Latent Variable Models
D.Kingma가 만든 모델이라고 한다. Adam, varitaional auto-encoder도 만든 대단한 분이라고 한다...
Autoencoder는 generative model인가?
variational auto-encoder는 generatiev model이니까 auto-encoder도 generative model인가? 그렇지 않다.
즉, variational auto-encoder를 generative model로 만들어주는 이유가 있고 이것을 아는 것이 중요하다!
Variational inference(VI)
The goal of VI is to optimize the variational distribution that best matches the posterior distribution.
- posterior distribution:
- observation이 주어졌을 때, 관심있어하는 random variable의 확률분포
- z: latent vector
- 반대로 뒤집은걸 보통 likelihood라고 한다.
- Varitaional distribution:
- posterior distribution은 구하기 불가능하거나 어려운 경우가 많다.
- posterior distribution에 근사하는 확률분포를 의미한다.
- KL divergence: 근사 방법
- 이를 사용해 true posterior와 variational distribution의 차이를 최소화하겠다.
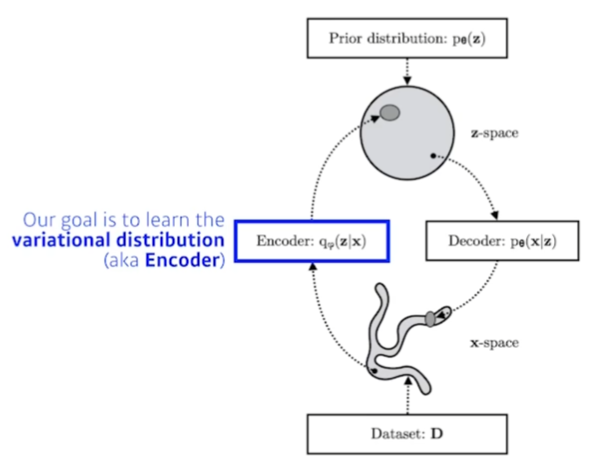
- Encoder: Variational distribution을 학습하는 곳
How to find objective?
gradient descent에서 true y를 알아야 loss function의 값을 계산할 수 있듯이, Variational inference도 posterior distribution을 알아야 variational distribution을 근사할 수 있을 것이다.
문제는 variational distribution을 구하는 이유가 posterior distribution을 구하기 어렵기 때문이라는 것이다. 모순이 발생한다.
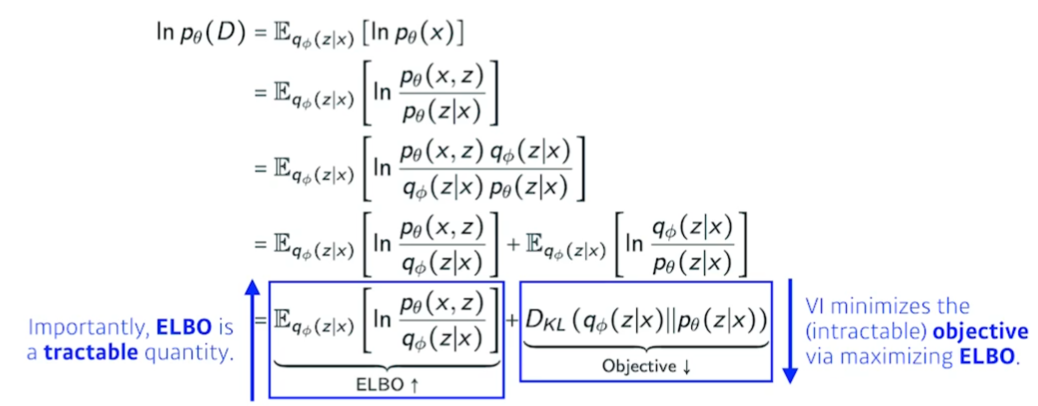
이를 수식으로 설명하면 위 수식이 된다고 한다. 학부 수준의 통계학을 들었다면 이해 가능한 수식이라고 한다. (...)
수식에서 Objective를 줄이는 것이 곧 posterior와 varitional의 차이를 줄이는 것이다. 하지만 실제 posterior를 모르기 때문에, 앞 항인 ELBO(Evidence Lower bound)를 늘려줘서 반대급부로 objective가 줄어드는 것을 유도한다고 한다.
이러한 방법 자체를 sandwitch method라고 부르기도 한다고 하더라.
