DL Basic
1.DL
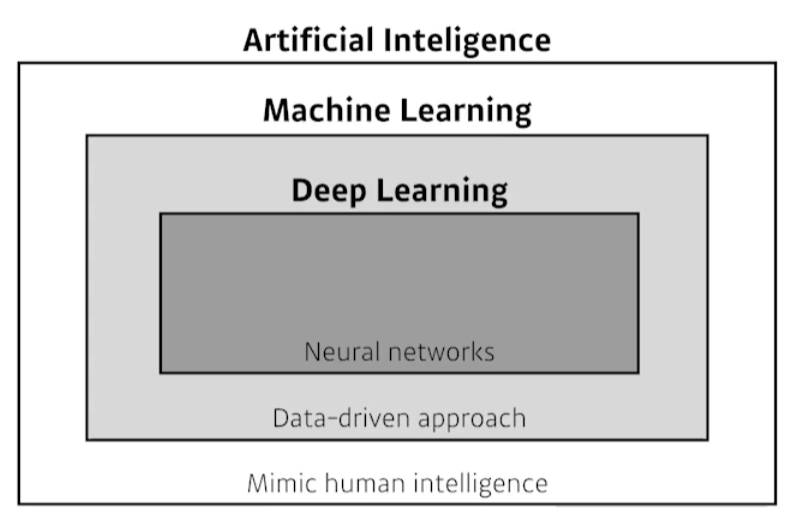
모호하게 알고 있던 내용들을 부캠강의에서 명료하게 정리해줬다. 당연한 이야기들도 많은데 그냥 다 정리했다.구현 능력수학 능력(Linear algebra, probability)최신 트렌드의 논문들을 많이 알고 있는 것AI = 사람의 지능을 모방하고자 한다ML = 데이터
2.NN & Multi layer perceptron
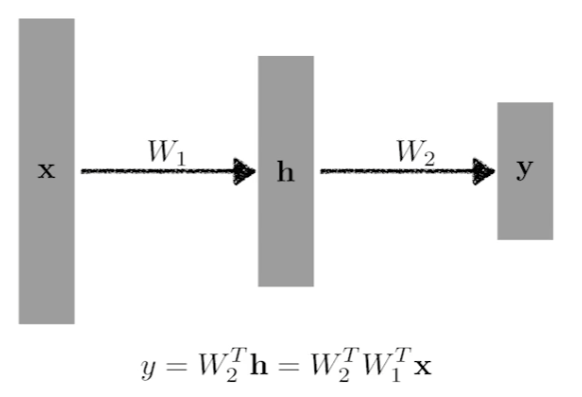
Neural Networks 인간이 가진 뇌의 신경망을 모방했기 때문에 잘 작동한다고도 한다. 어느 정도 맞는 말이다. 실제 뉴런의 형태를 모방해서 구현된 것이 NN의 node와 흡사하다. 하지만 굳이 뇌를 모방한 것이라 하기에는 Back propagation과 같
3.pytorch

pytorch에서 자동으로 해주기는한다.하지만 수동으로 parameter를 원하는대로 초기화해야하는 경우가 분명 발생한다. 이를 수동으로 해결하는 방법은 기본적으로 아래와 같다.pytorch의 큰 장점은 session이 없다는 것이다. 물론 tf도 ver 2부터는 se
4.Optimization

부캠 강사님께서 용어에 대해 확실히 알고 가라고 하셨다.어제(21.08.09) 선택과제 2번의 AAE에 대해서 알아보다가 기겁을 했다. 한 문장 안에서 모르는 단어를 세는 것보다, 아는 단어를 세는게 빨랐다. 분명 영어로 쓰여있는데 외계어 같았다... 인턴을 하면서,
5.Optimizer 실습
