특징추출
-
cnn은 최근 이미지 뿐만 아니라 텍스트 음성등 다양한 분야에서 사용된다.
-
이미지 데이터에서는 연구자가 스스로 특징을 찾아야한다.
-
비전분야에는 이미지에서 특징을 추출하기 위한 다양한 알고리즘이 개발되었다.
-
특징추출 기법중 하나인 convolution 연산은 각 픽셀을 본래 픽셀과 그 주변의 픽셀 조합으로 대체하는 동작이다
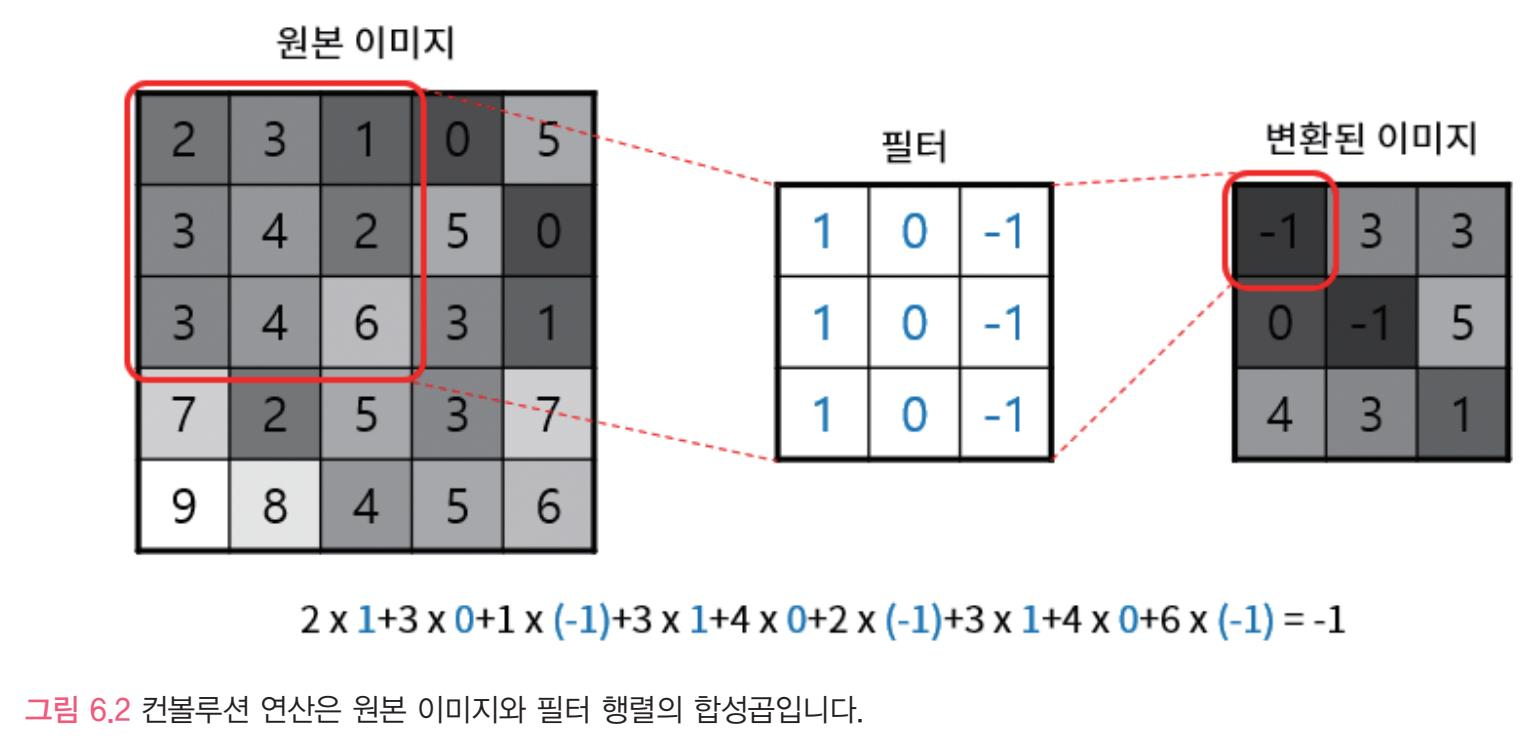
필터에 따라 사진과 같이 컨볼루션 연산 결과가 달라진다
-컨볼루션 레이어(특ㄱ징추출)
수작업 필터 문제
1. 다른데 적용이 안됨
2. 적용하고자 하는 분야의 전문적 지식이 필요
3. 시간과 비용이 많이 든다
CNN은 특징을 추출하는 필터를 자동으로 만든다.
