Redis 해시 자료구조
Redis 해시 자료구조는 필드-값 쌍의 컬렉션으로 구성된 데이터 구조이다.
특징
- 구조화된 데이터 저장
- 해시는 필드-값 쌍으로 구성되어 있어서 구조화된 데이터를 저장하는 데 적합하다. 이를 통해 복잡한 객체를 단일 키로 저장할 수 있다.
- 고성능 검색
- 해시의 필드는 고유한 키이기 때문에 특정 필드에 대한 조회가 빠르게 이루어진다. 이는 대량의 데이터에서도 빠른 검색을 가능하게 한다.
- 메모리 최적화
- Redis는 메모리 기반의 데이터 저장소이기 때문에, 해시는 메모리를 효율적으로 사용한다. 필드와 값은 문자열이기 때문에 적은 메모리를 사용하여도 대용량의 데이터를 저장할 수 있다.
- 원자성 연산
- 해시는 원자성 연산을 지원하여, 여러 필드를 동시에 업데이트하거나 가져오는 등의 작업을 안전하게 수행할 수 있다.
Example
redis-cli
127.0.0.1:6379> HSET player:42 name jinjin race elf level 4 hp 20 gold 20
(integer) 5
127.0.0.1:6379> HGETALL player:42
1) "name"
2) "jin"
3) "race"
4) "elf"
5) "level"
6) "4"
7) "hp"
8) "20"
9) "gold"
10) "20"
127.0.0.1:6379> HSET player:42 status dazed
(integer) 1
127.0.0.1:6379> HDEL player:42 status
(integer) 1
127.0.0.1:6379> HGET player:42 level
"4"
127.0.0.1:6379> HINCRBY player:42 gold 120
(integer) 140Performance
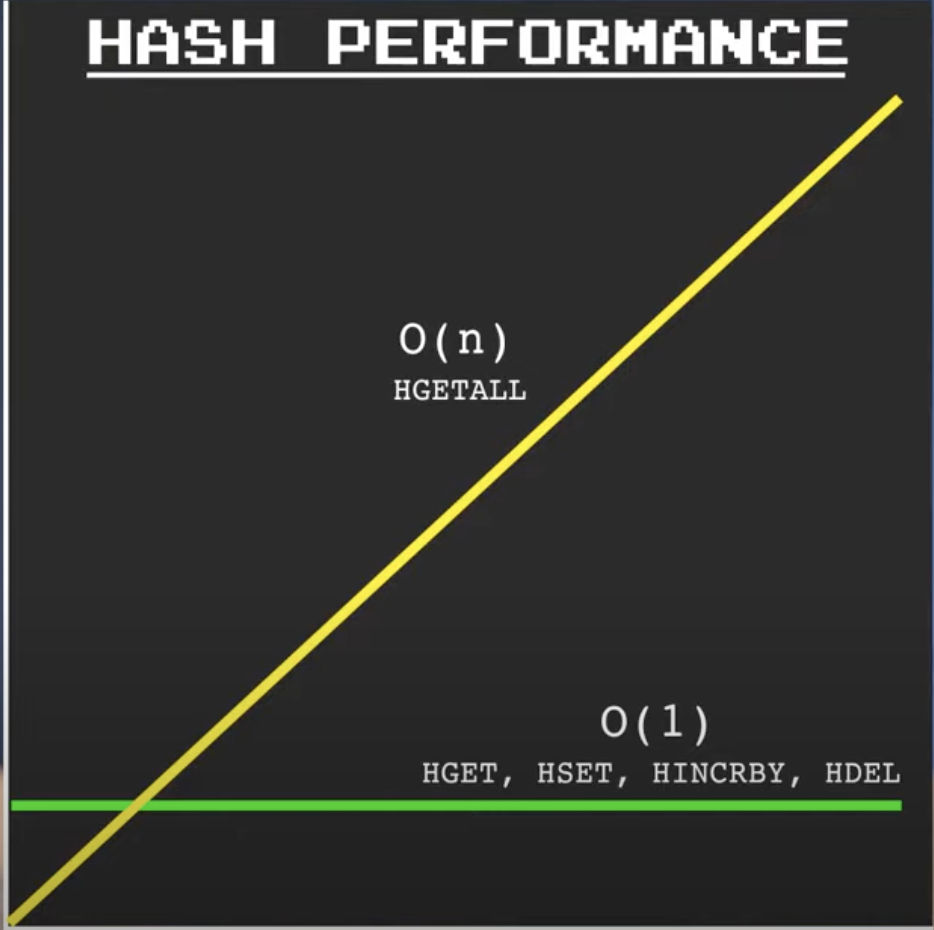
Redis 해시의 대부분의 명령어는 O(1) 복잡도를 가진다. 이는 명령어의 실행 시간이 해시의 크기에 관계없이 상수 시간에 유지된다는 것을 의미한다. 따라서 해시의 크기가 증가해도 명령어의 실행 시간에는 영향을 미치지 않는다.
