
컴퓨터(영어: computer, 문화어: 콤퓨터, 콤퓨타, 순화어: 전산기)는 전자 회로를 이용하여 프로그램과 정보를 전자적 형태(electronic form)로 저장하고 빠르게 계산하고, 입력된 데이터를 정해진 프로그래밍에 따라 처리하고 정보로 출력하는 전자 기기(programmable machine)다. 즉, 논리 연산이나 산술 연산을 자동으로 수행하도록 프로그래밍할 수 있는 범용 장치(electronic device)다. - Wikipedia 컴퓨터
말이 쓸데없이 복잡하지만 여기서 컴퓨터를 관통하는 핵심 단어는 다음과 같다: 입력 과 계산 그리고 출력 이다. 저장도 들어갈 순 있지만 메인은 아니다. 그럼 여기서 컴퓨터는 대체 무엇을 입력하고 계산하고 또 출력하는걸까? 그것은 바로 데이터 이다. 컴퓨터를 관통하는 핵심 개념 세 가지 모두 데이터를 다룬다. 이 때문에 자료구조 라는 학문 역시 생겨났다. 그만큼 컴퓨터에서 데이터는 정말 중요한 요소이다. 이번 글에서는 리눅스가 데이터를 어떻게 다루는지 설명할 것이다.
현재 작성 글 기준 커널 버전은 4.20 이다. 따라서 0 장에서 했던 것과 같이 4.20 버전으로 checkout 하면 된다.
1. C 언어의 기본 자료형
C 언어는 프로그래머를 위해 다양한 자료형을 제공한다. 대표적인 정수 자료형으로 int, 실수 자료형으론 float 을 제공한다. C 언어는 프로그래머에게 다양한 데이터 타입을 제공하고, 따라서 프로그래머는 폭넒은 선택을 할 수 있게 된다. 하지만 여기에는 하나의 큰 문제가 존재한다.
C 언어는 데이터 타입의 크기를 명세하지 않는다. 따라서int의 크기는2 byte일 수도182,311,267 byte일 수도 있다.
일반적으로 int 는 4 byte 지만 이는 아키텍쳐 와 컴파일러 에 따라서 바뀔 수 있다. 더 나아가 아키텍쳐에 따라 byte 의 크기 또한 바뀔 수 있다. (1 byte 는 8 bit 가 아니다. 이는 매우 중요한 포인트다) 이러한 애매모호함은 프로그래머가 자료형을 선택하는 것을 어렵게 만든다.
2. typedef 타입 재정의
사실 C 에서도 이러한 문제를 해결하기 위한 데이터 타입(<stdint.h> 에 정의된 고정 크기 자료형)을 제공하지만 이러한 구현은 사실 운영체제와 컴파일러를 통해 이뤄진다. 닭(운영체제)가 먼저냐, 달걀(컴파일러)가 먼저냐 같은데... 우선 닭 먼저 살펴 보겠다.
data/type01.c/** M: Yeounsu Moon <yyyynoom@gmail.com> W: https://velog.io/@mythos F: data/type01.c This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License */ #include <stdio.h> #include <stdlib.h> typedef char s8; typedef unsigned char u8; typedef short s16; typedef unsigned short u16; typedef int s32; typedef unsigned int u32; typedef long s64_; typedef unsigned long u64_; typedef long long s64; typedef unsigned long long u64; int main(void) { printf("s8 = %zu bytes\n", sizeof(s8)); printf("u8 = %zu bytes\n", sizeof(u8)); printf("s16 = %zu bytes\n", sizeof(s16)); printf("u16 = %zu bytes\n", sizeof(u16)); printf("s32 = %zu bytes\n", sizeof(s32)); printf("u32 = %lu bytes\n", sizeof(u32)); printf("s64_ = %zu bytes\n", sizeof(s64_)); printf("u64_ = %zu bytes\n", sizeof(u64_)); printf("s64 = %zu bytes\n", sizeof(s64)); printf("u64 = %zu bytes\n", sizeof(u64)); return 0; }
앞서 말했듯이 들여쓰기 크기는 8 칸이다. 위 코드는 C 언어의 기본 자료형을 typedef 하여 크기를 명시하고, 출력하는 코드이다. 실행결과는 다음과 같다: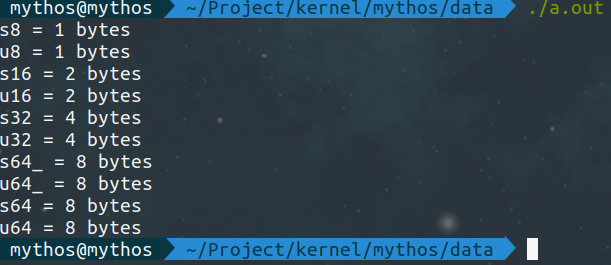 운영체제는
운영체제는 Ubuntu, 아키텍처는 x86_64, GCC x86_64 컴파일러(버전 9.3.0)를 사용해서 컴파일한 결과이다. 컴파일러나 운영체제, 아키텍처가 달라도 전체적인 결과는 대체로 비슷하겠지만, s64_ 와 u64_ 의 크기는 다를(대체로 4 byte) 수 있다.
