
학습동기
얼마전에 우아한테크코스에서 제이슨의 JPA 강의를 들었다. 프로젝트에서 JPA를 쓰는 입장인데 내가 JPA에 대해 '모르는 것이 많구나.'라고 느끼게 되는 강의였다. JPA에 대해 좀 더 공부하고자 학습을 다짐했다.
학습내용
우선 JPA의 가장 중요한 특징이라고 할 수 있는 영속성 컨텍스트에 대해 알아보자.
영속성 컨텍스트
- 엔티티를 영구 저장하는 환경이라는 뜻이다.
- 애플리케이션과 데이터베이스 사이에서 엔티티를 보관하는 장소이다.
- 엔티티가 DB에 저장되기 전에 머무는 장소이다.
- 자바의 컬렉션(list, map, set등등)과 비슷한 느낌이다.
내가 이해한 영속성 컨텍스트의 정의는 위와 같다. 영속성 컨텍스트는 직접 접근이 불가하고 EntityFactory에서 생성된 EntityManager를 통해 접근가능하다. EntityManager를 통해 엔티티를 저장하거나 조회할 때, 영속성 컨텍스트에 엔티티가 보관되고 관리된다.
entityManager.persist(entity)EntityManager의 .persist호출로 인해 entity가 영속성 컨텍스트에 저장된다. DB에 저장되는 것이 아닌 JPA의 영속성 컨텍스트에 저장된다!
EntityManager가 생성될 때 영속성 컨텍스트가 하나 만들어진다. 스프링 프레임워크에서 EntityManager를 주입받아사용할 때는, 같은 트랜잭션 범위에 있는 EntityManager는 동일한 영속성 컨텍스트에 접근하게 된다.
영속성 컨텍스트의 특징
영속성 컨텍스트의 특징은 크게 두 가지로 볼 수 있다.
1. 영속성 컨텍스트는 식별자 값(id)이 있어야 한다.
영속성 컨텍스트는 엔티티를 식별자 값으로 구분한다. 따라서 엔티티에 식별자 값이 없으면 영속성 컨텍스트에 의해 관리될 수 없다. 즉, 식별자 값(id)는 영속성의 조건이다.
2. flush(플러시)
JPA는 트랜잭션 커밋 시(entityManager.flush()로 직접 호출하거나 JPQL 쿼리 실행으로 자동 호출하는 방법도 있음) 영속성 컨텍스트에 새로 저장된 엔티티를 DB에 반영한다. 이때 영속성 컨텍스트의 변경내용을 데이터베이스에 반영하는 것을 플러시라고 한다. 커밋이 될 때 자동으로 발생하지만 실제로는 플러시 다음에 실제 커밋이 일어난다.
이때 주의해야 될 사항은 플러시로 인해 영속성 컨텍스트가 비워지는 것은 아니라는 것이다. 플러시는 영속성 컨텍스트의 변경 사항들과 DB의 상태를 맞추는 작업으로 영속성 컨텍스트의 변경 내용을 DB에 동기화한다.
플러시를 하게 되면 dirty checking(변경 감지)이 일어나고 쓰기 지연 저장소(등록, 수정 ,삭제 쿼리 저장소)가 비워진다. 하지만 1차 캐시는 그대로 유지된다.
그럼 1차 캐시, 쓰기 지연 저장소, 변경 감지는 뭘까??
영속성 컨텍스트의 이점을 통해 알아보자.
영속성 컨텍스트의 이점
- 1차 캐시
- 동일성 보장
- 트랜잭션을 지원하는 쓰기 지연
- 변경 감지
- 지연 로딩
영속성 컨텍스트의 이점은 위와 같다. 하나 씩 살펴보자.
1차 캐시
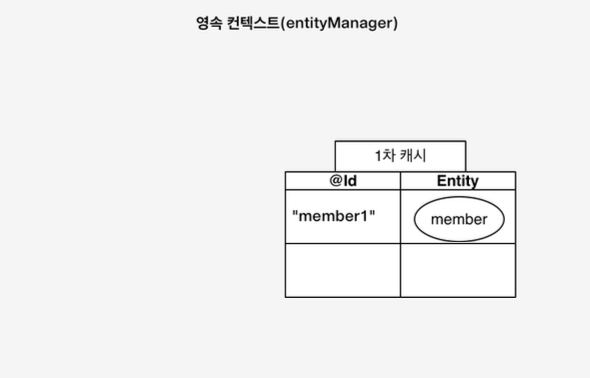
영속성 컨텍스트 안에는 위의 그림과 같이 1차캐시가 내장되어 있다. 1차 캐시에 엔티티가 저장되려면 Entity에 @ID 어노테이션이 붙은 key가 존재해야한다. 이 식별자를 Key값으로 해서 1차 캐시에 엔티티가 저장되는 것이다. 예를 들어 보자.