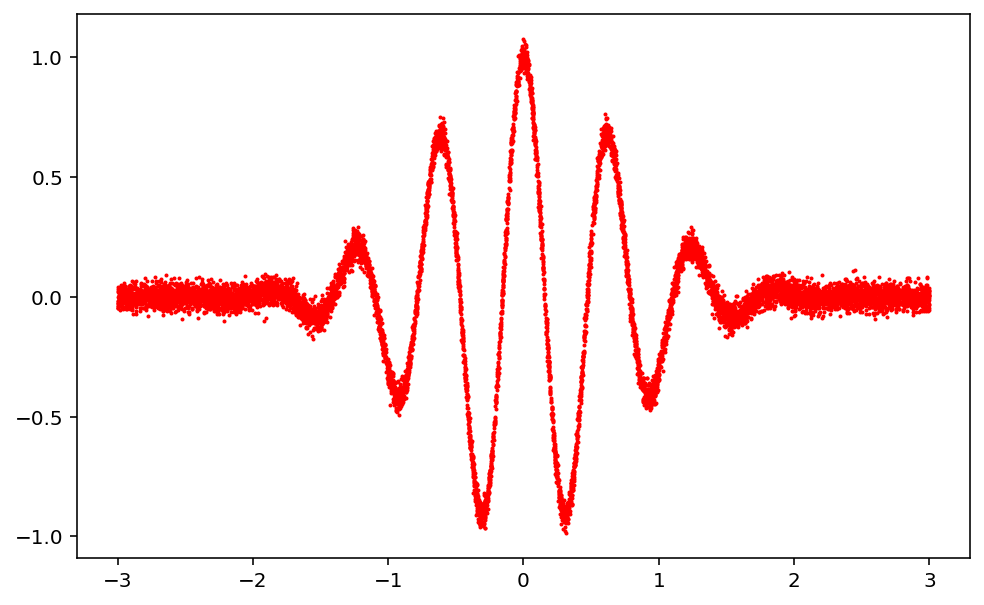
matplotlib와 같은 출력물의 해상도를 retina로 설정본래 의도한 함수의 그래프는 위와 같다. 해당 그래프에 노이즈를 추가해보자.노이즈는 위 코드에 서술됐듯이, np.random.randn()에 작은 실수값인 3e-2를 곱해줘서 구현된다.500번째, 3500번
6.Convolution
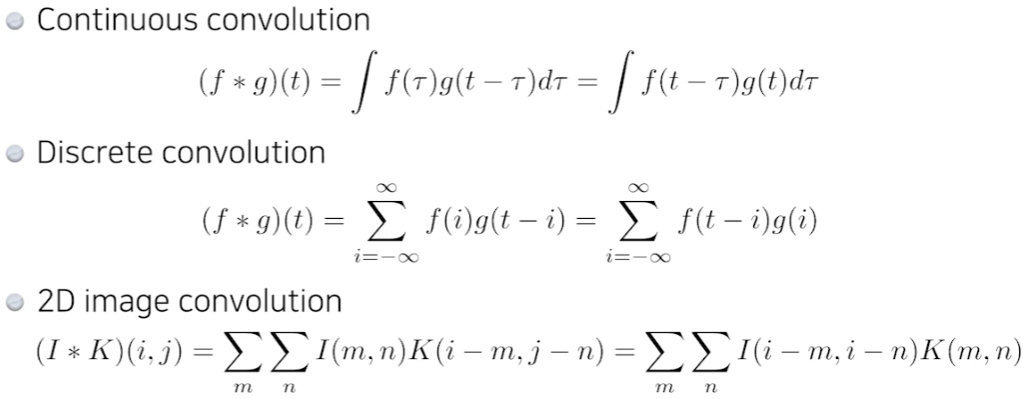
원하는 feature를 뽑을 수 있다.가령, 모든 kernel의 값이 1/9인 (3,3) kernel을 사용했다고 하자. 그러면 평균을 구하는 convolution 연산이 된다.channel이 3개인 RGB이미지를 가정해보자. 이 이미지에 (5,5) filter를 적용
7.weight init
다른 캠퍼분이 정리해주신 내용이 있는데 공유한다.https://velog.io/@hanlyang0522/weight-init%EC%9D%84-%ED%95%98%EB%8A%94-%EC%9D%B4%EC%9C%A0정리하면, weight init을 0으로 하지 않는
8.CNN key concept
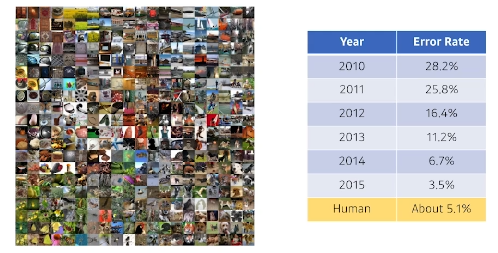
ImageNet Large-Scale Visual Recognition ChagllengeClassification, Detection, Localization, Segmentation1000 different categories2015년도를 기준으로 사람보다 erro
