LINK
Redis 파이프라이닝이란
- Redis 파이프라이닝은 Redis 명령을 일괄 처리하여 왕복 시간을 최적화하는 방법이다.
- 개별 명령에 대한 응답을 기다리지 않고 여러 명령을 한 번에 실행하여 성능을 개선하는 기술이다.
요청/응답 프로토콜과 왕복 시간(RTT)
Redis는 클라이언트-서버 모델과 요청/응답 프로토콜을 사용하는 TCP 서버이다. 일반적으로 요청은 다음 단계로 이루어진다.
- 클라이언트는 서버에 쿼리를 보내고, 보통 블로킹 방식으로 소켓에서 서버 응답을 읽는다.
- 서버는 명령을 처리하고 응답을 클라이언트로 다시 보낸다.
예를 들어 아래의 네 개의 명령 시퀀스가 있다.
Client: INCR X
Server: 1
Client: INCR X
Server: 2
Client: INCR X
Server: 3
Client: INCR X
Server: 4클라이언트와 서버는 네트워크 링크를 통해 연결된다. 링크는 매우 빠르거나(루프백 인터페이스) 매우 느릴(두 호스트 사이에 많은 홉이 있는 인터넷을 통해 설정된 연결된 경우) 수 있다.
cf. 루프백 인터페이스란?
컴퓨터 자체로 연결되는 가상 인터페이스이다. 실제 네트워크 장치가 필요하지 않고, 컴퓨터 내부로 데이터를 다시 전달하는 역할을 한다. 127.0.0.1 주소를 이용하여 로컬호스트에 연결할 수 있다.
네트워크 지연 시간에 상관없이 패킷이 클라이언트에서 서버로 이동하고 서버에서 클라이언트로 다시 돌아와 응답을 전달하는 데는 시간이 걸린다. 이 시간을 왕복 시간(RTT, Round Trip Time)이라고 한다.
클라이언트가 연속적으로 많은 요청을 수행해야 할 때, 예를 들어 한 리스트에 많은 항목을 추가하거나 많은 키로 데이터베이스를 채우는 경우, RTT는 성능에 영향을 많이 미친다. 예를 들어, RTT 시간이 250밀리초인 경우(인터넷을 통한 매우 느린 링크의 경우), 서버가 초당 100,000개의 요청을 처리할 수 있다고 하더라도 최대 4개의 요청만 처리할 수 있다.
사용되는 인터페이스가 루프백 인터페이스인 경우, RTT는 일반적으로 밀리초 미만으로 훨씬 짧지만 연속으로 많은 쓰기 작업을 해야하는 경우에는 이마저도 시간이 많이 늘어난다.
다행히 이 사용 사례를 개선할 수 있는 방법이 있다.
Redis 파이프라이닝(Pipelining)
요청/응답 서버는 이전 응답을 클라이언트가 아직 읽지 않았더라도 새로운 요청을 처리할 수 있는 방식으로 구현될 수 있다. 이렇게 하면 클라이언트가 이전 응답을 기다리지 않고도 서버에 여러을 명령 전송하고 한 번에 응답을 읽을 수 있다.
이를 파이프라이닝이라고 한다. 수십 년 동안 널리 사용되고 있는 기술이다. 예를 들어, POP3 프로토콜 구현에서는 파이프라이닝 기능을 지원하여, 이를 통해 서버로부터 새 이메일을 다운로드하는 과정이 매우 빨라질 수 있었다.
Redis는 초기 버전부터 파이프라이닝을 지원해왔으므로, 실행 중인 버전에 관계없이 Redis에서 파이프라이닝을 사용할 수 있다. 다음은 netcat 유틸리티를 사용한 예시이다.
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG이번에는 각 호출마다 RTT 비용을 지불하는 것이 아니라 3개의 명령에 대해 한 번만 RTT 비용을 지불한다.
파이프라이닝을 사용하였을 때, 이전 예시의 작업 순서는 다음과 같다.
Client: INCR X
Client: INCR X
Client: INCR X
Client: INCR X
Server: 1
Server: 2
Server: 3
Server: 4참고💡
클라이언트가 파이프라이닝을 사용하여 명령을 전송하는 동안, 서버는 메모리를 사용하여 응답을 강제로 대기열에 넣어야 한다. 따라서 파이프라이닝을 사용하여 많은 명령을 보내야 하는 경우에는 각각 적절한 수(예: 10,000개의 명령)를 포함하는 일괄 처리를 보내고, 응답을 읽은 다음 다시 10,000개의 명령을 보내는 식으로 보내는 것이 좋다. 속도는 거의 동일하지만 추가로 사용되는 메모리는 이 10,000개의 명령에 대한 응답을 대기열에 대기시키는 데 필요한 양만큼만 늘어난다.
