Open Domain Question Answering(ODQA)
앞선 MRC와는 다르게 웹 전체, 혹은 위키피디아 전체와 같이 광범위한 Domain에서 Passage retrieval을 수행해야 한다. input, output format은 동일하다.
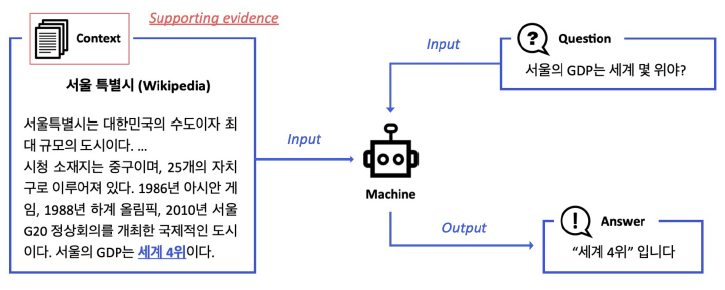
- Context가 따로 주어지지 않는다.
- World Knowledge에 기반해서 QA 진행
- Modern search engine들이 여기에 해당.
- 연관 문서들뿐만 아니라 연관된 answer들도 제공.
History of ODQA
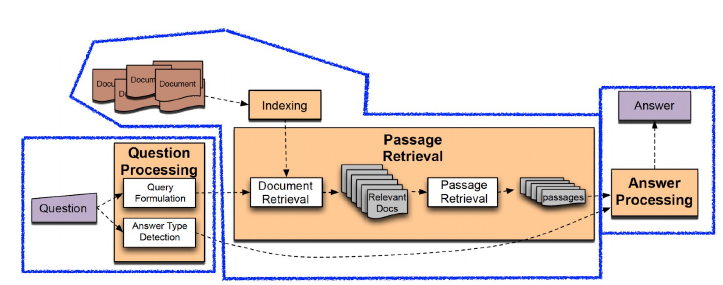
Text retrieval conference(TREC)에서 다뤄진 QA Tracks(1997-2007)에서 ODQA의 형태를 띈 task를 연구.
Question Processing, Passage retrieval, Answer processing으로 이루어지는 것은 현재의 구조와 매우 유사하다. 단순한 Information retrieval(IR)이 아니라 short answer with support를 목표로 했다고 한다. support가 의미하는 것은 답이 담겨 있는 문서를 의미한다. 즉, Question에 대한 답과 해당 문서를 함께 반환하길 원하는 task다.
Question processing
DL, ML model이 발전되지 않았기 때문에 질문으로부터 키워드를 선택하고, 해당 키워드에 대한 answer type selecting을 진행하는 형태였다.
Passage retrieval
현재 ODQA와 매우 유사하다.
1. 기존 IR을 이용해 연관된 document 추출
2. document를 passage 단위로 자르고 선별
3. Named entity, passage 내 question 단어 개수 등의 hand-crafted features 활용해 선별. e.g.,) TF-IDF, BM25
Answer processing
Hand-crafted features와 heuristic을 활용한 Classifer를 통해 주어진 Question에 대해서 어떤 document가 사용될지 결정.
최근의 MRC가 passage 뿐만 아니라 span level에서 답을 도출하기에 answer processing에서는 현재와 차이가 있다.
Recent ODQA Research
Retriever-Reader approach
앞선 MRC에서 활용했던 Retriever와 Reader(MRC model)을 활용해서 ODQA를 해결할 수 있다.
- Retriever: DB에서 관련 있는 문서를 검색
- input: document corpus, query
- output: document
- Train
- TF-IDF, BM25: labeling data 사용 안하고 self supervised learinig
- Dense: QA Dataset을 통해 train
- Reader: 검색된 문서에서 질문에 해당하는 답 도출
- input: Retrieved documnet, query
- output: answer
- Train
- SQuAD와 같은 MRC Dataset으로 학습
- Distant supervision을 통해 학습 데이터 추가 가능
Distant supervision
Quesition, Answer만 존재하는 dataset들은 answer가 어느 document에 존재하는지 알려주지 않는다.
e.g., CuratedTREC, WebQuestions, WikiMovies
하지만 Reader를 학습하기 위해서는 question, answer 외에 document가 필요하다! 따라서 supporting document가 필요한 경우 직접 answer가 어디에 위치하는지 찾아야 한다. 이러한 행위를 distance supervision이라고 한다.
- Retriver를 이용해 관련성이 높은 문서 검색
- 필터링을 한다.
