https://arxiv.org/abs/1706.03762
를 기반으로 작성하였습니다
Abstract
dominant sequence transduction 모델들은 복잡한 encoder와 decoder를 포함한 recurrent, convoultional neural network(RNN, CNN)를 기반합니다.
가장 최고의 performing model은 attention 매커니즘을 통해 encoder와 decoder와 연결됩니다.
우리는 attention 메커니즘만 사용하고, recurrences아 convolutions을 전혀 사용하지 않는 새롭고 간단한 architecture를 제안합니다.
etc..
Model Architecture
대부분의 competitive한 neural sequence transduction model들은 encoder-decorder 구조를 가진다.
encoder는 symbol representations로 이뤄진 input sequence (x_1, ..., x_n)을 continuous representation한 sequence인 z = (z_1, ..., z_n)으로 매핑한다
(간단히 encoder는 주어진 symbol sequence(단어나 글자 등)를 vector sequence Z로 모델이 입력을 이해하고 처리할 수 있는 형태로 만드는 역할을 한다는 뜻)
Z를 주고, decorder는 순차적으로 출력 y를 하나씩 생성해나가 output sequence(y_1, ..., y_n)를 만든다.
(즉, encoder가 영어문장을 vector로 표현하고, decoder가 영어문장을 기반으로 만든 vector를 한국어 문장을 하나씩 만들어 내는 식으로 작동한다라는뜻)
매 step마다 모델이 이전에 생성한 심볼을 추가 입력으로 사용하여, 다음 심볼을 생성하는 "auto-regressive"(자기회귀적) 특성을 가진다
(모델이 새로 출력을 생성할때, 이전에 생성했던 심볼을 참고하여 다음 심볼을 예측한다라는 뜻, 즉, 이런 방식으로 문맥을 반영할 수 있음)
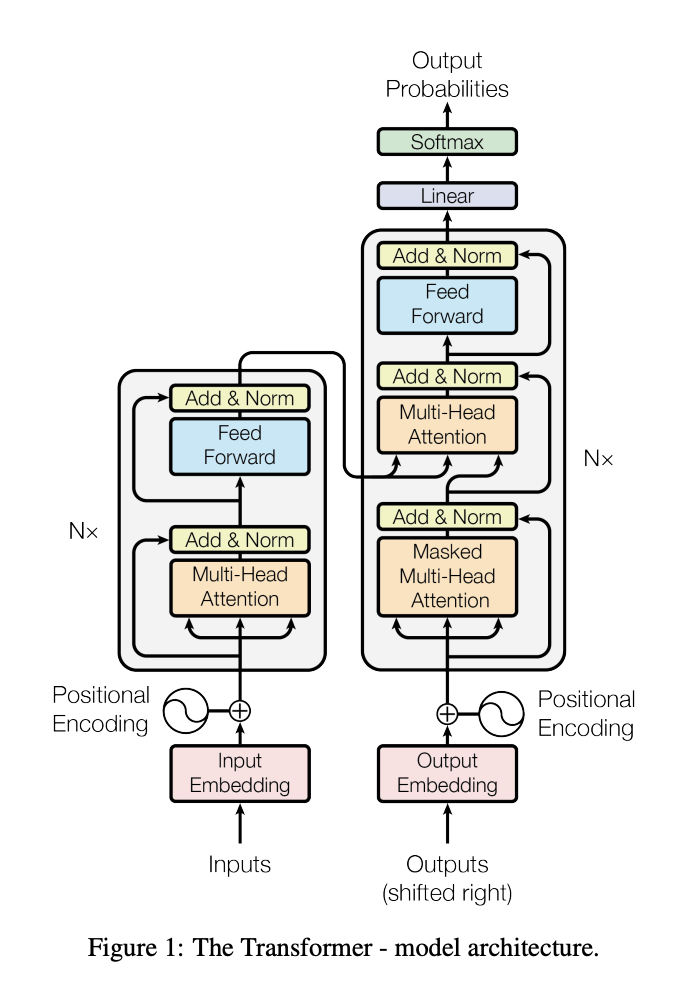
Transformer의 전체 architecture는 stacked self-attention, point-wise, fully connected layers를 사용한다 encoder, decoder 양쪽 둘다에
Encoder and Decoder stacks
Encoder
encoder는 6개의 동일한 layers(N=6)로 구성되어 있고, 각 layers는 2 sub-layers로 구성 되어있습니다.
- 1번째 sub-layer는 multi-head self-attention mechanism
- 2번째 sub-layer는 simple, positionwise fully connected feed-forward network
각 sub-layer에 주위에 residual connection(잔차 연결)이 적용한 뒤, layer normalization (계층 정규화)이 진행된다.
- sub-layer의 output은 LayerNorm(x + Sublayer(x)) 이다
(*Sublayer는 self-attention or feed-forward)
이러한 residual connection을 원활하게 하기 위해, model의 모든 sub-layers은 동일한 d_model = 512을 출력하도록 설정
Decoder
decoder도 또한 layers(N=6)으로 구성되어있고, 각 encoder layer에 있는 2개의 sub-layers를 추가하여, decoder의 각 layer는 3개의 sub-layers로 구성되어 있다.
- 1번째 sub-layer는 multi-head self-attention mechanism
- 2번째 sub-layer는 encoder의 출력에 대해 multi-head attention 수행
- 3번째 sub-layer는 simple, positionwise fully connected feed-forward network
각 sub-layer에 주위에 residual connection(잔차 연결)이 적용한 뒤, layer normalization (계층 정규화)이 진행된다.
- sub-layer의 output은 LayerNorm(x + Sublayer(x)) 이다
(*Sublayer는 self-attention or feed-forward)
decoder의 self-attention sub-layer는 미래 위치의 정보를 masking 하여, 현재 위치 이후의 정보를 보지 않도록 한다, 이를 통해 decoder는 i번째 위치의 예측이 i번째 이전의 출력에만 의존하게 된다.
Attention
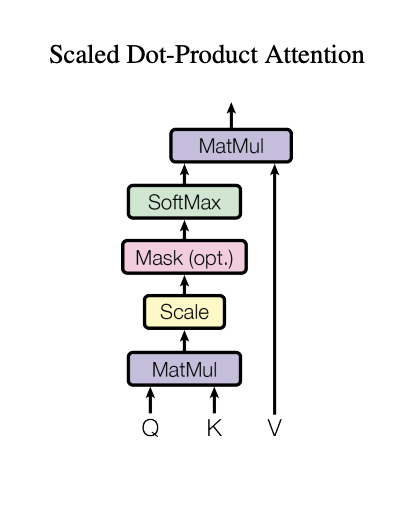
attention function은 query와 key-value pairset을 output으로 mapping 하는 function으로 설명될 수 있다.
(여기서 query, key, value, output => vector로 표현)
Output은 가중합으로 계산됨
Scaled Dot-Product Attention