이미지 분류를 위한 컨볼루션 신경망은 특징 추출기+ 분류기를 합쳐논 상태이다
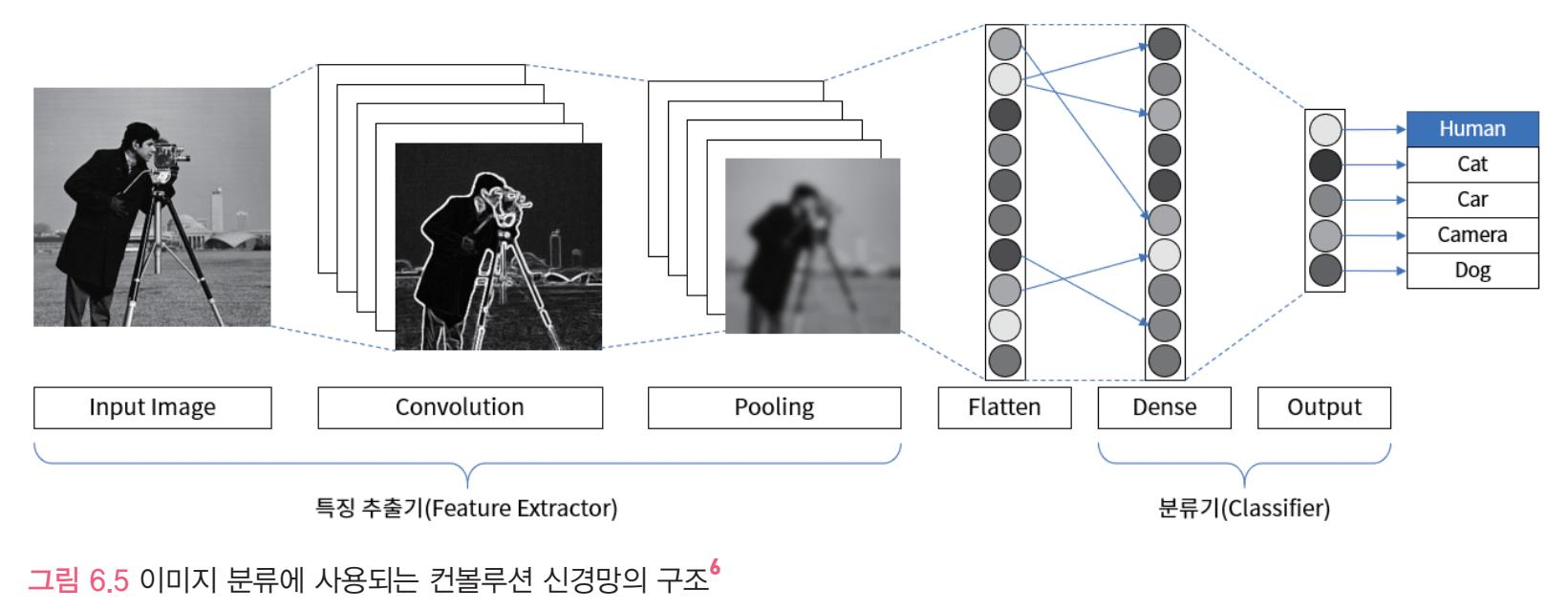
주요레이어 정리
1. 특징 추출기: 컨볼루션레이어와 풀링 레이어가 교차되며 배치
2.분류기: dense 레이어가 배치되고 적합을 막기위해 드롭아웃 레이어가 dense레이어 사이에 배치
1-1) 특징 추출기
-
- convoultion layer: 여기서 사용하는 필터는 네트워크 학습을 통해 자동으로 추출한다
kernel_size: 필터행렬크기
strides : 필터가 계산과정에서 한 스텝마다 이동하는 크기
padding:연산전 이미지 주변에 빈 값을 넣을지 정하는 옵션
valid: 빈값 사용안함, same: 빈값사용함(입력크기=출력크기)
filters:필터개수
- convoultion layer: 여기서 사용하는 필터는 네트워크 학습을 통해 자동으로 추출한다
-
필터의 수가 많을수록 다양한 특징을 추출할 수 있다.
