
학습 동기
현재 우테코에서 진행하고 있는 프로젝트에서 Spring data jpa에서 제공하는 saveAll()메서드를 사용하고 있다. 사용자 피드백을 반영하는 과정에서 saveAll() 메서드가 batch insert가 적용되지 않는다는 점을 깨달아 버렸고.... 1차적으로 이를 해결하기 위해 시작한 쿼리 개선기에 대해 정리해 보고자 글쓰기를 다짐했다.
학습 내용
문제가 되는 로직
public void update(Long coachId, List<ScheduleUpdateRequest> requests) {
for (ScheduleUpdateRequest request : requests) {
deleteAllByCoachAndDate(coachId, request);
saveAllByCoachAndDate(coachId, request);
}
}private void saveAllByCoachAndDate(Long coachId, ScheduleUpdateRequest request) {
Coach coach = findCoach(coachId);
List<Schedule> schedules = toSchedules(request, coach);
scheduleRepository.saveAll(schedules);
}
위의 로직은 코치가 스케쥴을 등록 및 수정하는 기능을 하는 로직이다. 사용자의 피드백에 따라 스케쥴을 일별이 아닌 월별로 일괄 처리하는 기능이 추가되면서 기존에 배치 처리되고 있지 않은 saveAll() 메서드의 성능이 더욱더 문제가 되는 상황이다.
요약을 해보면 위 로직에서 발생하는 문제점은 두 가지인데 아래와 같다.
문제1. saveAll() 메서드가 batch insert를 지원하지 않는다는 점
문제2. 쿼리생성에 직접적으로 영향을 미치는 로직을 반복문을 통해 처리하고 있는 점
문제1 - saveAll()
