터를 너무 자주 가져오면 장비 CPU 가 올라가 엔지니어가 장비로 접근할 수가 없기 때문이다.
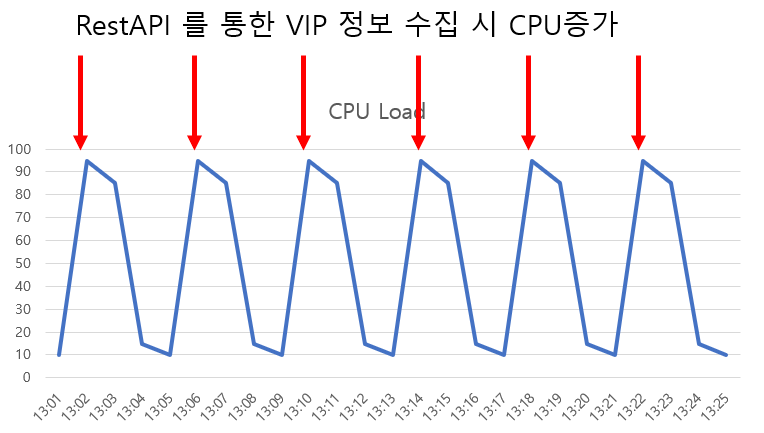
(대부분의 네트워크 장비는 관리용 CPU 를 좋은 것을 쓰지 않으니, 혹 관련 개발자분들은 이점 참고 해 주시면 좋을 것 같습니다.)
또한, 관리할 LB 장비 대수가 많아지고 Sync 동작으로 실행되는 Backend 특성상 여러 VIP 에 대한 제어를 할 경우 유저는 Web 혹은 API 에서 명령을 내린 후 한참을 기다려야 하는 일이 발생하게 되었다.
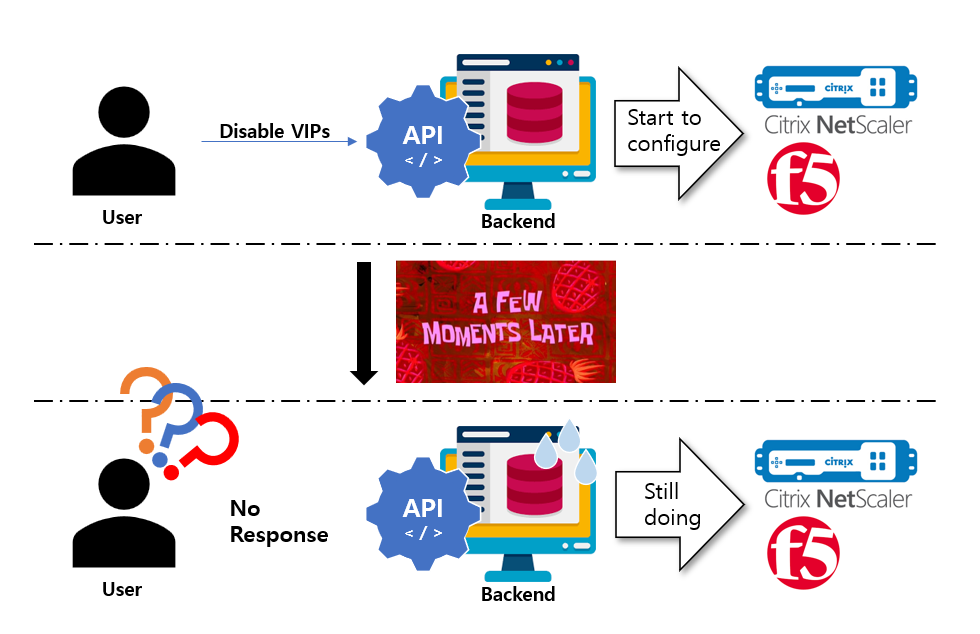
사실, 장비에 적용 중이다. 라고 하면 되긴 하지만, 유저가 응답을 일단 받고 대기하는 것과 아무 응답이 없는 것은 크다. 유저 입장에서는 Backend 가 문제인 것인지 어디가 문제인 것인지 알 도리가 없기 때문이다.
이 점들을 수정하기 위해 Loadbalancer as a Service v3 로 명명한 프로젝트를 시작하게 되었다.
MQ를 이용한 비동기 구조 구현
팀내에서는 이미 RabbitMQ 를 이용한 MQ 비동기 구조를 갖고 있는 일부 서비스들이 존재하고 있었다. (ex: CMDB) 따라서 해당 인프라를 그대로 활용하는 방안으로 진행하기로 하였다.
VIP 상태 재정의
비동기 구조를 구현하는데 있어 가장 중요하다 생각 되는 것은 구성의 상태라 생각하였다.
