
본 글에서는 QueryDSL의 구체적인 사용법을 다루지 않습니다.
QueryDSL를 사용하며 개인적으로 주의했던 내용을 담은 글입니다.
크레용은 리뉴얼 중 .. 🚧 🚜
리뉴얼 전
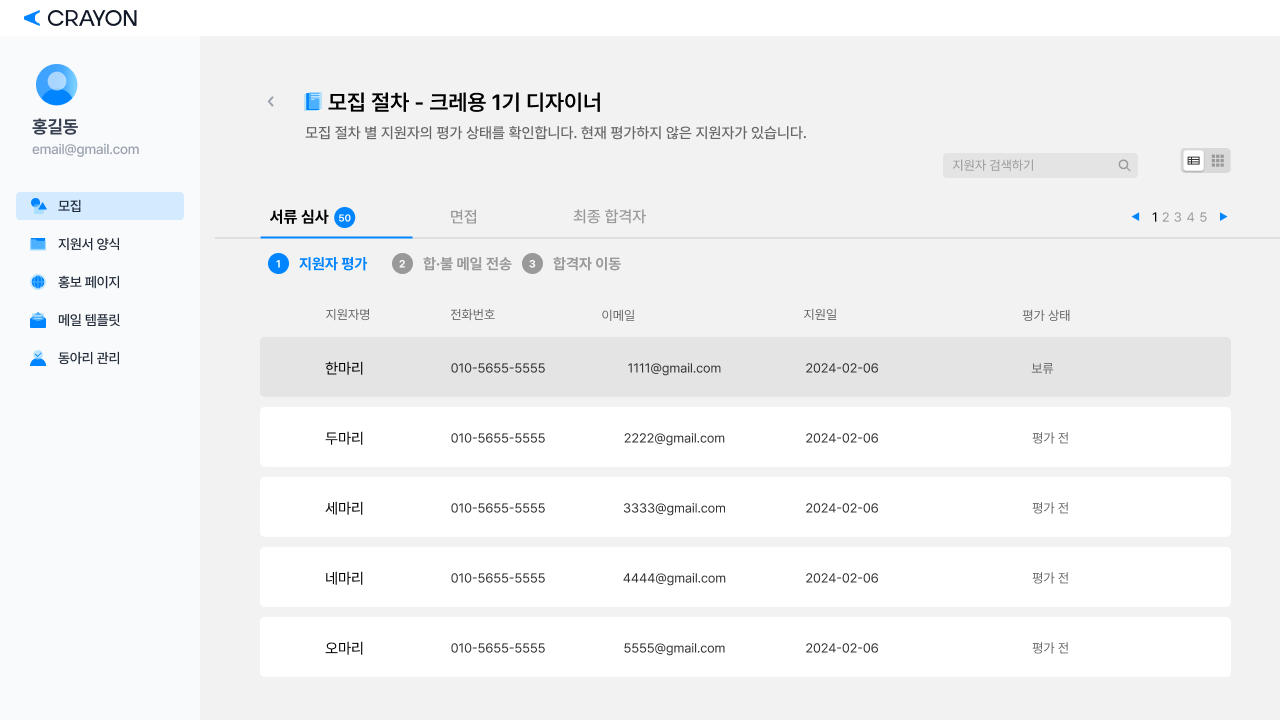
평가 상태가 보류인 지원자를 우선으로 정렬하고, 그 외 지원자들은 지원날짜 순으로 정렬된 모습이다.
UT를 진행하면서 보류 상태 우선 정렬에 대한 필요성보다, 커스텀 가능한 정렬 기준이 필요하다는 사용자 피드백을 얻었다.