그러나 몇 가지 명령어는 O(n) 복잡도를 가진다. 예를 들어, HKEYS, HVALS, HGETALL과 같은 명령어는 필드-값 쌍의 개수(n)에 비례하여 실행 시간이 증가한다. 이는 해당 명령어가 모든 필드나 모든 값을 반환해야 하기 때문에 발생한다. 필드나 값의 수가 증가하면 이러한 명령어의 실행 시간도 증가할 수 있다.
HSET
Redis의 HSET 명령어는 해시(hash) 데이터 구조에 새로운 필드-값 쌍을 추가하거나 기존 필드의 값을 업데이트하는 명렁어이다.
Syntax
HSET key field value [field value ...]key는 해시의 키를 나타내며,field는 추가하거나 업데이트하고자 하는 필드를 나타낸다.value는 해당 필드에 설정하고 하는 값이다.- 만약
field가 이미 존재하는 경우에는 해당 필드의 값을value로 업데이트하고, 존재하지 않는 경우에는 새로운 필드-값 쌍을 추가한다.
Example
HSET user:1000 username cindy age 15 email cindy@email.com
HSET user:1000 age 20 # user:1000 해시의 age 필드의 값을 20으로 업데이트한다.HINCRBY
Redis의 HINCRBY 명령어는 해시(hash) 데이터 구조에서 지정된 필드(field)의 값을 정수로 증가시키는 명령어이다. 만약 해당 필드가 존재하지 않는 경우, 새로운 필드를 생성하고 값을 증가시킨다.
Syntax
HINCRBY key field incrementkey는 해시의 키를 나타내며,field는 증가시킬 값을 갖는 필드를 나타낸다.increment는 해당 필드의 값을 증가시킬 양을 나타낸다.increment는 반드시 정수여야 한다.
Example
HSET user:1000 visits 10
HINCRBY user:1000 visits 1 # user:100 해시의 visits 필드의 값을 1 증가시킨다.
# 실행 후의 값은 11이 된다.HGET
Redis의 HGET 명령어는 해시(hash) 데이터 구조에서 지정된 필드(field)에 해당하는 값을 가져오는 명령어이다. 해시는 키(key)와 여러 개의 필드-값 쌍으로 구성된 데이터 구조로, 필드는 고유한 식별자이며 값은 해당 필드에 저장된 데이터이다.
Syntax
HGET key fieldkey는 해시의 키를 나타내며,field는 가져오고자 하는 값의 필드를 나타낸다.- 명령어를 실행하면 해당 필드에 대응하는 값을 반환한다.
- 만약 필드가 존재하지 않는다면 nil을 반환한다.
Examples
HSET user:1000 username cindy
HSET user:1000 age 15
HGET user:1000 username # cindy 반환
HGET user:1000 age # 15 반환
HGET user:1000 what # nil 반환HGETALL
Redis의 HGETALL 명령어는 해시(hash) 데이터 구조 내의 모든 필드-값 쌍을 가져오는 명령어이다. 해시는 키(key)와 여러 개의 필드-값 쌍으로 구성된 데이터 구조이며, HGETALL 명령어를 사용하면 해당 해시의 모든 내용을 가져올 수 있다.
Syntax
HGETALL keykey는 해시의 키를 나타낸다.- 명령어를 실행하면 해당 해시에 저장된 모든 필드-값 쌍이 반환된다.
- 반환된 값은 필드와 값이 번갈아 나타나는 배열 형태이다.
Examples
HSET user:1000 username cindy
HSET user:1000 age 15
HGETALL user:1000 # 아래 결과를 반환한다
1) "username" # field1
2) "cindy" # value1
3) "age" # field2
4) "15" # value2주의점
HGETALL 명령어를 사용할 때 몇 가지 주의할 점이 있다.