9.Convolution 실습
mlp든 뭐든 특별한 과정이 들어가는게 아니면 동일한 과정의 train이다. 커스텀이 필요하다면 졸프에서 했던 것과 같이, network의 input과 ouput을 자유롭게 수정도 가능하다.결국 달라지는 것은 network의 종류이다.batch normalization
10.CNN
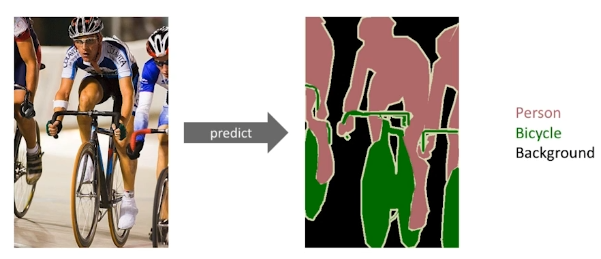
이미지를 모든 픽셀에 대한 라벨을 결정하는 문제.ref: https://youtu.be/cuIrijsu9GYdense layer를 없애고 convolution layer를 통해 구현하여 parameter를 줄여보자.이것을 convolutionalization이
11.RNN
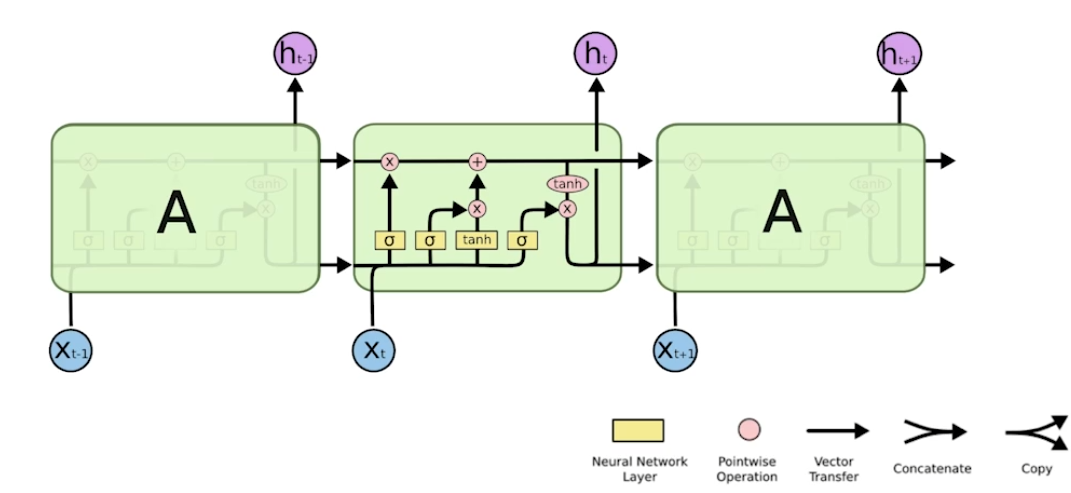
RNN Sequential model sequence data는 몇차원인지 알 수 없다. 즉, 임의의 n차원 입력에 대한 처리가 가능한 모델이 필요하다. sequential model은 고정된 길이의 과거 정보들을 활용해 다음의 seuqence에 대한 예측을 하는 모
12.parameter 수
수업을 기준으로 하는 2020년에는 parameter의 수를 줄이는 것이 관건이라고 했다. 왜냐하면 그럴수록 학습이 잘되고 일반적인 성능을 올리거나 generalize performance에도 좋다.하지만 오늘 master 클래스에서 교수님께서 2021년에서는 아니라고
13.Transformer