KL divergence를 모르기 때문에 ELBO를 키우는 방법을 활용해 variational inference는 학습을 진행한다.
ELBO

ELBO는 위처럼 다시 풀어쓸 수 있고, 이는 계산 가능하다.
- Reconstruction Term: Auto-encoder의 reconstruction loss term
- Prior Fitting Term: Latent Prior Term?
정리
Variational Inference의 궁극적인 목표는 입력 X에 대해서, X를 잘 표현하는 latent space(잠재변수 공간?)인 Z를 찾고 싶은 것이다.
하지만 posterior distribution인 를 모른다. 그래서 posterior distribution을 찾기 위해 variational distribution 혹은 encoder로 posterior distribution을 근사하고자 한다.
posteriror distribution을 모르는 상태에서 KL divergenec를 통해 추정치와 실제값의 거리를 구할 수는 없다! 따라서 Variational inference라는 기법을 사용해 ELBO를 Maximize하면 KL divergenec를 줄여서 추정치와 실제값의 거리를 줄여주는 효과를 유도한다.
ELBO는 Reconstruction term과 Prior fitting term으로 나뉜다.
Reconstruction term
- X라는 입력을 encoder를 통해 latent space로 보낸다.
- 이를 다시 decoder로 보냈을 때 발생하는 reconstruction loss를 줄이는 것이 reconstruction term
Prior fitting term
- X라는 입력을 latent space로 올려놨다고 해보자.
- 올라간 데이터들의 분포가 latent space의 prior distribution과 얼마나 차이가 있는지를 나타내는 term이다.
따라서, generative model이고 explicit model아닌 implicit model이다.
Variational Auto-Encoder(VAE)
입력 X가 주어지고, 이를 latent space로 보내서 무언가를 찾고 이를 통해 reconstruction term으로 만든다.
Generative model이 되기 위해서는 latent space의 prior distribution인 z를 샘플링하고 이를 Decoder에 통과시켜 나오는 output을 generation result라고 보는 것이다.
하지만 auto encoder는 이렇나 과정이 없다. 그냥 input이 latent space로 갔다가 output으로 나온다. 그래서 엄밀한 의미에서 auto-encoder는 generative model이 아니다.
VA의 특징은 아래와 같다.
- Intractable model이다.
- likelihood를 계산하는 것이 어렵다.
- implicit model이다.
- Prior fitting term은 계산하기 매우 어렵다.
- 미분했을 때 무언가 값을 얻기 쉽도록 isotropic Gaussian을 사용한다.
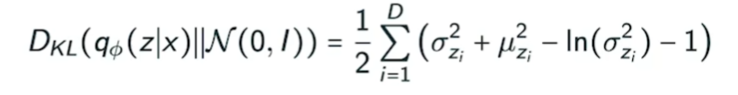
Adversarial Auto-encoder(AAE)
VAE의 단점은 prior fitting term에서 gaussian이 아닌 다른 것을 활용하기가 힘들다. 하지만 많은 경우에, prior distribution으로 gaussian을 활용하고 싶지 않을 때가 많다.
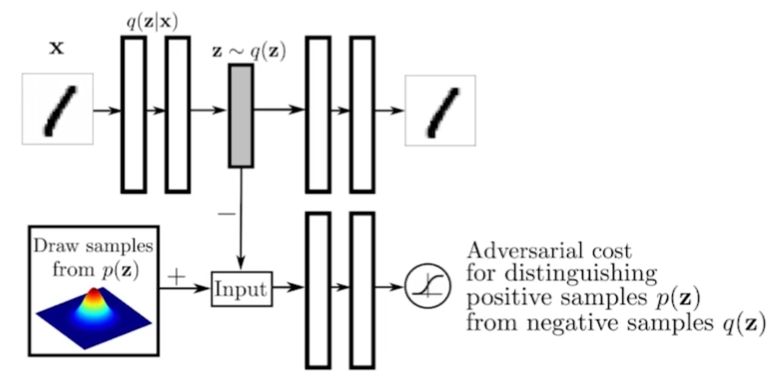
이를 위한 해결법으로 AAE가 있다.
GAN을 사용해서 latent distribution의 분포를 맞춰준다고 한다. 즉, VAE의 prior fitting term을 GAN으로 바꾼 것이다.
latent distribution에 샘플링만 가능한 어떤 분포만 있어도, prior fitting에서 사용할 수 있다.
e.g., uniform distribution, 혹은 복잡한 distribution도 가능.
