[논문리뷰] CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
Anomaly Detection

📝 이번 포스트는 "CutPaste: Self-Supervised Learning for Anomaly Detection and Localization" 논문에 대해 알아보도록 하겠습니다.
1. 논문의 배경
일반적인 supervised classification 문제와 다르게, anomaly detection은 고유한 문제를 직면하고 있습니다.
- 막대한 양의 label data와 unlabel data를 구하기가 어렵습니다.
- 정상과 이상 패턴의 차이가 미세(fine-grained)한 경우가 많으며, 고해상도 이미지에서는 anomaly가 아주 작을 수 있습니다.
대부분의 Anomaly Detection의 접근 방법은 아래와 같습니다.
사전에 anomaly 패턴이 어떤 식으로 나오는지 모르기 때문에 정상 데이터로 학습하고, 테스트 시에 학습된 모델이 데이터를 입력받았을 때 잘 representation 되지 못하면 anomaly라고 판단하도록 모델을 훈련시킵니다.
이 논문은 고해상도 이미지에서 다양한 형태의 알려지지 않은 anomaly 패턴이 존재하는 이미지의 one-class anomaly detection 문제를 해결하고자 연구되었습니다.
2. A Framework for Anomaly Detection
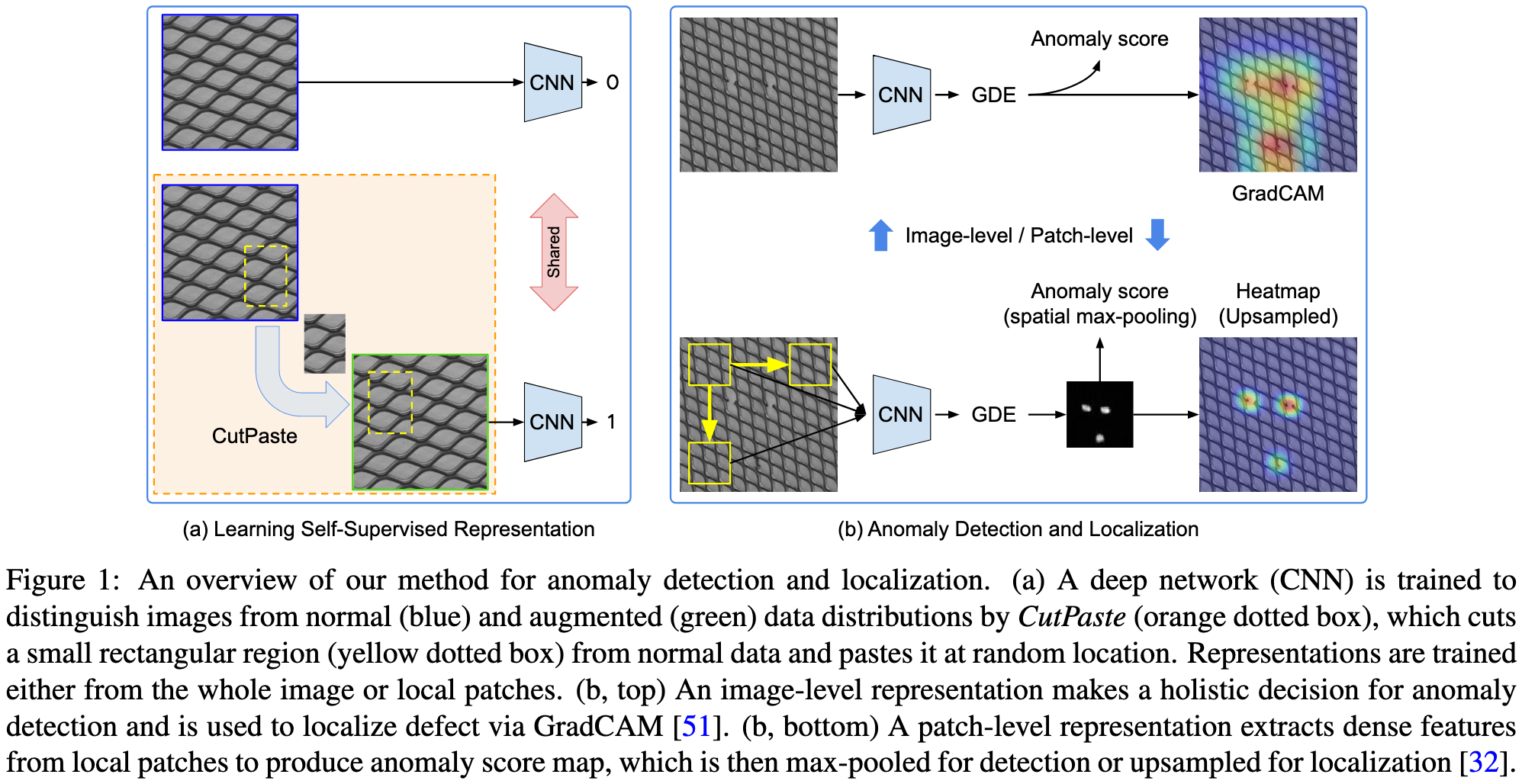
본 단락에서는 저자의 고해상도 이미지에 대한 anomaly detection 프레임워크를 설명드리겠습니다.
2.1. Self-Supervised Learning with CutPaste

Self-Supervised Learning은 pretext task를 정의하는 것이 중요합니다.
저자의 목표는 local 불규칙적인 패턴을 생성하는 증강 기법을 디자인하는 것이였습니다.
그리고 모델을 이 local 불규칙성을 식별하게 학습시킴으로써 테스트 시에 보지못한 실제 anomaly 데이터를 일반화하는 것을 목표로 합니다.