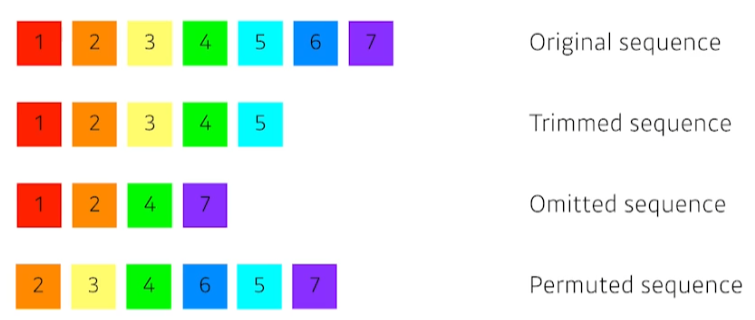
기존의 rnn들도 sequence data들을 다룰 수 있지만, 위와 같이 원본 데이터에서 일부 데이터가 빠진 sequence data들에 대해서 다루기는 매우 어려웠다.이를 다루기 위해 transformer가 등장했다. RNN처럼 재귀적인 구조가 없다.Tranasfo
14.Transformer 실습
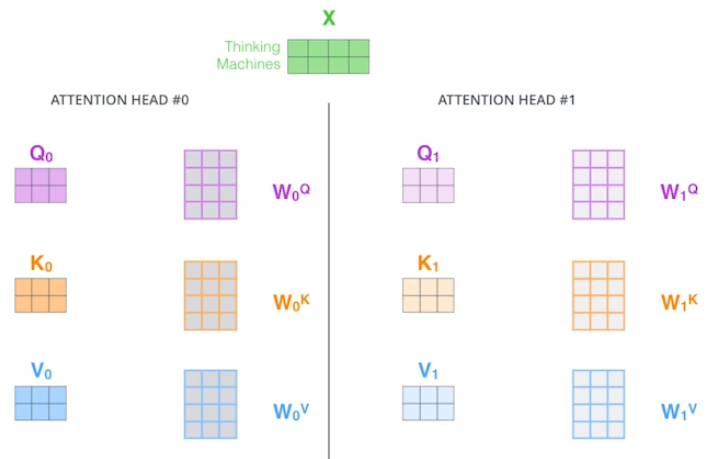
Scaled Dot-Product Attention.transformer를 배우면서 attention이 1개만 존재했던 그 모델이다. 위 그림처럼 여러 개의 Q, K, V를 생성하는 것이 MHA이고 한 쌍의 Q, K, V만 생성하면 SDPA.수식에서도 나와있듯이, qu
15.Generative Models
https://deepgenerativemodels.github.io/ 스탠포드 대학의 수업이라고하는데 참고해서 수업을 진행하셨다. Generative model 단순히 이미지와 문자를 만드는 것이 아니다. 강아지 이미지들을 받았다고 해보자. Generative
16.Generative model - 2
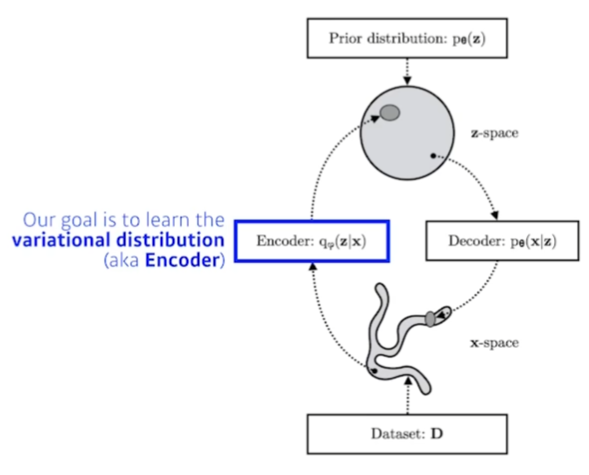
D.Kingma가 만든 모델이라고 한다. Adam, varitaional auto-encoder도 만든 대단한 분이라고 한다...Autoencoder는 generative model인가?variational auto-encoder는 generatiev model이니까