앞선 스케쥴링과 다른 'fairness' 관점에서 생각해보자
9. Fair share scheduler
- CPU time의 일정 비율대로 각 job이 할당 받는 것이 보장됨.
- = Proportional Share(비례배분!)
- turnaround time 과 response time은 optimized 되지 않음
- ex ) Lottery scheduling / Stride scheduling / Completely Fair schedulig(Nice,vruntime, timeslice, red-black tree)
9.1 Lottery scheduling
Basic Concept-추첨권이 당신의 지분이다.
Tickets: 하나의 process가 받는 resource의 비율 단위
- tickets의 비율이 시스템 리소스의 할당 비율
- process가 가진 티켓 수에 따라 해당 자원을 나눠가짐.
- ex) 프로세스 A가 75개의 티켓을 가지고 있으면, CPU 시간의 75%
- 프로세스 B가 25개의 티켓을 가지고 있으면, CPU 시간의 25%를 차지하도록 목표한다.
방법 초 간단.
- 스케줄러는 winnig ticket을 뽑는다.(난수)
- 해당 process를 로드하고, run 한다.
Example
- 해당 job들이 더 길게 경쟁할 수록, 그들이 기대하던 percentage와 가까워진다. 만약에 job들의 실행수가 적으면, 비율대로 실행이 안될 수도 있다.
- 무작위성을 기반으로 하므로, 원하는 비율을 정확히 보장하지느 않는다. 장시간 실행하면 원하는 비율 달성 가능성 높아진다.
- 처음엔 랜덤한 결과로 보이지만, 시간이 지날수록 각 프로세스가 받은 티켓 수에 비례하여 자원을 사용하는 비율이 점차 목표 비율(75% vs 25%)에 가까워짐.
- turnaround, response time 최적화 x
- short ,long job 고려 x
9.2 Ticket Mechanisms
1) Ticket Currency(티켓 통화)
: 사용자가 각 프로세스나 작업에 자신만의 방식으로 티켓을 할당하고, 시스템이 이를 전역 티켓 수(Global currency)로 변환하는 방식
- A1: 100 * (500/1000)
- A2: 100 * (500/1000)
- B1: 100 * (10/10)
2) Ticket transfer(티켓 양도)
: 자기가 당장 자원이 필요하지 않으면, 일시적으로 다른 프로세스에게 티켓 나눠주기
- ex) client가 server에게 ticket transefer(나중에 환수)
3) Ticket Inflation(티켓 인플레이션)
: 자기 소유 티켓의 수를 임시적으로 증가시키거나 감소시키기
- 만약 특정 프로세스가 더 많은 CPU 시간을 필요하면, 티켓수를 스스로 일시적으로 증가 시킨다.
9.3 Implementation 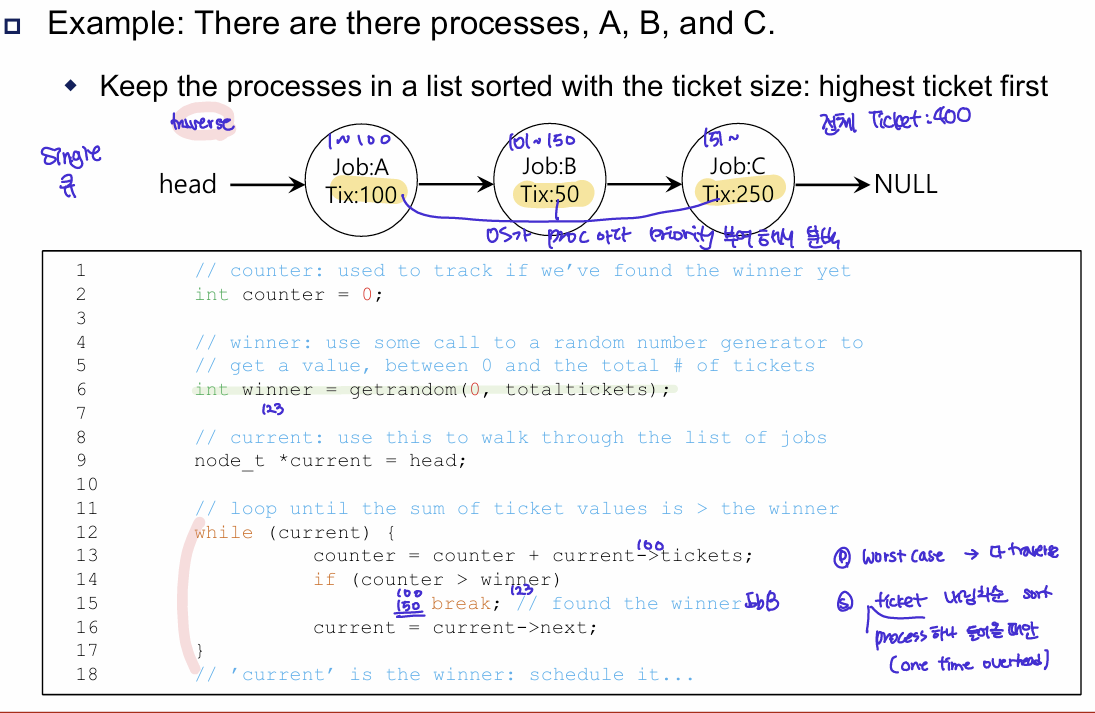
- 프로세스 및 티켓:
- Job A는 100개의 티켓
- Job B는 50개의 티켓
- Job C는 250개의 티켓
- 총 티켓 수는 400개야 (100 + 50 + 250).
