
학습 동기
앞서 작성한 쿼리 개선기1, 쿼리 개선기2에 이어 진행하고 있는 프로젝트의 쿼리를 개선한 내용을 정리하기 위해 글쓰기를 다짐하게 되었다. 그럼 쿼리 개선기3 시작해보자...!
학습 내용
문제가 되는 로직 - N+1
Service
public CoachReservationsResponse findByCoachId(Long coachId) {
validateCoachId(coachId);
List<Reservation> reservations = reservationRepository.findAllByCoachIdAndStatusNot(coachId, DONE);
return classifyReservationsAndReturnDto(reservations);
}Repository
@Query("SELECT r FROM Reservation AS r "
+ "INNER JOIN r.schedule AS s "
+ "INNER JOIN s.coach AS c "
+ "ON c.id = :coachId "
+ "WHERE r.reservationStatus NOT IN :status")
List<Reservation> findAllByCoachIdAndStatusNot(Long coachId, ReservationStatus status);위의 로직은 코치가 자신의 예약 목록을 확인할 수 있게 하는 코치가 보는 메인 뷰 로직이다. 위의 JPQL 쿼리가 문제가 되는데
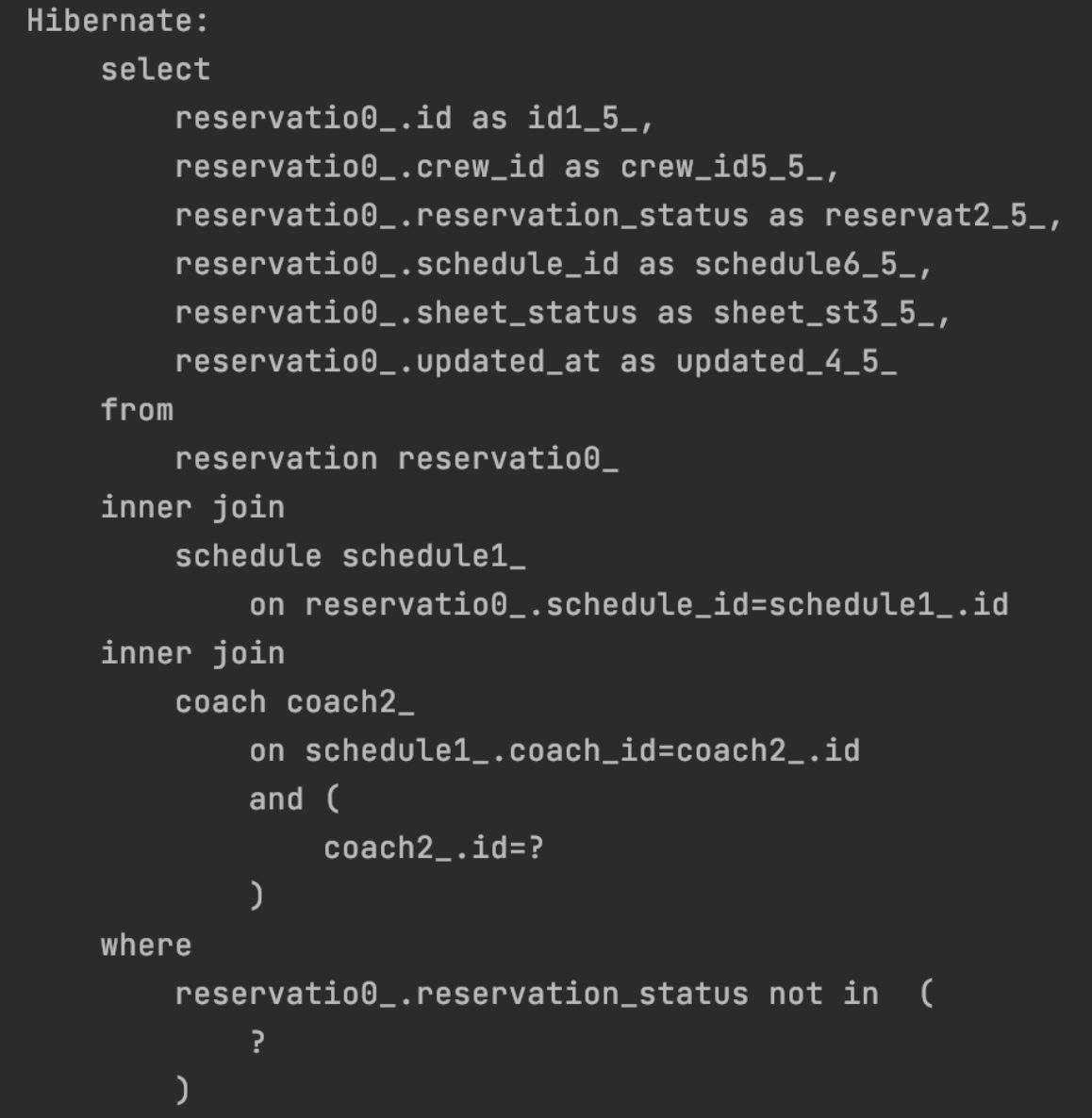
