
Motivation
With the project's features nearing completion, it's finally time for refactoring. The topic of refactoring is "Improving Queries!"—a subject I've been eager to tackle for some time. Until now, I've been relying entirely on the methods provided by JPA without ever defining JPQL queries myself, and I've been curious about what queries are being executed internally. I'm determined to document my experience of improving the queries and share my learnings through writing.
Contents
Logging the Number of Queries
During the refactoring process, the first task I undertook was to log and verify the number of queries executed per request for each page (e.g., main page, view profile, etc.). This part was handled in advance by our team member, Passionate Man Aki (thanks, Aki 🥲). We used StatementInspector to achieve this, so let's take a brief look at how it works.
StatementInspector
The detailed application methods can be found in the links below, so let’s take a quick overview here.
Aki's
Ozzi's
Inspect the given SQL, possibly returning a different SQL to be used instead.
Note that returning null is interpreted as returning the same SQL as was passed.
-
Register an implementation of
-
StatementInspector as a bean.
Register the implementation with HibernateProperties.Just creating an implementation of StatementInspector does not automatically intercept queries. You need to configure Hibernate to use this implementation.
-
Record logs in an interceptor or filter.

With this setup, we were able to count the queries generated for each request.
Defining JPQL
After Checking the queries generated for each request, We established the following criteria before defining JPQL:
For JPQL, apply it in cases where the WHERE clause contains three or more conditions (including ORDER BY).
The reason for setting this criterion is to improve method readability. When there are three or more conditions in the WHERE clause (including ORDER BY), the method name can become very cumbersome. For example, a method name like findByCrewIdOrderByScheduleLocalDateTimeDesc significantly reduces readability. By defining JPQL using the @Query annotation, the method name can be simplified to something more readable, such as findAllByCrewIdLatestOrder. This makes the code more maintainable and easier to understand.
Make sure to explicitly specify the join type
Next, after defining the JPQL queries for the queries with many conditions, I reran the Repository tests and analyzed the actual SQL statements being executed.
@Query("SELECT r FROM Reservation AS r "
+ "WHERE r.schedule.coach.id = :coachId "
+ "AND r.reservationStatus NOT IN :status")
List<Reservation> findByCoachIdAndStatusNotIn(Long CoachId, ReservationStatus status)You can see that a cross join is being executed. While I'm familiar with inner and outer joins, what exactly is a cross join?
Cross join
A cross join is also known as a Cartesian product, which computes the Cartesian product of the two tables being joined.
n simple terms, if Table1 has 200,000 records and Table2 has 200,000 records, a cross join would produce 200,000×200,000=40 billion records in the result. (This is a very performance-intensive method.)
As seen in the example, if you write JPQL with path expressions like r.schedule.coach.id without explicitly specifying the join type, it defaults to a cross join.
⭐️Therefore, when writing JPQL join queries, you should avoid using path expressions and explicitly specify the join type, as shown below.
