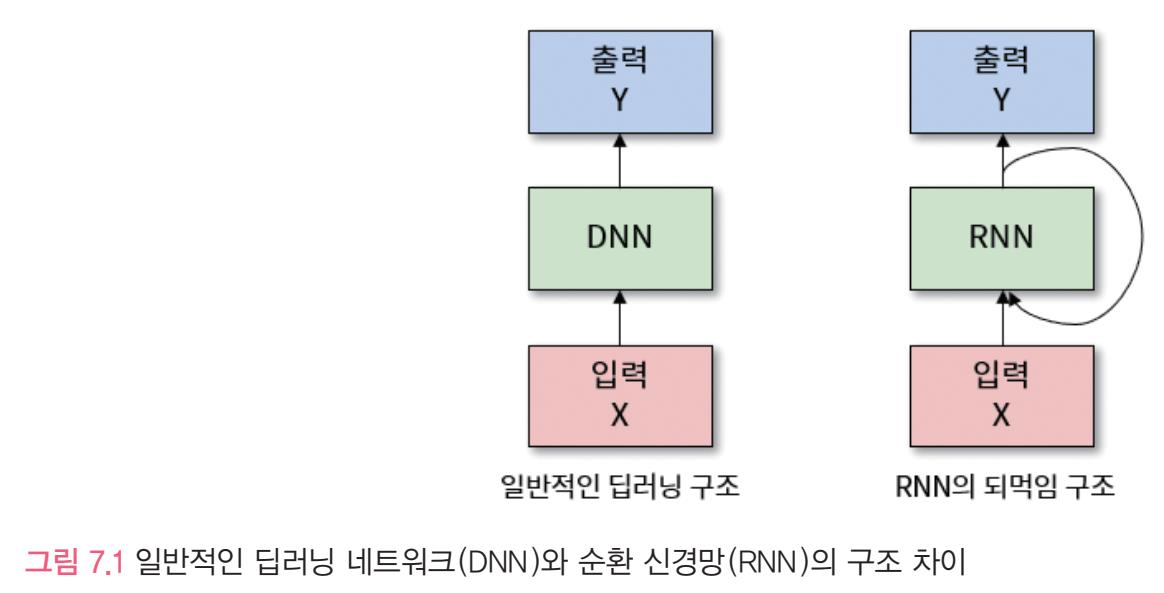
- 순환 신경망은 순서가 있는 데이터를 입력으로 받고 같은 네트워크를 이용해 변화하는 입력에 대해 출력을 얻어낸다
- 순환신경망은 되먹임 구조를 가지고 있다
- 어떤 레이어의 출력을 다시 입력으로 받는 구조
순환신경망은 입력과 출력의 길이가 제한이 없다 그래서 다양한 구조가 있다
1.one to one
2.one to many
3.many to many
4.many to one
Simple RNN
- 가장 간단한 형태의 RNN 레이어
- SimpleRnn은 변화하는 입력을 받기에 아래 그림에서는 각 단계에서 입력이 변할때의 계산의 흐름을 보여줌
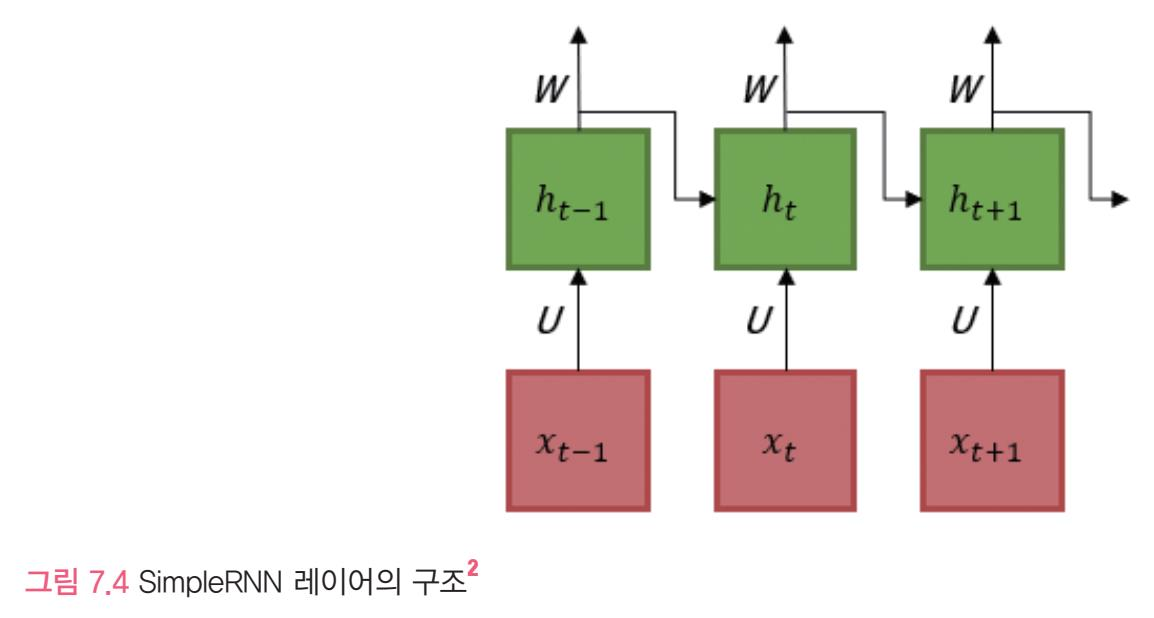
- 활성화함수tahn 사용
rnn1=tf.keras.SimpleRNN(units=1, activation='tahn',return_sequence=True)units: SimpleRnn레이어에 존재하는 뉴런수
activation: tahn이나 Relu사용
return_sequence: 출력으로 시퀀스 전체를 출력할지 여부
시퀀스 예측모델 정의
# 시퀀스 예측 모델 정의
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(units=10, return_sequences=False, input_shape=[4,1]),
tf.keras.layers.Dense(units=1)
])
model.compile(optimizer='adam', loss='mse')
model.summary()time steps=4,inputdim=1
timestpes: rnn이 입력에 대해 계산을 반복하는 횟수
input_dim: 입력벡터 크기
파라미터수: 입력벡터크기 x unit + 유닛 x unit + unit x 1(bias)
장기 의존성 문제
- 입력데이터가 갈이절수록 (데이터의 타임스텝이 커질수록) 학습능력이 떨어진다. 왜냐하면 중요정보가 시간이 지나면서 희석 되기 땜ㄴ이다
- 입력데이터와 출력사이의 길이가 멀어질수록 연관관계가 적어진다
이는 전부 Simpl Rnn 문제
2.LSTM
: simplernn의 문제를 해결하기 위해 나옴 long short term memory의 약자로 출력외에 lstm셀 사이에만 공유되는 셀상태를 가진 레이어다.
