1. 커널 주소 공간
커널 주소 공간 역시 페이징을 사용(이는 가상 공간을 사용한다는 것을 의미)하고, 이를 위한 데이터를 부팅 시점에 전역 변수 swapper_pg_dir 에 저장하여 사용한다.
32 비트 가상 주소 공간
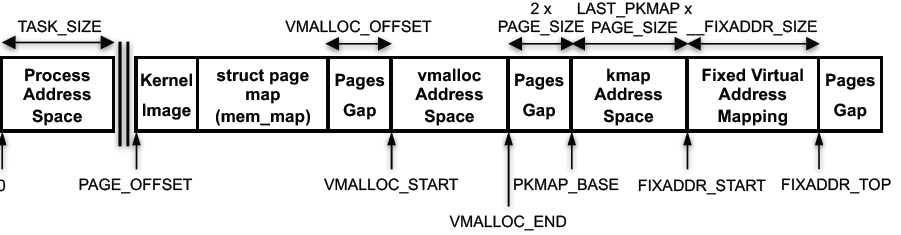
64 비트 가상 주소 공간
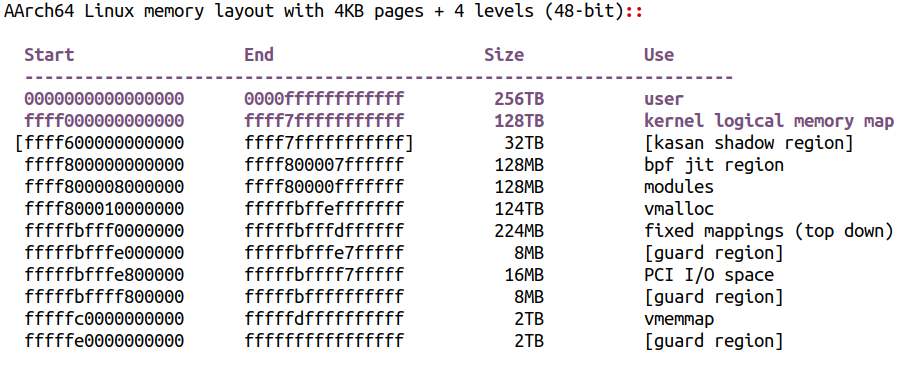
Direct Mapping 되어 있는 공간(vmalloc)은 단순히 오프셋을 더하고 빼는 연산을 통해 가상 > 물리 주소로 변환할 수 있다.
2. Slub 과 Slob
slab 할당자는 각각의 CPU와 node 에 대한 별도의 캐시를 마련한다. 따라서 시스템의 규모가 커지면 슬랩 할당자 자체의 메타 데이터가 늘어나 성능 저하로 이어질 수 있다.
Slub
slub 은 slab 과 달리 각 슬랩에 대한 별도의 메타 데이터를 유지하지 않는다. 대신 페이지 별로 할당되는 페이지 구조체의 freelist, inuse, offset 필드만을 이용하여 최대한 단순하게 관리한다.
Slob
Simple List Of Blocks 의 약자로 1 바이트조차 소중한 시스템에서 사용한다. 보통 4 바이트부터 시작하는 작은 크기의 메모리 블록을 단순 링크드 리스트로 유지하는 일종의 힙 형태의 할당자이다.
3. 파일 시스템
파일 시스템은 사용자에게 이름이라는 속성으로 접근 가능한, 추상적인 객체인 파일이라는 개념을 제공함으로써 영속적인 객체의 저장을 지원하는 소프트웨어이다.
파일 시스템은 사용자에게 제공하는 추상적 자원인 파일(File) 을 관리하기 위해 메타 데이터(Meta data) 와 사용자 데이터(User data) 를 저장한다. 메타데이터는 파일의 속성, 데이터 블록 인덱스 정보 등에 해당하고, 사용자 데이터는 사용자가 실제로 파일에 기록한 데이터를 의미한다.
