
Motivation
I’ve decided to start writing about the improvements we made to the project’s queries. So, let’s kick off “Query Optimization Chronicles, Part 2”…!
Contents
Problematic Situation - New Feature Added
After releasing the project, we received the following feedback from users:
"I want to know on the main page if the coach has available slots for meetings!"
This was something we anticipated might be inconvenient for users.

As a result, we added a new feature to inform users directly on the main page whether a coach is available for booking, without them having to check each coach’s schedule individually. This is indicated by a yellow circle at the top right corner of the screen.
Original Logic - Retrieve all coaches from the coach table using findAll().
@Transactional(readOnly = true)
public List<CoachFindResponse> findAll() {
List<Coach> coaches = coachRepository.findAll();
return CoachFindResponse.from(coaches);
return response;
}
Updated Logic After Adding the Feature - Retrieve all coaches and check each coach’s schedule to see if they have available slots using a loop.
@Transactional(readOnly = true)
public List<CoachFindResponse> findAll() {
List<CoachFindResponse> response = new LinkedList<>();
List<Coach> coaches = coachRepository.findAll();
for (Coach coach : coaches) {
boolean isPossible = scheduleRepository.existsIsPossibleByCoachId(coach.getId());
response.add(new CoachFindResponse(coach, isPossible));
}
return response;
}After adding this feature, a loop was introduced in the logic. As a result, an additional query is executed for the schedule table for each coach retrieved. This means the number of queries is no longer fixed. As the number of coaches increases, so does the number of queries.
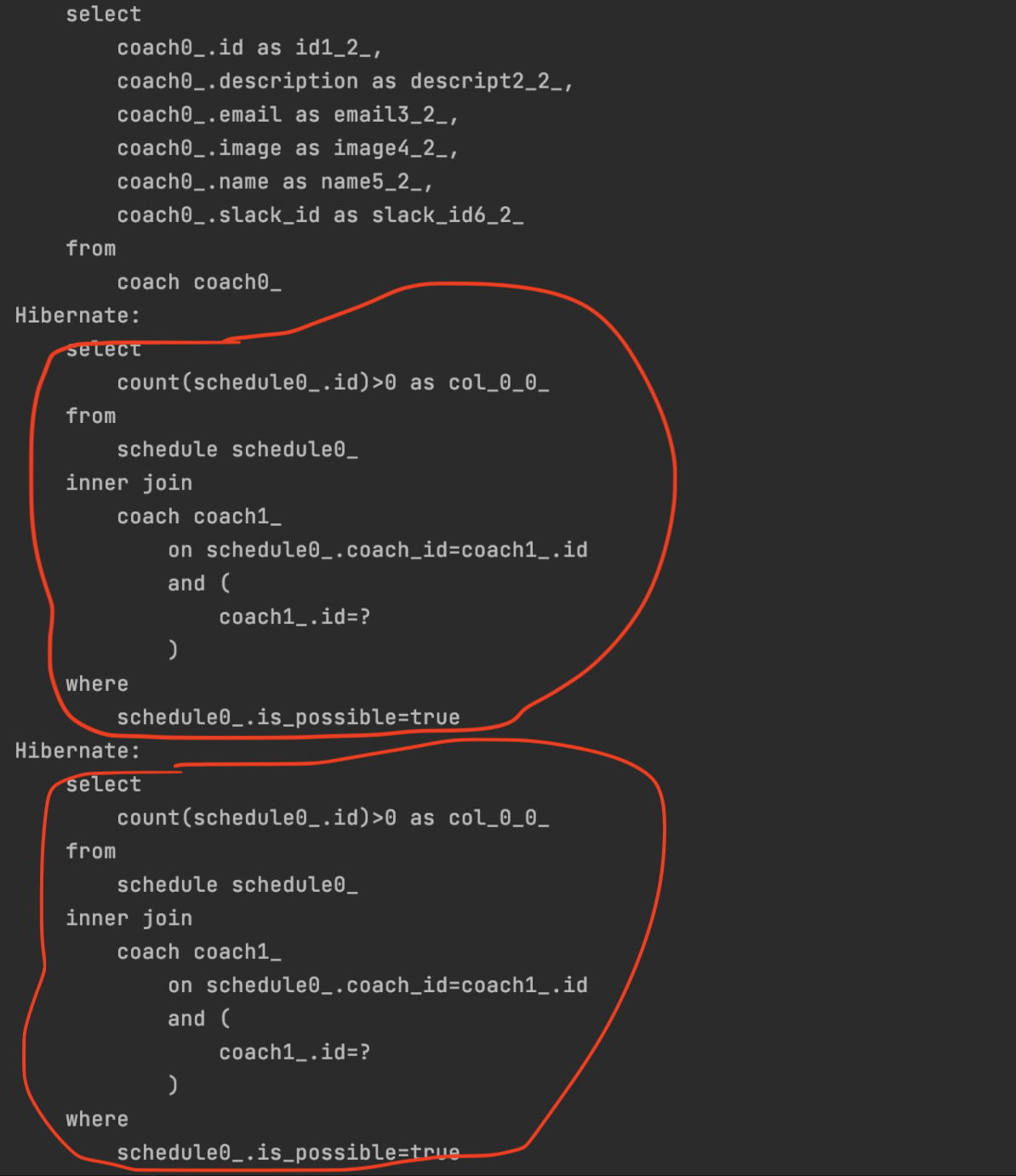
If there are two coaches, two queries are made; if there are three, then three queries, and so on...
