[논문리뷰] EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies
Anomaly Detection

📝 이번 포스트는 "EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies" 논문에 대해 알아보도록 하겠습니다.
1. Why : 논문의 연구 배경
Visual Anomaly Detection 분야는 산업용 Anomaly Detection에서 빠른 발전을 이루고 있습니다.
빠른 발전에도 불구하고 SOTA 방법론들은 성능 향상을 위해 계산 효율성을 희생하기도 합니다.
실제 Anomaly Detection 응용 분야에서 계산 자원에 대한 제약이 발생합니다.
예를 들어 공장 작업자의 신체에 칼날이 가까워지는 위험한 상황 같은 경우 시간적 비용을 줄이는 것을 요구됩니다.
따라서 real-time을 요구하는 실제 응용분야는 anomaly detection 방법을 real-time에 가깝게 하여 계산 및 경제적 비용을 고려하는 것이 중요합니다.
따라서 저자는 EfficientAD라는 방법론을 소개합니다.
이 방법론은 anomaly detection 성능과 이미지처리량과 실행시간 면에서 좋은 결과를 보였습니다.
이 방법론은 현대 최신 GPU에서 1ms 미만의 시간에 feature를 추출할 수 있는 신경망(CNN)과 Student-Teacher 모델로 구성되어 있습니다.
2. How : 연구 방법론
2.1 Efficient Patch Descriptors
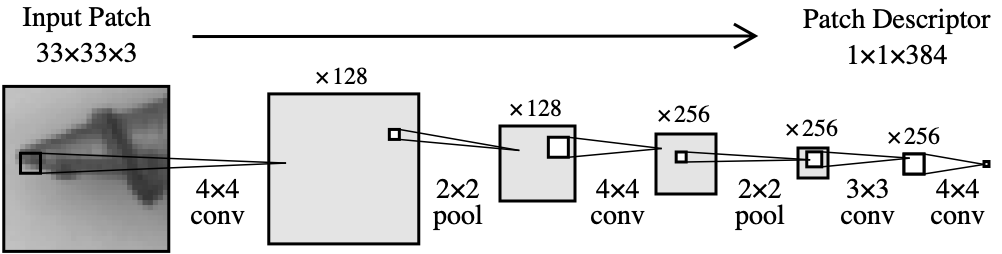
최신 anomaly detection 방법론들은 WideResNet-101과 같은 deep pretrained network를 주로 사용합니다.
반면 저자는 4개의 합성곱층만으로 이루어진 얕은 feature extractor를 사용합니다.
위 그림을 보면 33 33 크기의 패치를 입력받아서 feature vector를 출력합니다.
이 신경망을 PDN(Patch Descriptor Network)라고 부르며, 자세한 구조는 위 그림에 설명되어있습니다.
PDN이 표현력있는(expressive) feature를 생성하기 위해 pretrained network를 사용합니다.