데이터 타입 크기는 가변적이기 때문에 위와 같이 typedef 하여 그 크기를 명시하는 것은 중요하다. 위와 같이 데이터의 크기를 자료형 이름 안에 인코딩하여 넣게 되면 프로그래머는 필요에 따라 적절한 크기의 자료형을 선택할 수 있고, overflow (signed 의 overflow 는 Undefined behavior(UB) 이다) 나 UB 에 대처하기 쉽다.
참고로 위에서 정수 기본 자료형은 타입 재정의를 했지만 실수형은 하지 않았는데, 그 이유는 리눅스 커널이 성능상의 문제로 실수 자료형을 사용하지 않기 때문이다.
3. 헤더 파일로 분할
위에서 만든 type01.c 는 테스트를 위해 만든 코드이고, 이후에 사용할 코드에선 이를 헤더파일로 만들어 사용할 것이다.
data/type02.h/** M: Yeounsu Moon <yyyynoom@gmail.com> W: https://velog.io/@mythos F: data/type02.h This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License */ // include/uapi/asm-generic/int-ll64.h typedef __signed__ char __s8; typedef unsigned char __u8; typedef __signed__ short __s16; typedef unsigned short __u16; typedef __signed__ int __s32; typedef unsigned int __u32; #ifdef __GNUC__ __extension__ typedef __signed__ long long __s64; __extension__ typedef unsigned long long __u64; #else typedef __signed__ long long __s64; typedef unsigned long long __u64; #endif // include/asm-generic/int-ll64.h typedef __s8 s8; typedef __u8 u8; typedef __s16 s16; typedef __u16 u16; typedef __s32 s32; typedef __u32 u32; typedef __s64 s64; typedef __u64 u64;
행 주석으로 표시한 커널의 디렉토리로 이동하여 파일의 내용을 살펴보면 동일한 내용이 담겨있다. 그걸 가져와 모은 것이type02.h 다. 전체적으로 type01.c 와 크게 다르지 않다. 다만 일부 컴파일러 확장을 사용하였다. __extension__ 은 -ansi 나 -pedantic 같은 키워드로부터 발생하는 경고를 피하기 위해 사용한다. __signed__ 역시 -traditional 옵션이 붙어 있을 때 signed 키워드를 해석하지 못하는 문제를 막기 위해 사용한다.
이제 type02.h 헤더를 활용하여 새로운 타입을 재정의 해보겠다.