VAE보다 성능이 더 좋을때도 많다고 한다. 물론 항상 좋진 않다.
wasserstein autoencoder라는 논문이 2018년에 나왔는데, 사실 AAE는 latent space 사이의 wasserstein distribution을 줄여주는 것과 동일한 효과임을 수식으로 증명했다고 한다. 따라서 AAE도 wasserstein autoencoder의 한 종류라고 봐도 된다고 한다.
Generative Adversarial Network(GAN)
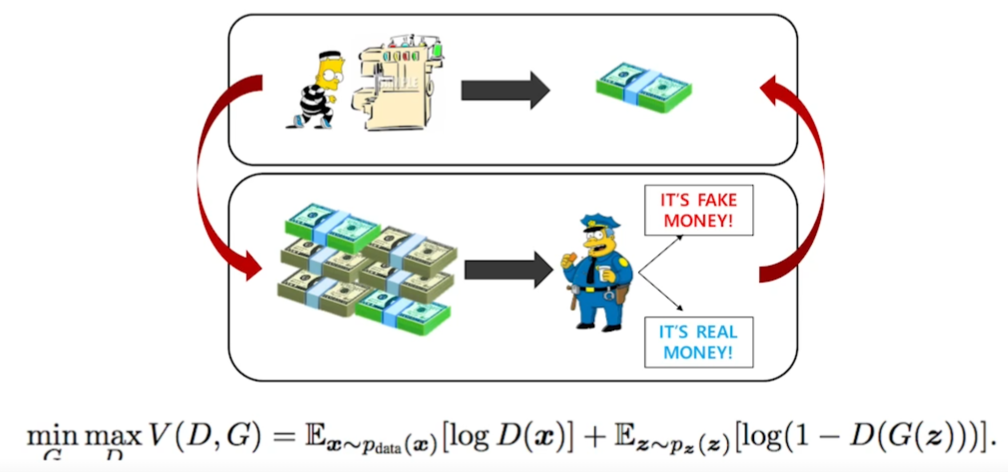
Generator는 위조지폐를 만들고 Discriminator(구별자?)는 위조지폐를 감별한다고 해보자.
Discriminator는 본인이 알고있는 지식과 generator의 결과를 바탕으로 더욱 위조지폐를 잘 구분하려고 학습한다. 만약 Fix된 discirminator라면 서로 학습이 잘 안될텐데, 이것이 매우 큰 장점이다.
Generator는 Discriminator를 더 잘 속일 수 있도록 학습한다.
GAN의 목표는 Generator의 성능을 향상시키는 것이다. Implicit model이다.
VAE vs GAN
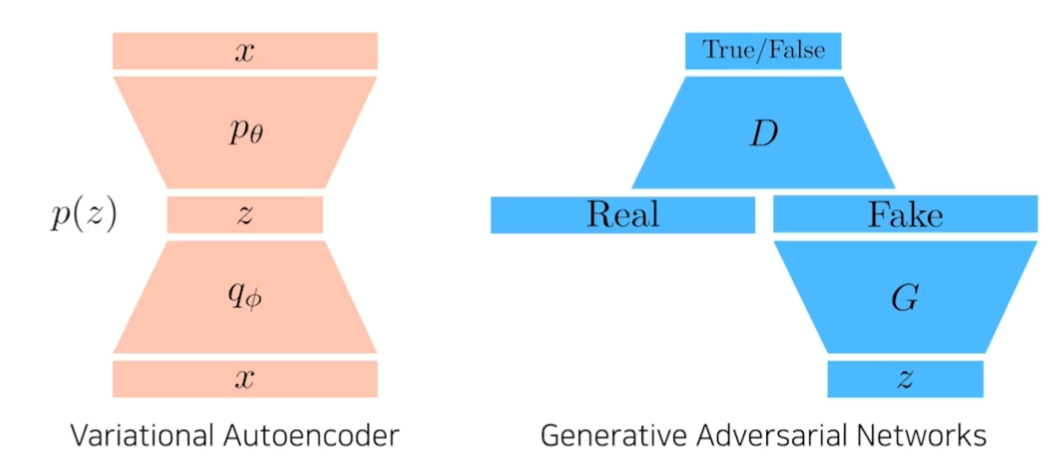
VAE
- 학습
- x라는 입력을 encoder를 통과시켜 z라는 latent vector로 만든다.