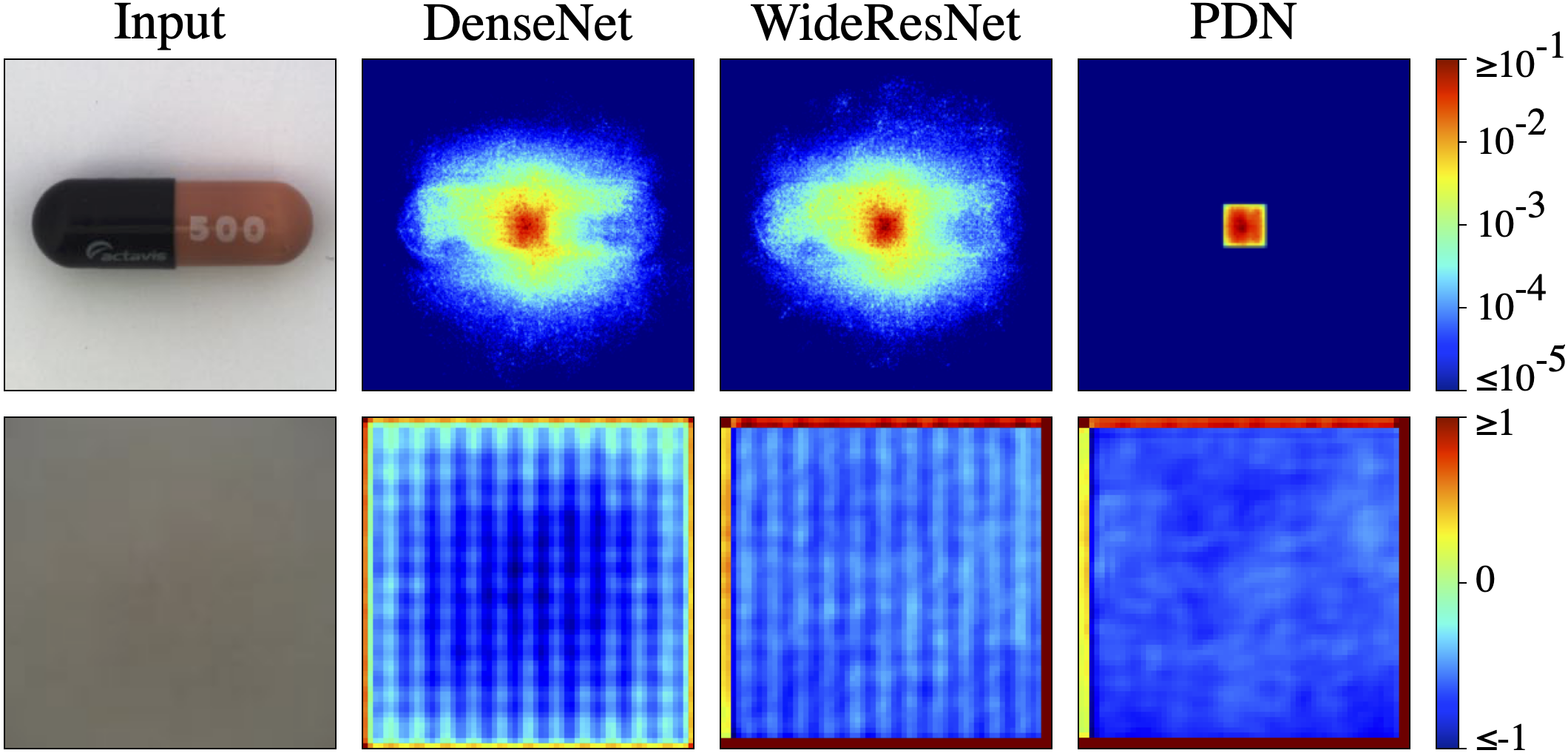
PDN의 또다른 장점은 33 33 패치 내의 픽셀에만 의존한다는 점입니다.
바로 위 그림으로 설명을 드리겠습니다.
- Upper row
feature vector의 absolute gradient를 시각화한 것입니다.
각 입력 픽셀별로 계산된 gradient를 입력과 출력 채널의 평균을 구한것입니다.- DenseNet과 WideResNet의 gradient는 넓게 분산되어 있는 것을 볼 수 있는데 이것은 이미지의 global한 feature를 학습하여 집중도가 낮음을 의미합니다.
- PDN의 경우, gradient가 거의 linear하지 못하고 discrete하게 차이가 나는 것을 볼 수 있는데, 이것은 local한 feature를 학습하며 집중도가 높음을 의미합니다. 33 33 크기의 패치로 학습을 하여 이러한 결과를 도출할 수 있었다고 합니다.
- Lower row
ImageNet 데이터셋에서 임의로 선택한 1000장의 첫 번째 출력 채널에 대한 feature map의 평균을 뜻합니다.- DenseNet과 WideResNet의 feature map은 그리드 패턴과 노이즈가 두드러지게 나타나는 것을 확인할 수 있습니다.