local한 불규칙성을 생성하는 데이터 증강기법으로는 Cutout이 있습니다.
Cutout은 이미지의 랜덤한 직사각형 영역을 없애는 증강기법입니다.
Cutout은 multi-class classification의 정확도를 향상시키는 불변성(invariance)를 강화하는 데이터 증강 방법으로 알려져 있습니다.
추후에 Cutout과 저자의 방법론과 비교실험을 합니다.
CutPaste는 증강된 이미지를 구별하는 단순한 decision rule 학습을 방지하고 모델이 불규칙성을 탐지하도록 학습시키기 위한 방법입니다.
CUtPaste 절차는 아래와 같습니다.
- 정상 train 이미지에서 가변 크기의 직사각형 영역을 자릅니다.
- 선택적으로, 패치의 픽셀 값을 회전시키거나 이동시킵니다.
- 잘라낸 패치를 잘라내었던 정상 train 이미지에 다시 붙여넣습니다.
: 정상 데이터의 집합
: CupPaste 증강기법
: binary classifier
: cross-entropy loss
위는 훈련 중에 구하는 손실함수입니다.
2.2.CutPaste Variants
CutPaste-Scar
CutPaste로부터 파생된 증강기법으로, 길고 얇은 직사각형 모양의 상자를 랜덤한 색상으로 채우는 증강기법입니다.
scar는 Figure 2의 (d)에 언급되어있습니다. 자세한 이해는 위 Figure 2를 참조하시면 되겠습니다.
Similarity between CutPaste and real defects
CutPaste의 성공은 outlier exposure로 설명할 수 있는데, 훈련 중에 pseudo anomaly를 생성하는 것입니다.
Outlier exposure와 같이 natural image를 사용하는 것과 달리, CutPaste는 정상 이미지의 local structure를 더많이 보존하는 이미지를 생성하여, 모델이 이 불규칙성(irregularity)를 찾는 데 더 적극적입니다.

CutPaste 방법은 실제 결함과 비슷해보입니다.
