[논문리뷰] MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection
Anomaly Detection

📝 이번 포스트는 "MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection"논문에 대해 알아보도록 하겠습니다.
Anomaly Detection 작업을 맡게 되어 벤치마크 데이터셋에 대해 알아봐야겠다고 생각하여 이 논문을 읽게 되었습니다.
1. Introduction
사람은 지금 본 것이 이전에 본 이미지와 유사한 지, 이상한 것인지 인식할 수 있습니다.
하지만 머신러닝 시스템은 이러한 작업에서 어려움을 겪고 있고 있습니다.
한 가지 예로, 제조 산업에서 광학 검사 작업에서 결함이 있는 샘플이 부족하거나 어떤 종류의 결함이 발견될지 명확하지 않은 경우가 있습니다.
이상 탐지 분야의 벤치마크인 MVTEC 데이터셋의 특징 아래와 같습니다.
MVTEC이란?
실제 산업 검사 현장을 바탕으로, 5개의 텍스쳐와 10개의 서로 다른 도메인의 객체로 구성된 고해상도 5354개 이미지를 포함하고 있습니다.
이 객체에는 73가지의 서로 다른 anomaly가 존재합니다.
각 anomaly 이미지에 대해 1888개의 픽셀단위의 ground-truth 영역을 제공하여 one-class classification과 anomaly detection을 평가할 수 있습니다.
이상 탐지 분야의 벤치마크인 MVTEC을 활용하였던 방법들을 설명합니다.
2. Related Work
용어정리
이상 탐지 분야 논문을 읽다면 같은 용어인데 다르게 말하는 경우가 있습니다.
outlier = defect = anomaly
inlier = defect-free = normal
이렇게 알아두시고 이 분야 논문을 읽으시면 됩니다.
2.1. Existing Datasets for Anomaly Detection
MVTEC 데이터셋은 defect 이미지와 defect-free 이미지를 구별하는 simple binary decision 데이터셋과 segmentation of anomalous regions 데이터셋을 설명합니다.
2.1.1. Classification of Anomalous Images
outlier detection할 때, MNIST, CIFAR10, ImageNet같은 데이터셋은 클래스를 inlier와 outlier로 재레이블링하여 inlier(정상) 이미지만 사용하여 학습을 하는 방법입니다.
그리고 테스트할 때 inlier로 훈련된 모델이 입력되는 이미지가 inlier인지 아닌지를 판별을 합니다.
2.1.2. Segmentation of Anomalous Regions
이미지의 anomaly segment를 다루는 공공 데이터셋은 매우 적습니다.
그 공공 데이터셋 중 NanoTWICE 라는 데이터셋은 현미경으로 나노 섬유 텍스쳐를 촬영한 45개의 grayscale 이미지로 구성되어 있는데, 5개가 정상이고 40개가 비정상 이미지로 구성되어 있습니다.
DAGM 워크숍에서 사용한 데이터셋도 있습니다.
이 데이터셋은 10개의 grayscale 텍스쳐 클래스를 갖고, 각 클래스는 1000개의 정상이미지와 150개의 비정상 이미지로 구성되어있습니다.
하지만 annotation이 형편없어서 일반화를 잘 할지 불분명합니다.
2.2. Methods
연구와 관련된 SOTA 방법론들에 대한 간략한 설명합니다.
2.2.1. Generative Adversarial Networks
GAN은 정상 이미지로만 훈련하여 학습한대로 얼추 비슷한 이미지를 생성하는 방법론입니다.
이상 탐지를 위해서 GAN은 주어진 입력 이미지를 재현하고 discriminator를 속일 수 있는 latent 샘플을 찾습니다.
anomaly segmentation은 재구성하여 생성된 이미지와 입력 이미지를 픽셀 단위로 비교하여 구합니다.
2.2.2. Deep Convolutional Autoencoders
Convolutional Autoencoders는 비지도학습 이상 탐지 분야에서 주로 사용됩니다.
이들은 정상 학습 이미지를 bottle neck(latent space)을 통해 재구성합니다.
테스트 시에는 학습시에 학습한 데이터 이외의 데이터를 생성해내지 못합니다.
그리고 입력 이미지와 재구성된 이미지의 픽셀 단위 비교를 통하여 anomaly를 감지합니다.
2.2.3. Features of Pre-trained Convolutional Neural Networks
과거에 ImageNet 데이터셋으로 pre-train된 ResNet-18 신경망으로 이상탐지 작업을 하였습니다.