우선 문제 상황 1번부터 해결해 보자. 위의 saveAll()이 문제인 것은 요청 값을 통해 들어 오는 데이터 개수에 비례해 insert 쿼리가 각각 생성되기 때문이다. saveAll()은 이름만 보면 batch insert가 적용되는 것 같아 보이지만 확인해 보면 batch insert가 적용되고 있지 않는다.
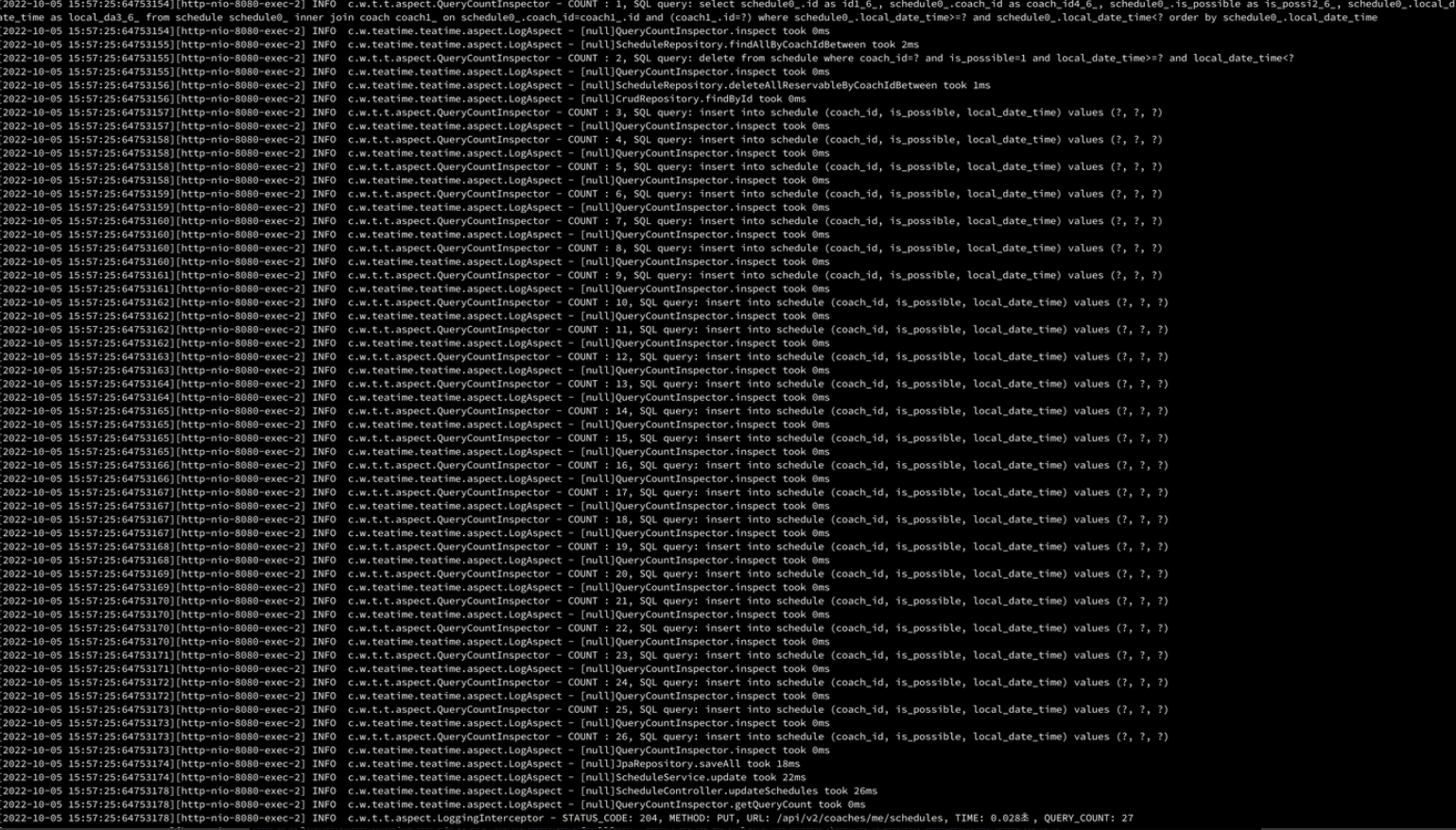
위의 로그를 보면 insert 쿼리가 응답 값에 비례해 생성되고 있음을 알 수 있다.
Spring data JPA의 saveAll() 메서드가 batch 적용이 안된다는 것은 사실 조금만 생각해 보면 약간은? 유추해 볼 수 있는 사실이다.(나는 간과했지한...ㅎ)
JPA는 엔티티들을 영속성 컨텍스트로 관리하는데 영속성 컨텍스트의 이점 중 하나인 쓰기 지연 저장소를 이용하려면 엔티티에 식별자 값인 id가 요구된다.(그냥 영속성 컨텍스트는 엔티티를 id값으로 관리하기 때문에 id값을 요구한다고 생각하면 편하다.) 따라서 save()를 할 때 엔티티에 식별자 id가 없다면 insert 쿼리를 쓰기 지연 저장소에 저장하고 플러시 시점에 db에 쿼리를 반영하는 것이 아니라 영속성 컨텍스트를 거치지 않고 바로 db에 쿼리를 찔러 버린다.
위 처럼 JPA에서 엔티티 save 원리를 생각해 보면 아 id값을 확인하고 존재하지 않으면 데이터 하나 하나를 바로 db로 찔러 버리는 구나라는 것을 유추해 볼 수 있지 않았을까?
또한 현재 Mysql의 id 생성 전략을 auto-increment로 가져가고 있는데 @GeneratedValue(strategy = GenerationType.IDENTITY) 설정에 대해서는 JPA에서 batch insert가 적용되지 않는다는 사실도 알게 되었다.
https://vladmihalcea.com/jpa-persist-and-merge/
이제 왜 saveAll메서드가 batch insert로 적용될 수 없는지 알게 되었다. 그럼 이 문제를 진짜로 해결하러 가보자.
해결 - JDBCTemplate 사용
saveAll에 batch insert를 적용하기 위해 Spring jdbc에서 제공하는 JDBCTemplate을 사용하였다.