@Query("SELECT r FROM Reservation AS r "
+ "INNER JOIN r.schedule AS s "
+ "INNER JOIN s.coach AS c "
+ "ON c.id = :coachId "
+ "WHERE r.reservationStatus NOT IN :status")
List<Reservation> findAllByCoachIdAndStatusNot(Long coachId, ReservationStatus status);
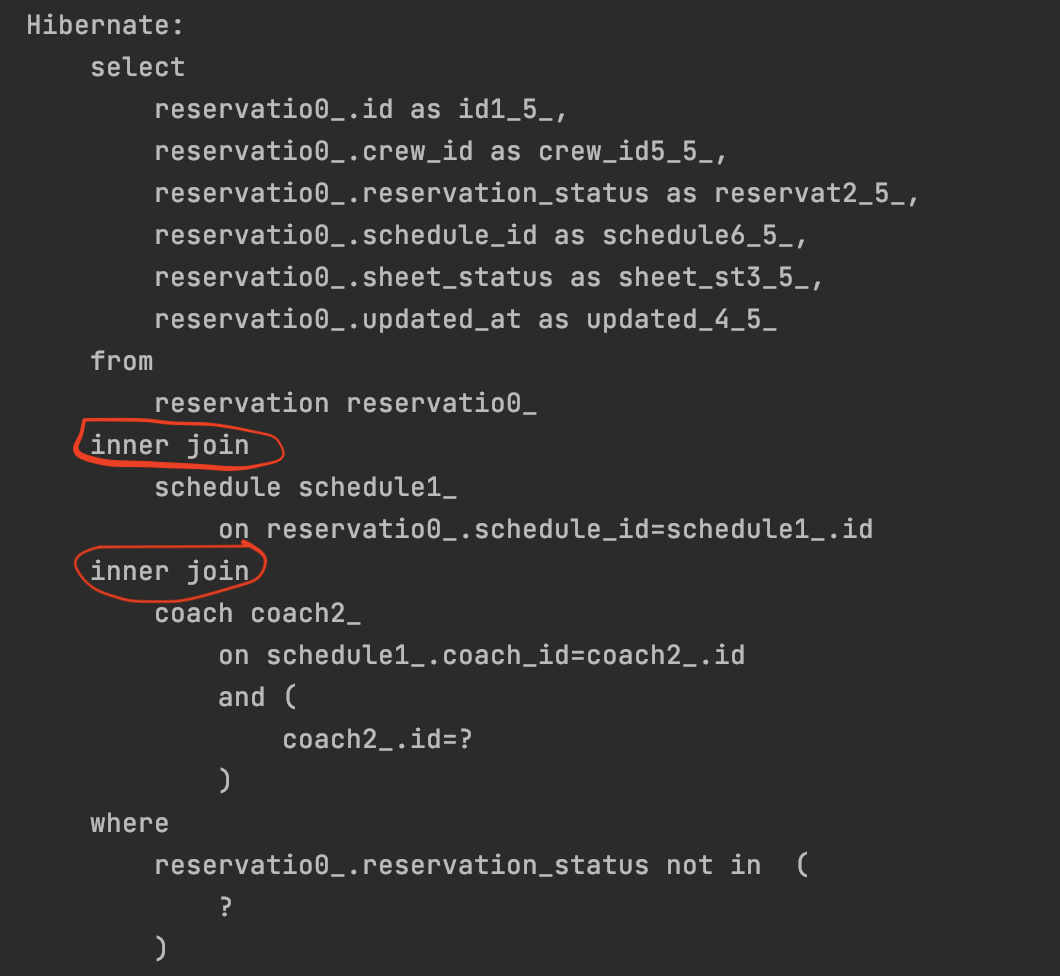
By explicitly specifying the join type, you can confirm that the SQL query is generated as an inner join, as shown above.
Improved 'deleteAll()' in Spring data jpa
The default deleteAll() provided by Spring Data JPA may seem like it performs a straightforward DELETE FROM Reservation operation to remove all entries from the table. However, that's not entirely accurate.
As discussed in the video 잉과 페퍼의 JPA 삽질일지 테코톡 the behavior of deleteAll() may not be as simple as it appears. This video could offer valuable insights and help clarify the nuances involved.
Behavior of deleteAll Method
1. The findAll() method is executed to retrieve all records from the database table.
2. The retrieved data is stored in the persistence context's first-level cache (also known as the first-level cache).
3. For each record in the first-level cache, a DELETE FROM Reservation WHERE id = ? statement is created and stored in the write-behind store (write-behind buffer).
