
학습 동기
앞서 작성한 JPA 쿼리 개선기1에 이어 진행하고 있는 프로젝트의 쿼리를 개선한 내용을 정리하기 위해 글쓰기를 다짐하게 되었다. 그럼 쿼리 개선기2 시작해보자...!
학습 내용
문제가 되는 상황 - 추가된 기능
프로젝트를 릴리즈하고 나서 사용자로부터 다음과 같은 피드백이 들어왔다.
코치가 면담가능한 일정이 등록되어 있는지 메인페이지에서 알고 싶어요!
사실 사용자들이 불편할만 하다고 충분히 생각했고

따라서 다음과 같이 상단 오른쪽의 노란색 동그라미로 코치의 일정을 일일이 확인하지 않고 메인에서 예약이 가능한지 가능하지 않은지 알려주는 기능이 추가됐다.
기존 로직 - coach table에서 모든 코치를 findAll로 조회한다.
@Transactional(readOnly = true)
public List<CoachFindResponse> findAll() {
List<Coach> coaches = coachRepository.findAll();
return CoachFindResponse.from(coaches);
return response;
}
기능이 추가된 후 바뀐 로직 -coach table에서 모든 코치를 조회하고 + 각 코치의 스케쥴을 조회해 예약가능한지 확인한다.
@Transactional(readOnly = true)
public List<CoachFindResponse> findAll() {
List<CoachFindResponse> response = new LinkedList<>();
List<Coach> coaches = coachRepository.findAll();
for (Coach coach : coaches) {
boolean isPossible = scheduleRepository.existsIsPossibleByCoachId(coach.getId());
response.add(new CoachFindResponse(coach, isPossible));
}
return response;
