Review
FIFO algorithm
- convoy effect(tractor가 길을 다 막는다) -> low CPU 와 device utilization
SJF(Shortest Job First) scheduling algorithm
- 평균 turnaround time(terminate-arrival)을 줄인다.
- 평균 waiting time(start-arrival)을 줄인다.
- job length를 미리 알 수 있는가? 항상 좋은가?
RR scheduling algorithm
- response time 줄인다.(각 프로세스마다 정해진 타임 퀀텀 동안 번갈아가며 CPU 할당)
- turnaround time을 줄이지는 못한다.
Need a new algorithm for
- optimize turnaround time -> run shortest job first
- minimize response time -> use Round Robin to 가능한 많은 job 실행 (반응성=first run - arrival)
- Learn from the past to predict the future without prior knowledge of job length
8. Scheduling: Multi-Level Feedback Queue(MLFQ)
8.1 Basic Rules
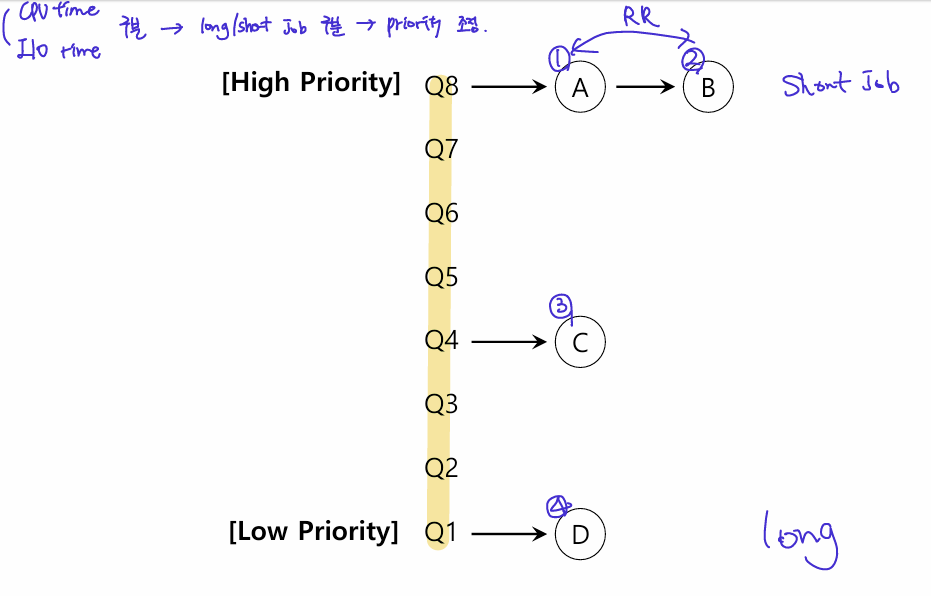
- 다른 priority level들로 구성된 queues들을 가진다.
- 하나의 job은 하나의 queue에서 실행된다.
Rule 1: 다른 큐끼리) higher queue에 있는 job이 우선적으로 실행된다.
Rule 2: 같은 큐끼리) Round Robin 스케쥴링을 사용하여 실행한다.(정해진 타임 퀀텀 끝나면 다른 job)
- 작업의 관찰된 행동에 따라 우선순위를 조정합니다.
- 작업이 반복적으로 CPU를 포기하고 입출력(I/O)을 기다리면, 우선순위를 높게 유지해.
- 반면, 작업이 오랜 시간 동안 CPU를 집중적으로 사용하면, 그 작업의 우선순위를 낮춘다.
8.2 How to Change Priority
Rule 3: 처음에 system에 job이 들어올 때, 가장 높은 priority queue에 위치한다.
Rule 4a: 실행중에 모든 time slice를 사용하면, 해당 job이 priority는 감소한다.
Rule 4b: 모든 time slice을 사용하기 전에 job이 CPU를 놓으면, 계속 해당 priority level을 유지한다.
--> 이러한 방식으로 Shortest Job First에 근사한다.
왜냐하면, 4a: CPU을 집중적으로 사용하는, 오래 걸리는 job이므로 우선순위를 낮추어 나중에 실행하게 한다.
4b: CPU를 조금 쓰고 스스로 놓는 경우, short job이므로 높은 우선순위 유지
-> turnaround time 평균 줄이기, fairness 추가(?)