- 목록 순서: 프로세스는 티켓 수에 따라 연결 리스트로 관리됨.
- 코드 설명:
- 랜덤 티켓 추출 (getrandom 함수): getrandom(0, totaltickets)에서 0과 총 티켓 수(400) 사이에서 무작위로 티켓 번호가 선택됨. 예를 들어, 150번 티켓이 선택될 수 있어.
- 반복문 (while 루프): 선택된 티켓 번호에 해당하는 프로세스를 찾기 위해 리스트를 순차적으로 탐색함.
- counter는 현재까지 확인한 티켓 수를 누적.
- 현재 프로세스의 티켓 수를 counter에 더하고, counter가 winner 값(랜덤으로 선택된 티켓 번호)을 초과하면 그 프로세스가 선택됨.
- 예를 들어, winner가 123이라면 Job A와 Job B를 합쳐 150(즉, Job B가 포함된 시점) Job B가 선택됨.
- 주의: 최악의 경우 리스트 끝까지 탐색해야 하는 상황이 있을 수 있음. Job C가 선택되려면 끝까지 가야 함.
-> 정렬: 티켓 수에 따라 미리 프로세스가 내림차순 정렬하기(이 작업은 한 번만 처리되는 오버헤드임)
9.4 Lottery Fairness Study
U: unfairness metric = (first job completed 시간) / (second job completed 시간)
- 실행시간(run time): A : 10, B : 10
- 끝난시간(finish time): A : 10, B : 20
- U = 1.0 / 2.0 = 0.5
- U가 1에 가까울 수록 fair하다.(거의 동시에 끝난다)
Lottery scheduler 문제: Fairness Problem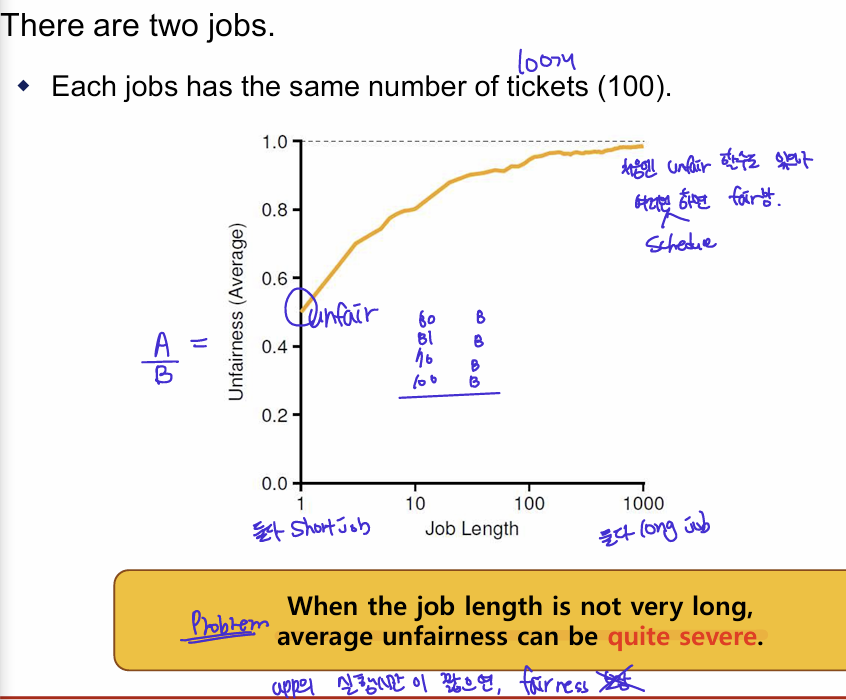
- 각 job들이 모두 같은 티켓 가지고 있는 예시이다.
