
📝이 포스트는 K-means clustering 에 대해 알아보겠습니다.
정의
-
K-평균 클러스터링은 주어진 데이터를 k개의 군집(= class = cluster)로 묶는 알고리즘을 뜻합니다.
-
K-평균 군집화는 손실함수 값이 최소화될 때까지 군집의 중심(Centroid)과 각 데이터가 포함될 군집을 반복해서 계산한다.
-
이 K-평균 클러스터링은
: 군집의 개수
: 번째 군집에 속하는 데이터들의 집합
: 번째 군집의 무게중심(centroid)
: 와 사이의 거리를 뜻한다. 거리를 구하는 방법은 euclidean distance를 이용한다.
원리
- 무게중심을 랜덤하게 개 생성한다.
- 모든 데이터 에서 각각의 무게중심 까지의 거리를 계산한다.
- 각 데이터별로 가장 가까운 무게중심을 선택한다.
- 선택한 무게중심이 속하는 클러스터를 정한다.
- 각 클러스터에 대해 무게중심 를 다시 계산한다.
- 최적의 무게중심을 찾아 더 이상 무게중심의 위치가 변하지 않을 때 까지 '순서 1' 을 제외한 모든 순서를 반복한다.
코드 이해
저는 iris dataset을 이용하여 K-평균 클러스터링을 수행하였습니다.
⚠️각 라인별로 주석을 달아서 각 라인이 무슨 의미인지 알려드리겠습니다.
- 무게중심을 랜덤하게 K개 생성하는 함수를 정의한다.
def random_centroids(values, K): # K : 군집 개수
centroids = []
# K번 반복하여 values 데이터중에 K개를 무게중심으로 선언
for i in range(K):
centroid = values[rand.randint(0, len(values)-1)]
centroids.append(centroid)
return centroids- 모든 데이터 에서 각각의 무게중심 까지의 거리를 계산한다.
- 각 데이터별로 가장 가까운 무게중심을 선택한다.
- 선택한 무게중심이 속하는 클러스터를 정한다.
이 3개를 묶어 각 데이터별로 가장 가까운 군집에 소속시키는 함수를 정의한다.
def assign_cluster(values, centroids):
assignments = [] #cluster assignments
# 각 데이터들
for value in values:
# 하나의 데이터와 K개의 무게중심과의 거리를 저장할 변수
dist_point_clust = []
# 각 무게중심들
for centroid in centroids:
# 랜덤한 무게중심과 각 데이터 간의 인덱스별로 뺄셈을 수행하여 유클리드 거리를 구한다.
d_clust = np.linalg.norm(np.array(value) - np.array(centroid))
dist_point_clust.append(d_clust)
# 거리가 최소인 값의 인덱스를 저장
assignment = np.argmin(dist_point_clust)
assignments.append(assignment)
return assignments- 각 클러스터에 대해 무게중심 를 다시 계산한다.
def new_centroids(values, centroids, assignments, K):
# values : 데이터
# centroids : 무게중심들이 모인 리스트
# assignments : 각 점 별로 어느 군집에 속하는지 알 수 있는 리스트
# K : 군집의 개수
# 새롭게 계산될 무게중심을 추가할 리스트
new_centroids = []
for i in range(K):
# i_cluster :
i_cluster = []
for x in range(len(values)):
# x번째 데이터가 속한 군집이 i번째 군집과 같다면
if (assignments[x] == i):
# i_cluster에 추가
i_cluster.append(values[x]) # append all single cluster points
# 각 클러스터에 속하는 데이터들끼리 평균
mean_cluster = np.mean(i_cluster, axis=0) # mean value of the cluster points will serve as new centroid
# 계산된 평균 지점을 새로운 무게중심으로 설정
new_centroids.append(mean_cluster)
return new_centroids- 손실함수를 구한다. 손실함수가 어느 조건일 때까지 반복하여 무게중심을 재조정 하기 위해서 손실을 구한다.