4. When a flush operation occurs, all stored delete statements are sent to the database and executed.
Problem
The issue is that in step 3, a DELETE statement is generated for each record in the first-level cache.
void deleteAllByCoachIdAndLocalDateTimeBetween(Long coachId, LocalDateTime start, LocalDateTime end);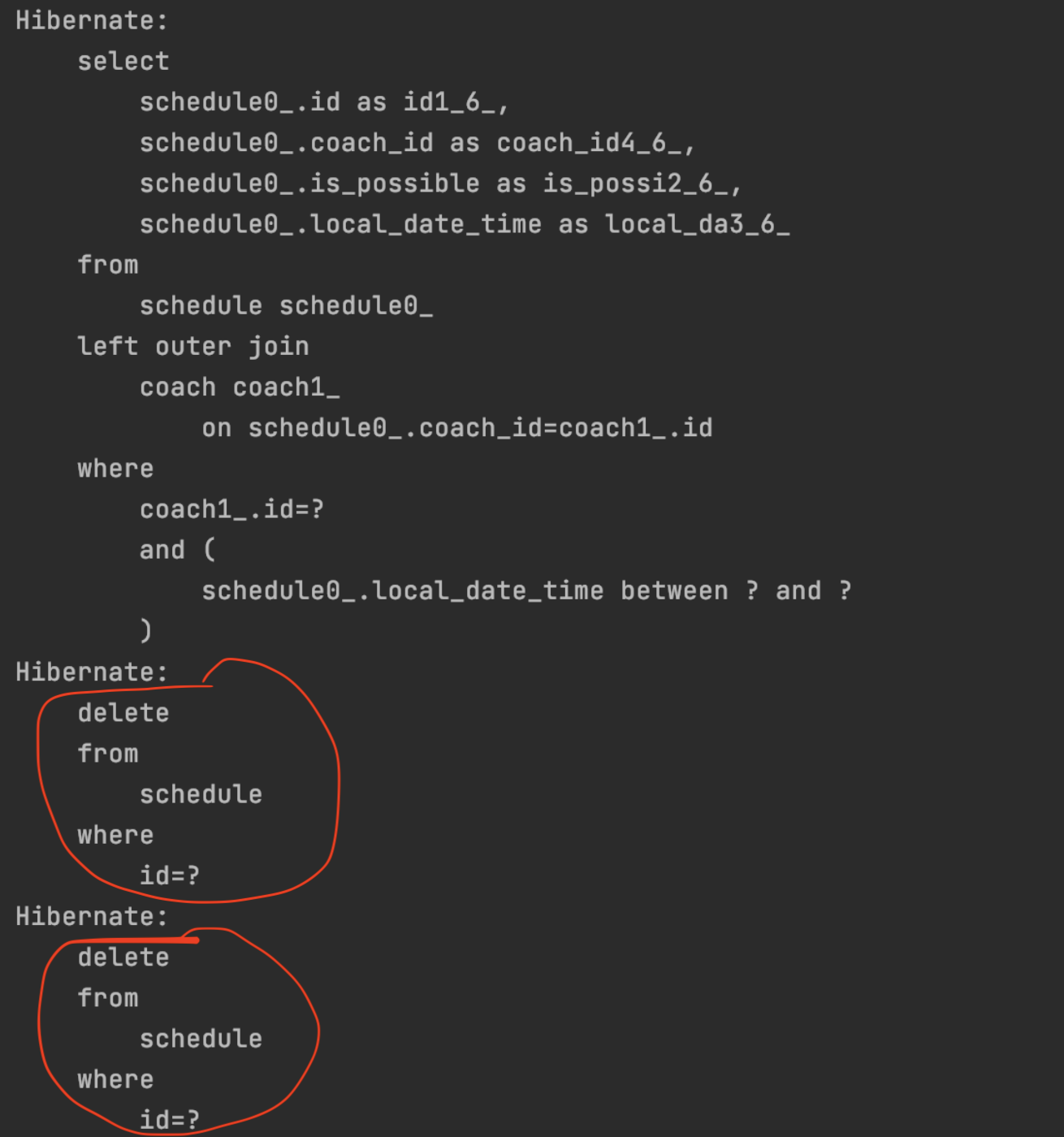
The method above is the one where JPQL is not defined using the @Query annotation. When executed, you can observe that DELETE statements are generated in a geometrically increasing number, proportional to the amount of data.