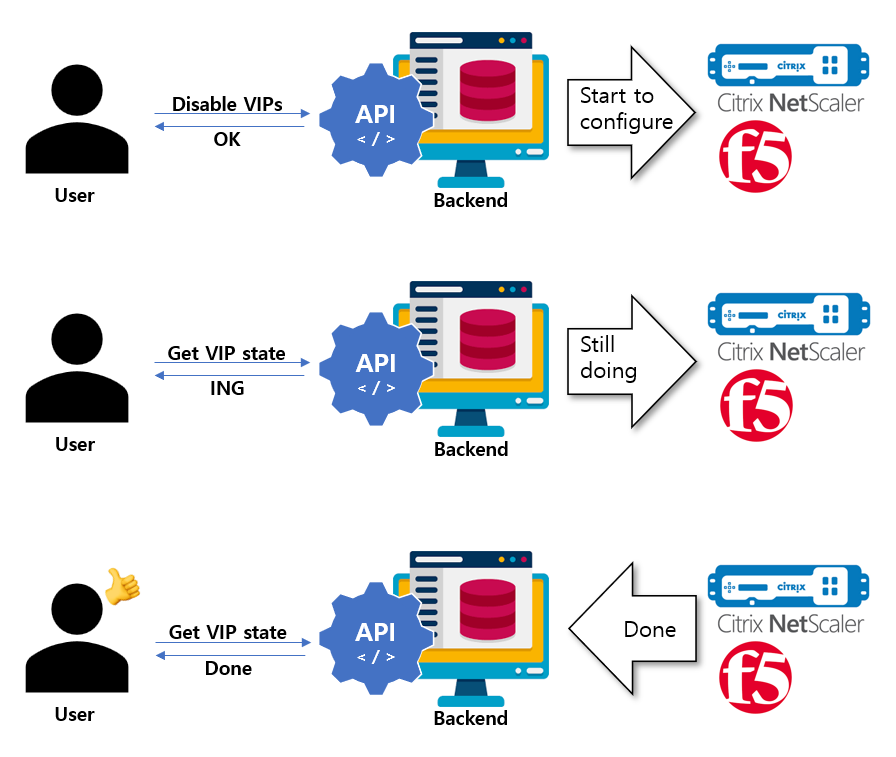
설정 명령은 크게 생성, 수정, 삭제, 비활성화, 활성화가 있기 때문에 해당 설정들에 대한 시작, 진행, 완료, 실패, 에러등에 대하여 상태를 정의할 필요가 있었다. 따라서 VIP 는 활성, 비활성의 상태 뿐만 아니라 위에 언급한 상태까지 지니게 되었으며 유저는 설정 명령과 VIP 상태의 조합에 따라 현재 VIP 가 어떤 Stage 에 머물고 있는지 확실하게 알 수 있게 되었다.
설정 SDK 분리
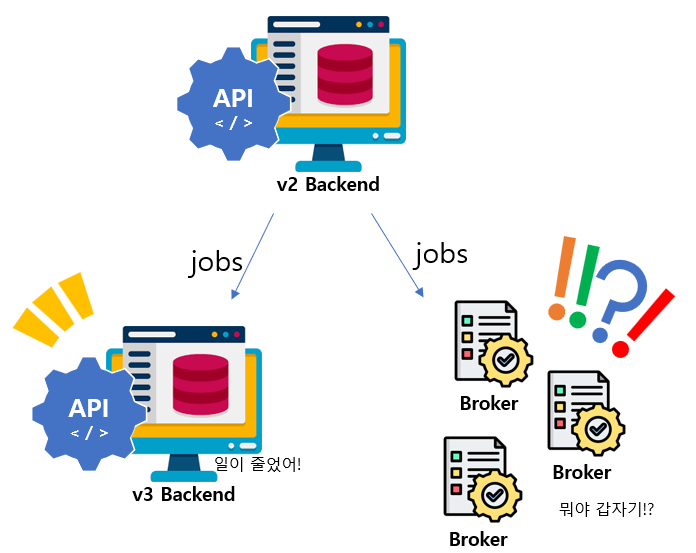
MQ 를 사용한 비동기 구조로 구현되며 기존 Backend 의 역할에 대한 분할이 진행되었다. 데이터에 대한 관리와 정형화는 Backend 에서, 장비와의 실질 커뮤니케이션을 담당하는 것은 Broker에서 진행을 하게 되었다.