쿼리를 통해 위와 같이 Reservation 정보들과 Reservation과 연관된 엔티티의 id값들만 가져오고 있다. id만 조회하는 이유는 연관 엔티티들을 가져오는 전략을 지연로딩으로 설정했기 때문이다.(즉시로딩으로 해도 마찬가지긴하다.) 하지만 결국 응답을 내려 줄때는 이 id 값들(Crew, Schedule, Coach)을 이용해 연관된 엔티티의 세부 정보도 얻어오게 된다. 얻어 오는 부분은
private static CoachReservationDtoWithSheetStatus from(Reservation reservation) {
return new CoachReservationDtoWithSheetStatus(
reservation.getId(),
reservation.getScheduleDateTime(),
reservation.getCrew().getId(),
reservation.getCrew().getName(),
reservation.getCrew().getImage(),
reservation.getSheetStatus()
);
}위와 같다. 위는 메인 뷰에 노출될 응답을 내려주는 내부 dto 로직이다. JPQL 쿼리를 이용해 얻어온 Reservation 엔티티와 연관된 엔티티를 getXXX().get()XXX하는 시점에 n개의 쿼리가 추가로 발생하게 된다.
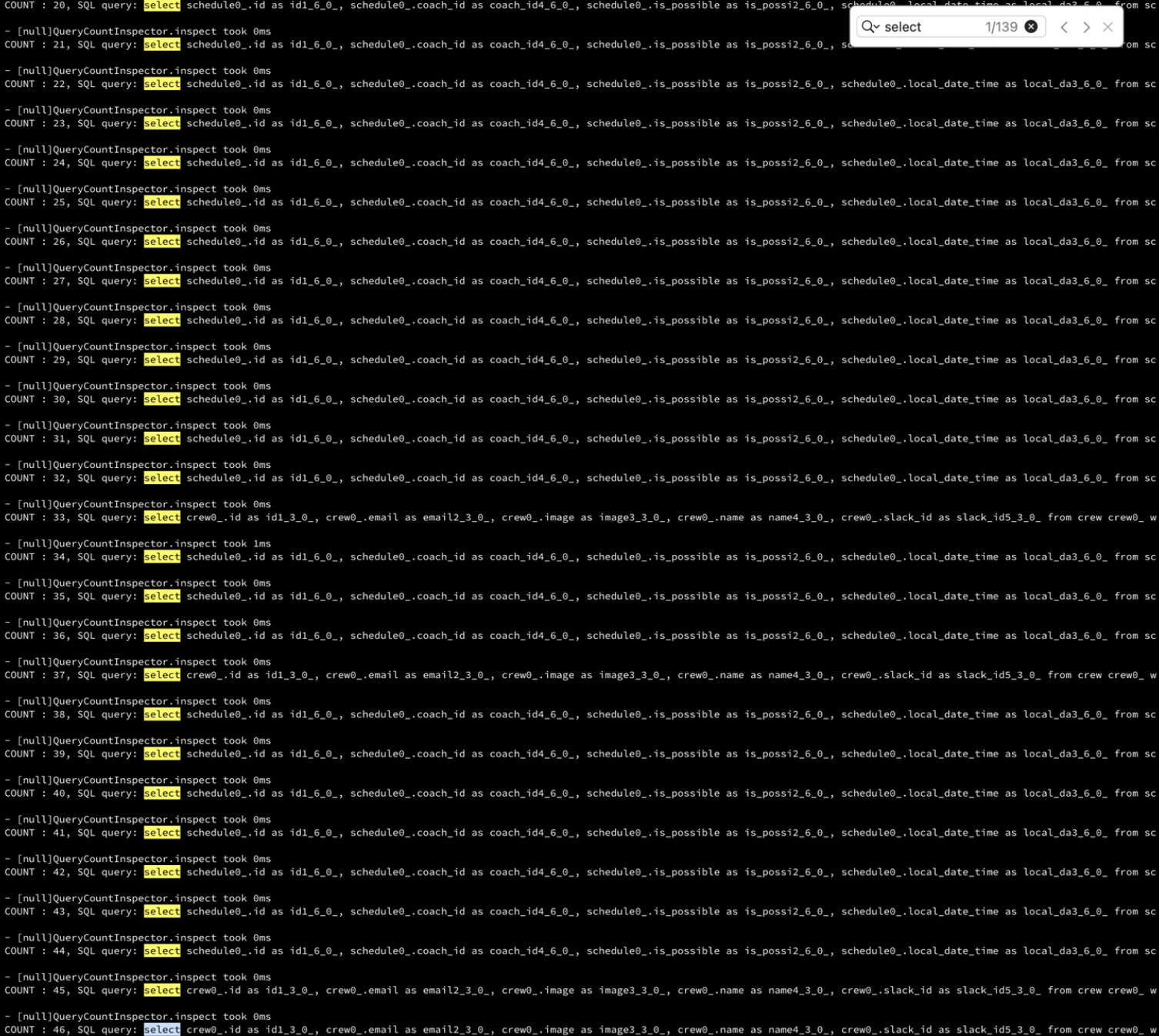
위는 실제 dev 서버에 찍힌 추가로 나가는 N개의 쿼리들이다. 해당 코치가 가진 예약의 개수에 비례해 N개의 쿼리가 추가로 나가고 있는데 예약 개수에 쿼리 개수가 종속적인 위험한 상황이라고 판단됐다.
해결 - Fetch Join 적용
적용후, 수정된 JPQL 쿼리
@Query("SELECT r FROM Reservation AS r "
