[논문리뷰] Uninformed Students: Student-Teacher Anomaly Detection with Discriminative Latent Embeddings
Anomaly Detection

📝 이번 포스트는 "Uninformed Students: Student-Teacher Anomaly Detection with Discriminative Latent Embeddings" 논문에 대해 알아보도록 하겠습니다.
1. Why : 논문의 연구 배경
머신러닝 모델에게 이상(anomalous)하거나 새로운(novel) 것을 unsupervised learning 방식으로 정확히 segmentation하는 것은 컴퓨터 비전의 여러 분야에서 중요한 동시에 풀어나가야할 과제입니다.
여러 알고리즘이 anomaly detection 문제를 해결해보려고 노력했었습니다.
- one-class / multi-class classification
이 방법은 단순하지만 단점이 있습니다.
anomaly가 완전히 다른 클래스의 이미지 형태라고 가정하고, 단순한 이미지가 이상인지 아닌지 binary로 결정하는 것을 목표로 합니다. - Generative Adversarial Network / Variational AutoEncoder
기존연구들은 주로 GAN이나 VAE가 생성알고리즘으로 이상탐지에 접근하였습니다.
이 방법들은 픽셀 단위의 reconstruction error 또는 모델의 확률 분포로부터 얻은 밀도를 평가하여 anomaly를 탐지합니다.
그러나 이러한 방법은 부정확한 reconstruction이나 잘못된 확률로 인해 문제가 발생할 수 있습니다. - discriminative embedding from pretrained networks
지도학습 방법에서는 pretrain된 네트워크에서 얻은 discriminative embedding을 사용하는 transfer learning을 통해 성능이 향상됨을 밝혔습니다.
하지만 비지도학습의 이상탐지에서는 이러한 접근법이 탐구되지 않았습니다.
이러한 이유로 저자는 얕은 모델의 이러한 한계를 극복하기 위해 Student-Teacher 모델을 제안하였습니다.
2. How : 연구 방법론
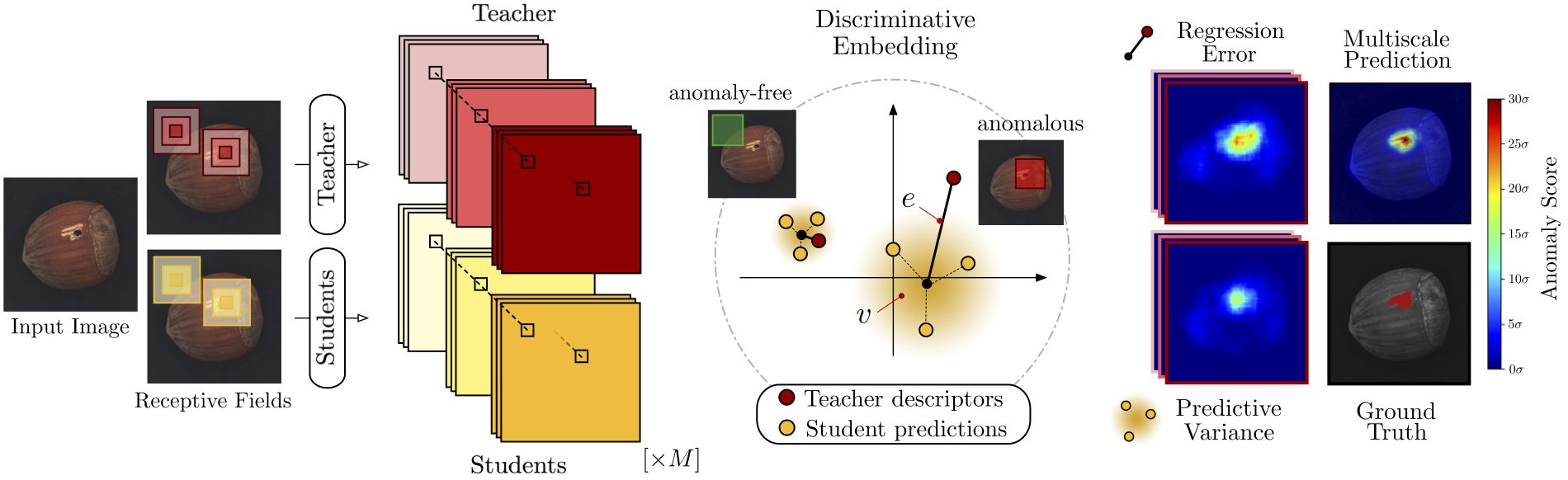
저자의 연구 목적은 정상 이미지들로 구성된 학습 데이터셋 가 주어졌을 때, 테스트 이미지 에서 이상을 탐지할 수 있는 Student 모델 앙상블인 를 생성하는 것입니다.
