[RxSwift] Hashable에 관하여
시작하기
DiffableDataSource를 공부하면서 identifier의 타입이 Hashable해야 한다는 말을 많이 들어봤을 것이다.
그래서 Hashable이 뭘까?
DiffableDataSource
기존의 DataSource는 section과 item의 indexPath를 들고 있어서 만약 데이터가 수정, 삭제된다면 indexPath도 변경될 수 있기 때문에 불안정한 정보를 가진다.
특정 indexPath에 반드시 해당 값이 존재한다고 확실할수가 없기 때문에 reloadData()를 할 때, 어떤 데이터가 변했는지 datasource에서 파악할 수가 없어서 모든 데이터를 다시 로딩하여 컬렉션뷰를 업데이트 한다.
이런 한계를 극복하기 위해 DiffableDataSource가 나왔는데, DataSource와 비교해서 DiffableDataSource가 안정적인 이유는 뭘까?
결론부터 말하면 identifier덕분이다.
구체적으로 변경된 item이 무엇인지 파악하는 방법은
현재 상태를 나타내는 스냅샷과 이전 상태를 나타내는 스냅샷을 비교해서 달라진 item을 파악하는것.
이때 비교는 identifier로 하게 된다.
변하지 않는 identifier덕분인데, 그러면 어떻게 변하지 않는 identifier를 만들 수 있을까?
Hashable
타입이 Hashable 하다는것 = 값이 해시함수에 들어가서 정수 해시값으로 변경될 수 있다는 것을 의미한다.
변환된 해시 값은 해시 테이블의 key로 사용될 수 있다.
해시테이블은 딕셔너리처럼 key값을 index로 사용해서 value를 저장한다.
key만 가지고 있으면, 쉽게 해시 테이블에서 저장된 value를 꺼내올 수 있다.
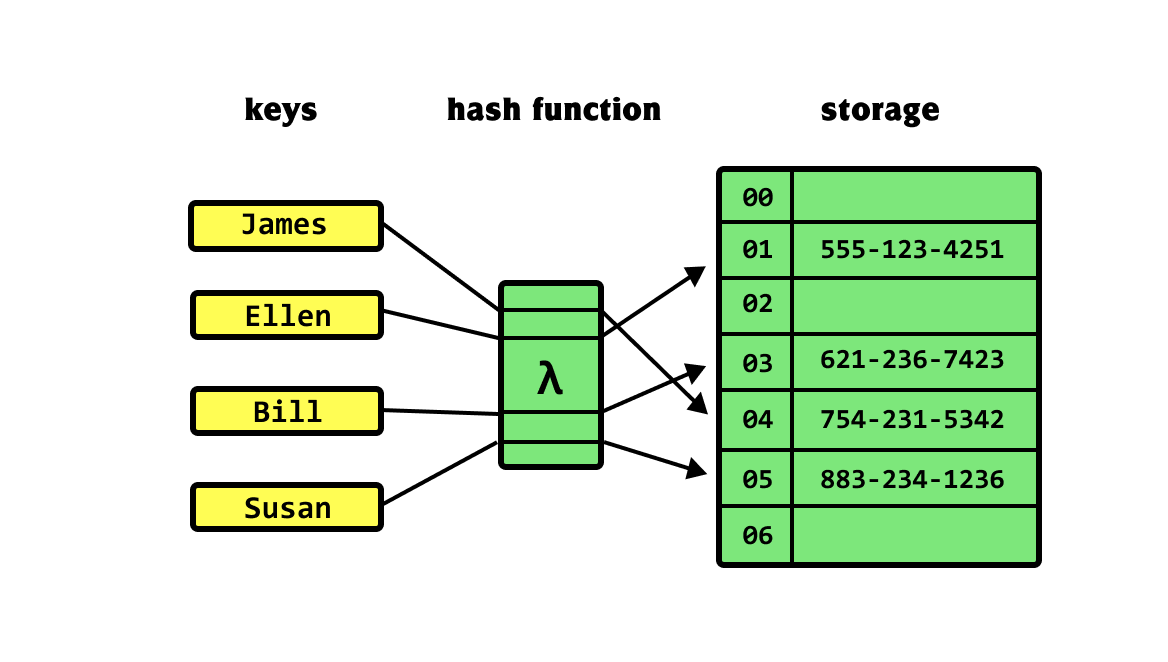
해시테이블은 딕셔너리나 Set처럼 순서가 없지만, 내부적으로는 배열로 구현되어 있어서 index가 있다.
순서가 없다면서 무슨 index가 나오지? 할 수 있지만
해시함수가 있어서 가능한 일이다.
그림의 예시를 보면 James라는 키가 해시함수에 들어가면 04라는 해시값(index)로 변환되는 모습을 볼 수 있다.
해시함수가 키를 해시 주소값(index)로 변환해주어서 해시 테이블 내부적으로 인덱스가 존재할 수 있었던 것이다.
다시 정리하자면, 해시 함수를 이용해 key를 해시 주소값(해시 테이블의 index)으로 바꾸고,
해시 주소값(해시 테이블의 index)를 통해 해시 테이블에 접근하여 값을 가져오거나 저장하는 형태이다.
해시의 장점
해시테이블은 key-value가 1:1로 매핑되어 있기 때문에 삽입, 삭제, 검색의 과정에서 모두 평균적으로O(1)의 시간복잡도를 가지고 있다.
해시의 단점
해시 충돌이 발생(개방 주소법, 체이닝 과 같은 기법으로 해결해 줘야 한다.)
그러면 여기서 드는 의문은 Hashable은 왜 Equatable을 상속받을까?
Equatable을 채택해야 하는 이유
Equatable 프로토콜을 채택하면 두 객체가 서로 같은 값을 가졌는지 비교할 수 있기 때문이다.
Hashable은 Equatable을 상속받고 있는데, 그 이유는 hashvalue가 항상 unique하지 않기 때문이다.
hashValue가 같아서 해시 충돌이 날 수 있기 때문에, Equatable이 필요한 것이다.
- hashValue로는 사용자가 찾는 객체에 접근하고
- Equatable의 구현사항인 == 함수로 hashValue가 고유값인지 식별한다
자동으로 Hashable한 타입은 뭐가 있지
스위프트 스탠다드 라이브러리 중 거의 다 이미 Hashable을 채택하고 있음
따라서,, 따로 우리가 채택해주지 않아도 값을 비교할 때 ==를 사용할 수 있다.
String, Integer, Float, Bool, Double
커스텀 타입을 만약 Hashable을 채택하도록 하려면
-
모든 저장 프로퍼티가 Hashable한 Int타입인 경우 Hashable만 채택하면 hash(into:) 구현하지 않아도 자동으로 생김
-
그 외의 경우에는 두가지를 구현해줘야 하는데
-
== 함수← Equatable 프로토콜을 따라야해서 -
hash(into:)함수 ← Hashable 프로토콜을 따라야해서