Solution
@Modifying
@Query("DELETE FROM Schedule AS s "
+ "WHERE s.coach.id = :coachId "
+ "AND s.localDateTime > :start "
+ "AND s.localDateTime < :end")
void deleteAllByCoachIdAndTimeBetween(Long coachId, LocalDateTime start, LocalDateTime end);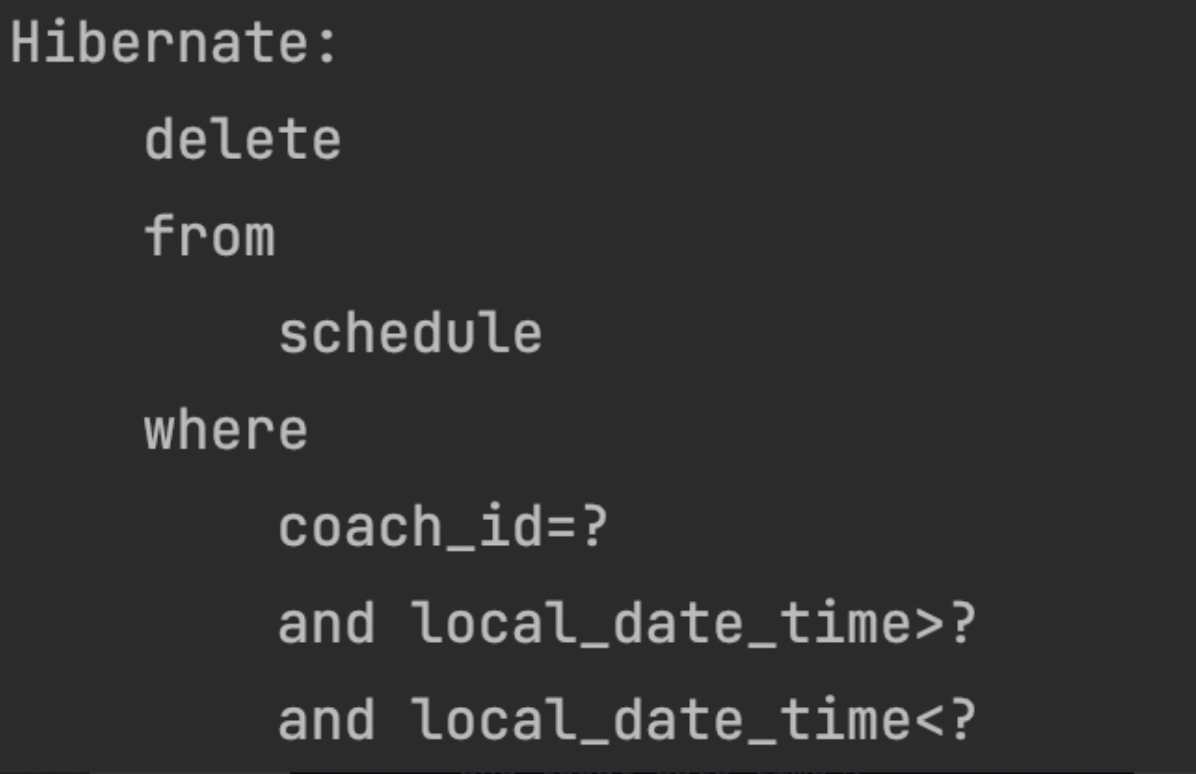
By defining the JPQL as shown below, the issue was resolved. However, it's important to note that if you do not include the @Modifying annotation to indicate a bulk update, you will encounter Hibernate errors like the one below. Always remember to include the @Modifying annotation when performing bulk updates!

Conclusion
Improving queries with JPA made me realize that my previous belief was incorrect: 'JPA frees developers from SQL.'
Instead, it should be 'JPA allows you to develop web applications without needing to know SQL'.