- decoder를 통해 다시 x라는 도메인으로 출력.
- generation
- p(z)에서 z를 샘플링한다.
- z를 decoder를 통과시켜 원하는 결과를 generate.
GAN
- z라는 latent distribution을 입력.
- z는 G를 통과해 Fake를 생성.
- Discriminator는 Real, Fake를 구분하는 Classifier를 학습.
- Generator는 Discriminator가 True를 출력하도록 학습.
- Discriminator는 Real, Fake를 더 잘 구분하도록 재학습.
GAN Objective
A two player minimax game between generator and discriminator.
Discriminator
앞서 본 GAN의 수식을 Discriminator에 대해서만 보면 아래와 같다.
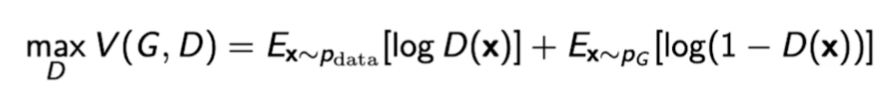
이 때, optimal discriminator는 아래와 같다.
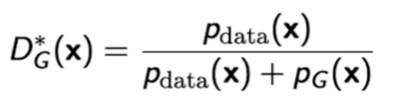
Generator를 fix했을 때의 optimal한 형태라고 한다. 해당 값이 높으면 true, 낮으면 false 같은 형식이라고 한다.
Generator
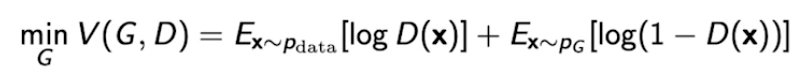
위에서 얻은 optimal discriminator를 generator에 대해서만 풀어쓴 GAN 수식에 대입해보자.
그러면 아래와 같이 Jenson-Shannon Divergence(JSD)가 유도된다고 한다.

즉, 실제 true data와 generator가 생성한 data간의 거리를 재는데 Jenson-Shannon divergence가 사용된다고 할 수 있다.
하지만, 이는 optimal discriminator가 보장된 상태에서만 유도 가능한 결과이다. 즉, 이론적으로는 맞지만 실제로는 사용하기 어렵다.
DCGAN
처음의 GAN은 MLP로 만들었다. 이를 이미지 도메인을 위해 만든 것이 DCGAN이다.
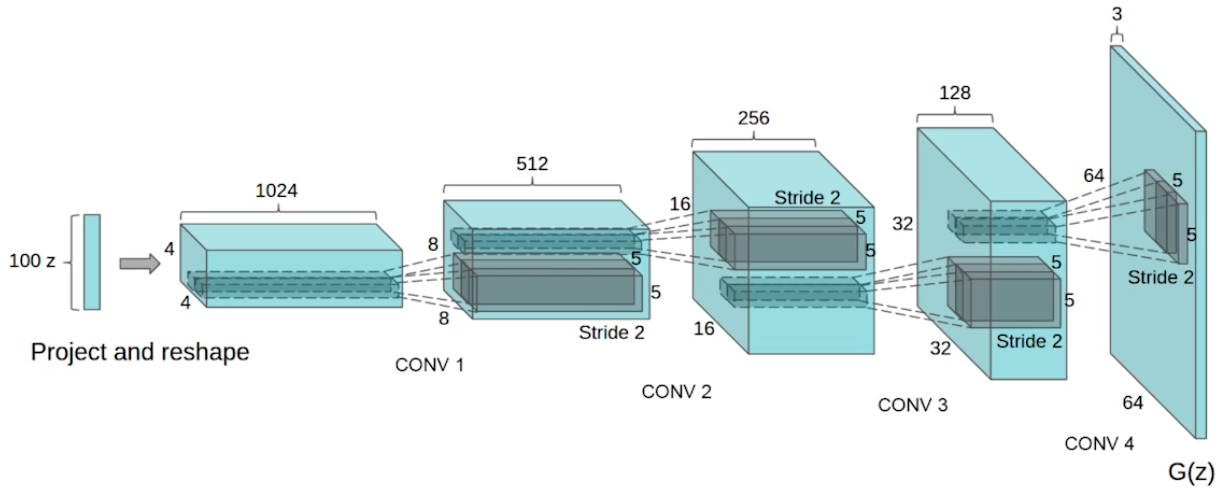
Encoder에서는 deconvolution을 사용했고 discriminator에서는 convolution을 사용했다.