4. 디스크 용어 정리 1
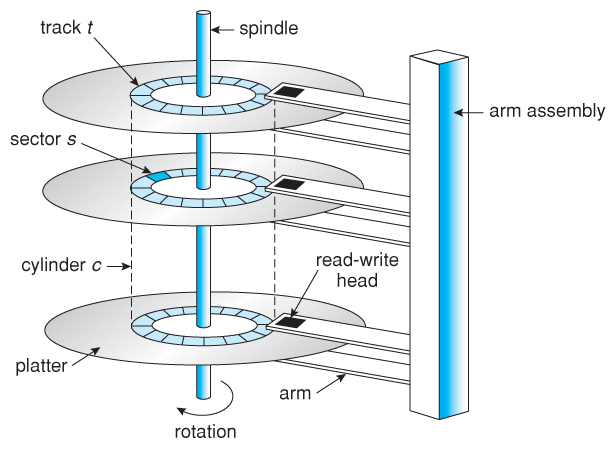
디스크는 원판(plotter), 팔(arm), 헤드(head) 로 구성된다.
원판은 같은 반지름을 가지는 트랙(track) 들이 존재하며, 모든 원판에서 같은 위치를 가지는 트랙의 집합을 실린더(cylinder) 라 한다. 트랙은 섹터(sector) 들이 모여서 완성되며, 이러한 섹터는 일반적으로 512 byte 크기를 가진다. 이는 디스크에서 데이터를 읽고 쓰는 최소 단위이다.
디스크 블록(Disk block)은 0, 1, 2 등의 논리적인 번호를 하나씩 가진다. 일반적으로 디스크 블록의 크기는 페이지 프레임의 크기와 동일한 4 KiB 이지만 속도가 느린 Disk I/O 를 줄이기 위해 블럭 크기를 더 키우기도 한다.
단, 디스크 블록의 크기는 속도의 비례하지만, 공간 효율성은 반비례하기 때문에 적절한 크기를 사용하는 것이 중요하다.
디스크 블록의 크기가 4 KiB 이고, 섹터의 크기가 512 byte 라면 하나의 디스크 블록을 구성하기 위해 8개의 섹터(512 * 8 byte = 4 KiB)를 읽어야 한다. 디스크 블록과 섹터를 매핑하는 일은 디스크 디바이스 드라이버 또는 디스크 컨트롤러가 담당한다.
5. 디스크 블록 할당
디스크 볼록 할당 방법은 연속 할당(sequential) 과 불연속 할당(non-sequential) 으로 나뉜다.
연속할당
연속 할당은 하나의 파일에 연속된 디스크 블럭(ex. 3,4,5,6) 을 할당하는 방법이다. 이 방법의 특징은 읽는 속도는 빠르지만(그냥 순차적으로 읽으면 되므로), 파일의 크기가 커졌을 때 연속적으로 할당할 수 없다면(6 > 9 로 커져야 하는데 8, 9 가 사용 중), 해당 디스크 블럭을 연속적으로 사용 가능한 공간으로 모조리 옳겨야 한다.
불연속 할당
불연속 할당은 순차적으로 할당하지 않고 free 된 임의의 디스크 블록들을 통해 파일을 저장한다. 따라서 파일에 속한 디스크 블럭들이 어디에 위치하는지 기록해야 한다.
6. 디스크 블록 할당 기법
블록 체인 기법
블록체인 기법은 같은 파일에 속한 디스크 블록들을 체인(블록에 포인터를 두어 다음 블록의 위치를 기록)으로 연결하는 방법이다. 연속 할당에 비해 확장성은 좋지만 lseek(SEEK_END) 와 같은 시스템 콜이 호출되면 앞부분부터 끝까지 읽어야 한다는 단점이 있다.
인덱스 블록 기법
인덱스 블록 기법은 파일에 속한 디스크 블록의 논리적 번호를 배열의 형태로 디스크 블럭에 저장하는 기법이다. 파일의 시작과 끝 탐색은 블록 체인 기법에 비해 빠르지만, 인덱스 블록을 위한 별도의 공간이 필요하며, 인덱스 블록이 가득찼을 때 이를 해결하기 위한 방법 또한 고안해야 한다.