-
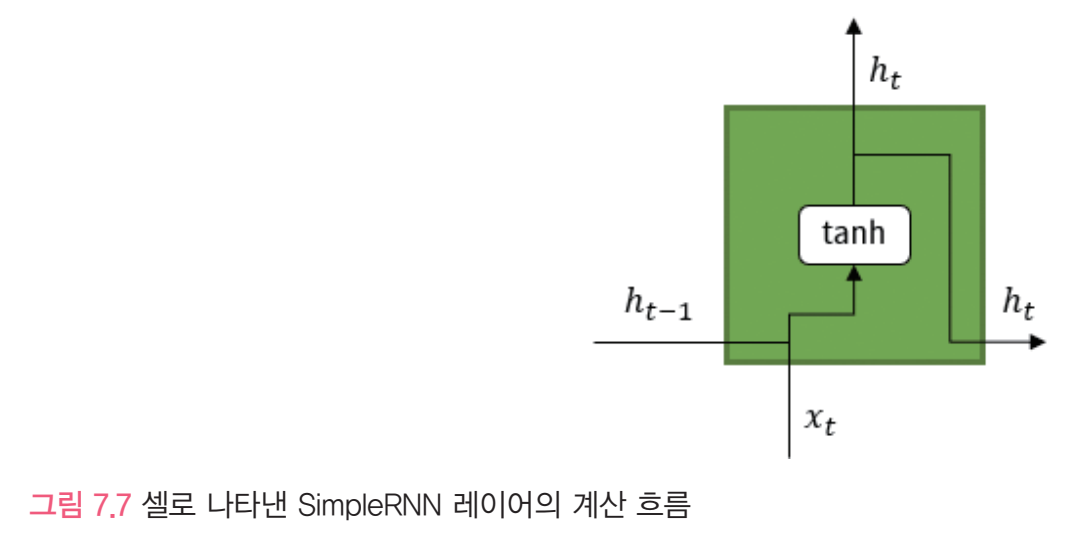
SimpleRnn레이어를 셀로 나타내면 입력과 이전 레이어의 출력은 합쳐진 다음 활성화함수 tanh를 통과해 출력을 얻는다.
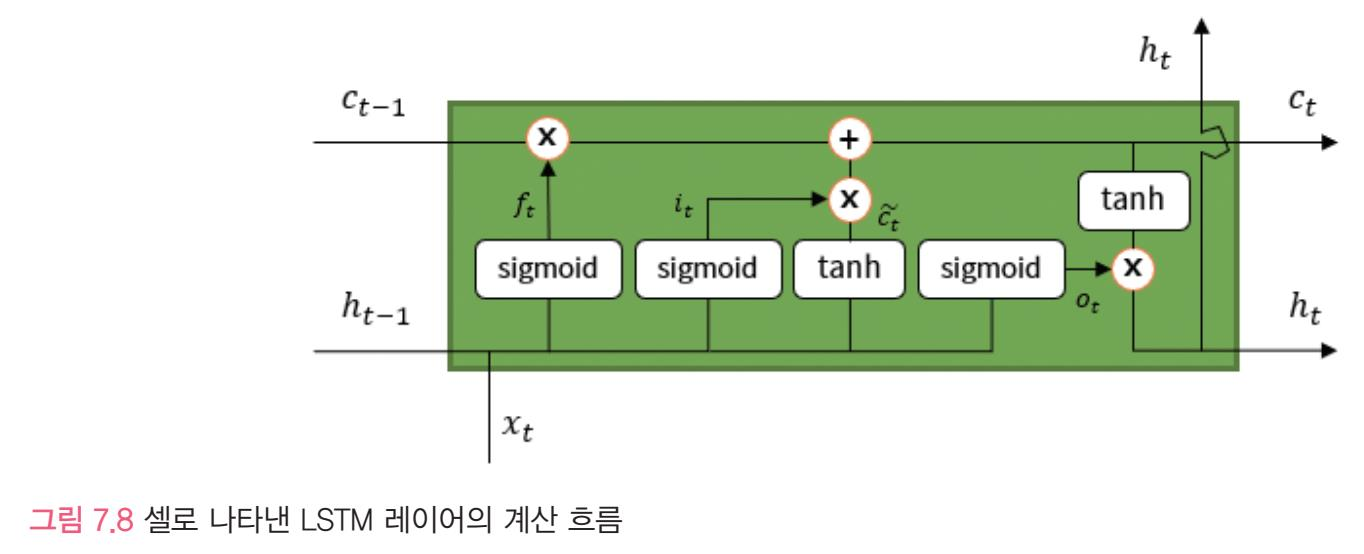
LSTM 레이어
ct-1과 c-t는 셀상태로, lstm은 이 또한 평행선으로 ht와 함께 다음셀에 전달 이처럼 타임스텝을 가로지르며 셀상태가 보존되기에 장기 의존성 문제를 해결한다.