+ "JOIN FETCH r.schedule AS s "
+ "JOIN FETCH r.crew AS cr "
+ "INNER JOIN s.coach AS co "
+ "ON co.id = :coachId "
+ "WHERE r.reservationStatus NOT IN :status")
List<Reservation> findAllByCoachIdAndStatusNot(Long coachId, ReservationStatus status);N+1 문제를 해결하는 가장 간단한 방법은 Fetch join을 적용하는 것이다. Fetch Join에 대해 간단하게 알아보도록 하자.
Fetch Join
- JPQL에서 성능 최적화를 위해 제공하는 기능
- 지연로딩이 일어나지 않는다
- sql 호출 횟수를 줄여 성능을 최적화 할 수 있다.
Fetch Join은 N+1 문제를 해결할 수 있는 JPQL에서 제공하는 가장 쉽고 효과적인 방법이다.
Fetch Join이 성능 최적화를 위해 사용되는 이유는 한 번의 쿼리로 연관된 엔티티의 id값만이 아닌 칼럼(필드) 값들까지 한 번에 가져오기 때문이다. Inner Join이나 Outer Join은 최초 쿼리의 결과로 연관된 엔티티의 id값만 가져오기 때문에 지연로딩이 적용된 경우는 연관 엔티티가 사용되는 시점(연관entity.getXXX().get()XXX하는 시점)에 가져온 id값을 통해 추가로 쿼리(ex. select * from Coach where id = ?)가 나가게된다. 즉시 로딩이 적용된 경우는 최초 쿼리로 가져온 id 값이 사용되는 시점이 아닌 최초 쿼리 바로 다음에 추가 쿼리가 즉각 나가게 된다.