Solution
Using Native Query
To resolve the issue, we decided to use a native query instead of JPQL. But what exactly is a native query?
In JPA, a native query allows you to execute SQL that is specific to a particular database.
There are situations where you need to write database-dependent SQL—for instance, when using SQL hints or features that only work with specific databases. This is where native queries come into play. But you might wonder, why would we choose to use a native query, despite its dependency on a specific database?
I pondered this question extensively. I tried to solve the problem without resorting to a native query, aiming to address the N+1 query issue with a single query. However, I ultimately concluded that using a native query was necessary.
Why We Had to Use Native Query
To solve the problem in one query, we needed to use a subquery in the SELECT clause. However, JPQL does not support subqueries (scalar subqueries) in the SELECT clause—JPQL only allows subqueries in the WHERE or HAVING clauses. Given these limitations, I found it impossible to resolve the issue without a native query.
I also considered using Fetch Join or Batch Size, but what we needed wasn’t the Schedule entities related to the Coach; instead, we just needed to know whether a Crew could book a schedule or not. Fetching all related Schedule entities for each coach seemed inefficient, so I ruled out those options.
@Query(value = "SELECT c.id As id, c.name, c.description, c.image, EXISTS ("
+ "SELECT * FROM schedule s2 WHERE s2.coach_id = id AND s2.is_possible = TRUE) possible "
+ "FROM coach c "
+ "LEFT JOIN schedule s "
+ "ON s.coach_id = c.id "
+ "GROUP BY c.id", nativeQuery = true)
List<CoachWithPossible> findCoaches();Therefore, I wrote the above MySQL-specific SQL query.
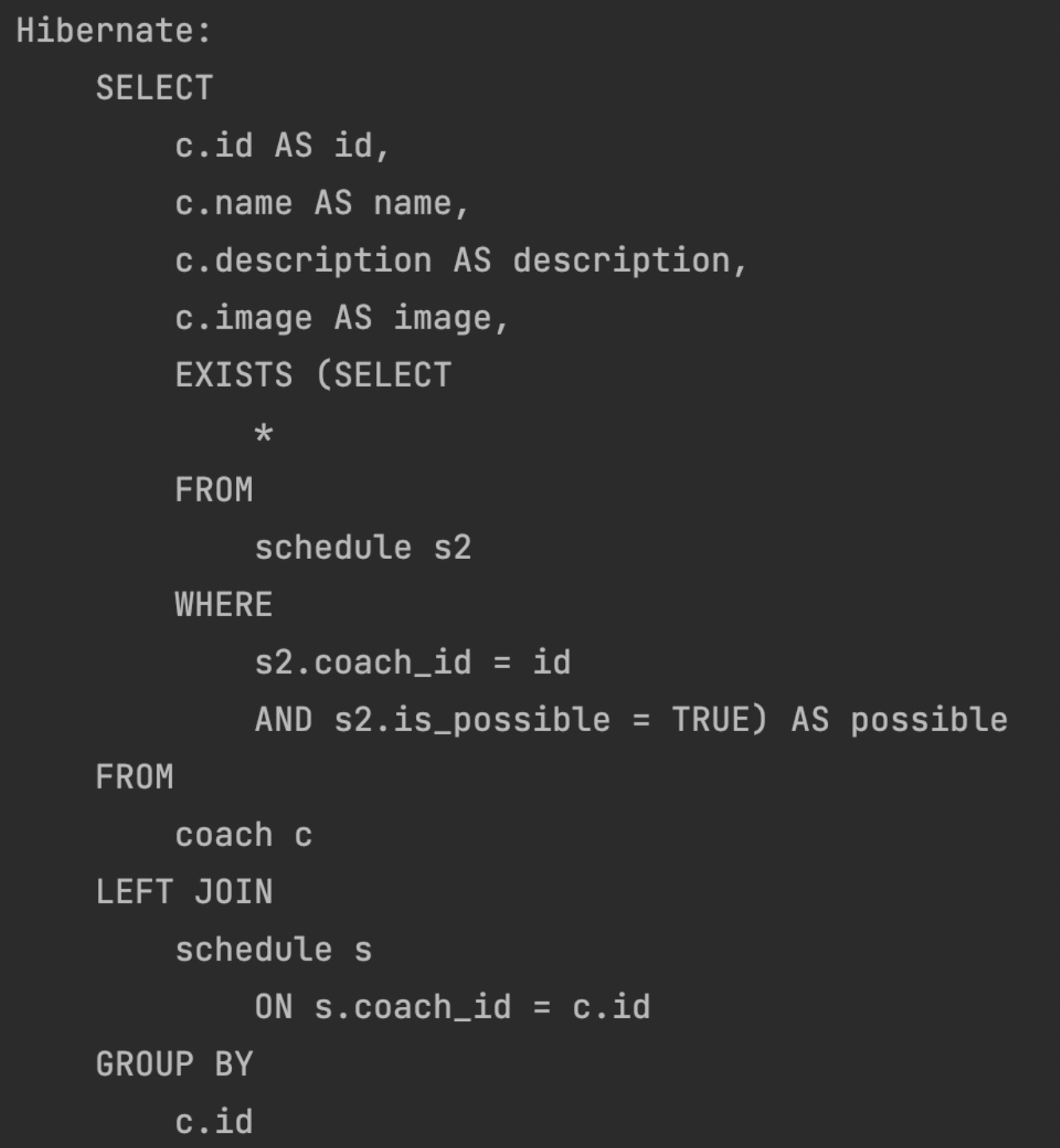
Looking at the captured query, you can see that the N+1 query issue was resolved with a single query.
Points to Consider
The return type of the query above is a DTO called CoachWithPossible, not a domain entity.
Initial Approach: Declaring the DTO as an Interface
public interface CoachWithPossible {
Long getId();
String getName();
String getDescription();
String getImage();
Boolean getPossible();