data/type03.h/** M: Yeounsu Moon <yyyynoom@gmail.com> W: https://velog.io/@mythos F: data/type03.h This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License */ // include/linux/types.h /* bsd */ typedef unsigned char u_char; typedef unsigned short u_short; typedef unsigned int u_int; typedef unsigned long u_long; /* sysv */ typedef unsigned char unchar; typedef unsigned short ushort; typedef unsigned int uint; typedef unsigned long ulong; #ifndef __BIT_TYPES_DEFINED__ #define __BIT_TYPES_DEFINED__ typedef u8 u_int8_t; typedef s8 int8_t; typedef u16 u_int16_t; typedef s16 int16_t; typedef u32 u_int32_t; typedef s32 int32_t; #endif /* !(__BIT_TYPES_DEFINED__) */ // #if defined(__GNUC__) #if defined(_GNUC_) typedef u64 uint64_t; typedef u64 u_int64_t; typedef s64 int64_t; #endif #ifdef CONFIG_ARCH_DMA_ADDR_T_64BIT typedef u64 dma_addr_t; #else typedef u32 dma_addr_t; #endif // include/uapi/asm-generic/posix_types.h typedef unsigned long __kernel_ulong_t; typedef __kernel_ulong_t __kernel_size_t; typedef __kernel_size_t size_t;
위 파일 역시 리눅스 커널의 파일에 내용을 긁어서 완성한 헤더파일이다. 실제로 해당 경로로 들어가서 어떤 내용이 들어있는지 살펴보면 많은 도움이 될 것이다.
4. 한계(limits)
지금까진 데이터 타입을 재정의하여 해당 자료형의 크기를 자료형 이름 안에 인코딩 하는 법을 살펴 보았다. 다음으론 리눅스 커널에서 위 자료형들의 한계를 어떻게 표현하는지 살펴 보겠다.
include/linux/kernel.h/* SPDX-License-Identifier: GPL-2.0 */ #ifndef _LINUX_KERNEL_H #define _LINUX_KERNEL_H #include <stdarg.h> #include <linux/linkage.h> #include <linux/stddef.h> #include <linux/types.h> #include <linux/compiler.h> #include <linux/bitops.h> #include <linux/log2.h> #include <linux/typecheck.h> #include <linux/printk.h> #include <linux/build_bug.h> #include <asm/byteorder.h> #include <uapi/linux/kernel.h> #define USHRT_MAX ((u16)(~0U)) #define SHRT_MAX ((s16)(USHRT_MAX>>1)) #define SHRT_MIN ((s16)(-SHRT_MAX - 1)) #define INT_MAX ((int)(~0U>>1)) #define INT_MIN (-INT_MAX - 1) #define UINT_MAX (~0U) #define LONG_MAX ((long)(~0UL>>1)) #define LONG_MIN (-LONG_MAX - 1) #define ULONG_MAX (~0UL) #define LLONG_MAX ((long long)(~0ULL>>1)) #define LLONG_MIN (-LLONG_MAX - 1) #define ULLONG_MAX (~0ULL) #define SIZE_MAX (~(size_t)0) #define PHYS_ADDR_MAX (~(phys_addr_t)0) #define U8_MAX ((u8)~0U) #define S8_MAX ((s8)(U8_MAX>>1)) #define S8_MIN ((s8)(-S8_MAX - 1)) #define U16_MAX ((u16)~0U) #define S16_MAX ((s16)(U16_MAX>>1)) #define S16_MIN ((s16)(-S16_MAX - 1)) #define U32_MAX ((u32)~0U) #define S32_MAX ((s32)(U32_MAX>>1)) #define S32_MIN ((s32)(-S32_MAX - 1)) #define U64_MAX ((u64)~0ULL) #define S64_MAX ((s64)(U64_MAX>>1)) #define S64_MIN ((s64)(-S64_MAX - 1)) #define STACK_MAGIC 0xdeadbeef // 이하 생략
보는 것과 같이 데이터 타입별 최대 최소 값을 비트 연산자를 통해 구한다. 부호없는(unsigned) 자료형은 0 에 보수를 취하여 최대값을, 부호있는(signed) 자료형은 0 의 보수를 취한 후, 오른쪽으로 1 bit 만큼 bitshift 한 값을 사용한다. 정말 재미있는 사실은 부호있는 자료형에 대해 Implementation-defined behavior 인 right bit shift 연산자의 문제를 해결하기 위해, 부호없는 자료형에 먼저 수행하고, 이후에 형변환을 한다는 것이다.