알고리즘적으로 향상된 부분은 없지만, 여러 테크닉들을 사용했다고 한다. 에러 종류도 바꿔보고 hyper parameter 세팅 등..
Info-GAN
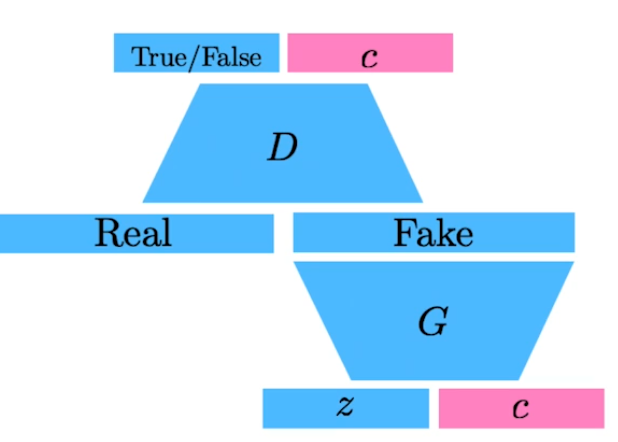
z라는 입력을 넣을 때, c라는 클래스를 나타내는 원핫벡터를 넣는다. 이는 Generation을 할 때, GAN이 c라는 벡터를 활용해서 특정 모드에만 집중할 수 있도록 해준다.
따라서, multi modal distribution을 학습하게 되는 현상을 c 벡터를 통해 잡아주는 효과가 생긴다.
Text2Image

문장이 주어지면 그림을 만들어준다고 한다. openai의 DALL-E 연구가 이 논문을 바탕으로 시작됐다고 한다.
Puzzle-GAN
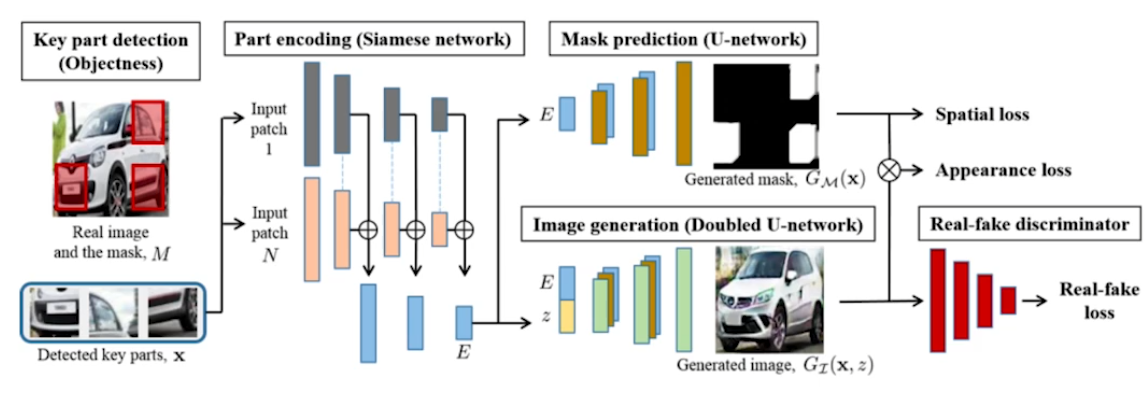
교수님께서 저자로 참여하신 논문이라고 한다. ...
이미지의 sub patch를 넣어주면 전체 이미지를 복원하는 모델이라고 한다.
CycleGAN

이미지 사이의 도메인을 바꿔주는 모델이다. 가령, 그림처럼 zebra를 horse로 바꾸는 것이다.