}기능이 추가되고 로직에 반복문이 추가되었다. 이에 따라 조회한 코치마다 schedule table을 이용하는 쿼리가 하나씩 추가로 발생하게 되었다.
로직에서 쿼리의 개수가 고정적인게 아니라 코치의 개수가 늘어나면 쿼리도 하나씩 늘어나게 된다.
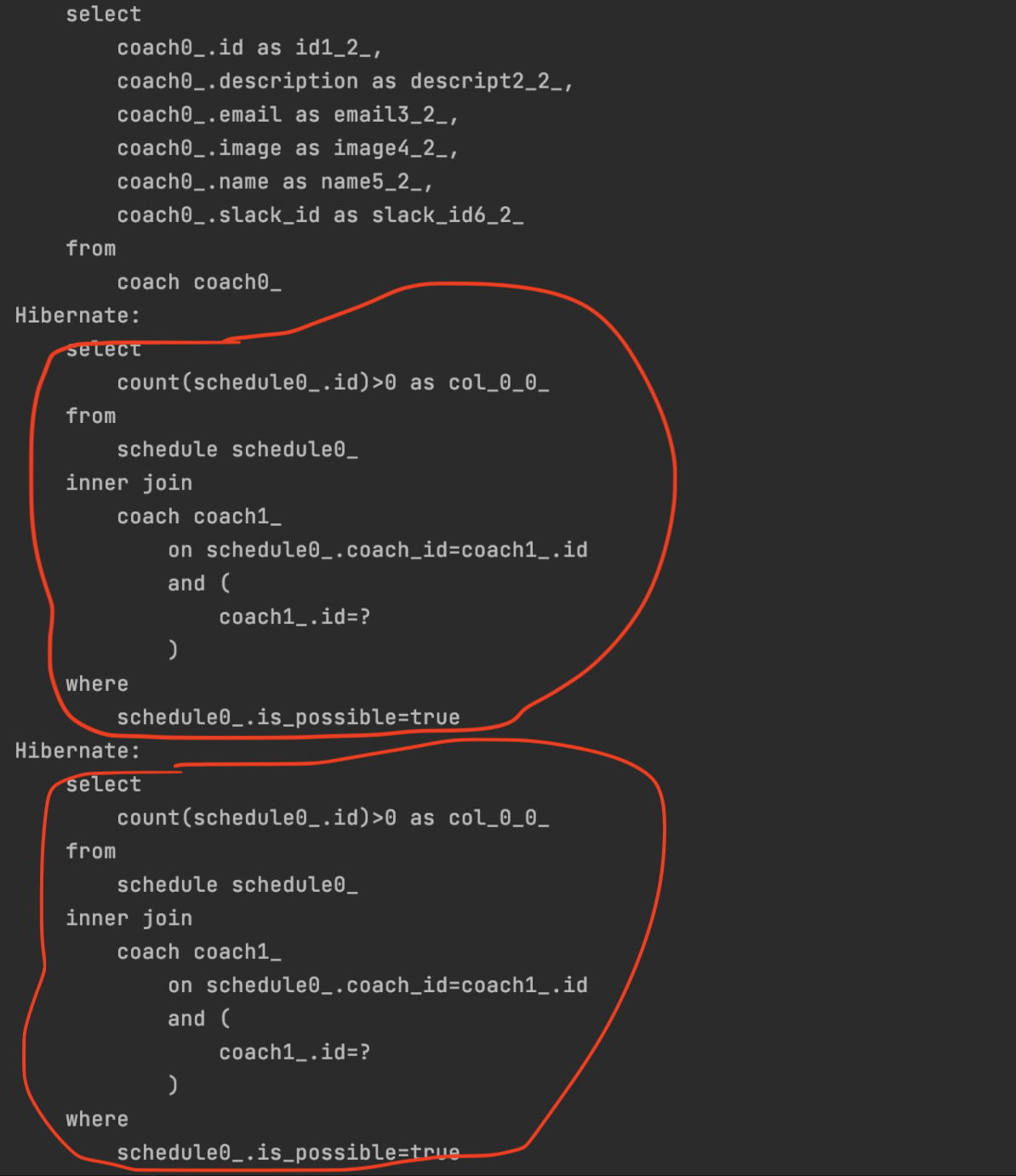
코치가 두 명이면 두 개 세 명이면 세 개 네명이면 네 게....
해결
Native query 사용
문제를 해결하기 위해 JPQL이 아닌 네이티브 쿼리를 사용했다. 네이티브 쿼리가 뭘까?
JPA에서 JPQL 대신 직접 특정 db에 한정적인 SQL을 사용할 수 있다.
특정 상황에서 예를 들어 SQL 힌트같은 특정 db에서만 동작하는 기능을 사용해야 할 경우를 대비해 특정 db에 종속적인 sql을 작성해야 할 경우가 있는데 이 같은 sql을 네이티브 쿼리라 한다.
근데 굳이 위의 상황에서 특정 db에 의존해서 SQL을 작성해야 한다는 단점이 있는 네이티브 쿼리를 써야만 했을까?
위 질문에 대해 정말 많은 고민을 했다. 네이티브 쿼리를 사용하지 않고 저 n+1로 쿼리가 나가는 상황을 한 번의 쿼리로 해결해 보려고 했지만 결국 네이티브 쿼리를 사용할 수 밖에 없었다.
Native query를 사용할 수 밖에 없었던 이유
위 로직을 쿼리 한 번으로 해결하려면 select에서 서브 쿼리를 작성해야 한다. 하지만 JPQL은 select에서 서브 쿼리(스칼라 서브 쿼리)를 지원하지 않는다.(JPA의 서브쿼리는 where, having절에서만 가능) JPQL을 사용하면서 서브 쿼리 없이 문제를 해결하기엔 역부족이여서 네이티브 쿼리를 사용했다. Fetch join이나 Batch Size를 이용한 방식도 고려해 보았지만 우리가 필요한 것은 Coach와 연관된 Schedule 엔티티들이 아닌 Crew가 이용 가능한 일정이 있는 지 없는 지의 유무였기 때문에 Coach와 연관된 Schedule 엔티티를 전부 다 가져오는 것은 비효율적이라 판단했다.