- PDN의 경우, 비교적 더 깔끔하고 노이즈가 적음을 보여주며, 이는 즉 효율적인고 정확한 feature expression이 가능하다고 해석할 수 있습니다.
2.2. Lightweight Student-Teacher
pretrained PDN을 사용하는 Teacher을 이용하여 Student-Teacher 방법론을 사용합니다.
또한 Student도 이런 light한 PDN을 적용합니다.
하지만 기존 Student-Teacher 모델에서 사용하던 앙상블, 계층적 피라미드 구조, Student-Teacher간의 구조적 비대칭성을 사용하지 않습니다.
이러한 차이에 대처하기 위해 이상탐지 성능을 향상시키면서도 테스트 시에 계산량에 영향을 미치지 않는 훈련 손실함수를 제안합니다.
저자의 목표는 Student가 정상 이미지에서 충분히 Teacher를 모방할 수 있도록 데이터를 충분히 보여주면서 anomaly 이미지에 대해 일반화하는 것을 피하는 것입니다.
이를 구현하기 위해 Online Hard Example Mining과 유사한 이미지의 가장 중요한 부분에만 Student의 손실함수를 제한하는 것입니다.
이것을 Hard Feature Loss라고 부릅니다.
Hard Feature Loss 구하는 방법
1. 선생 와 Student 는 이미지 에 대해 신경망의 출력으로 와 를 출력
2. 각 튜플(, , )에 대해 와 의 제곱 오차를 계산 :
3. mining fator 에 따라 요소의 분위수(quantile)인 를 계산
4. 이상인 의 평균을 훈련 손실함수 로 설정
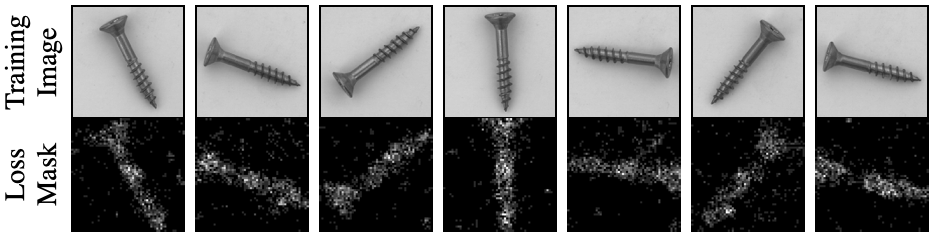
위 그림은 Hard Feature Loss를 통해 생선된 Loss Mask를 가시적으로 보여준 그림입니다.
특정 영역의 feature vector가 역전파에 얼마나 기여되었는지를 나타냅니다.
- Loss Mask의 밝은 부분 : 해당 영역의 feature vector가 역전파 때 많이 선택된 픽셀임을 뜻함
- Loss Mask의 어두운 부분 : 상대적으로 덜 선택된 픽셀임을 뜻함
추론 시에는 2D anomaly score map 를 생성합니다.
이며, 3채널의 평균으로 구해지는 것을 뜻합니다.
추가로 정상 학습 이미지가 아닌 이미지에서 Teacher를 모방하는 것을 못하게 하기 위해 훈련 중 손실 패널티(loss penalty)를 도입했습니다.
이 말은 즉, Teacher는 ImageNet과 같은 거대한 데이터셋에서 학습한 반면, Student는 응용할 분야의 작은 데이터셋을 학습하는데, Student의 훈련 과정에 임의로 Teacher가 학습한 거대한 데이터셋의 일부를 첨가하는 것을 뜻합니다.
Teacher가 학습할 때 사용한 거대한 데이터셋의 이미지 를 Student가 학습에서 만날 때 손실함수를 구하게 됩니다.
손실 패널티는
로 나타낼 수 있습니다.
는 Student의 손실패널티를 뜻하며,
는 전에 구했던 Hard Feature Loss를 뜻하며,
는 Frobenius Norm Regularization으로 구하는 방법입니다.
1차원(C, W, H) 값들에 대해 Frobenius Norm을 구하는 것입니다.
Frobenius Norm이란?