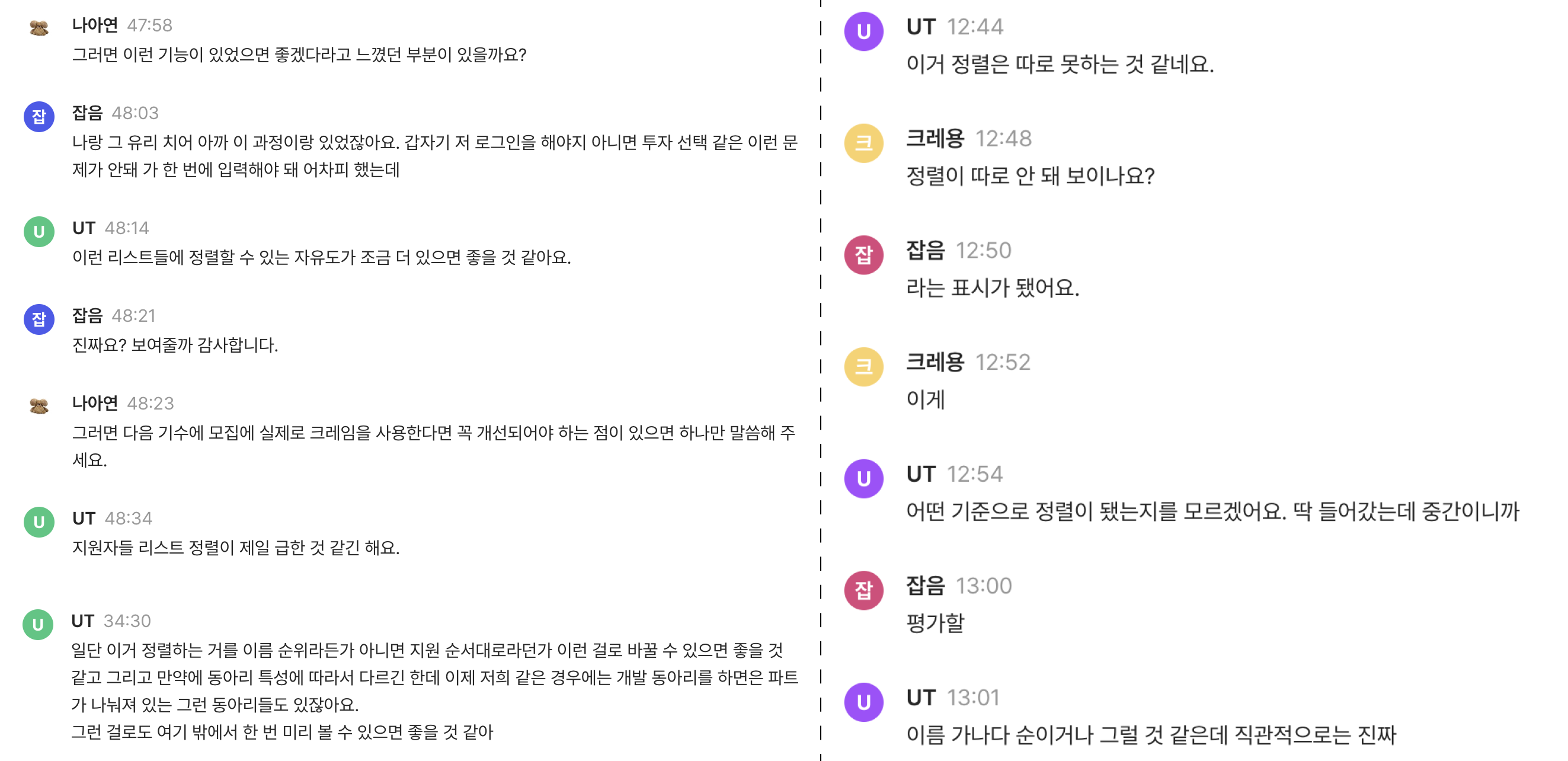
(교훈: UT는 조용한 공간에서 하자)
리뉴얼 후
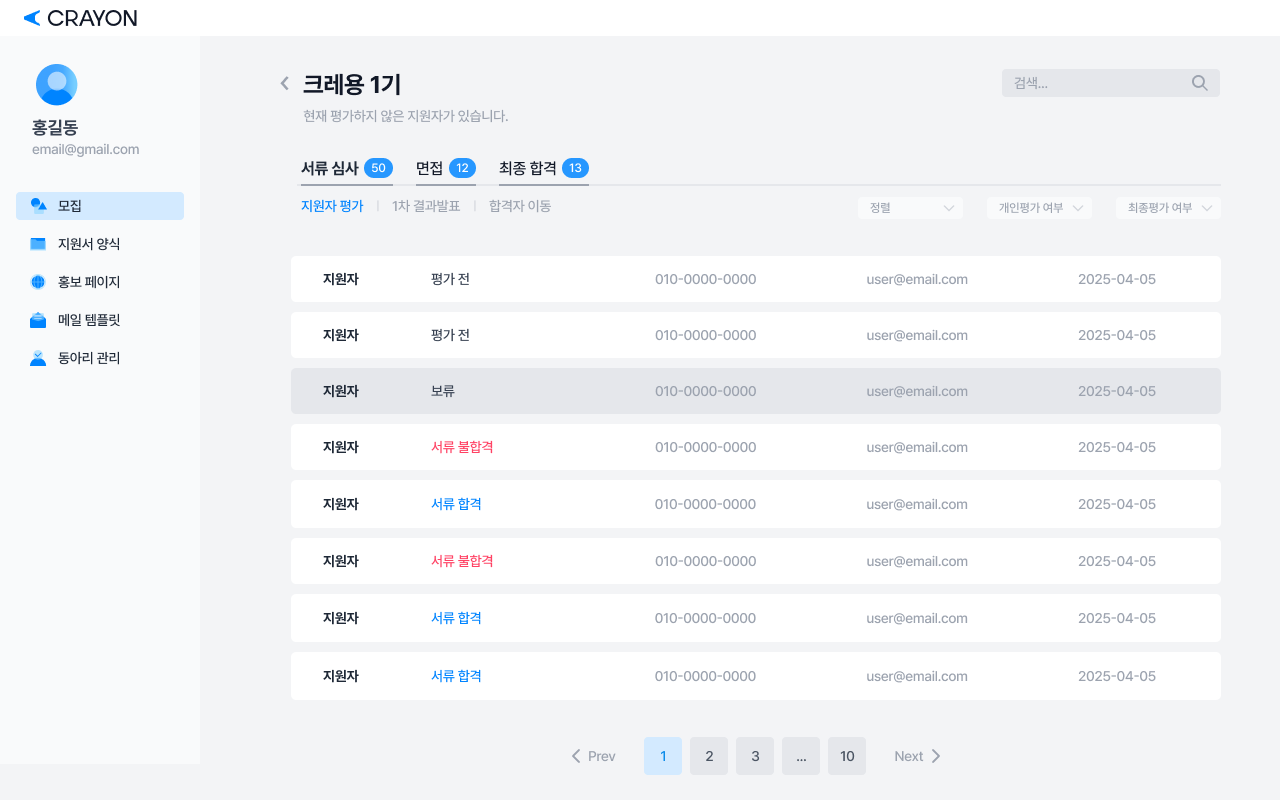
크레용팀은 UT를 바탕으로 정렬과 필터링 기능을 추가했다.
정렬 기준에는 이름, 지원일이 있다.
개인평가 여부와 최종평가 여부는 필터링 기능이다.
여기에 페이지네이션까지 있으니 벌써부터 쿼리가 복잡해질 게 눈에 보인다
@Query("""
SELECT new com.yoyomo.domain.application.domain.repository.dto.ApplicationWithStatus(
a,
pr.status
)
FROM Application a
LEFT JOIN ProcessResult pr ON a.id = pr.applicationId AND a.process.id = pr.processId
WHERE a.process = :process AND a.deletedAt IS NULL
ORDER BY CASE
WHEN pr.status = 'PENDING'
THEN 0 ELSE 1 END,
a.createdAt DESC
""")
Page<ApplicationWithStatus> findAllWithStatusByProcess(@Param("process") Process process, Pageable pageable);보류를 우선 정렬하는 크레용은 위와 같은 정적 쿼리를 사용하고 있다.
현재 요구사항을 정적 쿼리(@Query)로 전부 구현하려면, 동적 조건 없이 경우의 수별로 메서드를 여러 개 만들어야 한다.😓💦
즉, 정렬과 개인평가 여부, 최종평가 여부 조합에 맞춰서 각각 쿼리를 만들어야 하는 구조가 되는 거다.
개인평가 여부(필터링x/유/무) × 최종평가 여부(필터링x/평가상태) × 정렬(이름/지원일)
→ 3 × 2 × 2 = 12개 메서드 필요
음 말도 안된다.
정적 쿼리를 12개 작성한다고 해도, 필요한 쿼리를 찾는 로직이 분기 지옥에 빠질 것이다.