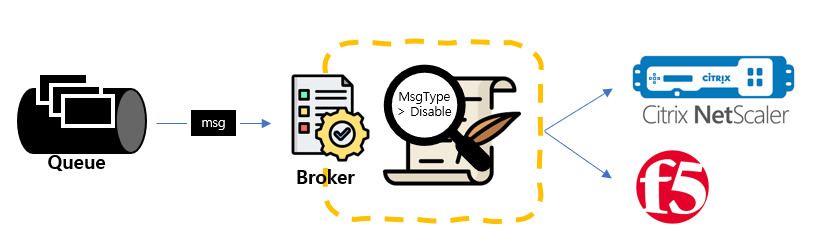
Broker 는 Queue 에 메시지가 담기면 해당 메시지를 가져와 메시지의 타입(설정 명령 외 다수의 타입)을 보고 실행해야하는 Script 를 골라 실행하는 형태로 구현되었다. Broker 에서 실행된 내용은 데이터를 정형화하여 Backend 로 직접 API 를 날려 해당 VIP 의 데이터를 Update 해주는 방향으로 진행되었다.
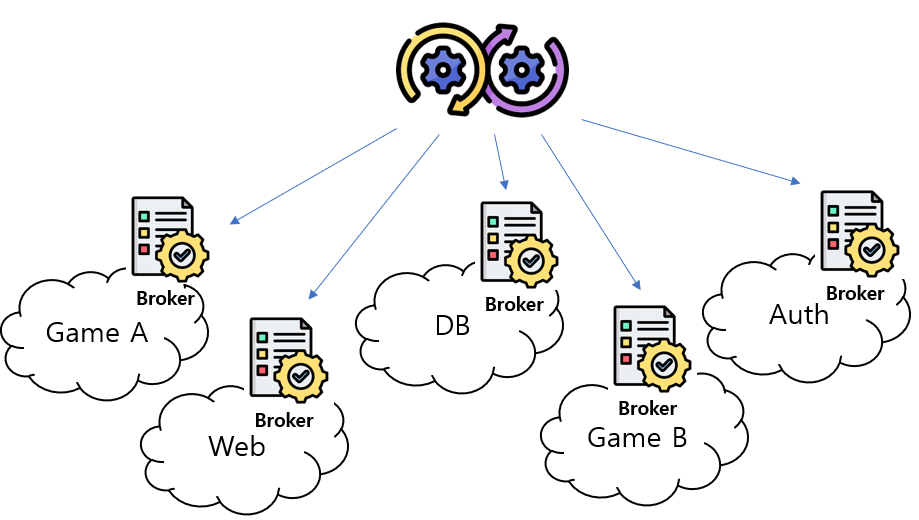
회사는 서비스망을 논리적으로 분할하여 사용하고 있었고, 각 논리적 분할된 망내 LB 가 존재하였기 때문에 관리되는 LB 의 수 만큼 Broker 를 관리하게 되었고, 결국 배포 자동화까지 진행하게 되었다.

GIT 에서 소스를 받아 Build 하고 특정 이름으로 Repo 에 Image 를 올리면 Kuberetes 로 구성된 Backend 로의 특정 Node 에 Redeploy 를 하는 형태로 명세하였다. 인프라는 Broker 별 버전이 다른 경우는 없어 일괄 관리를 하면 되었기 때문에, Daemon Set 으로 각 네트워크에 존재하는 Node 를 node-select 를 이용하여 지정되어 있어 간단히 구성할 수 있었다.
VIP State 획득 주기
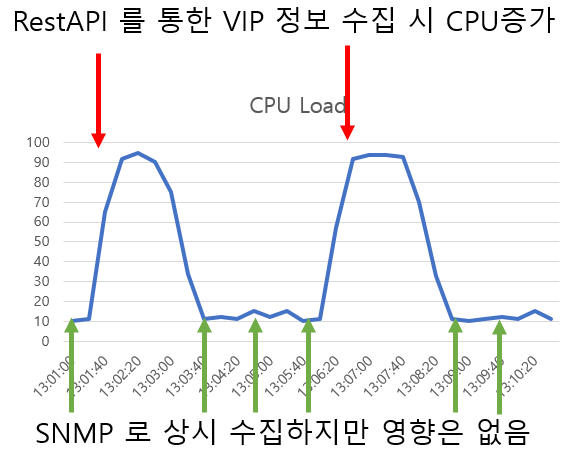
앞서 이야기 한바와 같이 VIP 상태 수집시 CPU Load 가 많이 올라갔다. 하지만 원래 많이 올라갈 만한 것이 아니다. 왜냐하면 VIP 의 모든 정보를 가져올 필요가 없기 때문이다. 하지만 기존 버전에서는 모든 정보를 한꺼번에 가져오는 Logic 으로 구현되어 있었기 때문에 이러한 이슈가 발생을 한 것이다.
그럼 간단하다. VIP 구성정보 획득과 VIP 상태 획득을 분할 하면 된다! (Simple is Best!)
SNMP (Simple Network Management Protocol)
서버나 네트워크 장비의 대부분은 SNMP 라는 프로토콜이 내장되어 있다.
SNMP 의 자세한 내용은 링크를 참고해 주세요!