Teacher 모델은 Student 모델에 비해 상당히 많은 지식을 갖고 있어야 합니다.
그러므로 Teacher 모델은 는 대규모 데이터셋(ImageNet)에서 학습이 됩니다.
그 다음 Student들이 Teacher에게 지식을 전달받아야합니다.
그 과정은 이와 같이, Student 모델들은 이 descriptive한 Teacher 모델로부터 얻은 regression target을 기준으로 학습됩니다.
이렇게 학습 후 Student들의 regression error와 uncertainty를 기반으로 각 이미지 픽셀에 대해 anomaly score를 계산하면 학습이 끝이 납니다.
2.1. Detail of Teacher
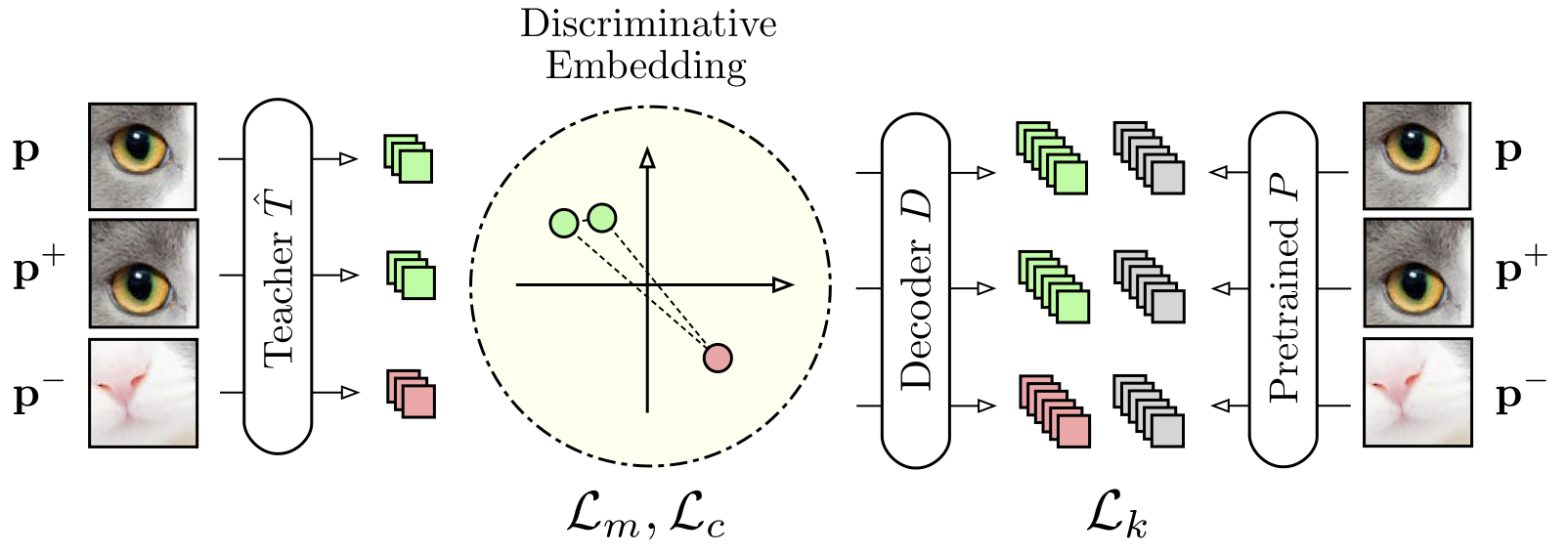
descriptive Teacher 모델 T를 효율적으로 구축하기 위해 metric learning과 knowledge distillation과 descriptor compactness를 사용합니다.
Teacher 모델은 입력 이미지 내의 한 변의 길이가 인 정사각형의 패치 descriptor를 출력합니다.
Teacher 모델 는 패치 크기의 이미지 를 차원 의 metric 공간에 매핑하는 네트워크인 을 학습하여 얻습니다.
이 학습 시에는 Convolution과 max-pooling layer만이 사용됩니다.
이 semantic하게 강한 descriptor를 출력하기 위해 self-supervised metric learning과 pretrained network knowledge distillation을 사용하였습니다.
2.1.1. Knowledge Distillation
저자는 ImageNet 데이터셋으로 pretrained된 강력하게 학습된 네트워크 의 지식을 에 전달하기 위해 의 출력을 으로부터 얻은 디코딩된 descriptor와 일치시키는 방법을 사용합니다.
Loss
- : patch-sized image ()
- : patch 단위로 ImageNet 데이터셋을 학습한 pretrained model
- : 차원 의 metric 공간에 매핑하는 Teacher 모델
- D : Fully-Connected Network
첫 번째 항은 Teacher 모델이 패치크기의 이미지를 학습하고 FC 연산을 통해 dimension을 줄이는 과정입니다.
