지도학습: 하나 이상의 입력 변수를 기반으로 출력하거나 변수 추정,예측하는 통계 알고리즘 (회귀(선형), 분류(선형), 비선형)
비지도 학습: 출력변수 없이 입력변수만으로 자료의 상관관계나 특징을 찾아 내는 통계 알고리즘
오토인코더: 입력에 대한 출력을 학습해야한다는 점에서 지도학습이나 출력과 입력이 동일하다
오토인코더
손실 압축으로 인해 입력과,출력이 완전 일치하지 않음
대신 압축률이 크게 올라가며 압축률을 높이는과정에서 원본 데이터느이 특징을 잘 나타냄
적은 양의 데이터로 많은 양의 정보 표현
딥러닝 모델중 최근 주목받는 적대적 생성 모델의 생성자에서는 랜덤하세 생성된 변수를 잠재변수처럼 활용해 이미지 얻음
1. 인코더
입력에서 잠재변수를 만듦
2. 디코더
잠재변수를 출력으로 만듦
3. 잠재변수
특징추출기인 인코더를 통해 추출된 일차원 벡터로 특징을 잘 표현하는 정보이기에 여러가지 용도로 쓰일 수 있다.
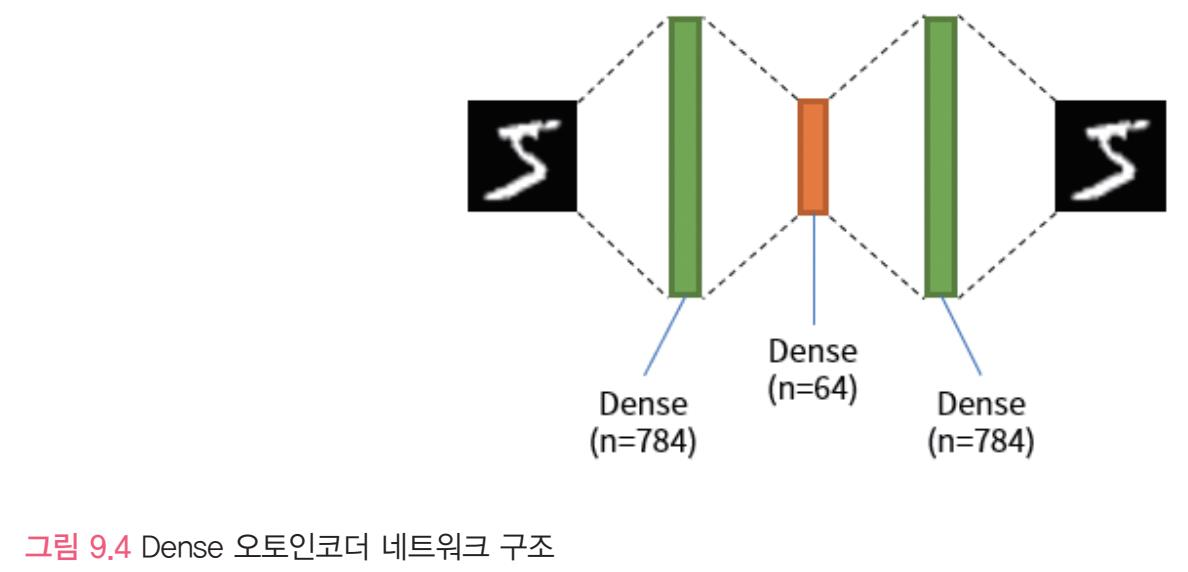
인코더와 디코더는 동일한 레이어를 대칭되는 구조로 쌓아 올린다.