def sse(values, assignments, centroids):
# values : 데이터
# assignments : 각 점 별로 어느 군집에 속하는지 알 수 있는 리스트
# centroids : 무게중심들이 모인 리스트
errors = []
for i in range(len(values)):
#get assigned centroid for each point
centroid = centroids[assignments[i]]
#compute the distance (error) between one point and its closest centroid
error = np.linalg.norm(np.array(values[i]) - np.array(centroid))
#append squared error to the list of error
errors.append(error**2)
#and sum up all the errors
sse = sum(errors)
return sse이 과정을 다 포괄하는 함수를 정의했다. 나중에 K-mean clustering을 쓰고 싶을 때 단 한 번의 함수 호출을 하기 위함이다.
def kmeans_clustering(values, K, max_iter = 100, tol = pow(10,-3) ):
# iteration : 반복 횟수
it = -1
all_sse = []
assignments = []
# STEP 1. 초기 랜덤 무게중심 생성
centroids = random_centroids(values, K)
# 에러가 1 이하이거나 최대반복횟수 아래의 반복중이면서 { (현재 손실 - 직전 과거 손실) / 직전 과거 손실 } 이 0.001 이상이면 반복 진행
while (len(all_sse)<=1 or (it < max_iter and np.absolute(all_sse[it] - all_sse[it-1])/all_sse[it-1] >= tol)):
it += 1
# STEP 2. 유클리드 거리 구하기
assignments = assign_cluster(values, centroids)
#STEP 3. 무게중심 재조정
centroids = new_centroids(values, centroids, assignments, K)
#STEP 4. 손실률 구하기
sse_kmeans = sse(values, assignments, centroids)
all_sse.append(sse_kmeans)
print('에러율 : {}'.format(sse_kmeans))
return (assignments, centroids, all_sse, it)적용 :
result = kmeans_clustering(values=values, K=4)에러율 : 76.01591907424665
에러율 : 72.44054722344684
에러율 : 71.33622242453569
에러율 : 71.33622242453569result 변수는 4차원 변수 일 것이다.
왜냐하면 kmean_clustering 메소드가 4개의 결과를 return하기 떄문에 길이가 4일 것이다.
이제 시각화를 하여 각 데이터들이 어느 군집에 속하는지 살펴보겠습니다.
centroids_x = [result[1][x][0] for x in range(len(result[1]))] #sepal_length: [0]
centroids_y = [result[1][x][2] for x in range(len(result[1]))] #petal_length: [2]
x = data['sepal_length']
y = data['petal_length']
assignments = result[0] # result[0] = assignments
# reuslt[1] = centroids
# result[2] = all_sse
# result[3] = it
plt.scatter(x, y, c=assignments)
plt.plot(centroids_x,centroids_y, c='white', marker='.', linewidth='0.01', markerfacecolor='red', markersize=22)
plt.title("K-means Visualization")
plt.xlabel("sepal_length")
plt.ylabel("petal_length")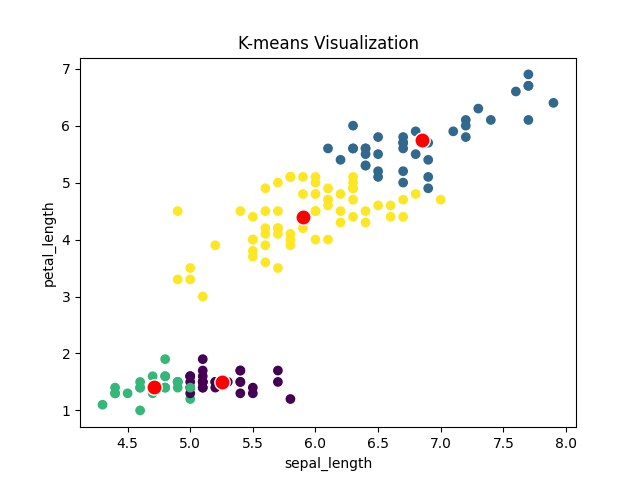
보시는 바와 같이 kmean_clustering() 메소드에 K=4 라고 파라미터를 입력하여 centroid(빨간색 점)이 4개이고 노란색, 남색, 보라색, 초록색이 각각의 군집입니다.
💻 따라서 해당 데이터의 라벨을 모르는 상태에서 분류를 하여야 할 때 무게중심이라는 개념을 통해서 무게중심과의 거리를 계산하여 클래스(군집)을 만들어주는 역할이 필요합니다.
이럴 때 K-means-clustering 알고리즘을 이용하여 클래스별로 데이터를 묶어 줄 수 있습니다.