-
작게는 1차원 크게는 3차원 이상까지 사용가능 보통 2차원 기준으로 설명
- 차원수= 필터수 -
- pooling layer
:이미지를 구성하는 픽셀 중 인접한 픽셀들ㄹ은 비슷한 정보들을 갖는 경우가 많기에 이미지의 크기를 줄이면서 중요한 정보만 남기기 위해 사용하는 레이어
- pooling layer
-
효율적인 메모리
-과적합 방지pool_size: 한번에 max연산을 수행할 범위
strides: 계산과정에서 한 스텝마다 이동하는 크기
conv2D에서도 max2d에서도 크기가 줄어든다
-3. Dropout layer
- 네트워크 과적합을 막기 위한 레이어
- 학습과정에서 무작위로 뉴런의 부분집합을 제거
pool1=tf.keras.layers.Dropout(rate=0.3) #여기서 rate는 제거할 뉴런 비율데이터는 정규화 해주면 좋다
# 데이터를 채널을 가진 이미지 형태(3차원)으로 바꾸기
# reshape 이전
print(train_X.shape, test_X.shape)
train_X = train_X.reshape(-1, 28, 28, 1) 흑백데이터 경우 1개의 채널을 갖기에 가장뒤에 채널을 추가한다
test_X = test_X.reshape(-1, 28, 28, 1)
# reshape 이후
print(train_X.shape, test_X.shape)분류신경망모델
# Fashion MNIST 분류 컨볼루션 신경망 모델 정의
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(input_shape=(28,28,1), kernel_size=(3,3), filters=16),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=32),
tf.keras.layers.Conv2D(kernel_size=(3,3), filters=64),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=128, activation='relu'),
tf.keras.layers.Dense(units=10, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()파라미터 계산법: (커널크기x inputchannel+1)*output channel
model.fit(trainx,trainy,epochs=25,validation_split=0.25)
model.compile(optimizer=tf.keras.optiomizers.Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
histort=model.fit(train_x,train_y, epochs=25, validation_split=0.25)
#verbose=0(표기 x)
=1 진행바
2 에포크당 ㅜㄹ력
model.evaluate 퍼포먼스 높이기
1. 더 많은 레이어 쌓기
2. 이미지 증장( image augmentation)
- 더 많은 레이어 쌓기
VGGNet 코드

-VGGNet 중에서 실제학습이 일어나는 conv레이어와 dense레이어 개수가 19개인 VCG_19이게 가장 깊은 구조
- 이미지 증강
: 이미지 보강은 훈련데이터에 없는 이미지를 새로 만들어내서 훈련데이터를 보강하는 것으로 이미지를 가로로 뒤집거나 약간 회전시키거나, 기울이거나, 일부 확대하거나, 평행이동 시켜서 다양한 이미지를 만들어내서 training 데이터의 표현력을 더 좋게 만든다
ImageDataGenerator 말그대로 훈련이미지 보강
rotation__range
zoom_range
shear_range
width_shift_range
height_shift_range
horizontal_flip
vertical_flip
회전, 줌,기울이기,높이/너비변경, 좌우 뒤집기 등이 적용한 보강이미지
flow() : 실제로 보강된 이미지를 생성함
VGGNet 구성요소
conv2d,conv2d,maxpool2d,dropout, conv2d,conv2d,maxpool2d, dropout, flatten,dense,dropout,dense,droupout,dense(softmax)
이미지 분류기에 마지막에 활성화 함수는 꼭 softmax
metrics=['accuracy'] loss=**"sparse_categorical_crossentropy"