- job length가 짧은 처음에는 unfair 할 수 있으나, 길어질수록 fair함.
작업 길이가 그리 길지 않을 때, 평균 불공정성(average unfairness)이 상당히 심각할 수 있다.
9.5 Solution: Deterministic Approach: Stride Scheduling
: 무작위성을 이용하면 단순하게는 가능하지만 정확한 비율 보장을 못하므로 결정론적으로!!
: 우선순위가 높으면 -> 티켓 많음 -> 보폭 적음 -> 조금씩 진행 되므로, 강강약약인 OS는 기회를 더 줌.
: pass value(+=stride)가 가장 적은 process를 schedule시킨다.
Stride of each process
- (large number) / (the number of tickets of the process)
- 자신이 가지고 있는 추첨권 수에 반비례
- Example: large number = 10,000
- Process A has 100 tickets -> stride of A is 100
- Process B has 50 tickets -> stride of B is 200
Counter(=passvalue)
: 각 process마다 0에서 시작하여 run할때마다, 각 프로세스의 stride를 더한다.
: 얼마나 CPU를 사용하였는지 추적 용도
Stride Scheduling Example(imp) 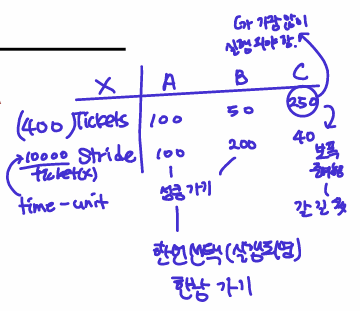
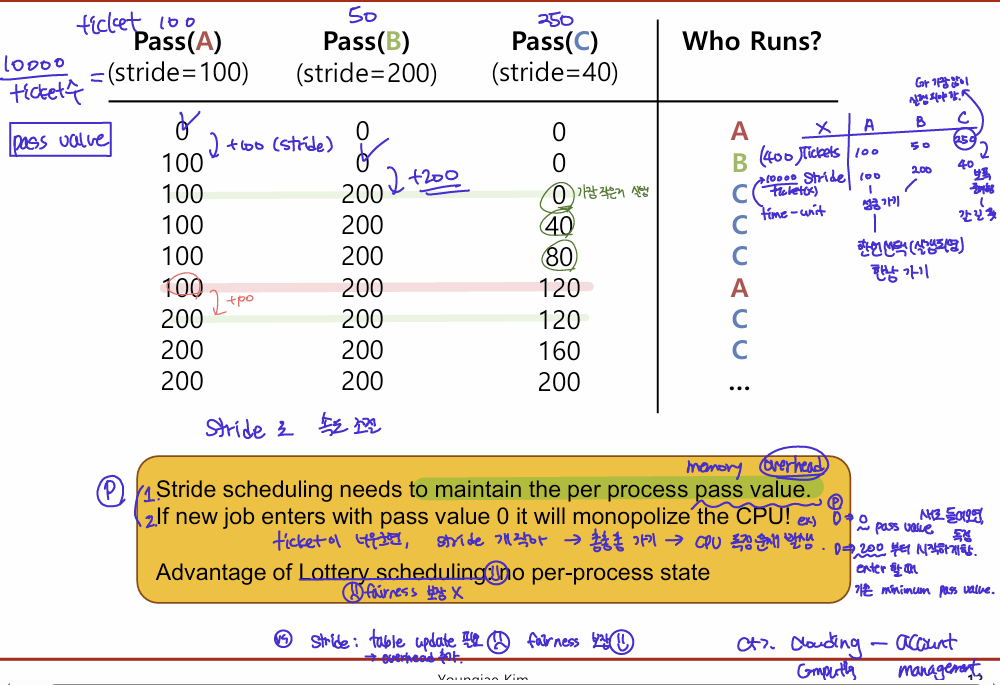
Problem1: 각 process마다 pass value를 유지해야한다.