// 처음에 1차 캐시에 id가 1인 엔티티가 없다고 가정
1. entityManager.find(User.class, "1");
2. entityManager.find(User.class, "1"); 우선 1번의 findByID 명령을 통해
1. id가 1인 User 엔티티를 1차 캐시에서 찾는다.
2. 1차 캐시에 해당 엔티티가 없으므로 DB에 접근해 값을 조회한다.
3. 다음 조회 요청에서 재사용 할 수 있도록 1차 캐시에 엔티티 값을 저장한다.
4. 애플리케이션에 엔티티 값을 반환한다.
다음과 순서로 엔티티 값이 조회된다.
그리고 2번의 findByID 명령을 통해
1. id가 1인 User 엔티티를 1차 캐시에서 찾는다.
2. 1차 캐시에서 해당 엔티티 값을 탐색해 반환한다.
다음 순서로 엔티티 값이 조회된다.
우리는 1차 캐시를 다음과 같이 DB에서 값을 조회하는 과정(Sql 쿼리를 db에 날리는 작업)을 생략하여 이점을 얻을 수 있다.
1차 캐시 동작 확인 - 1차 캐시 적용된 경우
@DataJpaTest
@Sql("/import.sql")
class MemberRepositoryTest {
@Autowired
private MemberRepository members;
@Test
void firstLevelCache() {
members.findById(1L);
members.findById(1L);
}
}

두 번의 findById()를 명령했지만 한 번의 sql쿼리가 날라가는 것을 확인할 수 있다.
1차 캐시 동작 확인 - 1차 캐시 적용안된 경우
@DataJpaTest
@Sql("/import.sql")
class MemberRepositoryTest {
@Autowired
private MemberRepository members;
@Test
void firstLevelCache() {
members.findByName("ing");
members.findByName("ing");
}
}

식별자 값으로 조회하지 않으면 위와 같이 두 번의 sql쿼리가 날라가는 것을 확인할 수 있다.
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true)
private String name;entity Member의 구조는 위와 같다. name을 unique로 저장하더라도 1차 캐시에 저장되지 않는다. 1차 캐시는 @ID 에노테이션이 붙은 필드 값만을 키 값으로 사용한다는 것을 알 수 있다.
그럼 1차 캐시에 값은 언제 비워질까?
값이 1차 캐시에 항상 저장되는 것은 아니다. EntityManager는 앞에서 설명했듯이 트랜잭션 단위로 동작하기 때문에 트랜잭션이 끝나면 1차 캐시도 지워진다. 아마도
1. 커밋을 인지한 플러시 발생 (이때 비워지는 것은 절대 아님)
2. 실제 데이터베이스에 커밋
3. 엔티티 매니저가 close됨
3. 영속성 컨텍스트가 닫히고 1차 캐시가 비워짐
이 플로우로 1차 캐시가 비워지는 것이라고 생각한다.
동일성 보장
우리는 영속성 컨텍스트를 통해 엔티티의 동일성도 보장받을 수 있다.
@Test
void identity() {
final Member member1 = members.findById(1L).get();
final Member member2 = members.findById(1L).get();
assertThat(member1 == member2).isTrue();
}
위의 테스트는 영속성 컨텍스트가 엔티티의 동일성을 보장해 주기 때문에 성공한다.
그럼 왜 동일성을 보장해 주는 것일까?
동일성이 보장되는 이유는 1차 캐시 때문이다. 앞에서 알아 봤듯이 member2를 반환할 때는 DB를 조회하지 않고 1차 캐시에 저장된 엔티티를 바로 가져옴으로 member1과 member2의 동일성이 보장되는 것이다.
1차 캐시로 REPEATABLE READ 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공받을 수 있다.
REPEATABLE READ 등급의 트랜잭션 격리 수준
REPEATABLE READ란 간단히 말해서 동일한 트랜잭션 내에서 동일한 결과를 보여주는 트랜잭션 격리 수준을 뜻한다. 다른 트갠잭션 내에서 데이터가 변경되었을 경우에 다른 결과가 보여지는 것을 해결한 격리수준이다.
트랜잭션을 지원하는 쓰기 지연(transactional write-behind)

쓰기지연이란 영속성 컨텍스트에 변경이 발생했을 때,(영속성 컨텍스트에 엔티티가 들어왔을 때) 바로 데이터 베이스에 쿼리를 보내지 않고 SQL 쿼리를 쓰기 지연 저장소(버퍼)에 모아 놨다가, 영속성 컨텍스트가 flush하는 시접에 모아둔 SQL 쿼리를 데이터베이스로 보내는 기능이다.