- 또 sigmoid, tanh을 사용
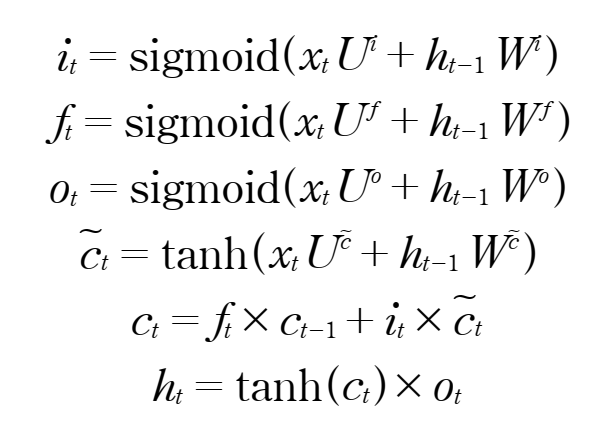
rnn: (입력+은닉+1)x 다음출력
lstm: 입력게이트,출력게이트,망각게이트,현재셀게이트라 4더 곱하기
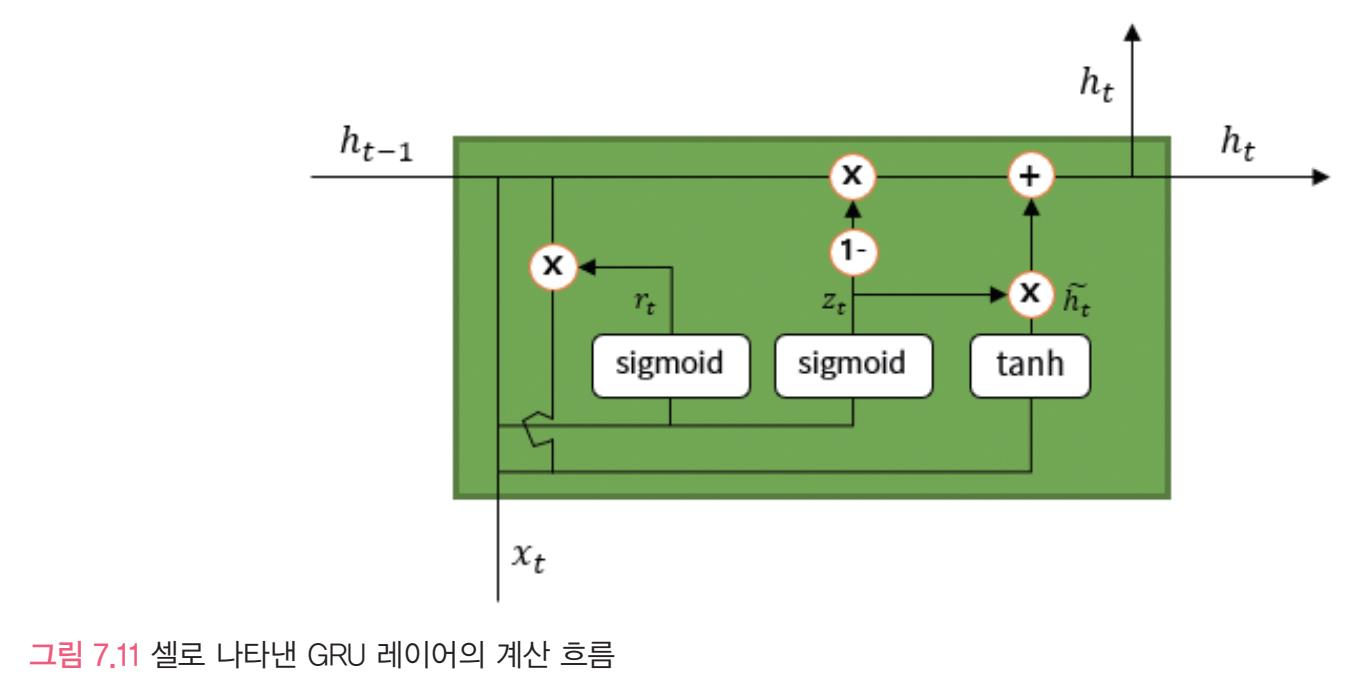
GRU레이어
lstm 레이어와 비슷한 역할을 하지만 구조가 더 간단하기에 계산상의 이점이 있고, 어떤문제에서는 LSTM 레이어보다 좋은 성능을 보인다.