 -> 낮은 우선순위 계속 실행 못할 수도 있으므로 priority boost 추후 사용
-> 낮은 우선순위 계속 실행 못할 수도 있으므로 priority boost 추후 사용
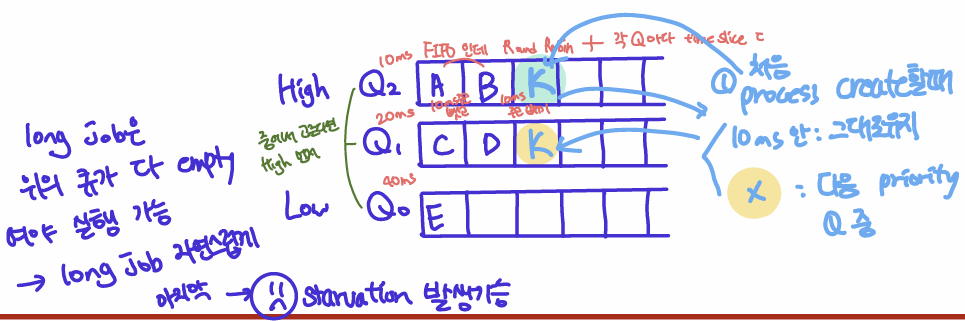
Example 1: 한개의 긴 실행시간 가진 작업
 처음 시스템에 들어올 때 가장 높은 우선순위 큐에 위치하지만, 10ms 안에 CPU를 놓지 않으므로 계속해서 더 낮은 priority 큐로 강등된다.
처음 시스템에 들어올 때 가장 높은 우선순위 큐에 위치하지만, 10ms 안에 CPU를 놓지 않으므로 계속해서 더 낮은 priority 큐로 강등된다.
Example 2: 짧은 작업과 함께  가장 먼저 시스템에 들어온 A는 가장 priority 높은 Q2에서 시작하지만, 앞선 예시와 같은 이유로 강등된다. 그후 B가 들어오고 B도 20ms 동안 실행하므로 강등된다. 그렇지만 A보다는 높아서 먼저 실행된다.
가장 먼저 시스템에 들어온 A는 가장 priority 높은 Q2에서 시작하지만, 앞선 예시와 같은 이유로 강등된다. 그후 B가 들어오고 B도 20ms 동안 실행하므로 강등된다. 그렇지만 A보다는 높아서 먼저 실행된다.
Example 2: 입출력 작업 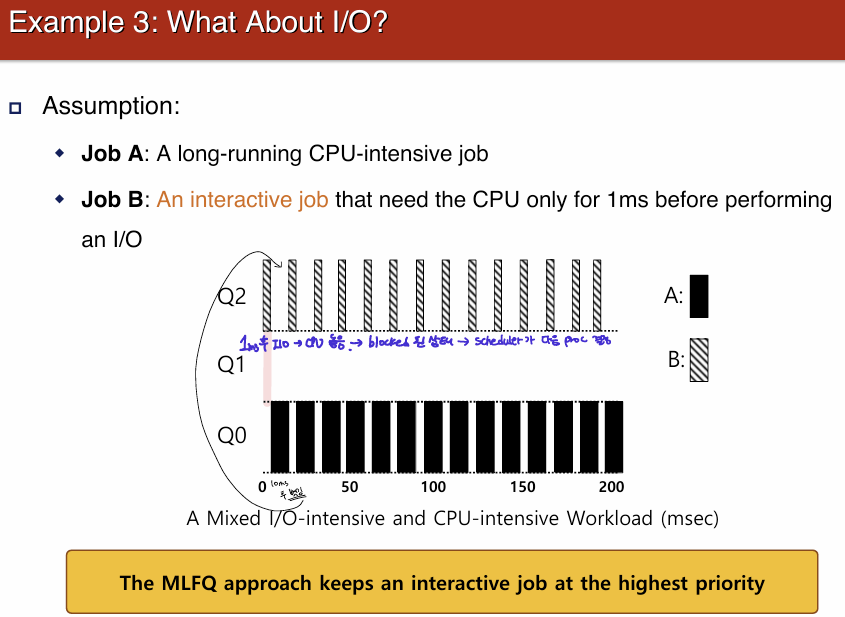 B는 CPU를 매우 짧게 사용하여, 10ms안에 스스로 놓기 때문에 강등되지 않고 I/O 작업을 수행한다. 그리고 CPU는 B의 I/O 작업이 끝나고 나서 (B가 ready queue로 들어가므로) 다시 또 짧은 job인 B가 실행 될 수 있도록 한다.
B는 CPU를 매우 짧게 사용하여, 10ms안에 스스로 놓기 때문에 강등되지 않고 I/O 작업을 수행한다. 그리고 CPU는 B의 I/O 작업이 끝나고 나서 (B가 ready queue로 들어가므로) 다시 또 짧은 job인 B가 실행 될 수 있도록 한다.