- 성능 고려:
HGETALL명령어는 해시에 저장된 모든 필드-값 쌍을 가져오므로, 해시의 크기가 크면 성능에 영향을 줄 수 있다. 특히, 큰 해시를 사용할 때는 네트워크 대역폭이나 Redis 인스턴스의 메모리 사용량을 고려해야 한다. - 메모리 사용량:
HGETALL은 전체 해시를 가져오므로, Redis 인스턴스의 메모리 사용량에 영향을 줄 수 있다. 만약 메모리 사용량이 중요한 경우, 필요한 필드만 가져오는 개별적인HGET명령어를 사용하는 것이 더 효율적일 수 있다. - 네트워크 부하:
HGETALL명령어는 모든 필드-값 쌍을 한 번에 가져오므로, 네트워크 부하를 유발할 수 있다. 특히, 클라이언트와 Redis 서버 간의 네트워크가 느린 경우에는 이러한 부하에 대해 고려해야 한다. - 결과 순서:
HGETALL명령어는 필드-값 쌍을 반환할 때 순서를 보장하지 않는다. 따라서 반환된 필드-값 쌍의 순서가 항상 일정하지 않을 수 있다. 필요에 따라 명시적으로 정렬을 수행해야 할 수 있다.
만약 16GB RAM vs 4GB RAM 컴퓨터에서 3GB HGETALL을 한다면...
16GB RAM 컴퓨터와 4GB RAM 컴퓨터에서 3GB HGETALL을 한다면 성능적으로 어떤 차이가 있을까?
- 메모리 용량에 따른 스왑
- 16GB RAM: HGETALL 작업에 충분한 메모리 공간을 제공하여 데이터를 메모리에 직접 저장하고 처리할 수 있다. 스왑 가능성이 낮아 성능 저하 가능성이 낮다.
- 4GB RAM: HGETALL 작업에 필요한 메모리 공간이 부족하여 데이터를 디스크에 저장하고 필요할 때마다 로드해야 한다. 메모리 부족으로 인해 스왑 사용 가능성이 높아 성능 저하가 발생할 수 있다.
- 메모리 대역폭 (단위 시간당 메모리와 CPU 사이에서 전송될 수 있는 데이터의 최대량)
- 16GB RAM: 더 높은 메모리 대역폭을 제공하여 데이터를 더 빠르게 처리할 수 있다.
- 4GB RAM: 더 낮은 메모리 대역폭으로 데이터 처리 속도가 느려진다.
- CPU 캐시
- 16GB RAM: 더 큰 CPU 캐시를 사용하여 데이터를 더 빠르게 처리할 수 있다.
- 4GB RAM: 더 작은 CPU 캐시를 사용하여 데이터 처리 속도가 느려진다.
실무 활용 예시
- 사용자 프로필 관리
- 사용자의 프로필 정보를 해시로 저장할 수 있다. 각 사용자의 고유 식별자를 키로 사용하고, 해당 사용자의 이름, 이메일, 나이 등을 필드로 저장할 수 있다.
HMSET user:1 name "John" email "john@example.com" age 30 - 제품 카탈로그
- 제품 정보를 해시로 저장하여 제품 카탈로그를 구축할 수 있다. 제품 ID를 키로 사용하고, 제품의 이름, 설명, 가격 등을 필드로 저장할 수 있다.
HMSET product:1234 name "Smartphone" description "High-end smartphone" - 세션 관리
- 사용자의 세션 정보를 해시로 저장하여 로그인 상태 및 기타 세션 관련 정보를 관리할 수 있다. 세션 ID를 키로 사용하고, 사용자 ID, 로그인 시간, 세션 유효 기간 등을 필드로 저장할 수 있다.
HMSET session:abcd1234 user_id 1234 login_time 2024-02-20T15:00:00 expiry_time 2024-02-20T16:00:00 - 카운팅 및 집계
- 특정 이벤트나 항목에 대한 카운팅 및 집계 정보를 해시로 저장할 수 있다. 이를 통해 사용자의 행동이나 애플리케이션의 상태를 추적하고 분석할 수 있다.
HINCRBY event:login:20240220 user_count 1
LINK