두 번째 항은 ImageNet으로 pretrained된 모델이 패치크기의 이미지를 학습하는 과정입니다.
이 두 항의 오차를 줄여나가는 방법이 knowledge distillation loss입니다.
2.1.2. Metric Learning
이 방법은 pretrained 모델을 사용하지 않을 경우 사용합니다.
self-supervised learning으로 local 이미지 descriptor를 학습합니다.
이전에 언급했었던 (patch-sized image)를 , , 로 증강합니다.
- : patch-sized image
- :랜덤한 방향으로 작은 거리 이동, 이미지 밝기 변화, 가우시안 노이즈를 사용하여 증강된 이미지 패치
- : 다른 이미지에서 랜덤하게 잘라온 패치
와 는 가우시안 분포가 얼추 비슷할 것입니다.
하지만 와 는 도메인이 달라졌기 때문에 가우시안 분포가 많이 차이 날 것입니다.
Loss
로 triplet distance 와 는 아래와 같습니다.
- = margin parameter ( > 0)
로 와 유사한 는 가까워지도록, 유사하지 않은 는 멀어지도록 학습하는 self-supervised learning의 Loss 함수입니다.
2.1.3. Descriptor Compactness
이 방법은 correlation을 최소화하고 descriptor의 compactness를 증가시키고 불필요한 중복성을 제거하기 위한 방법입니다.
- : 현재 미니배치의 모든 descriptor()에 대해 계산된 correlation matrix
로 비교적 간단합니다.
최종 training Loss는 개별 손실함수 , , 에 대한 가중치 계수 , , 를 포함하여
로 정의됩니다.
2.2. Detail of Student
다음으로 정상 학습 데이터셋으로 Teacher 모델의 출력을 예측하도록 Student 모델()을 학습하는 방법을 설명하겠습니다.
는 Teacher 모델()와 동일한 구조의 신경망을 갖습니다.
그리고 개의 random하게 초기화됩니다. 표현하자면 와 같습니다.
는 IamgeNet으로 학습된 반면에, 는 anomaly detection 데이터셋으로 학습이 이루어집니다.
정확하게는 anomaly detection 데이터셋의 정상 이미지를 학습하게 됩니다.
정상 이미지에 대해 Teacher와 동일한 관점으로 학습을 해야하는데, 그 방법은 아래 Loss와 같습니다.
- : training descriptor(Teacher)의 평균
- : training descriptor(Teacher)의 표준편차
- , : 픽셀좌표
- : (r, c) 픽셀에 대해 의 예측한 값
- : Student들이 예측해야하는 Teacher의 descriptor
- : 표준편차로 채워진 대각행렬의 역행렬
로 -거리 제곱으로 표현할 수 있습니다.
Teacher의 descriptor에 train된 descriptor의 평균을 뺍니다.
그 값을 descriptor의 표준편차로 채워진 대각행렬의 역행렬에 곱합니다.
그리고 Student 모델의 예측값에 그 값을 빼주고 -거리 제곱으로 구해주면 Student 모델의 Loss가 됩니다.
2.3. Anomaly Score
학습이 끝나면 anomaly score를 계산합니다.
저자는 2가지 방식으로 anomaly score를 계산합니다.
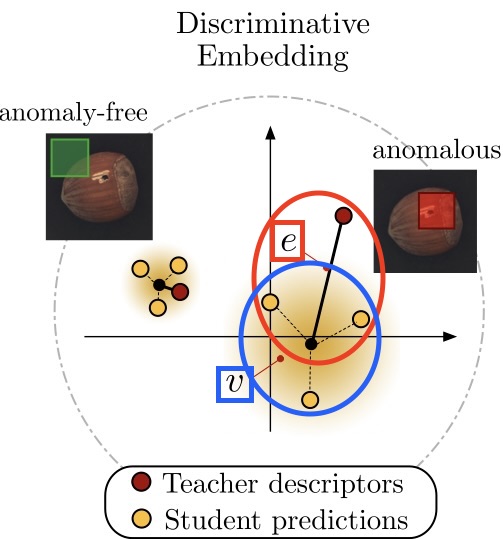
2.3.1. Regression Error
Student 모델이 학습 중 관찰되지 않은 anomaly 영역에서는 교사의 출력을 제대로 회귀하지 못할 것이라는 것입니다.
Teacher는 ImageNet으로 학습할 때, 다양한 도메인의 데이터를 학습하였기 때문에 anomaly를 처음보는 Student와 다른 출력을 낼 것입니다.