따라서 CutPaste의 성공이 실제 defect를 잘 모방한 것인지 확인이 필요합니다.
Figure 3에서는 학습된 모델의 representation을 시각화한 t-SNE입니다.
t-SNE란?
t-distributed Stochastic Neighbor Embedding의 약자로,
고차원 데이터를 저차원 공간으로 시각화하기 위해 사용되는 비선형 차원축소 기법입니다.
Figure 3의 Patch 클래스가 CutPaste를 뜻합니다.
CutPaste가 완벽하게 Anomaly와 같은 분포를 같지는 않지만, 정상 샘플들과는 확연히 분포가 차이가 나는 것을 보실 수 있습니다.
이를 통해서 불확실성(irregularity)을 학습하는 것이 보지 못한 anomaly를 잘 일반화한다는 것을 의미합니다.
2.3. Computing Anomaly Score
저자는 representation에 대해 KDE(kernel density estimator)나 GDE(Gaussian density estimator)와 같은 generative classifier를 구축하였습니다.
nonparametric KDE 분포 가정에 대해서 자유롭지만, 정확한 추정을 위해 많은 example이 필요로 하고 계산 비용이 많이 들 수 있습니다.
제한된 데이터셋 상황에서, 저자는 단순한 parametric 가우시안 밀도 추정법(GDE)을 고려하여 가우시안 밀도는 다음과 같이 계산됩니다.
와 은 정상 데이터로부터 학습된 값입니다.
2.4. Localization with Patch Representation
object detector와 같은 local 정보를 찾는 anomaly detector를 만들었습니다.
전체적인 representation을 학습하는 대신, 이미지 수준의 탐지외에 결함 영역을 local화하려면 이미지 패치의 representation을 학습하는 것이 더 좋습니다.
CutPaste 예측은 패치 representaiton 학습에 쉽게 적용할 수 있으며, 학습 시 CutPaste 증강을 적용하기 전에 패치를 잘라내면 됩니다.
는 임의 위치에서 패치를 crop하는 함수를 뜻합니다.
테스트 시에는 주어진 간격으로 모든 패치로부터 임베딩을 추출합니다.
각 패치에 대해, 저자는 anomaly score를 평가하고 가우시안 스무딩을 사용해 각 픽셀의 점수를 propagate합니다.
3. Related Work
3.1. Relation to Other Augmentaitons
Cutout & RandomErasing
Cutout과 RandomErasing은 CutPaste와 유사하지만, 작은 직사각형 영역을 0이나 균일하게 샘플링된 픽셀 값으로 채워 불규칙성(irregularity)을 생성하며, CutPaste처럼 이미지 패치로 채우지는 않습니다.
Scar
Scar는 랜덤한 색상의 긴 얇은 직사각형을 사용하는 증강기법입니다.
CutPaste의 이미지 패치와는 차원이 다르게 작아서 학습된 representation보다 성능이 낮습니다.
CutMix
CutMix는 A이미지에서 조그마한 이미지 패치를 추출하여 B이미지의 랜덤한 위치에 붙이는 증강기법입니다.
이미지 패치를 잘라서 붙이는 방법은 CutPaste와 유사하지만, 어느 이미지에 붙이냐는 차이입니다.
4. Experiments
저자는 MVTec 데이터셋으로 실험을 진행하였습니다.
ResNet-18을 기반한 모델을 사용하였고 one-class classification을 수행하였습니다.
모델의 디테일한 구조는 average pooling layer와 마지막 linear layer에 MLP projection 헤드를 추가하여, 처음부터 augmentation prediction으으로 respresentation을 학습하였습니다.
그 후 최종 pooling된 feature에 대해 가우시안 밀도 추정법을 기반으로 anomaly detector를 구축하였습니다.
모델에는 256x256 크기의 이미지가 입력으로 주어집니다.
다른 증강기법들과 비교하여 CutPaste가 더 좋은 성능을 보임을 증명하였습니다.
