
학습동기
우아한테크코스 레벨3 프로젝트에서 기술 스택으로 JPA를 쓰기로 정해졌다. 근데 JPA는 왜 쓸까? JPA는 뭐고 어떻게 동작할까?
학습내용
JPA란?
JPA는 Java Persistence API로 관계형 데이터베이스(RDBMS)데이터를 자바 객체로 매핑하는 자바 표준 스펙이다.
여기서 객체와 RDBMS를 매핑하는 기술을 ORM이라고 한다. 그럼 ORM은 무엇일까?
ORM이란?
Object Relational Mapping의 줄임말로 객체-관계 매핑이란 뜻이다. 말 그대로 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말한다.
그럼 왜 객체와 관계형 데이터베이스를 매핑 시켜주는 도구가 필요할까? 이유는 다음과 같다.
-> 객체 지향 프로그램은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용한다. 이때 객체 모델과 관계형 모델 간에 불일치가 존재하는데 ORM이 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결해 주는 것이다.
이 ORM이라는 도구를 알기 전에는 DAO를 만들고 늘 그 안에 RowMapper를 따로 만들어주고 JDBCTemplate을 이용해 쿼리 문을 작성하여 객체와 관계형 데이터 베이스의 불일치를 해결하였다. 예시를 들어서 알아보자.
JDBCTemplate 사용
@Repository
public class CustomerDao {
private static final RowMapper<Customer> CUSTOMER_ROW_MAPPER = (rs, rowNum) -> {
return new Customer(
rs.getLong("id"),
rs.getString("email"),
rs.getString("name"),
rs.getString("password")
);
};
private final JdbcTemplate jdbcTemplate;
public CustomerDao(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public Optional<Customer> findById(Long id) {
final String sql = "SELECT id, email, name, password FROM Customer WHERE id = ?";
try {
return Optional.ofNullable(jdbcTemplate.queryForObject(sql, CUSTOMER_ROW_MAPPER, id));
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}JPA 사용
public interface CustomerDao extends JpaRepository<Customer,Long> {
Optional<Customer> findById(Long Id);
}위의 예시를 보면 알 수 있듯이 JPA를 사용하면 코드 자체가 훨씬 깔끔해 진다. 엄밀히 말하면 JPA 예시 코드는 JPA를 Spring framework에서 JPA를 편리하게 사용할 수 있도록 해주는 Spring JPA를 사용한 것이지만 일단 JPA의 예시라고 해도 좋을 듯 하다.
또한 JdbcTemplate을 사용하면 Entity가 되는 Class에 새로운 필드가 추가되면 관련 SQL을 다 수정해야 한다는 단점도 존재한다.
public Optional<Customer> findById(Long id) {
final String sql = "SELECT id, email, name, password FROM Customer WHERE id = ?";
try {
return Optional.ofNullable(jdbcTemplate.queryForObject(sql, CUSTOMER_ROW_MAPPER, id));
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}위 코드에서 Customer의 필드에 nickname이 추가된다면 일일이 DAO의 sql문을 수정해 줘야 한다. JPA를 사용하면 이러한 불필요한 반복 작업을 줄여 준다는 장점도 있다.
마지막으로 스키마를 자동 생성해준다는 장점도 존재한다. 사실 이것은 실제 운영디비에서 조심스럽게 사용해야 될 것 같은 느낌이 들지만 test코드를 짤 때는 아주 편할 것 같다.
JdbcTemplate을 사용할 때는 Schema.sql파일을 따로 만들어 스키마를 sql 문법에 맞게 수기로 작성해 줘야 했다.
Schema.sql
drop table if exists product;
drop table if exists customer;
create table customer
(
id bigint not null auto_increment,
username varchar(255) not null,
primary key (id)
) engine=InnoDB default charset=utf8mb4;
alter table customer
add unique key (username);
create table product
(
id bigint not null auto_increment,
name varchar(255) not null,
price integer not null,
image_url varchar(255),
primary key (id)
) engine=InnoDB default charset=utf8mb4;
JPA를 사용하면 ddl-auto 설정을 통해 이런 수기 작업에 대한 수고를 줄일 수 있다.
ex) spring.jpa.hibernate.ddl-auto=create
ddl-auto 옵션 종류
create: 기존 테이블 삭제 후 다시 생성 (DROP + CREATE)
create-drop: create와 같으나 종료시점에 테이블 DROP
update: 변경된 부분만 반영 (운영 DB에 사용하면 안됨)
validate: entity와 table이 정상 매핑되었는지만 확인
none: 사용하지 않음
정리하자면, JPA를 사용하면
1. 코드가 깔끔해딘다
2. 반복작업이 줄어든다
3. 스키마 자동 생성해준다.
는 장점이 있을 수 있다는 생각을 했다.