이러한 차이의 regression error로 anomaly score를 계산합니다.
위 그림의 빨간 원을 보시면 이해가 쉬울 수 있습니다.
각 변수에 대한 설명은 위의 loss 변수들과 같습니다
위와 같이 regression error는 Student와 Teacher간의 차이를 계산하여 anomaly score를 구합니다.
2.3.2. Uncertainty
가우시안 혼합분포의 예측 uncertainty를 사용하여 각 픽셀의 anomaly score를 계산합니다.
Student 모델은 anomaly 데이터를 학습해보지 못했기 때문에 모든 Student 모델들이 다양하고 가지각색으로 예측을 할 것입니다. 방향이 잡혀지지 않은 채 예측을 하는 것이죠.
이러한 불확실성(Uncertainty)을 기반으로 anomaly score를 구하는 것입니다.
위 그림의 파란 원을 보시면 이해가 쉬울 수 있습니다.
- : (r, c) 픽셀에 대해 의 예측한 값
- : (r, c) 픽셀에 대해 Student들의 평균 예측한 값
로 Student 모델들 간의 차이를 구하여 anomaly score를 계산하는 방법입니다.
그 다음 위 식과 같이 각 regression error와 uncertainty를 평균과 표준편차를 이용하여 정규화하여 더해주면 최종 anomaly score가 됩니다.
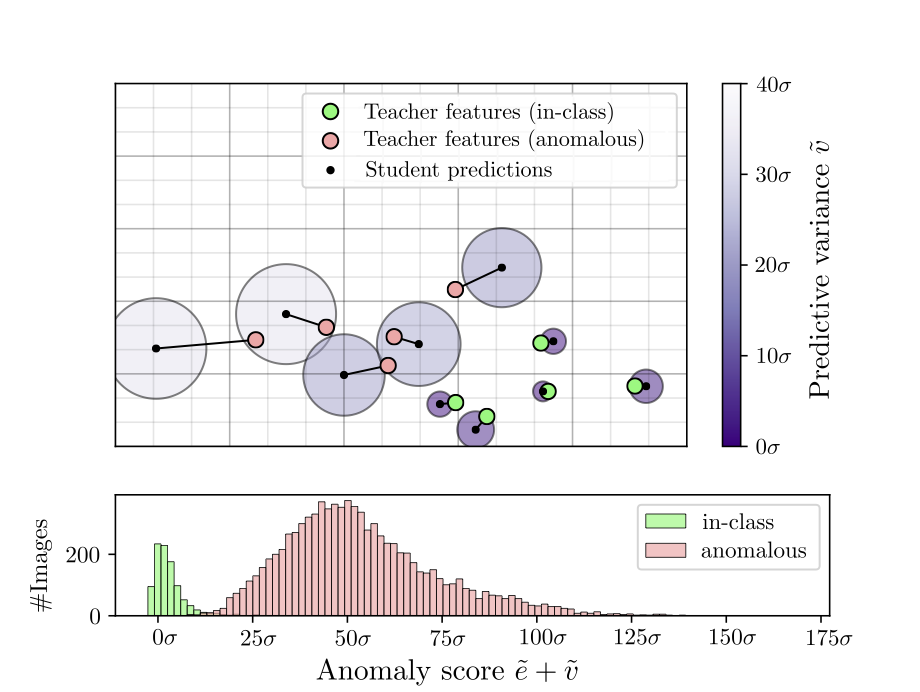
위 그림은 M=5로 하여 한 실험입니다. in-class같은 경우 Teacher의 descriptor와 Stdent의 prediction이 가깝습니다.
하지만 anomalous같은 경우는 Teacher의 descriptor와 Student의 prediction의 거리도 멀 뿐만 아니라, Student의 예측에 대한 분산도 큽니다.
2.4. Multi-Scale Anomaly Segmentation
저자는 Student과 Teacher 둘 다 receptive field 를 조절할 수 있는 프레임워크를 만들었습니다.
를 다양하게 설정하여 여러 규모의 anomaly를 탐지할 수 있습니다.
다양한 를 가진 여러 Student-Teacher 앙상블 쌍들을 학습시켜 다양한 사이즈의 anomaly를 탐지할 수 있게 합니다.
L개의 다른 사이즈로 학습했을 때 anomaly score는 평균을 통해 간단하게 구현할 수 있습니다.
이와 같이 L개의 다른 사이즈로 anomaly score를 계산할 수 있습니다.
3. 결론
Knowledge Distillation을 사용하는 Anomaly Detection 방법론인 논문을 분석해보았습니다.
어떻게 앙상블 모델들끼리 Loss를 구하는지, Teacher와 Student가 어떻게 Loss를 구하는지 알게되었습니다.