@RequiredArgsConstructor
@Repository
public class ScheduleDao {
private static final int BATCH_SIZE = 1000;
private final JdbcTemplate jdbcTemplate;
public void saveAll(List<Schedule> schedules) {
int batchCount = 0;
List<Schedule> subItems = new ArrayList<>();
for (int i = 0; i < schedules.size(); i++) {
subItems.add(schedules.get(i));
if ((i + 1) % BATCH_SIZE == 0) {
batchCount = batchInsert(batchCount, subItems);
}
}
if (!subItems.isEmpty()) {
batchCount = batchInsert(batchCount, subItems);
}
}
private int batchInsert(int batchCount, List<Schedule> subItems) {
jdbcTemplate.batchUpdate("INSERT INTO schedule (coach_id, local_date_time, is_possible) VALUES (?, ?, ?)",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setLong(1, subItems.get(i).getCoach().getId());
ps.setTimestamp(2, Timestamp.valueOf(subItems.get(i).getLocalDateTime()));
ps.setBoolean(3, subItems.get(i).getIsPossible());
}
@Override
public int getBatchSize() {
return subItems.size();
}
});
subItems.clear();
batchCount++;
return batchCount;
}
}
JDBCTemplate은
1. 특정 db에 종속적인 쿼리가 적성된다는 단점
2. 조회한 데이터를 매핑할 RowMapper를 정의해야 한다는 단점
3. 애플리케이션 레벨에서 db접근 관련해서 관리포인트가 많아 진다는 단점
이 존재했지만 팀원들과 논의 끝에 우선 수 많은 응답에 대해 batch insert를 적용할 수 없다는 문제를 해결해주고 지금은 insert 로직만 처리할 것이기 때문에 단점2가 영향을 미치지 않으므로 JDBCTemplate을 사용하기로 최종적으로 결정하게 되었다.
문제2 - 반복문에 종속적인 쿼리 생성 로직
쿼리생성에 직접적으로 영향을 미치는 saveAllByCoachAndDate 메서드와 deleteAllByCoachAndDate 메서드가 반복문에 의존적인 것도 굉장한 문제이다.
해결 - 로직 개선
문제2에 대해서는 비교적 쉽게 해결 할 수 있었다.
개선전 로직
public void update(Long coachId, List<ScheduleUpdateRequest> requests) {
for (ScheduleUpdateRequest request : requests) {
deleteAllByCoachAndDate(coachId, request);
saveAllByCoachAndDate(coachId, request);
}
}위의 기존 로직에서는 리스트로 받은 request들을 반복문을 통해 돌리고 있었다. 이 request에서 필요한 정보들(localDateTime)을 stream을 통해 하나의 리스트로 묶어 해결할 수 있었다.
사실 delete 로직( deleteAllByCoachAndDate)에서 필요한 건 들어온 응답 값들의 localDateTime(날짜)들 중 가장 오래된 날짜와 가장 최신의 날짜였고 save 로직(saveAllByCoachAndDate) 에서 필요한 것도 날짜들 뿐이였다.(결국 날짜 들을 이용해 Schedule이라는 entity를 생성해서 save를 하기 때문)
List<Schedule> schedules = toSchedules(localDateTimes, coach);
scheduleDao.saveAll(schedules);개선후 로직
public void update(Long coachId, List<ScheduleUpdateRequest> requests) {
List<LocalDateTime> localDateTimes = requests.stream()
.map(ScheduleUpdateRequest::getSchedules)
.flatMap(Collection::stream)
.sorted()
.collect(Collectors.toList());
deleteAllByCoachAndDate(coachId, localDateTimes);
saveAllByCoachAndDate(coachId, localDateTimes);
}쿼리 네번(검증로직 2개 + delete 1개 + save 1개)으로 스케쥴 수정 로직을 처리할 수 있게 되었다.
마무리
사실 관리 포인트가 많아져서 JDBCTemplate을 이용하고 싶지는 않았지만 어쩔 수 없이 JDBCTemplate을 이용하게 됐다. 역시 인생은 내 맘대로 되지 않는구나... 그래도 재밌었다!🥲
JPQL 쿼리들이 복잡한 것들(join이 세 개 이상 등등)이 꽤 많은 것 같은데 이를 QueryDsl을 이용해 가독성을 높여보고 싶단 생각이 든다. 할 것도 많고 해보고 싶은 것도 많다.