행렬의 크기를 측정하는데 사용하는 Norm으로 행렬의 모든 원소를 제곱한 값을 합한 다음, 제곱근을 한 값으로 정의됩니다.
벡터의 L2 Norm을 행렬에 적용한 방법입니다.로 나타낼 수 있습니다.
이를 통해 Student가 자신의 도메인 이미지(MVTec)가 아닌 out-of-distribution 이미지(ImageNet)에서도 Teacher를 모방하려는 것을 방지할 수 있습니다.
2.3. Logical Anomaly Detection

Logical Anomaly는 missing, misplace, surplus object, violation of geometrical constraint가 있습니다.
저자는 이러한 논리적 제약을 탐지하기 위해 오토인코더를 사용합니다.
저자가 사용한 오토인코더는 표준적으로 사용하는 오토인코더 구조인 인코더에는 stride 기반 convolution 레이어를 사용하고, 디코더에는 bilinear upsampling을 사용하는 구조를 따릅니다.
손실함수는 아래와 같습니다.
는 이미지를 뜻하고, 는 인코더의 출력 는 Teacher의 출력을 뜻합니다.
하지만 오토인코더는 logical anomaly를 reconstruction할 때 문제점이 있습니다.
이 문제점을 해결하기 위해, Student의 아웃풋 채널 수를 두배로 늘리고, 오토인코더와 Teacher의 출력을 예측하도록 훈련합니다.
이 추가적인 출력 에 대한 손실함수는 이와 같습니다.
그리고 최종 학습 손실함수는 로 정의됩니다.
Student는 학습 시에 정상 이미지에서 발생하는 오토인코더의 reconstruction error를 학습하는 반면에, 학습 시에 anomaly 이미지에 대해서는 reconstruction error를 학습하지 않습니다.
이유는 학습데이터셋이 아니기 때문입니다.
그리고 anomaly map는 아래와 같이 만들어집니다.
Student와 Teacher의 출력 간의 제곱오차로 구해지며, 이 anomaly map은 Local anomaly map이라고 합니다.
Student와 오토인코더의 출력 간의 제곱오차로 구해지는 것은 Global anomaly map이라고 합니다.
그 후 Local anomaly map과 Global anomaly map으로 평균을 구합니다.
이 평균된 anomaly map의 최대 값을 anomaly score로 사용합니다.
이러한 구조는 structural & logical anomaly를 모두 탐지하면서도 낮은 계산량을 유지할 수 있게 합니다.
2.4. Anomaly Map Normalization
local과 global anomaly map을 평균내기 전에 normalization을 수행해야 합니다.
1. 정상 이미지 속 노이즈의 스케일을 추정하기 위해 validation 이미지를 사용합니다.
각 두 anomaly map에 대해 validation 이미지의 모든 픽셀 anomaly score를 계산합니다.
2. -분위수 와 를 계산합니다.
각 p는 a와 b입니다.
3. 를 anomaly score 0으로, 를 anomaly score 0.1로 매핑하는 선형 변환을 수행합니다.
4. 테스트 시에는, local과 global anomaly map은 각각의 선형 변환을 사용해 정규화합니다.
그 이후에 평균을 구하는 것입니다.
3. Experiments
실험에 사용되는 EfficientAD는 2가지입니다.
EfficientAD-S와 EfficientAD-M입니다.
EfficientAD-S는 위에 설명한 그대로의 PDN 구조를 갖으며, EfficientAD-M은 교사와 학생 둘 다 PDN구조가 살짝 변형됩니다.
2번째 pooling layer와 마지막 Conv layer 뒤에 1 1 Conv layer가 추가된 구조의 네트워크를 갖습니다.
신경망의 깊이가 증가한만큼 실행시간도 늘어나겠죠. 그 영향은 뒤에 실험결과에서 알 수 있습니다.
저자는 GCAD, SimpleNet, S-T, FastFlow, DSR, PatchCore, PatchCore-Ens, AST 방법론과 비교하여 EfficientAD의 성능을 설명합니다.