Cycle-consistency loss
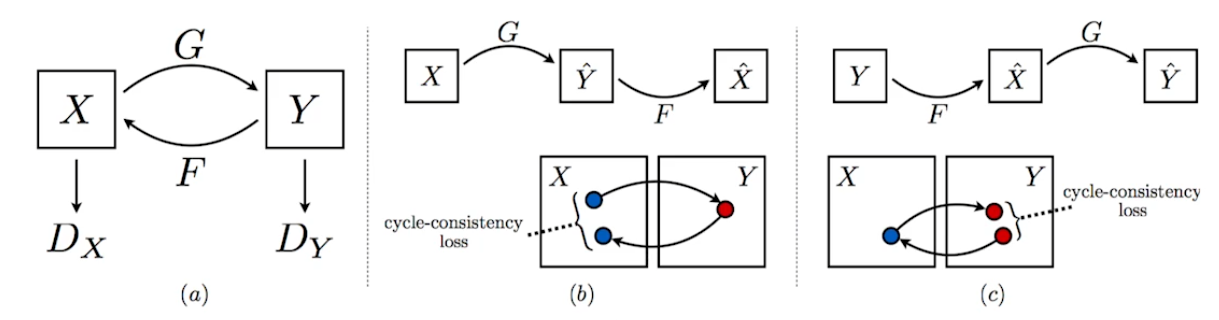
일반적으로 이미지의 도메인을 바꾸기 위해서는 두 개의 이미지가 필요하다. 가령, 얼룩말 사진을 말 사진으로 바꾸고 싶다면, 동일한 곳에서 찍은 얼룩말과 말의 이미지가 필요하다.
하지만 cycleGAN은 그냥 만든다. 즉, 야생의 말 사진과 야생의 얼룩말 사진들을 잔뜩 학습하면 위의 과정을 알아서 만들어준다.
Star-GAN

한국인 학생분께서 쓰신 논문이라고 한다. 이미지에 단순히 도메인 변화를 주는 것이 아니라 도메인에 대한 컨트롤을 할 수 있는 방법론이라고 한다. 인용도 엄청 많이 됐다.
Progresive-GAN

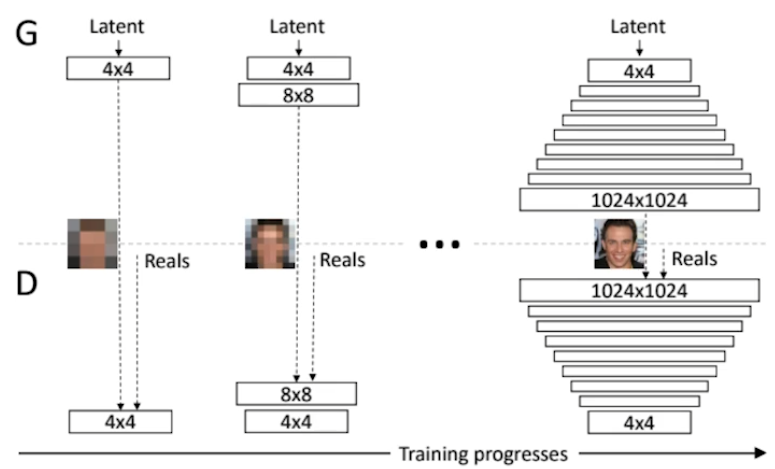
처음부터 고차원의 이미지를 학습하지않고, 4x4이미지의 차원을 늘려가면서 1024x1024까지 점진적으로 학습했다고 한다. 이것이 성능향상에 큰 기여를 했다고 한다.
정리
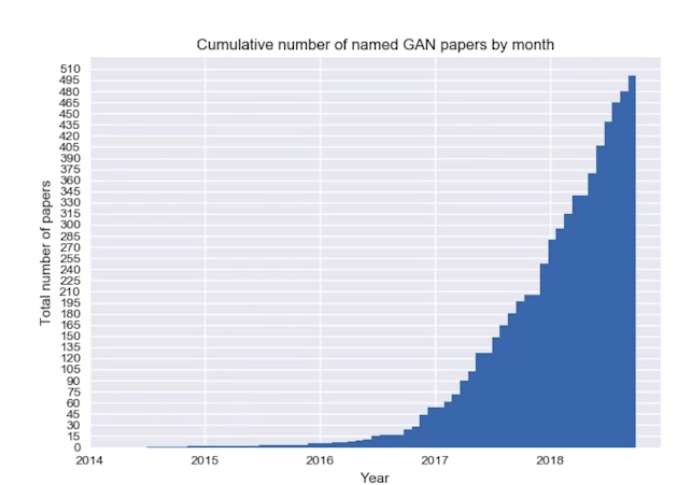
GAN 논문의 수를 나타낸 그래프다. 2018년에만 500개라고 하니, 모든 GAN에 대해 다 아는 것을 불가능하다. openai의 DALL-E 연구를 보면 GAN을 쓰는 것이 아니라 transformer를 쓰는 것이 제일 좋을 수도 있겠다고 하셨다.
중요한 것은 알아가는 것이다.