위 그림의 memberA와 memberB가 영속성 컨텍스트에 들어오면 1차 캐시에 엔티티가 저장되고 쓰기 지연 저장소에 sql을 쌓아둔다. 그리고 트랜잭션널이 커밋되는 시점에 flush 호출을 통해 쓰기 지연 저장소에 있는 데이터베이스로 sql 쿼리를 보낸다.
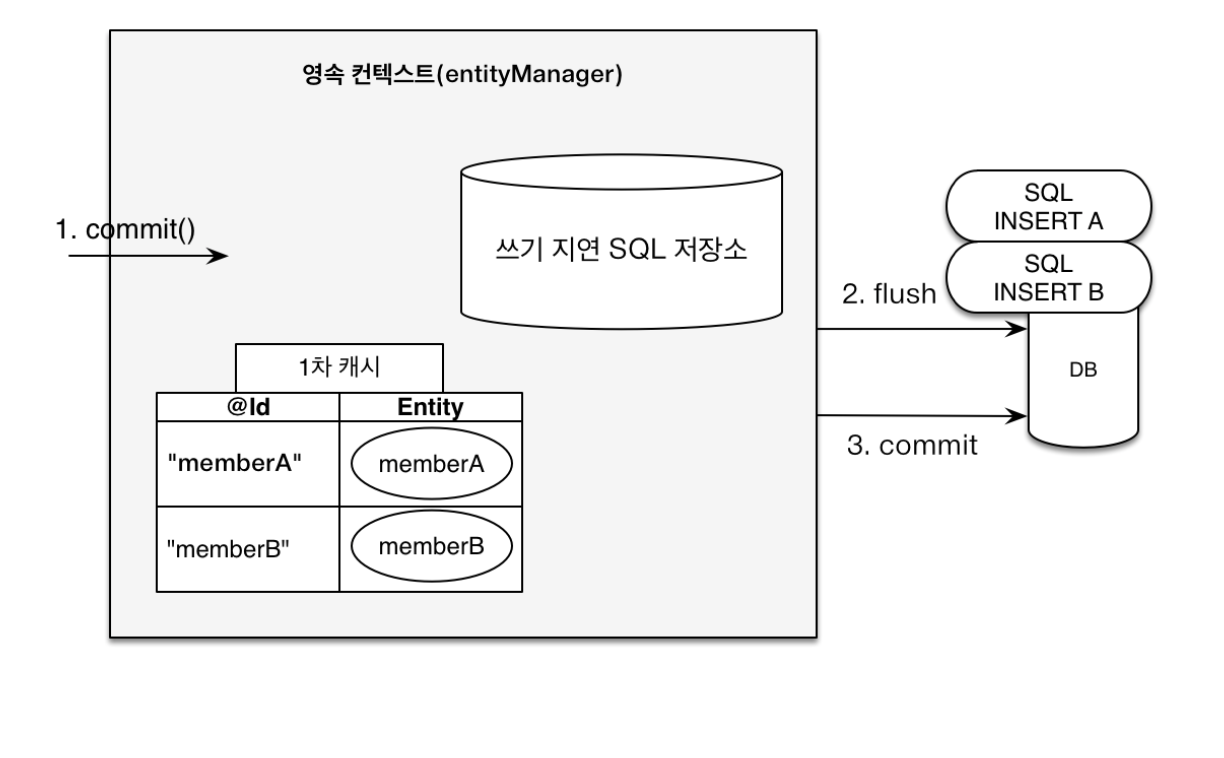
참고
@ID 기본 키 자동 생성 전략인 INDENTITY 식별자 생성 전략은 엔티티를 데이터베이스에 저장해야 식별자를 구할 수 있으므로 em.persist()를 호출하는 즉시 INSERT SQL이 데이터베이스로 전달된다.
따라서 쓰기 지연이 동작하지 않는다.
Dirty Checking(변경 감지)
dirty checking이란 변경을 검사한다는 것이다. 영속성컨텍스트를 이용하면 update 로직을 따로 실행하지 않아도 된다. 이 기능은 눈으로도 바로 확인이 가능해 JPA를 처음 써보면 다들 신기해 할 기능이다. 예를 들어보자.
@Test
void dirtyChecking() {
final Member member = members.findById(1L).get();
System.out.println(member.getName());
member.setName("eng");
members.flush();
}

위의 예시를 보면 애플리케이션 레벨에서 객체를 변경했을 뿐인데 update 쿼리가 실행되는 것을 확인할 수 있다. 이것이 dirty checking 때문이다. dirty checking은 왜 일어날까?
