
Motivation
In our current Woowacourse project, we’ve been using the saveAll() method provided by Spring Data JPA. However, while incorporating user feedback, I realized that the saveAll() method doesn’t apply batch inserts. This discovery led me to begin optimizing our queries, and I’ve decided to document this journey in a series of posts. Here’s the first installment of my query optimization efforts!
Contents
Problematic Logic
public void update(Long coachId, List<ScheduleUpdateRequest> requests) {
for (ScheduleUpdateRequest request : requests) {
deleteAllByCoachAndDate(coachId, request);
saveAllByCoachAndDate(coachId, request);
}
}private void saveAllByCoachAndDate(Long coachId, ScheduleUpdateRequest request) {
Coach coach = findCoach(coachId);
List<Schedule> schedules = toSchedules(request, coach);
scheduleRepository.saveAll(schedules);
}
In the current logic, which handles the registration and updating of coach schedules, a new feature was added based on user feedback to process schedules on a monthly basis rather than daily. This has exacerbated performance issues with the saveAll() method, which does not support batch processing.
The issues with the current logic can be summarized as follows:
Problem 1: saveAll() Method Does Not Support Batch Inserts
Problem 2: Iterative Processing Directly Affects Query Generation
Problem1 - saveAll()
The first issue to resolve is that the saveAll() method in Spring Data JPA does not support batch inserts. Although the method’s name might suggest batch processing, in reality, it does not apply batch insert functionality. Instead, it generates separate SQL INSERT statements for each entity based on the number of items in the request.
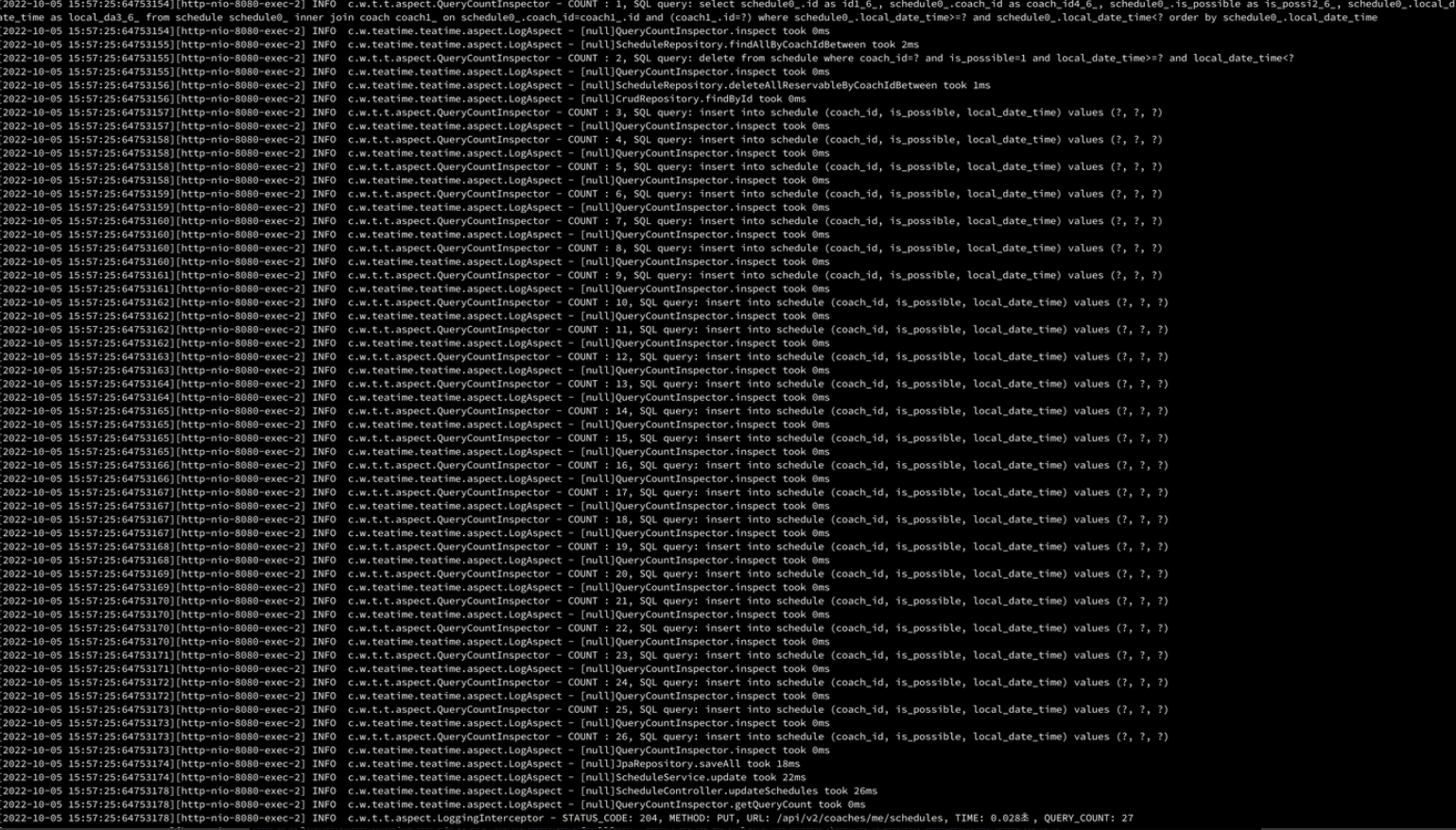
From the logs, it's clear that insert queries are being generated in proportion to the response values. It's somewhat intuitive that saveAll() in Spring Data JPA doesn't apply batch processing, though I had overlooked this initially.