그들의 single class classification을 위해 설계되었기 때문에 입력 이미지에 이상이 있는지 여부를 binary decision을 통해 결정합니다.
spatial anomaly map을 얻기 위해서 classifier는 여러 이미지 location을 evaluate해야하고, 개별 픽셀에서 평가해야 한다.
그러나 큰 이미지에서는 병목 현상이 발생하고, 성능을 높이기 위해서 모든 픽셀 위치가 evaluate하지 않아서 그 결과 anomaly map이 이상해집니다.
2.2.4. Traditional Methods
Gaussian Mixture Model은 feature vector의 분포를 만들어냅니다.
GMM에서 낮은 확률을 보이는 추출된 feature는 이상으로 감지된다.
하지만 이 알고리즘은 규칙적인 텍스쳐 이미지에만 적용되었습니다.
또한 variation model을 텍스쳐가 아닌 객체에 대한 간단한 baseline을 획득하기 위해 고려해보았습니다.
이 모델은 사전 객체 컨투어가 필요하며, 각 픽셀에 대한 평균과 표준편차를 계산하여 훈련 이미지의 gray-scale값 statics을 모델링합니다.
테스트 시에는 각 이미지 픽셀의 gray-scale 값이 평균에서 얼마나 벗어났는지를 측정하는 통계적 테스트가 수행됩니다.
편차가 threshold보다 높으면 해당 픽셀은 anomaly로 감지합니다.
3. Dataset Description
MVTec Anomaly Detection 데이터셋은 15개의 카테고리로 구성되어 있습니다.
3629개의 train과 validation 이미지와 1725개의 test 이미지로 구성되어있습니다.
train 데이터셋에는 정상 이미지들로만 구성되어 있고, test 데이터셋에는 anomaly 이미지와 정상 이미지로 구성됩니다.
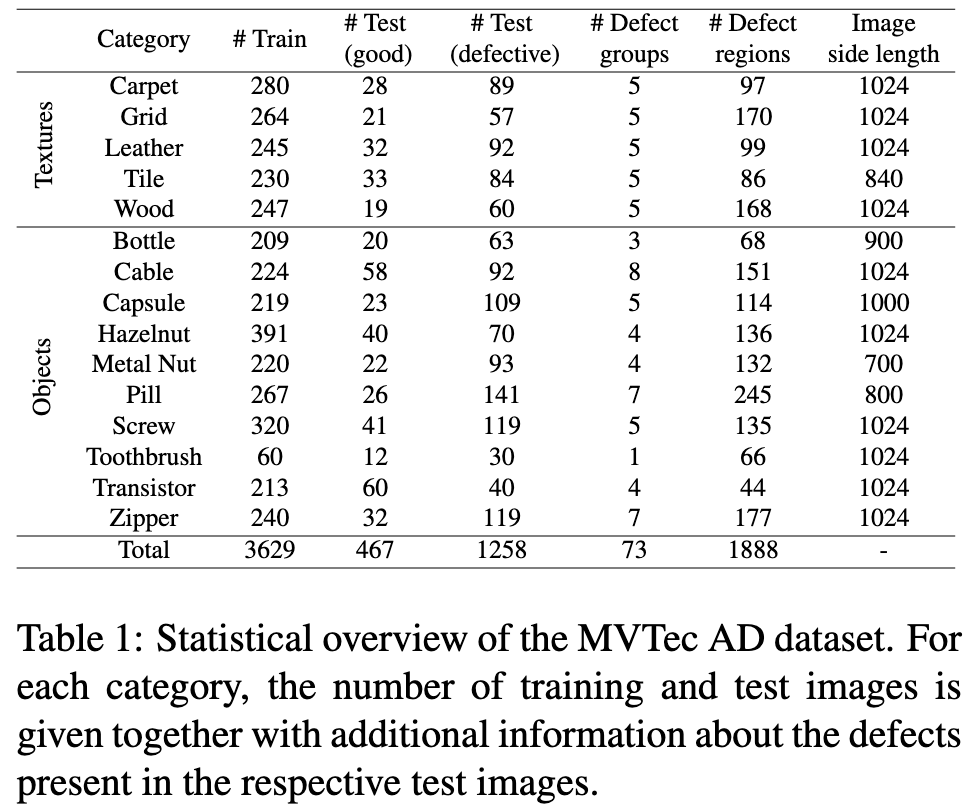
를 보면 어떻게 구성되는지 이해할 수 있습니다.
5개의 카테고리는 텍스쳐(카펫, 그리드, 가죽, 타일, 나무)를 포함하고, 나머지 10개는 병, 금속너트, 케이블 등이 있습니다.
모든 이미지는 700x700에서 1024x1024 픽셀의 RGB 혹은 gray-scale 해상도를 갖습니다.