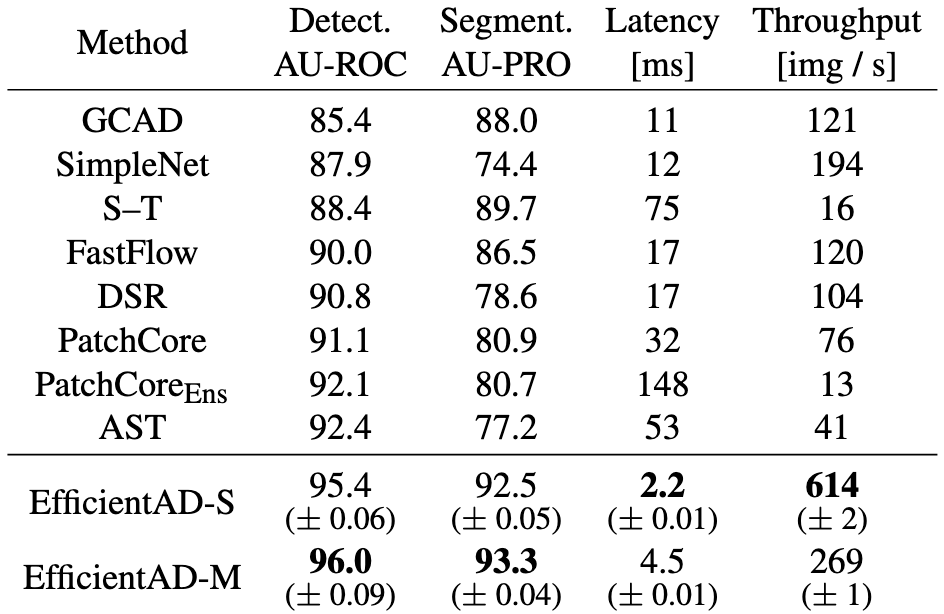
위 표 Table 1은 기존 방법론들과 저자의 2가지 방법론을 비교한 것입니다.
AU-ROC와 AU-PRO 지표는 MVTecAD, VisA, MVTec LOCO에서의 성능들의 평균값을 구한 것입니다.
EfficientAD-S와 EfficientAD-M이 기존 방법론들에 비해 훨씬 빠른 실행시간 보여주며, 훨씬 많은 이미지처리량을 보여줍니다.
EfficientAD-S와 EfficiendAD-M을 비교했을 때, EfficientAD-M이 AU-ROC와 AU-PRO 지표에서 더 높은 결과를 보여주는데, 이유는 신경망을 더 깊게 만들어 represenation 성능을 향상시켰기 때문입니다.
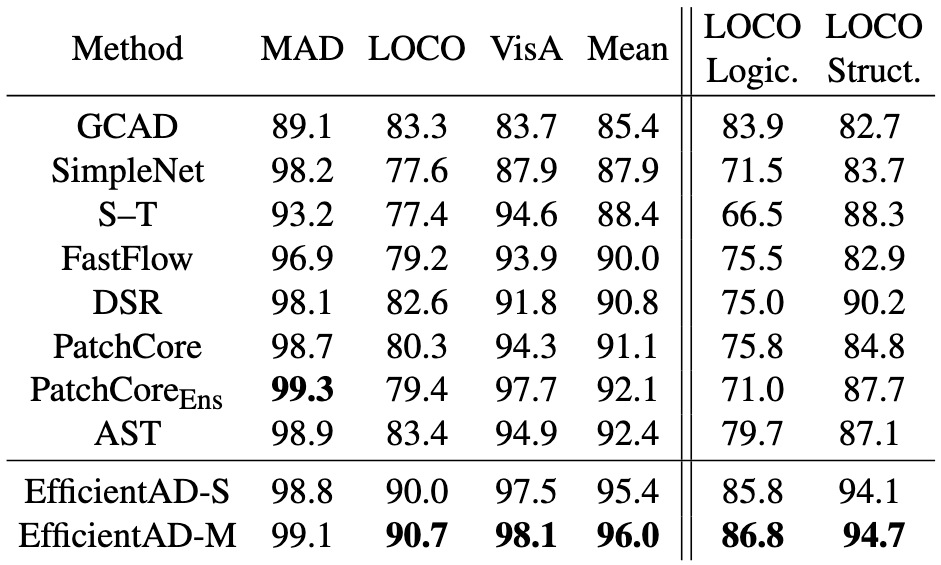
위 표 Table 2는 기존 방법론들과 저자의 2가지 방법론을 여러가지 데이터셋에서 AU-ROC 지표를 구하여 비교한 것입니다.