@Query(value = "SELECT c.id As id, c.name, c.description, c.image, EXISTS ("
+ "SELECT * FROM schedule s2 WHERE s2.coach_id = id AND s2.is_possible = TRUE) possible "
+ "FROM coach c "
+ "LEFT JOIN schedule s "
+ "ON s.coach_id = c.id "
+ "GROUP BY c.id", nativeQuery = true)
List<CoachWithPossible> findCoaches();따라서 위와 같은 mysql용 sql로 쿼리를 작성하였다.
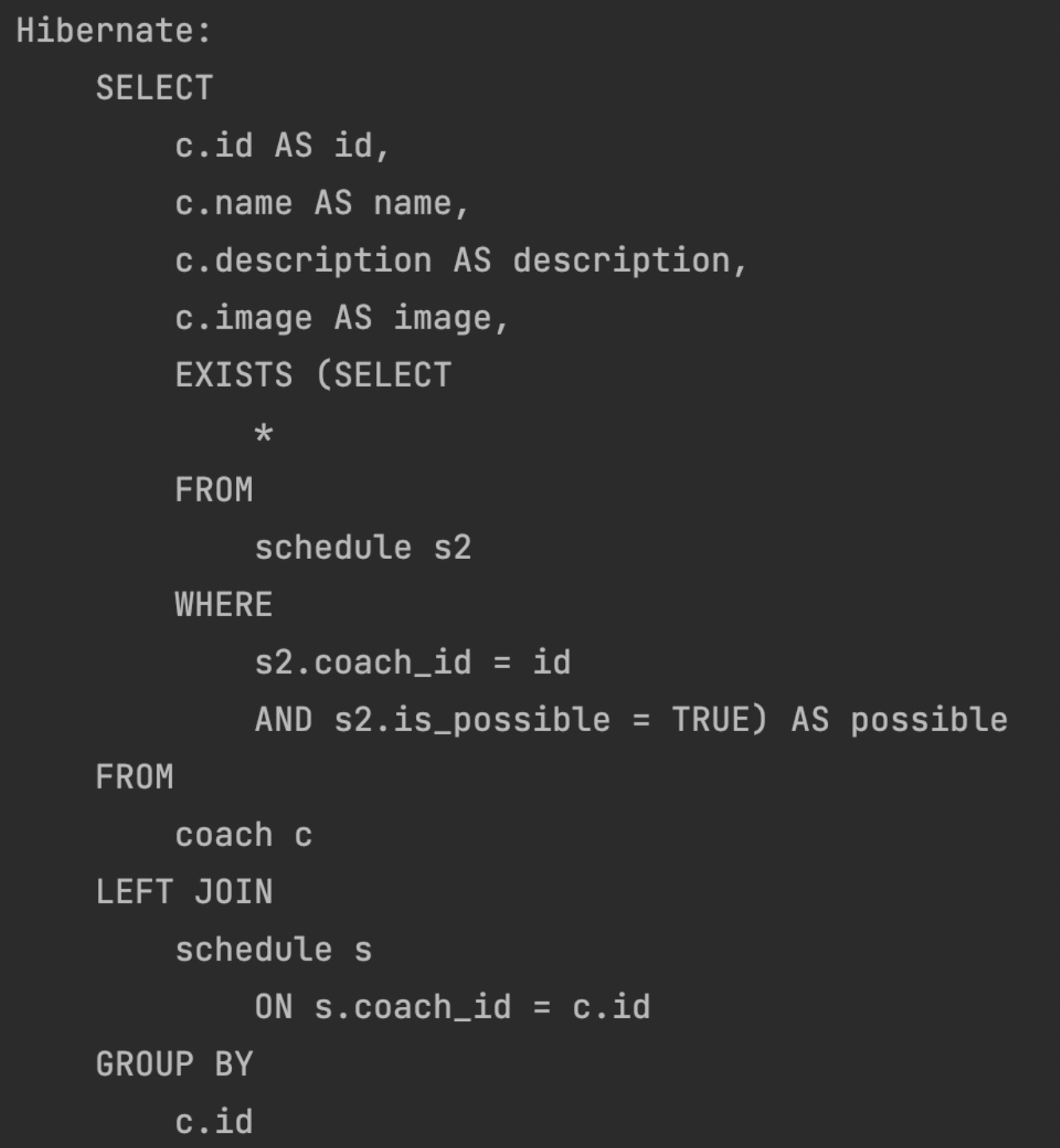
찍힌 쿼리를 보면 쿼리 한 번으로 n+1로 나가는 쿼리가 개선된 것을 확인해 볼 수 있다.