- GRU 레이어는 LSTM 과 성능이 비슷하지만 구조가 간단
- 다른점: 셀상태가 보이지 않음 ,ht가 비슷한 역할을 함
rt= reset 게이트를 통과한 출력 (이전 타임스텝의 출력인 ht-1에 곱해지기 때문에 이전 타임스텝의 종보를 얼마나 남길지 결정)
zt= update게이트를 통과한 출력
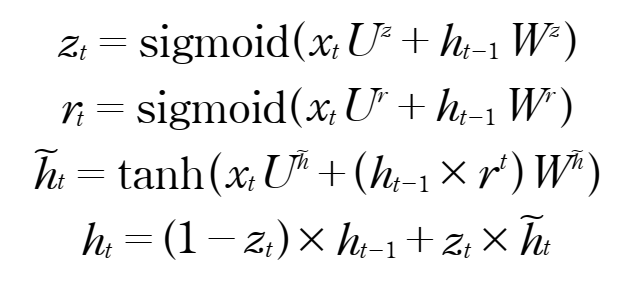
Embedding layer
- 임베딩 레이어는 자연어를 수치정보로 바꾸기 위한 레이어
- 비슷한 기법으로 몇 개의 문자를 묶어서 파악하려는 n-gram기법이 있지만 최근 딥러닝 기법 발달로 임베딩 레이어가 주목받음
정수인덱스 기법: 단어의 출현 순서대로 인덱스 저장
원핫인코딩 단점 : 원핫인코딩의 차원수만큼의 단어만 표현가능
- 사용하는 메모리양에 비해 저장되는 정보량이 부족함
이를 해결하기 위해 임베딩기법
-
정수 대신 실수 값을 사용하기에 한정된 벡터내에서도 무한한 단어를 표현가능
-
임베딩 레이어는 정수인덱스 기법으로 구한 인덱스를 단어 임베딩으로 바꾼다
정수인데스기법구한 인데스-> 단어 임베딩
-
임베딩 레이어의 행과 각 단어 임베딩은 동일한 값을 가짐
-
임베딩 레이어는 정수 인덱스에 저장된 단어의 수만큼 단어 임베딩을 가지고 있다가 필요할 때 꺼내쓸 수 있는 저장공간과 같은 역할
-
자연어에서 많은 단어들이 있으므로 보통 정수 인덱스로 저장하지 않는 단어에 대한 임베딩 값을 따로 마련한다.
긍정 부정 감정분석(0부정,1긍정)
- 입력 x는 토큰화 하고 정제하여 사용
- 토큰화: 자연어를 처리 가능한 작은 단어로 나눈것 띄어쓰기 단위로 나누면 된다.
- 정제: 원하지 않는 입력이나 불필요한 기호등을 제거
- import re: 정규표현식 라이브러리 불러옴
문장 전처리
tokenizer=Tokenizer(num_words=20000)
tokenizer.fit_on_tests(sentences)
train_X=tokenizer.texts_to_sequences(sentences)
train_X=pad_sequences(train_X,padding='post')전처리된 문장은 단어가 숫자로 바뀌었고 부족하면 0으로 채워 길이가 25가 되게 하였다
이때 상위 20000개의 단어에 속하지 못하면 0으로 처리한다.
tokenizer는 의미있는 데이터만 변환 아니면 0
- 배치크기는 128로 설정하고 , 데이터를 섞을 때의 버퍼크기는 10000으로 설정
- 자소 단위 학습이지만 한 글 만위