MVTecAD에서는 기존 방법론들이 EfficientAD와 비슷한 결과를 보여주기도 하며, PatchCore-Ens 방법론 같은 경우 EfficientAD보다 높은 결과를 보여주었습니다.
하지만 MVTec-LOCO 데이터셋에서는 EfficientAD가 압도적으로 높은 결과를 보여줍니다.
Logical anomaly에서 강한 특성을 여기서 알 수 있습니다.
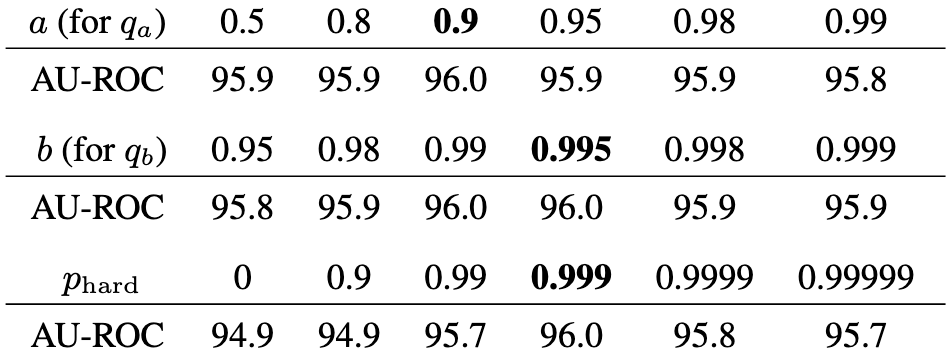
위 표 Table 3는 분위수 변수인 와 와 mining factor 를 조정하였을 때 어떠한 결과가 나오는지 보여주는 실험입니다.
저자가 실험하였을 때 각 변수별로 최적의 값을 어떠한 값이였는지 알 수 있습니다.
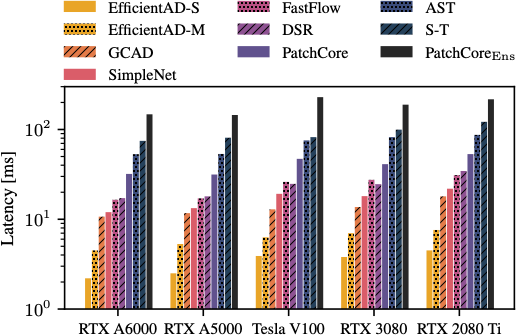
위 그림은 GPU를 다르게 했을 때, 각 방법론들의 Latency를 비교하는 실험입니다.
가장 가벼운 네트워크인 EfficientAD-S가 가장 작은 latency를 보였습니다.
그 다음 EfficientAD-M이 다음으로 작은 latency를 보였습니다.
이 그림으로부터 가벼운 신경망을 사용한 EfficientAD가 작은 latency를 보였음을 알 수 있습니다.
4. 결론
EfficientAD는 높은 anomaly detection 성능과 높은 계산 효율성을 갖춘 방법론입니다.
EfficientAD가 latency 측면에서 두 번째로 높은 AU-ROC를 보이는 AST 방법론에 비해 24배 작은 latency를 보이며, 이미지 처리량에서는 15배 증가시켰습니다.
EfficientAD는 real-time을 요구하는 실제 응용 분야 산업현장에서 상당한 기여를 할 수 있을 것이라 기대합니다.