(ˉ﹃ˉ) 너무 짧고 긴 문서, 질문의 고유명사를 포함하지 않는 문서 제거
(ˉ﹃ˉ) answer가 exact match로 들어있지 않는 문서 제거 - 필터링되고 남은 문서들 중 사용 단어를 기준으로 하여 연관성이 가장 높은 단락을 supporting evidence로 사용
Inference
- Retriever
- 질문과 가장 관련성이 높은 5개 문서 출력
- Reader
- 5개 문서를 읽고 답변 예측
- Reader의 예측 답변 중 가장 score가 높은 것을 최종 답으로 사용
Issues, Recent Approaches
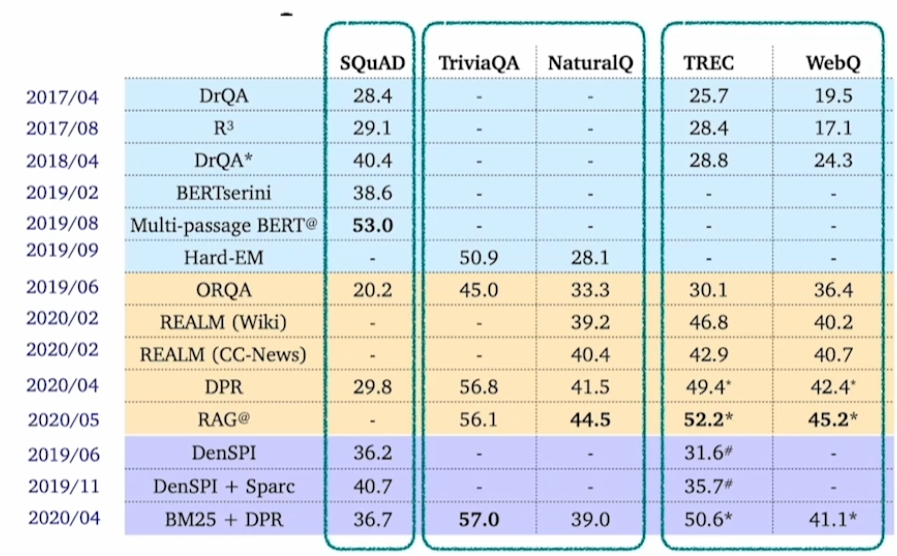
Different granularities of text at indexing time
Wikipedia 데이터를 사용한다고 할 때, 어떠한 기준으로 index를 정의할지 사전에 정의해야 한다. 보통 article, paragraph, sentence를 기준으로 한다.
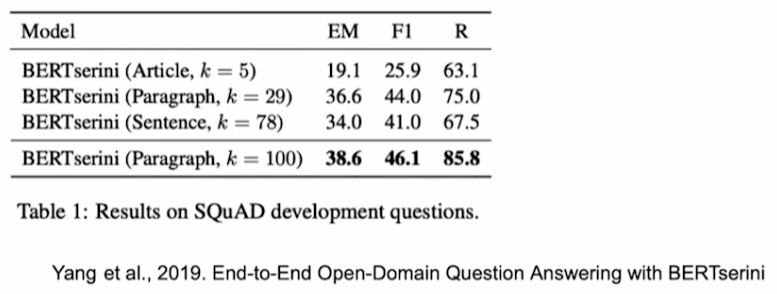
따라서 Retriever는 top-k를 정의할 때, granularity에 따라 k가 달라지게 된다. 보통은 위 표와 같이 k를 정의하게 된다. 또한 granularity에 따라서 점수도 약간식 차이가 발생한다.
k를 늘릴 때 보통 성능이 향상되지만 아닌 경우도 존재한다. MRC 대회에서는 k를 튜닝하는 것도 관건이다.
Single passage training & Multi-passage training
Single-passage training
지금까지 배운 방식이다. Retriever는 k개의 문서를 반환하고 Reader는 k개의 문서에 대한 답변과 점수를 구해 최선의 답을 구하는 방식이다. 여러 개의 문서를 보지만 결국 reader의 관점에서는 passage를 개별적으로 보기 때문에 single passage training이라고 한다. Retriever가 건네준 문서들 간의 상관관계를 고려하지 않기 때문이다.
Multi-passage trainig
Retrived passage 전체를 하나의 passage로 간주하는 것이다. single-passage 방식과는 다르게 전체 passage 간의 관계를 고려해서 Reader를 학습시키고자 한다.
학습 문서가 매우 길어지므로 GPU cost가 커진다.
Importance of each passage
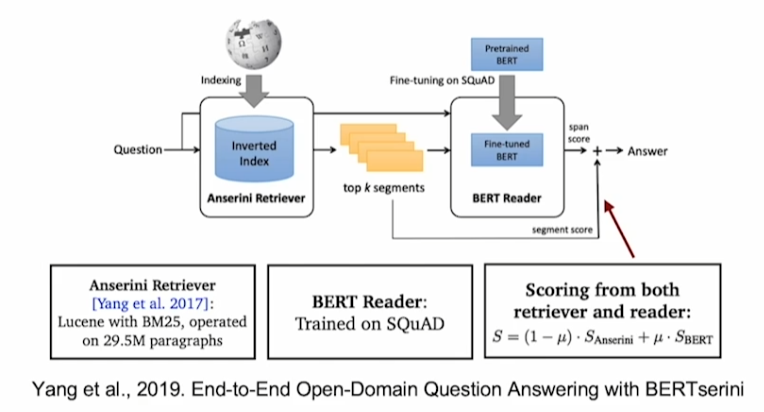
Retriever에서 얻은 Passage들의 score를 버리지말고 최종 score를 얻을 때 활용하고자 하는 방법론이다.