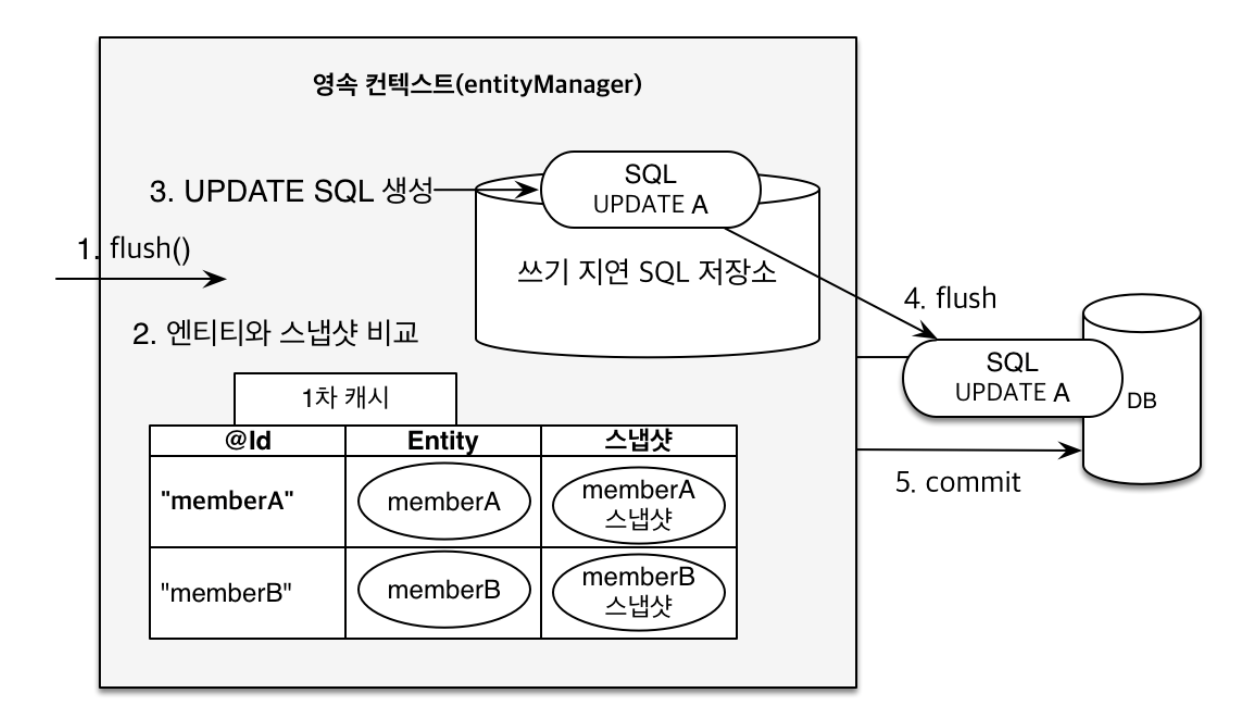
JPA에서는 엔티티를 조회하면 해당 엔티티를 조회 상태 그대로 1차 캐시에 스냅샷을 만들어 놓는다. 그리고 트랜잭션이 커밋되는 시점에, 더 정확히는 flush될 때 이 스냅샷과 엔티티 객체를 비교해 변경이 되었으면 update 쿼리를 쓰기 지연 저장소에 생성하고 db에 반영한다.
지연 로딩(Lazy Loading)
이제 지연 로딩에 대해 간단히 알아보자. 예를 들어보자. Meber와 Product가 1:N 관계라고 할 때, 지연 로딩은 로딩 시점에 Lazy 로딩 설정이 되어 있는 Product 엔티티를 프록시 객체로 가져온다.
그리고 이후에 실제 Product가 사용되는 시점에 초기화가 된다. 이 때 관련 쿼리가 날아간다.
간단히 말해 지연로딩은 실제 객체 대신 프록시 객체를 로딩해주고 해당 객체를 실제 사용할 때 영속성 컨텍스트를 통해 데이터를 불러오는 방법이다.
마무리
이번에는 JPA의 영속석 컨텍스트에 대해 알아봤다. 학습을 하면서 아직 많이 모호한 부분이 많다고 생각했다. 지연로딩, 프록시, 2차 캐시, 트랜잭션.....등등 앞으로 JPA 학습을 더욱더 열심히 해서 최대한 이해해 보고자 한다.

잉로그 진짜 너무 유용해요~! JPA 추가 포스팅 기대하겠습니다.