5. 취합
위에서 본 내용을 취합하여 각 자료형의 최대값과 최소값을 출력해보겠다:
type04.c 에서 포함한 type02.h 와 type03.h 는 위에서 작성한 예제이다.
data/type04.c
/** M: Yeounsu Moon <yyyynoom@gmail.com> W: https://velog.io/@mythos F: data/type04.c This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License */ #include <stdio.h> #include <stdlib.h> #include "type02.h" #include "type03.h" #define USHRT_MAX ((u16)(~0U)) #define SHRT_MAX ((s16)(USHRT_MAX>>1)) #define SHRT_MIN ((s16)(-SHRT_MAX - 1)) #define INT_MAX ((int)(~0U>>1)) #define INT_MIN (-INT_MAX - 1) #define UINT_MAX (~0U) #define LONG_MAX ((long)(~0UL>>1)) #define LONG_MIN (-LONG_MAX - 1) #define ULONG_MAX (~0UL) #define LLONG_MAX ((long long)(~0ULL>>1)) #define LLONG_MIN (-LLONG_MAX - 1) #define ULLONG_MAX (~0ULL) #define SIZE_MAX (~(size_t)0) #define PHYS_ADDR_MAX (~(phys_addr_t)0) #define U8_MAX ((u8)~0U) #define S8_MAX ((s8)(U8_MAX>>1)) #define S8_MIN ((s8)(-S8_MAX - 1)) #define U16_MAX ((u16)~0U) #define S16_MAX ((s16)(U16_MAX>>1)) #define S16_MIN ((s16)(-S16_MAX - 1)) #define U32_MAX ((u32)~0U) #define S32_MAX ((s32)(U32_MAX>>1)) #define S32_MIN ((s32)(-S32_MAX - 1)) #define U64_MAX ((u64)~0ULL) #define S64_MAX ((s64)(U64_MAX>>1)) #define S64_MIN ((s64)(-S64_MAX - 1)) #include <inttypes.h> #define STACK_MAGIC 0xdeadbeef int main(void) { printf("U8_MAX = %" PRIu8 "\n", U8_MAX); printf("S8_MAX = %" PRId8 "\n", S8_MAX); printf("S8_MIN = %" PRId8 "\n", S8_MIN); printf("U16_MAX = %" PRIu16 "\n", U16_MAX); printf("S16_MAX = %" PRId16 "\n", S16_MAX); printf("S16_MIN = %" PRId16 "\n", S16_MIN); printf("U32_MAX = %" PRIu32 "\n", U32_MAX); printf("S32_MAX = %" PRId32 "\n", S32_MAX); printf("S32_MIN = %" PRId32 "\n", S32_MIN); printf("U64_MAX = %" PRIu64 "\n", U64_MAX); printf("S64_MAX = %" PRId64 "\n", S64_MAX); printf("S64_MIN = %" PRId64 "\n", S64_MIN); return 0; }
서식 문자는 자료형에 크기에 맞는 매크로를 사용했다. 다만 이 글은 독자 여러분이 C 언어 를 어느정도 알고 있다는 것을 가정하고 작성한 글이기 때문에 자세하게 설명하진 않을 것이다. 아마 PRIu64 는 환경에 따라 long 과 long long 사이의 충돌이 발생할 수도 있는데 큰 문제는 아니다.
실행결과는 아래와 같다: 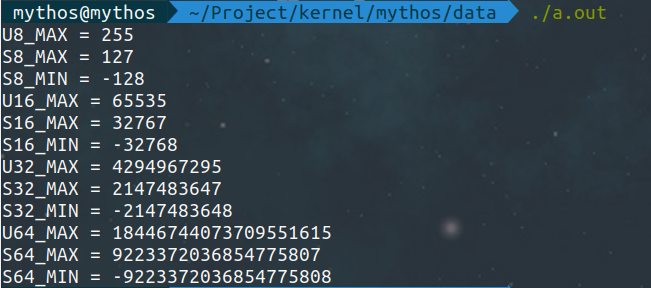
최대값과 최소값이 모두 정상적으로 출력된 것을 확인할 수 있다.
출처
[사이트] https://gcc.gnu.org/onlinedocs/gcc/Alternate-Keywords.html
[책] 리눅스 커널 소스 해설: 기초입문 (정재준 저)