비슷한데 좀 다름 윤곽선이 달라지고 흐릿해짐
컨볼루션 레이어 2개 사용한 오토인코더
# 컨볼루션 오토인코더 모델 정의
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=2, strides=(2,2), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=64, kernel_size=2, strides=(2,2), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(7*7*64, activation='relu'),
tf.keras.layers.Reshape(target_shape=(7,7,64)),
tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=2, strides=(2,2), padding='same', activation='relu'),
tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=2, strides=(2,2), padding='same', activation='sigmoid')
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.summary()kernal_size(2,2), strides=(2,2)sm는 풀링레이어의 strides(2,2)와 같음 크기 반으로 줄어든다.
conv2DTranspose는 conv2D레이어가 하는 일의 반대 되는 계산, 즉 입력이 하나의 값을 convolution에 통과시켜 출력의 여러값을 계산해주는 레이어고 디컨볼루션 레이어
- 활성화 함수로 relu 사용 , 음수가 들어오면 출력을 0으로 반환
- 출력은 다음 레이어의 가중치에 곱해지기에 출력이 0이면 가중치의 효과가 모두 0이다.
이런 문제를 해결하기 위해 elu 사용
elu는 0이하에서 부드럽게 감소하며 -1에 수렴
# 활성화함수를 elu로 바꾼 컨볼루션 오토인코더 모델 정의 및 학습
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=2, strides=(2,2), activation='elu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=64, kernel_size=2, strides=(2,2), activation='elu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='elu'),
tf.keras.layers.Dense(7*7*64, activation='elu'),
tf.keras.layers.Reshape(target_shape=(7,7,64)),
tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=2, strides=(2,2), padding='same', activation='elu'),
tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=2, strides=(2,2), padding='same',
activation='sigmoid')
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.fit(train_X, train_X, epochs=20, batch_size=256)오토인코더를 학습시키면 원본에 존재하는 노이즈도 제거한다
K-평균 클러스터링
주어진 입력중 k개의 클러스터 중심을 임의로 정한 다음 각 데이터와 K개의 중심과의 거리를 비교해서 가장 가까운 클러스터로 배당하고, K개의 중심의 위치를 해당 클러스터로 옮긴 후, 이를 반복하는 알고리즘
- 각 관측치는 K cluster중 적어도 하나에 속함
- 어떤 관측치도 두 개 이상의 cluster에 속하지 않음
- W(ck):클러스터 내의 관측치들이 얼마나 다른지 나타낸 측도
이거를 줄이는게 매우매우 중요
K-means algo
1. randomly assign a number,from 1 to k, to each of the observations.
These serve as initial cluster assignments for the observations.
2. Iterate until the cluster assignments stop changing:
a. 클러스터 무게중심 찾기
b. 무게중심은 p개 변수 평균들으 벡터
ISSUE K-means
1. w(ck) 감소 보장
2. 초기 랜덤할당을 다르게 해서 알고리즘 여러번 수행해서 최소인 것을 선택한다(global optima)
-
사이킷 런의 클러스터링
kmeans=KMeans(n_clusters=10,n_init=10, random_state=42)
#클러스터링개수 10, 중심위치 다르게 10번 , 랜덤시드 42 -
labels_에는 각 데이터가 어떤 클러스터에 속하는지 정보 저장
-
clustercenters 각 클러스터의 중심좌표가 저장되지만 64차원이기에 이 정보가 무엇을 의미하는지 알기 힘듦
t-sne
- t-SNE: 고차원의 데이터를 저차원의 시각화를 위한 데이터로 변환 (SNE: Stochastic neighbor embedding[ 확률적 이웃 임베딩])
- t분포: 정규분포와 비슷하게 생겼지만 중심이 더 낮고 꼬리가 좀 더 두꺼움
- 거리를 확률로 표현하기 위해 데이터 하나를 중심으로 다른 데이터를 거리에 대한 t- 분포 확률로 치환
- 가까운 거리의 데이터는 확률이 높아지고, 먼거리의 데이터는 확률값이 낮아진다.
- 고차원과 저차원에서 확률값을 각각 구한 후 ,저차원의 확률값이 고차원에 가까워지도록 학습시키는 것이 t-sne알고리즘 주내용이다.
- 고차원과 저차원에서 확률값을 각각 구한 후 , 저차원의 확률값이 고차원에 가까워지게 학습시키는거 것이 t-SNE알고리즘

각 숫자는 대부분 자기 클러스터에 표시
같은 클러스터 안에서 움직이면 각도,굵기 등이 연속적 변화