-> 세 경우 모두 작업이 짧은 작언인지 긴 작업인지 알 수 없어도 먼저 짧다고 가정 후 우선순위를 조정하며 SJF 에 근사한다.
Problems with the Basic MLFQ
1) Starvation
- interactive(대화형) jobs들이 많으면, 계속 해당 job들만 실행되므로, long running job들이 CPU를 할당 받지 못한다.
2) Game the scheduler
- 만약, time slice의 99%만 사용하고, I/O operation 을 수행하는 job이 있다고 가정하자. 이 job은 time slice를 다 사용하기 거의 직전에 스스로 CPU를 놓으므로 계속 높은 priority을 유지한다. 그렇지만 계속해서 CPU를 거의 다 사용하여 독점현상이 발생한다.
3) A program may change its behavior over time
- CPU bound process였다가 I/O bound process로 바뀔 수도 있다. 이때 다시 우선순위가 높아지는 mechanism이 필요하다.
P2-Solution: Better Accounting
Rule 4: 한 작업이 주어진 레벨(우선순위 큐)에서 할당된 시간(time allotment)을 모두 사용하면, (몇 번이나 CPU를 포기했는지에 상관없이), 그 작업의 우선순위가 낮아진다(즉, 큐에서 아래로 이동한다). 입출력 중점 대화형 작업을 빨리 실행시킨다.
이 규칙은 작업이 특정 우선순위 큐에서 CPU 시간(time allotment)을 다 소모하면, 더 낮은 우선순위로 이동하게 된다.
P1,P3-Solution: The Priority Boost
Rule 5: some time period S 이후엔, 모든 job들을 가장 높은 우선순위 큐로 옮긴다.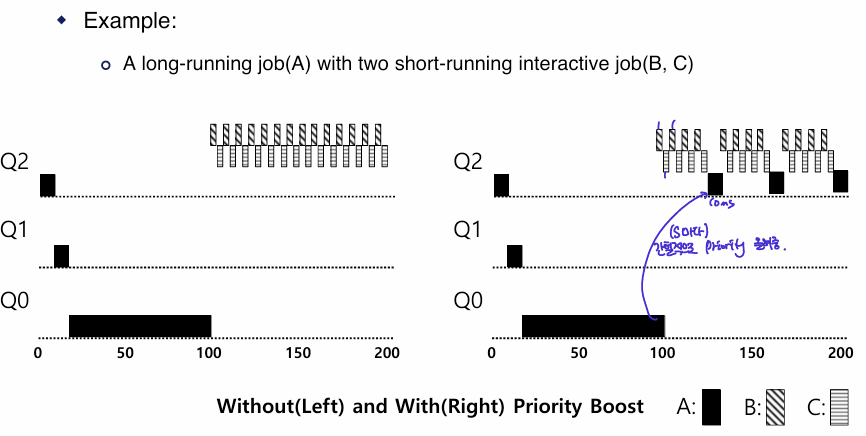
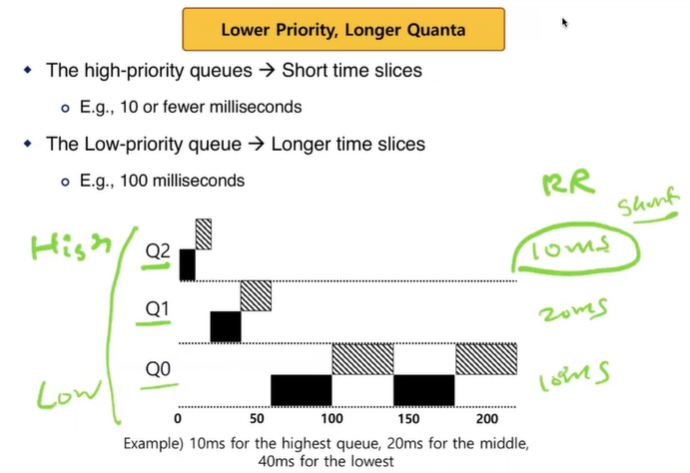
Tuning MLFQ And Other Issues
-> Lower Priority, Longer Quanta
- 우선순위가 높은 큐 -> short time slice
- 우선순위가 낮은 큐 -> long time slice
The Solaris MLFQ Implementation
- 60개 queue를 가진다.
- 낮은 우선순위 : 수백 milliseconds
- 높은 우선순위 : 20msec(빨리 빨리 response time 반응성)
- 1s 마다 우선순위 boost!
--> 프로세스의 CPU 사용에 대한 이전 지식이 필요하지 않는다.