In JPA, entities are managed through the persistence context, which includes a feature called the write delay storage. For this feature to work effectively, entities need to have an identifier, such as an ID. When calling save() on an entity, if the entity lacks an ID, JPA will not utilize the write delay mechanism to batch insertions. Instead, it issues insert queries directly to the database.
Understanding this JPA behavior, where entities without IDs result in immediate database writes rather than batch processing, explains why saveAll() does not perform batch inserts.
Additionally, with MySQL's ID generation strategy set to auto-increment using @GeneratedValue(strategy = GenerationType.IDENTITY), it's clear that batch inserts are not supported in JPA under this strategy.
For more details, refer to this article which explains why batch processing doesn't apply with this ID generation strategy.
Now that we understand why saveAll() cannot be batch-processed, let's proceed with solving the problem.
Solution - Used JDBCTemplate
To apply batch inserts with saveAll(), we used JdbcTemplate provided by Spring JDBC.
@RequiredArgsConstructor
@Repository
public class ScheduleDao {
private static final int BATCH_SIZE = 1000;
private final JdbcTemplate jdbcTemplate;
public void saveAll(List<Schedule> schedules) {
int batchCount = 0;
List<Schedule> subItems = new ArrayList<>();
for (int i = 0; i < schedules.size(); i++) {
subItems.add(schedules.get(i));
if ((i + 1) % BATCH_SIZE == 0) {
batchCount = batchInsert(batchCount, subItems);
}
}
if (!subItems.isEmpty()) {
batchCount = batchInsert(batchCount, subItems);
}
}
private int batchInsert(int batchCount, List<Schedule> subItems) {
jdbcTemplate.batchUpdate("INSERT INTO schedule (coach_id, local_date_time, is_possible) VALUES (?, ?, ?)",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setLong(1, subItems.get(i).getCoach().getId());
ps.setTimestamp(2, Timestamp.valueOf(subItems.get(i).getLocalDateTime()));
ps.setBoolean(3, subItems.get(i).getIsPossible());
}
@Override
public int getBatchSize() {
return subItems.size();
}
});
subItems.clear();
batchCount++;
return batchCount;
}
}
JdbcTemplate has some downsides:
-
Database-Specific Queries: It requires writing database-specific SQL queries, which may reduce portability.
-
RowMapper Definition: You need to define a RowMapper to map retrieved data, which adds additional complexity.
-
Increased Management Points: It adds more management points at the application level for database access.
However, after discussing with the team, we decided to proceed with JdbcTemplate. This decision was based on the following reasons:
Batch Insert Problem: It effectively solves the issue of applying batch inserts for a large number of responses.
Current Scope: Since we are only handling insert operations at the moment, the issue of mapping retrieved data (downside 2) does not affect us.
Thus, we concluded that using JdbcTemplate is the best approach to address the immediate need for batch inserts.
Problem2 - Query generation logic dependent on loops
The methods saveAllByCoachAndDate and deleteAllByCoachAndDate, which directly influence query generation, also have a significant problem due to their dependence on loops.
Solution
before
public void update(Long coachId, List<ScheduleUpdateRequest> requests) {
for (ScheduleUpdateRequest request : requests) {
deleteAllByCoachAndDate(coachId, request);
saveAllByCoachAndDate(coachId, request);
}
}In the existing logic, the request data received as a list was processed through a loop. However, this can be streamlined by using a stream to aggregate the necessary information (i.e., localDateTime) into a single list.
For the delete logic (deleteAllByCoachAndDate), what was needed were the oldest and the most recent dates among the provided localDateTime values.
Similarly, for the save logic (saveAllByCoachAndDate), the essential information was also the dates, as they are used to create Schedule entities for saving.
List<Schedule> schedules = toSchedules(localDateTimes, coach);
scheduleDao.saveAll(schedules);after
public void update(Long coachId, List<ScheduleUpdateRequest> requests) {
List<LocalDateTime> localDateTimes = requests.stream()
.map(ScheduleUpdateRequest::getSchedules)
.flatMap(Collection::stream)
.sorted()
.collect(Collectors.toList());
deleteAllByCoachAndDate(coachId, localDateTimes);
saveAllByCoachAndDate(coachId, localDateTimes);
}We were able to streamline the schedule modification logic to be handled with just four queries: two for validation, one for deletion, and one for saving.
Conclusion
Although I initially didn't want to use JdbcTemplate due to the increased management points, it became necessary. Life rarely goes as planned... but it was still an interesting experience! 🥲
There are many complex JPQL queries (such as those involving three or more joins), and I’m thinking about using QueryDSL to improve readability. There’s a lot to do and many things I want to try.