7. FAT (File Allocation Table)
FAT (File Allocation Table) 기법은 인덱스 블럭 기법과 달리, 하나의 전역적인 FAT 자료구조를 통해 파일 시스템 전체를 관리한다.
FAT 구조의 유실은 곧 파일 시스템 내의 모든 파일의 소실을 의미하므로, FAT 의 내용을 중복하여 관리한다.
FAT 파일 시스템
파일 시스템이 관리하는 데이터는 메타 데이터와 유저 데이터로 구분할 수 있다. FAT 시스템에서 메타 데이터는 다시 FAT 테이블(FAT Table), 디렉터리 엔트리(Directory Entry), 그리고 슈퍼 블록(Super block)으로 구성된다.
struct msdos_dir_entry {
__u8 name[MSDOS_NAME];/* name and extension */
__u8 attr; /* attribute bits */
__u8 lcase; /* Case for base and extension */
__u8 ctime_cs; /* Creation time, centiseconds (0-199) */
__le16 ctime; /* Creation time */
__le16 cdate; /* Creation date */
__le16 adate; /* Last access date */
__le16 starthi; /* High 16 bits of cluster in FAT32 */
__le16 time,date,start;/* time, date and first cluster */
__le32 size; /* file size (in bytes) */
}; MSDOS 의 FAT 파일 시스템은 각 파일마다 디렉터리 엔트리를 하나씩 가진다. 디렉터리 엔트리가 모여서 다시 디렉터리를 구성한다. 결국 디렉터리 역시 자신이 포함하는 파일의 이름들을 데이터로 가지고 있는 특수한 파일에 불과하다. 리눅스는 디렉터리와 파일 구분없이 모두 파일로 관리한다.
MSDOS 파일 시스템의 디렉터리 엔트는 파일 이름과 확장자를 담는 name, 파일의 속성과 시간 정보, 파일 크기를 담는 size FAT 구조를 이용해 인덱싱하기 위한 테이블 블록 중 첫 블록의 번호를 담아둔 start 변수 등이 존재한다.
8. 파일 탐색
리눅스는 사용자 태스크의 현재 작업 디렉터리(CWD, Current Working Directory) 를 항상 task_struct 구조체에 유지하고 있기 때문에 쉽께 상대 > 절대 경로로 변환할 수 있다.
따라서 /home/mythos/schedule/7.27.txt 라는 파일을 요청하면 / 디렉터리 엔트리를 읽어 데이터 블록에서 home 을 찾고, 반복적으로 따라 내려가서, 마침내 7.27.txt 파일을 가져온다.
슈퍼 블록
디렉터리의 시작인 / 의 디렉터리 엔트리와 경로 + 파일만 알고 있다면 어떠한 파일이든 가져올 수 있다. 이를 위해 파일 시스템은 최상위 디렉터리의 위치를 파일 시스템이 관리하는 공간 맨 앞에 가져다 놓는다. 이를 슈퍼 블록(super block) 이라 한다.
9. 아이노드 (inode)
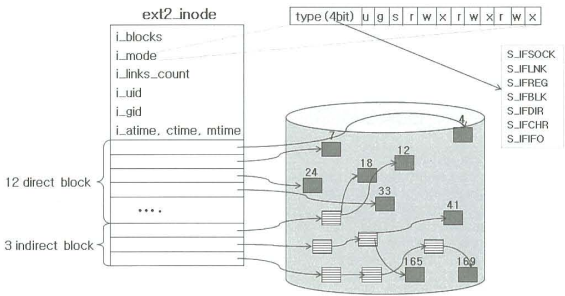
리눅스의 디폴트 파일 시스템은 ext4 이며, 이러한 구조를 inode 구조라 한다.