Problem2: 새로운 job이 pass value 0으로 새로 들어오면, 기존 다른 어떤 process 보다 pass value가 작으므로, CPU를 독점할 것이다.
Stride Scheduling vs Lottery Scheduling
- stride scheduling: fairness 보장(짧은 길이의 job이더라도)
- lottery scheduling: no per process-state (overhead x)
9.7 The Linux Completely Fair Scheduling(CFS)
- non-fixed timeslice
- CPU의 사용 비율로 할당
- priority - nice value 사용
- 덜 nice 할수록, 우선순위 높아지게 weight 크다.
- 더 nice 일수록, 우선순위 낮아지게 weight 작다.
- efficient data structure
- use red-black tree(효율적인 검색, 삽입, 삭제)
1) (basic) Virtual runtime(vruntime)
- 프로세스가 실제로 실행된 시간(프로세스마다 별도 관리)
- vruntime이 가장 낮은 프로세스를 스케쥴러가 선택한다.
- CPU 자원의 공정한 배분을 도와준다.
- process가 얼마만큼 CPU 썼는지 추적한다.
2) Sched_latency(지연시간)
- 스케줄러가 프로세스에게 CPU를 할당하기 위한 기본적인 지연 시간을 의미해. 일반적으로 이 값은 48밀리세컨드(millisecond)로 설정
- 공정하게 CPU 자원을 할당받을 수 있도록 타임슬라이스가 결정되며, 프로세스 수가 많아질수록 각 프로세스가 받을 수 있는 CPU 시간은 줄어듦
3) (basic) Time Slice = sched_latency / (실행 중인 프로세스의 수)
Example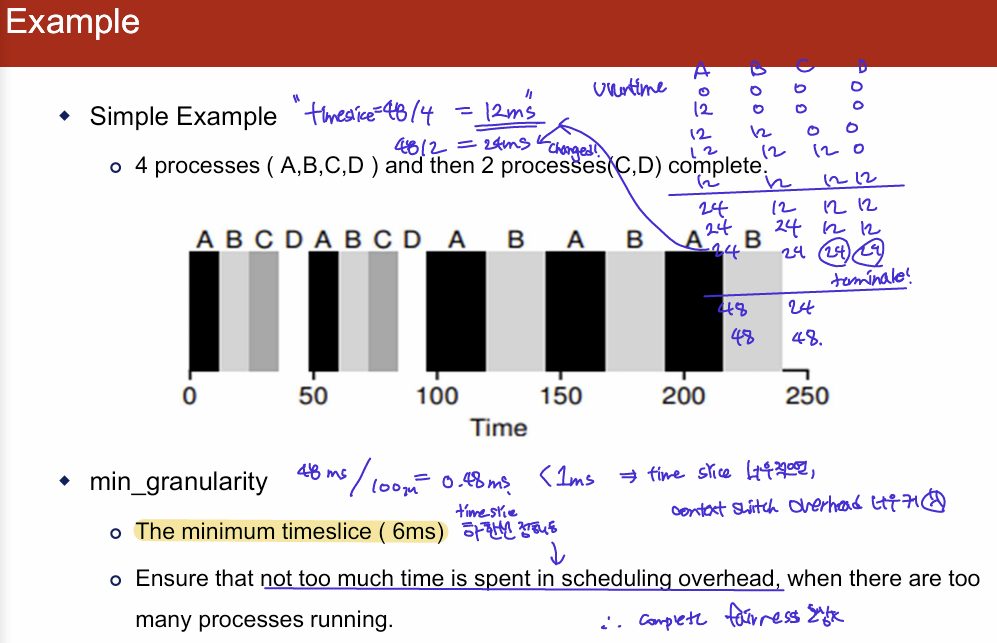
- timeslice = 48/4=12ms -> 48/2 = 24ms
- min_granularity: CPU 프로세스에 할당되는 최소 타임슬라이스
- 만약에 time slice가 6ms보다 작으면 그냥 6ms 보장
- 왜냐하면, 프로세스 수가 많을 경우, 스케줄러는 각 프로세스의 상태를 관리하고 CPU를 할당하기 위해 지속적으로 작업해야한다. 이때 너무 짧은 타임슬라이스를 설정하면 스케줄링에 소요되는 오버헤드가 증가한다.