결국 합쳐서 생각해보면 Sql에 쏟는 개발자의 수고를 줄여주고 도메인에 집중 할 수 있게 해주는 것이 핵심이다. 우리는 객체 지향적인 코드로 인해 더 직관적으로 비즈니스 로직에 집중할 수 있다.
JPA 동작원리
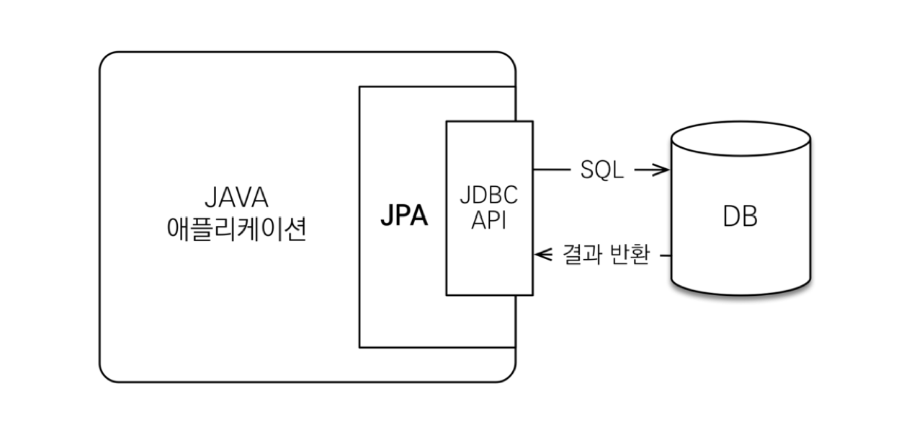
JPA를 조금이라도 아는 사람들은 위 그림을 한 번 쯤은 봤을 것이다. 그림에서 볼 수 있듯이 JPA는 java 애플리케이션과 JDBC 사이에서 동작한다. JPA를 사용하면, JPA 내부에서 JDBC API를 사용하여 SQL을 호출하여 DB와 통신한다. 즉, 개발자는 JDBC에 직접 관여하지 않아도 된다는 것이다.
위의 JDBCTemplate 사용 코드 예시에서 볼 수 있듯이 JDBCTemplate은 DB 연결에 대해서 개발자에게 편리함을 주긴 하지만 SQL을 알아야 한다는 점에서 개발자에게 귀찮은 작업을 남겨준다.
JPA는 개발자가 JDBC와 SQL에서 벗어나게 해준다는 이점을 주면서 동작한다.
영속성 컨텍스트
그럼 이제 JPA의 중요한 특징이라고 하는 영속성 컨텍스트에 대해서 간단하게 알아보자.
영속성
우선 영속성이란
데이터를 생성한 프로그램이 종료되어도 사라지지 않는 데이터의 특성을 말한다.
우리는 데이터를 파일이나 DB에 영구 저장함으로써 데이터에 영속성을 부여한다.
이제 영속성에 대해 알아봤으니 본론으로 돌아가 영속성 컨텍스트에 대해 알아보자.
영속성 컨텍스트
- 엔티티를 담고 있는 집합.
- JPA는 영속 컨텍스트에 속한 엔티티를 DB에 반영한다.
- 엔티티를 검색, 삭제, 추가하게 되면 영속 컨텍스트의 내용이 DB에 반영된다.
- 영속 컨텍스트는 직접 접근이 불가능하고 EntityManager를 통해서만 접근이 가능하다.
여기서 엔티티란 @Entity를 붙인 DB와 매핑되는 class를 뜻한다.
Dirty Checking
JPA를 공부하면서 가장 신기하다고 느낀 점이 dirty checking이다. dirty cheking이란 변경을 감지한다는 뜻으로 객체 수정시에 우리에게 새로운 경험을 하게 해준다.
기존 JDBCTemplate을 사용할 때는 객체를 수정할 때 jdbcTemplate.update()를 해줌으로 DB에 수정한 객체를 반영해 줘야 했다.
하지만 JPA를 사용하면 Dirty Checking 기능으로 인해 .update()를 하지 않아도 된다.
이유는 Dirty Checking으로 인해 객체가 수정되면 영속성 컨텍스트에 등록된 객체의 스냅샷과 변경된 객체를 비교해서 달라졌으면 트랜잭션이 commit될 때 알아서 update 쿼리를 내부적으로 보내기 때문이다.
마무리
JPA에 대해 간략하게 알아보았는데 아직 모르는 부분이 많이 있다고 느꼈다. 이번 학습을 통해 내가 아직 DB 개념에 대해서도 많이 부족하여 JPA를 확실히 이해하는데 어려움이 있다는 것을 깨달았다. 앞으로 JPA를 사용하면서 더 깊게 공부해 볼 예정이고 DB공부도 더 많이 해야겠다.