-
i_block: 파일이 가지고 있는 데이터 블럭의 개수 -
i_mode:inode가 관리하는 파일의 속성 -
i_links_count:inode를 가리키고 있는 파일의 수 -
i_uid,i_gid: 파일을 생성한 소유자 ID, 그룹 ID -
i_atime, ctime, mtime: 각각 접근, 생성, 수정 시간 -
i_mode: 상위 4비트 (파일 유형)
-u: 파일 수행 시 태스크의 소유자가 아닌, 파일을 생성한 생성한 사용자 권한으로 동작
-g: 그룹 아이디
-s: 메모리에서 쫓겨나면swap으로 가도록
-rwxrwxrwx: 이하 동문 -
i_block[15]:
- 12 개:직접 블록(direct block)
- 3 개:간접 블록(indirect block)
직접 블록
실제 파일의 내용을 가지는 디스크의 데이터 블록을 가르키는 포인터
간접 블록
인덱스 블록(디스크 블록을 가르키는 포인터를 갖는 블록)을 가르키는 포인터.
3개의 간접 블록은 단일, 이중, 삼중 간접 블럭으로 부르며 단일은 인덱스 블록을 직접 가르키고, 이중은 2 단계의 인덱스 블록으로, 삼중은 3 단계의 인덱스 블록을 가르킨다.
구조적 한계로 ext2 는 파일 하나가 4 GiB 를 넘길 수 없다. 이러한 제약을 해결하고 안정성을 높인 것이 ext4 이다.
10. 디스크 용어 정리 2
IDE
IDE (Integrated Drive Electronics)
가장 오래된 전송 규격으로 PATA(Parallel Advanced Technology Attachment) 인터페이스라고도 부름. 병렬 포트로 전송속도 확보, 133 MiB/s
SATA
SATA (Serial Advanced Technology Attachment)
병렬이 아닌 직렬 포트를 사용(완벽하게 직렬은 아니고 IDE 비해 포트 수가 좀 줄어듬)한다. 하드 디라이브의 속도와 연결 방식 개선을 위해 개발했다.
SATA 1 : 150 MiB/s
SATA 2 : 300 MiB/s
SCSI
SCSI (Small Computer System Interface) 스커지
서버와 워크 스테이션에서 사용하는 고속 인터페이스 320 MiB/s 높은 안정성과 비싼 가격
SAS
SAS (Serial Attached SCSI)
한단계 더 발전된 SCSI 규격. 성능은 320 SCSI 보다 좋음.
11. Ext2 파일 시스템
IDE 방식의 디스크가 장착되면 /dev/hd~ 라는 이름으로 시작. 두 개 이상의 디스크는 hda, hdb 와 같은 이름이 붙는다.
디스크는 사용자가 원하는 개수 만큼의 논리적 영역(partition)으로 분할될 수 있다. 디스크 A 의 파티션이 3 개로 분리되면 /dev/hda1, /dev/hda2, /dev/hda3 와 같은 이름을 가지게 된다.
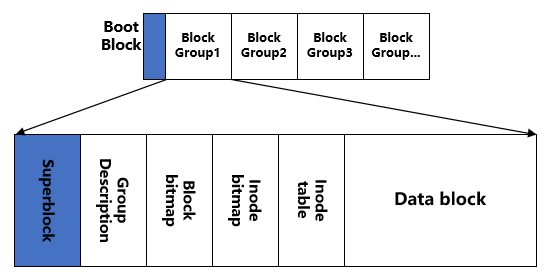
ext2 파일 시스템을 구축하면 부트스트랩 코드가 존재하는 부트블록 (boot block)과 여러 개의 블록 그룹 (block group) 으로 구성된다. 블록 그룹을 다시 슈퍼 블록 (super block) 과 블록 그룹 디스크립터 (block group descriptor), 디스크 블록을 위한 데이터 블록 비트맵 (data block bitmap), 아이노드 비트맵(inode bitmap) 과 테이블 (inode table) 등으로 구분된다.
inode 테이블 의 크기는 파일 시스템 구축 시 정해진다. inode 테이블의 빈 공간은 inode 비트맵 이, 데이터 블록의 빈 공간은 데이터 블록 비트맵 이 관리한다. 이 비트맵들은 모두 한 블럭 내에 존재해야 한다.