- 이거 때문에 완전 complete fairness를 보장하는 건 아님...
4) Weight-Nice Value
Nice Value
- CFS가 priority을 조정할 수 있게 한다.
- Nice vlaue: -20 ~ 19 정수
- -20: 가장 높은 우선순위 (덜 나이스 할수록 더 많이 CPU 할당)
- +19: 가장 낮은 우선순위 (더 나이스 할수록 덜 CPU 할당)
- nice value # weight (mapping)
- nice 낮을 수록, weight 높다.
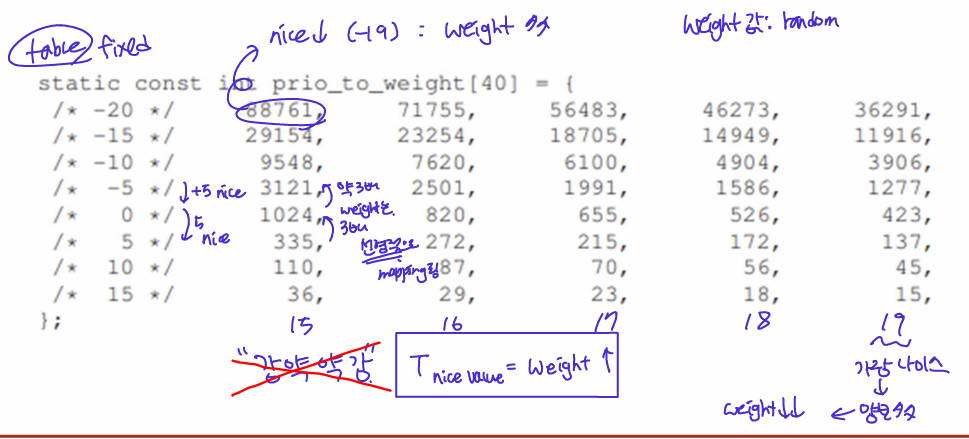
- nice 낮을 수록, weight 높다.
5) Weighting=가중치 (Niceness)
(new) Timeslice with weight

- 프로세스의 우선순위 차이까지도 고려한 timeslice이다.
(new) Vruntime with weight
: vruntime += nicevalue의 중간값 weight(0) / 내 weight * runtime
- 실행시간 누적하는 것 뿐만 아니라 우선순위 차이까지도 고려한다.
- weight 높을수록, vruntime 작아져서 먼저 실행된다.(stride로 나누듯이 weight로 나누기)
---> 가중치 표의 장점은 nice값의 차이가 유지되면, CPU 배분 비율도 유지된다.
Structure of ready queue: Red-Black Tree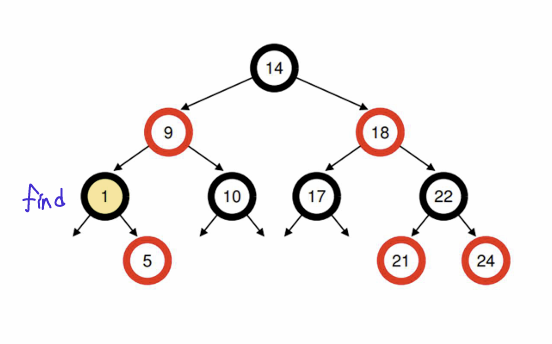
- balanced binary tree
- ordering : O(logn)
- 최소 vruntime process을 효율적으로 찾을 수 있다.
- 오직 running(runnable O, sleep X, blocked X)중인 process들만 tree에 있다.
I/O(blocked) and Sleeping(semaphore, api) Process ?
- 문제: process가 sleep 하는 동안은 vruntime이 증가하지 않아, 매우 작아집니다. 매우 작아진 프로세스가 다시 CPU 사용하게 되면, CPU를 독점하여 과도하게 차지할 수 있습니다.
- 해결: 프로세스가 다시 깨어날 때, 해당 프로세스의 vruntime을 현재 트리에서 발견된 최솟값으로 설정합니다.
- 그러나, Process that sleep for short periods of time frequently do not ever get their fair share of the CPU.(왜??)