일반적인 네트워크 장비는 REST API 보다는 SNMP 가 CPU Load 가 훨씬 적게 든다. 물론 SNMP 로 모든 데이터를 walk 로 가져온다면 크게 다르지 않지만, 일부 데이터만 가져온다면 아주 적은 CPU 리소스를 사용하게 된다.
Rest API 를 이용하여 VIP 의 SNMP List 정보를 획득한 후 한정된 OID 값을 이용하여 VIP Getbulk 를 통한 데이터 획득을 하여 CPU Load 도 줄이고, 획득 주기를 5분에서 1분으로 줄여 VIP down 으로 인한 장애 확인의 민감도를 올렸다.
데이터 관리
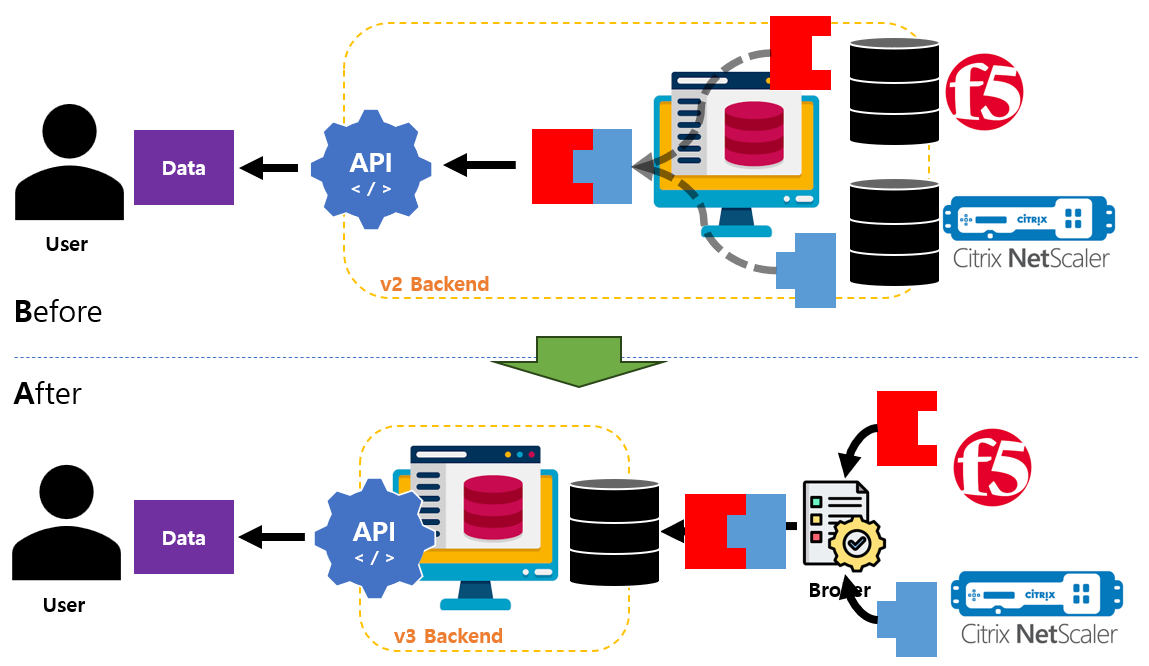
기존에는 F5와 Netscaler 데이터를 장비에서 관리하는 형태 그대로 DB 담아두고, API 에서 Call 할 경우 관련 데이터를 수집해 추상화하여 전달하였다. v3 로 변경되면서 데이터 추상화를 먼저 진행하였고, 각 장비에서 발생한 데이터는 Backend 에서 관리하는 데이터 형태에 맞도록 변경하여 전달하여 Backend 에서는 데이터를 전처리할 필요성이 없어졌다. 또한 CMDB 에서 진행했던 계층적 데이터 형태 구조를 답습하여 하위 계층 데이터에 대한 검색을 할 수 있도록 변경하였다.
마치며
문제점이 있어 시작한 내용도 있지만, 회사 업무 특성상, 급하지 않으면 잘 진행하지는 않는다. LBaaS v3 가 그런 종류였는데, 사내 클라우드 서비스 오픈을 위한 IaaS 개발과 맞물리며 프로젝트 진행에 박차가 가해져 개인적으로는 다행이었다 생각한다. (그동안에 시달린 운영 이슈가..) 지금은 퇴사하여 해당 솔루션이 잘 활용되고 있는지는 모르겠지만, 잘 활용되기를 바라고 있다. 최소한 퇴사 전까지는 아주 활용을 잘 하고 있었으니..ㅎㅎ...
위와 같은 구조는 추후 Firewall as a Service 개발에서도 동일하게 활용하였다. FWaaS 는 이후 포스팅에서 만나도록 하자.