RTT 개선 뿐만이 아니다!
파이프라이닝은 왕복 시간과 관련된 지연 비용을 줄이는 방법에서 그치지 않는다. 실제로 Redis 서버에서 초당 수행할 수 있는 작업 수를 크게 향상시킨다. 파이프라이닝을 사용하지 않을 때, 각각의 명령을 처리하는 데는 데이터 구조에 접근하고 응답을 생성하는 측면에서는 비교적 적지만, 소켓 I/O 측면에서는 매우 비용이 많이 들게 된다. 이는 read()와 write() 시스템 호출을 포함하고 있으며, 유저 영역과 커널 영역 간의 전환이 일어나게 된다. 이 과정에서 발생하는 컨텍스트 스위치는 속도를 현저하게 저하시킨다.
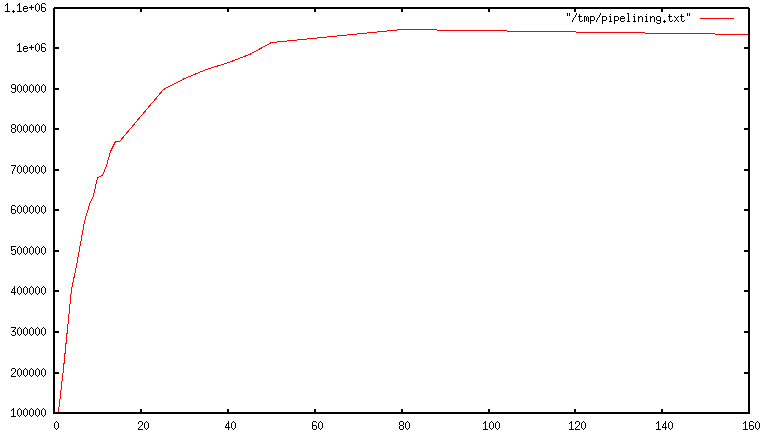
파이프라이닝을 사용하면 일반적으로 여러 명령이 하나의 read() 시스템 호출로 한꺼번에 읽히고, 여러 응답이 하나의 write() 호출로 전송된다. 그 결과, 초기에는 파이프라인이 길어질수록 초당 총 쿼리 수가 거의 선형적으로 증가하고, 결국 아래 그림과 같이 파이프라이닝을 사용하지 않았을 때보다 10배 가량 높은 성능을 얻을 수 있다.
cf. 국내 RTT 조사
$ ping lge.com # LG전자 # 평균 RTT=150.572 ms
PING lge.com (76.223.18.25): 56 data bytes
64 bytes from 76.223.18.25: icmp_seq=0 ttl=245 time=8.745 ms
64 bytes from 76.223.18.25: icmp_seq=1 ttl=245 time=42.042 ms
64 bytes from 76.223.18.25: icmp_seq=2 ttl=245 time=283.384 ms
64 bytes from 76.223.18.25: icmp_seq=3 ttl=245 time=135.976 ms
64 bytes from 76.223.18.25: icmp_seq=4 ttl=245 time=176.372 ms
64 bytes from 76.223.18.25: icmp_seq=5 ttl=245 time=219.597 ms$ ping skhynix.com # SK하이닉스 # 평균 RTT=86.417 ms
PING skhynix.com (20.196.144.36): 56 data bytes
64 bytes from 20.196.144.36: icmp_seq=0 ttl=115 time=9.676 ms
64 bytes from 20.196.144.36: icmp_seq=1 ttl=115 time=7.818 ms
64 bytes from 20.196.144.36: icmp_seq=2 ttl=115 time=8.750 ms
64 bytes from 20.196.144.36: icmp_seq=3 ttl=115 time=8.250 ms
64 bytes from 20.196.144.36: icmp_seq=4 ttl=115 time=47.495 ms
64 bytes from 20.196.144.36: icmp_seq=5 ttl=115 time=91.606 ms
64 bytes from 20.196.144.36: icmp_seq=6 ttl=115 time=335.978 ms
64 bytes from 20.196.144.36: icmp_seq=7 ttl=115 time=53.741 ms
64 bytes from 20.196.144.36: icmp_seq=8 ttl=115 time=94.027 ms$ ping kia.com # 기아자동차 # 평균 RTT=284.401 ms
PING kia.com (209.198.180.28): 56 data bytes
64 bytes from 209.198.180.28: icmp_seq=0 ttl=52 time=143.855 ms
64 bytes from 209.198.180.28: icmp_seq=1 ttl=52 time=186.224 ms
64 bytes from 209.198.180.28: icmp_seq=2 ttl=52 time=235.422 ms
64 bytes from 209.198.180.28: icmp_seq=3 ttl=52 time=278.486 ms
64 bytes from 209.198.180.28: icmp_seq=4 ttl=52 time=325.061 ms
64 bytes from 209.198.180.28: icmp_seq=5 ttl=52 time=228.472 ms
64 bytes from 209.198.180.28: icmp_seq=6 ttl=52 time=276.008 ms
64 bytes from 209.198.180.28: icmp_seq=7 ttl=52 time=518.370 ms
64 bytes from 209.198.180.28: icmp_seq=8 ttl=52 time=366.124 ms$ ping celtrion.com # 셀트리온 # 평균 RTT=231.204 ms
PING celtrion.com (66.81.203.196): 56 data bytes
64 bytes from 66.81.203.196: icmp_seq=0 ttl=52 time=272.937 ms
64 bytes from 66.81.203.196: icmp_seq=1 ttl=52 time=317.567 ms