그래서 크레용팀이 선택한 해결책은, 글 제목에서 알 수 있듯이 동적 쿼리를 지원하는 QueryDsl이다.
QueryDSL도 Query다
Spring data가 QueryDSL을 아주 잘 지원한다 👍
정렬을 하는 아주 쉬운 방법으로 컨트롤러 레이어에서 @QuerydslPredicate(root = XXX.class)를 사용할 수 있다. 하지만 나의 경우, 엔티티에 대한 컨트롤러의 의존성이 너무 강해진다는 판단으로 사용하진 않았다.🤔
그 대신 정렬, 필터링, 페이지 정보들은 기본형으로 받아 Condition 객체로 사용했다.
@GetMapping("/manager/{recruitmentId}")
@Operation(summary = "[Manager] 지원서 목록 조회")
public ResponseDto<Page<ApplicationListResponse>> readAll(
@CurrentUser User user,
@RequestParam Integer stage,
@PathVariable UUID recruitmentId,
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "8") int size,
@RequestParam(defaultValue = "applied") String sort,
@RequestParam(defaultValue = "all") String evaluationFilter,
@RequestParam(defaultValue = "all") String resultFilter
) {
ApplicationCondition condition = ApplicationCondition.from(sort, evaluationFilter, resultFilter);
Page<ApplicationListResponse> response = applicationManageUseCase.readAll(
recruitmentId, stage, user, condition, PageRequest.of(page, size)
);
return ResponseDto.of(OK.value(), SUCCESS_READ_ALL.getMessage(), response);
}기껏 엔티티 필드명과 API 스펙을 분리했다.
백엔드 내부 사정으로 엔티티가 변경되어도 API 스펙에는 변경이 없길 바란다🙏
QueryDSL DTO 매핑
QueryDSL을 사용하면서 원하는 DTO로 반환하고 싶은 경우에는 Projections나 @QueryProjection + QDTO을 사용할 수 있다.
| 방식 | 설명 | 성능 | 장점 | 단점 |
|---|---|---|---|---|
Projections.constructor(...) | 생성자 기반 매핑 | 느림 (리플렉션) | 생성자 타입 체크 덕분에 컴파일 타임 오류 발생 | 생성자 순서/타입 일치 필수 |
Projections.fields(...) | 필드 직접 주입 | 느림 (리플렉션) | 필드명만 일치하면 편리 | 타입 불일치 시 런타임 오류 |
@QueryProjection + QDTO | 컴파일 타임 생성된 타입 사용 | 빠름 (컴파일 타임 생성 코드) | 타입 안정성, 리팩토링 안전 | DTO가 QueryDSL에 의존하게 됨 |
Projections는 리플렉션 기반이라 성능이 느리다고 한다.
하지만 현재 쿼리는 대용량 배치 처리도 아니며, 반환하는 DTO를 서비스 레이어에서도 사용하고 있기 때문에 QueryDSL에 의존시키고 싶지 않았다.
그리고 Projections.fields(...)는 필드를 직접 주입하기 때문에,
record나 클래스의 생성자 로직 (canonical constructor)를 호출하지 않는다. 하지만 크레용 서비스에서는 아래처럼 DTO 생성 시 초기화 로직이 필요하다. 그래서 Projections.construct(...)를 사용했다.
public record ApplicationWithStatus(
Application application,
Status status
) {
// canonical constructor
public ApplicationWithStatus {
if (status == null) {
status = Status.BEFORE_EVALUATION;
}
}
}QueryDSL 후기
일단 Java 코드로 쿼리를 작성하니 IDE의 자동완성 기능을 활용 가능하다는 점이 편하다 🥹 JPQL의 문자열 기반 쿼리보다 훨씬 실수 가능성이 적다는 점!! 그리고 컴파일 시점에 오류를 잡을 수 있다는 점도 만족스러웠다.
그리고 몰랐던 사실인데, QueryDSL은 JPA의 1차 캐시, 영속성 컨텍스트, Fetch Join 등 기능도 활용 가능하다고 한다.
아직 익숙하지 않은 탓도 있지만, 문법이 다소 장황하다 느낀다. 그럼에도 12개의 JPQL 쿼리를 작성하는 것보단 장황하지 않다(ㅋㅋ)
참고
전체 코드는 PR을 참고해주세요