따라서 한 블럭 그룹은 최대 4096 x 8 개의 블럭을 가질 수 있다. inode 구조체의 크기는 128 byte 이므로 한 블록 내에 4096 / 128 개의 inode 가 존재할 수 있다.
슈퍼 블록과 그룹 디스크립터는 소실되면 안되는 매우 중요한 정보이기 때문에 각 블록 그룹마다 중복하여 기록한다. 따라서 한 그룹에 있는 슈퍼 블록이나 그룹 디스크립터의 내용 전체 또는 일부가 유실되어도 복구가 가능하다.
12. Ext3 파일 시스템
Ext3 의 설계 철학: 특정 파일로 인해 야기되는 문제가 파일 시스템 전체에 주는 영향을 없애고, 해당 파일로 국한 시킨다.
- 빠른 디렉터리 탐색을 위한
해쉬 (hash)기반HTree기술이 도입되었다. 기존ext2는 디렉터리를 단순 연결 리스트로 관리하였는데,ext3에서는HTree구조를 도입해 한 디렉터리 내의 많은 파일이 존재하더라도 빠르게 탐색할 수 있도록 하였다. 저널링(journaling)기법을 도입했다.ext3은 불시의 전원이 나가는 경우와 같은 결함을 허용(fault tolerant) 한다.ext3에서는 아래의 세 가지 저널링 모드를 지원한다.Journal: 파일 시스템에 데이터 기록 전에 모든 데이터를 저널에 기록한다. 속도는 떨어지지만 높은 안전성을 제공한다.Ordered: 메타 데이터만을 저널링한다. 메타 데이터는 쓰기 순서가 보장된다.Write-back:Ordered와 유사하나 쓰기 순서는 보장되지 않는다.
- 시스템 가용시간 향상
LVM (Logical Volume Manager)를 도입하여 파일 시스템이 관리하고 있는 용량을 동적으로 늘릴 수 있는 기법을 도입했다.
13. Ext4 파일 시스템
지연 할당 (Delayed Allocation)기법과선할당(Pre-allocation)기법 도입.
파일 생성 시 미리 할당해둔 물리적으로 연속적인 공간을 반환하여 성능 향상을 도모한다. 지연 할당은 블록 카운트만 갱신하고 실제 할당은 뒤로 미뤄 단편화를 방지한다.extent기반 데이터 블록 유지
50 개의 블록 할당 시 직접 블록과 간접 블록을 통해 50 개의 블럭을inode가 가르켜야 했다.extent기법은 데이터 블럭이 선형적일 때 단순히 데이터 블럭의 시작 위치와 크기, 두 가지 데이터만을 가지고 표현(412,50시작 블럭412, 크기 +50, ~462)하여 메타 데이터의 양과 인덱싱 시간을 줄인다.- 기타 등등.
- 저널링 성능 향상을 위한
저널링 체크섬 (Journaling checksum) - 대용량 파일 시스템과 큰 크기의 파일 지원
- 온라인 단편화 제거 지원
- 저널링 성능 향상을 위한
+ 추가
NAND Flash Memory 인 SSD 는 특정 셀만 사용하면 수명이 빨리 줄어드는 문제가 있는데 이를 해결하기 위한 파일 시스템이 있는가? YES
그러나 요즈음엔 UFS 를 통해 일반 파일 시스템을 바로 사용해도 큰 문제가 없다. 알아서 관리해준다.
최근 파일 시스템의 방향성은? BTRFS > Versioning File System 이 인기
출처
[책] 리눅스 커널 내부구조 (백승제, 최종무 저)
[이미지] https://unix.stackexchange.com/questions/412100/kernel-address-space-and-kernel-page-table
[이미지] https://www.programmersought.com/article/12718230025/
[이미지] https://revisezone.com/Html/Cs/Hardware
[사이트] https://coolfam.de/linux/2020/12/28/linux-file-system.html
[사이트] https://blog.naver.com/PostView.nhn?isHttpsRedirect=true&blogId=skyluvtoya&logNo=100120822628
[이미지] https://www.programmersought.com/article/26331723168/