}The simplest way I found through Googling to map query results to a DTO was to declare the DTO as an interface like this. While all the test cases passed, once I deployed to the development server, I encountered the following error:
JpaRepository - Hibernate - java.math.BigInteger cannot be cast to java.lang.Boolean
I concluded that this error occurred because the test environment was using H2 instead of the actual database, MySQL. This means I’ll need to switch the test database to MySQL later... 🥲 Ultimately, mapping via an interface did not work correctly!
Final Approach: Using @SqlResultSetMapping and @NamedNativeQuery
@Entity
@SqlResultSetMapping(
name = "CoachWithPossibleMapping",
classes = @ConstructorResult(
targetClass = CoachWithPossible.class,
columns = {
@ColumnResult(name = "id", type = Long.class),
@ColumnResult(name = "name", type = String.class),
@ColumnResult(name = "description", type = String.class),
@ColumnResult(name = "image", type = String.class),
@ColumnResult(name = "possible", type = Boolean.class),
}
)
)
@NamedNativeQuery(
name = "findCoaches",
query = "SELECT c.id AS id, c.name AS name, c.description AS description, c.image AS image, EXISTS ("
+ "SELECT * FROM schedule s2 WHERE s2.coach_id = c.id AND s2.local_date_time > NOW() AND s2.is_possible = TRUE ) AS possible "
+ "FROM coach c",
resultSetMapping = "CoachWithPossibleMapping")Finally, I resolved the issue using @SqlResultSetMapping and @NamedNativeQuery in the domain class, as shown above. This solution is mentioned in Chapter 10 of Kim Young-han’s JPA book. Initially, I avoided this method because it can make the domain class more complex. However, I ultimately found this to be the best approach for our situation. If I find a better solution later, I’ll consider refactoring the code again.
Conclusion
Improving the unstable queries in our project has been a great learning experience, allowing me to absorb various new concepts. In this optimization effort, I delved into SQL subqueries and their applications. The next installment of this series will once again focus on solving the N+1 problem, 
nd. I’ve noticed a logic issue where additional queries are triggered by lazy loading when retrieving related entities in queries executed with inner joins. Let’s tackle that challenge next and enjoy the process of optimizing our project even further!