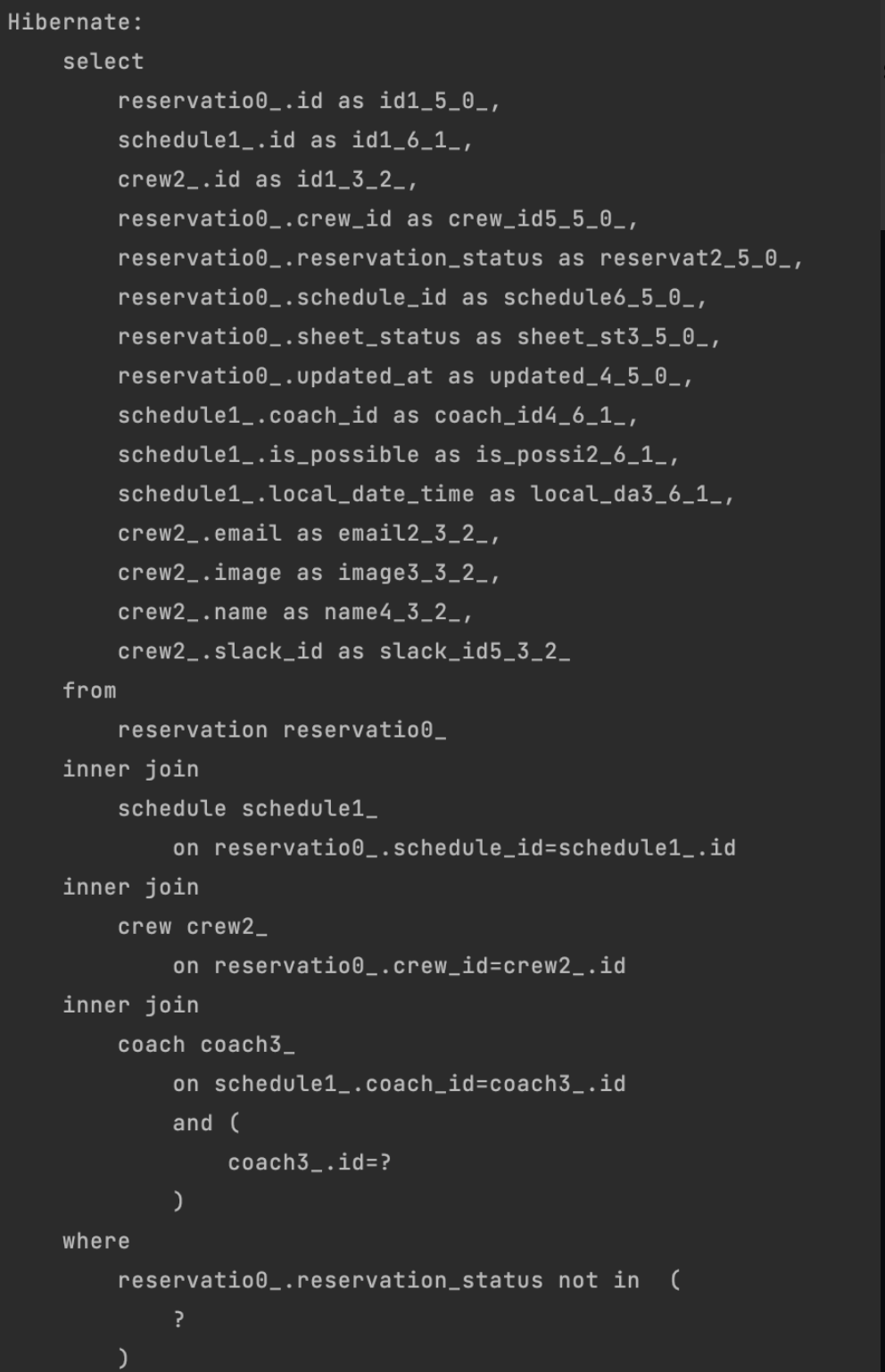
패치 조인 적용 후의 나가는 쿼리를 보면 위와 같이 연관 엔티티의 id값만이 아닌 엔티티의 필드 정보들 전부를 가져오고 있는 것을 확인할 수 있다. 결과적으로 N+1 문제를 해결할 수 있었다.

Fetch Join 주의점
패치 조인은 성능상 많은 이점을 가져 다 주지만 꼭 만능인 것은 아니다. 패치 조인은 객체 그래프를 유지할 때 사용하면 효과적이지만, 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 한다면 억지로 패치 조인을 사용하기 보다는 여러 테이블에서 필요한 필드들만 조회해서 DTO로 반환하는 것이 효과적이다. 패치 조인을 너무 남용하면 불필요한 정보들까지 가져오게 되어(한번에 너무 많은 정보를 가져오는 경우) 오히려 역으로 성능상 이슈가 발생할수도 있을 것으로 보인다.