64 bytes from 66.81.203.196: icmp_seq=2 ttl=52 time=137.787 ms
64 bytes from 66.81.203.196: icmp_seq=3 ttl=52 time=137.409 ms
64 bytes from 66.81.203.196: icmp_seq=4 ttl=52 time=451.104 ms
64 bytes from 66.81.203.196: icmp_seq=5 ttl=52 time=138.996 ms
64 bytes from 66.81.203.196: icmp_seq=6 ttl=52 time=155.933 ms$ ping gsgcorp.com # GS # 평균 RTT=47.523 ms
PING gsgcorp.com (13.209.139.254): 56 data bytes
64 bytes from 13.209.139.254: icmp_seq=0 ttl=110 time=30.281 ms
64 bytes from 13.209.139.254: icmp_seq=1 ttl=110 time=40.400 ms
64 bytes from 13.209.139.254: icmp_seq=2 ttl=110 time=87.502 ms
64 bytes from 13.209.139.254: icmp_seq=3 ttl=110 time=8.373 ms
64 bytes from 13.209.139.254: icmp_seq=4 ttl=110 time=62.710 ms
64 bytes from 13.209.139.254: icmp_seq=5 ttl=110 time=85.802 ms
64 bytes from 13.209.139.254: icmp_seq=6 ttl=110 time=10.718 ms$ ping newjeans.kr # 뉴진스 # 평균 RTT=12.824 ms
PING newjeans.kr (54.230.176.89): 56 data bytes
64 bytes from 54.230.176.89: icmp_seq=0 ttl=243 time=10.412 ms
64 bytes from 54.230.176.89: icmp_seq=1 ttl=243 time=16.290 ms
64 bytes from 54.230.176.89: icmp_seq=2 ttl=243 time=10.877 ms
64 bytes from 54.230.176.89: icmp_seq=3 ttl=243 time=15.340 ms
64 bytes from 54.230.176.89: icmp_seq=4 ttl=243 time=10.767 ms
64 bytes from 54.230.176.89: icmp_seq=5 ttl=243 time=9.769 ms=> 각 평균 RTT는 다음과 같다.
- LG전자: 150.572 ms
- SK하이닉스: 86.417 ms
- 기아자동차: 284.401 ms
- 셀트리온: 231.204 ms
- GS: 47.523 ms
- 뉴진스: 12.824 ms
=> 전체 평균 RTT는 다음과 같다.
- 135.49 ms
Code Example in Go
파이프라이닝을 지원하는 Redis Go 클라이언트를 사용하여 파이프라이닝으로 인한 속도 향상을 테스트해보았다.
package main
import (
"context"
"fmt"
"time"
"github.com/redis/go-redis/v9"
)
var ctx = context.Background()
func bench(descr string, fn func()) {
start := time.Now()
fn()
fmt.Printf("%s %v seconds\n", descr, time.Since(start))
}
func withoutPipelining() {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
for i := 0; i < 10000; i++ {
rdb.Ping(ctx)
}
}
func withPipelining() {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
pipe := rdb.Pipeline()
for i := 0; i < 10000; i++ {
pipe.Ping(ctx)
}
_, err := pipe.Exec(ctx)
if err != nil {
panic(err)
}
}
func main() {
bench("without pipelining", withoutPipelining)
bench("with pipelining", withPipelining)
}실행 결과는 다음과 같다.
go run main.go
without pipelining 668.024715ms seconds
with pipelining 9.112195ms seconds파이프라이닝을 사용하여 전송 속도를 향상시켰다!
결론
Redis 파이프라이닝(Pipelining)은 클라이언트가 모든 명령을 한 번에 보내고, 그 후에 일괄적으로 모든 응답을 받기 때문에 네트워크 오버헤드를 줄이고 처리 속도를 향상시킬 수 있다. 이를 통해 대규모 데이터 처리 및 응용 프로그램 성능을 향상시킬 수 있다. 그러나 응답 순서가 보장되지 않고, 서버의 메모리 사용량이 늘어날 수 있으므로 주의가 필요하다.