주의할 점
위의 쿼리의 리턴 타입을 보면 도메인이 아니라CoachWithPossible이라는 dto라는 것을 확인할 수 있다.
처음에 시도한 방법 - dto를 interface로 선언
public interface CoachWithPossible {
Long getId();
String getName();
String getDescription();
String getImage();
Boolean getPossible();
}구글링을 통해 얻은 dto로 쿼리의 결과를 매핑하는 가장 간단한 방법은 위와 같이 매핑할 dto를 인터페이스로 선언하는 방법이었다. 이 방법으로 모든 테스트 코드는 돌아갔으나.... 막상 dev 서버에 배포를 하니
JpaRepository - Hibernate - java.math.BigInteger cannot be cast to java.lang.Boolean
위와 같은 에러가 발생하였다. 테스트 환경의 db를 실제 사용하는 mysql 로 설정하지 않고 h2로 설정함에 따라 발생한 에러라고 판단하였다.(추후에 테스트 db도 mysql로 변경해야 겠다...🥲)
결론은 인터페이스를 이용한 매핑은 제대로 매핑이 일어나지 않는다!
최종적으로 시도한 방법 - @SqlResultSetMapping, @NamedNativeQuery 사용
@Entity
@SqlResultSetMapping(
name = "CoachWithPossibleMapping",
classes = @ConstructorResult(
targetClass = CoachWithPossible.class,
columns = {
@ColumnResult(name = "id", type = Long.class),
@ColumnResult(name = "name", type = String.class),
@ColumnResult(name = "description", type = String.class),
@ColumnResult(name = "image", type = String.class),
@ColumnResult(name = "possible", type = Boolean.class),
}
)
)
@NamedNativeQuery(
name = "findCoaches",
query = "SELECT c.id AS id, c.name AS name, c.description AS description, c.image AS image, EXISTS ("
+ "SELECT * FROM schedule s2 WHERE s2.coach_id = c.id AND s2.local_date_time > NOW() AND s2.is_possible = TRUE ) AS possible "
+ "FROM coach c",
resultSetMapping = "CoachWithPossibleMapping")결국 최종적으로 위와 같이 해당 도메인 클래스에서 @SqlResultSetMapping과 @NamedNativeQuery를 사용해 해결하였다. 이 방법은 김영한 JPA책 10장에 나오는 해결 방법이다. 위 방법을 처음부터 사용하지 않았던 이유는 도메인 클래스가 복잡해 질 수 있다는 이유 때문이었는데... 결국 이 방법으로 해결하였다. 나중에 더 좋은 방법이 있으면 개선해 봐야 겠다.
마무리
프로젝트의 불안정한 쿼리를 개선해보면서 다양한 지식을 흡수하고 있는 기분이다. 이번 개선기에서는 sql 서브 쿼리에 대해 배우게 되었다. 다음 개선기의 내용은 또 다시 n+1 문제 개선(이번과 다른 류의)일 것이다. inner join으로 실행되는 쿼리들에서 지연로딩에 의해 연관 엔티티를 조회하는 시점에서 n개의 쿼리가 추가로 발생하고 있는 로직을 봐버렸다....! 다음에도 재밌게 개선해 보자!
