MRC
1.MRC

기계독해. Machine reading comprehension.주어진 지문(context)를 이해하고, 질의(Query/Question)의 답변을 추론하는 task.최종적으로는 train에 사용한 MRC Dataset에 존재하지않는 QA에 대해서도 외부 데이터를 활용
2.Unicode, Tokenization

e.g., U+AC00'U+': unicode를 뜻하는 접두어'AC00': 16진수 code pointord: character to unicode code pointchr: unicode code point to character완성형 한글 11,172자len을 적용
3.Extraction-Based MRC
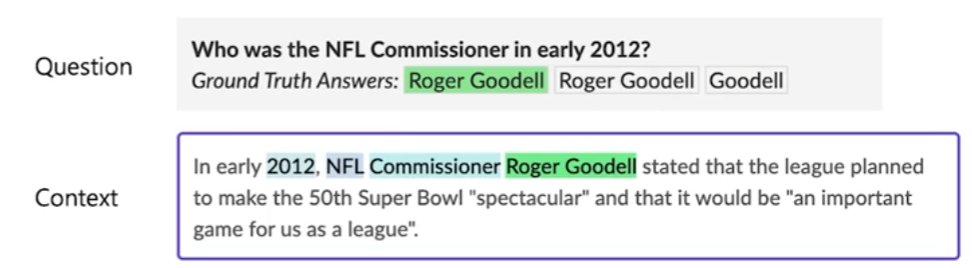
질문의 답변이 항상 주어진 지문(context)내에 span으로 존재.답변을 생성하지 않고 답변을 context에서 찾는 것으로 문제를 좁힐 수 있다.e.g.,) SQuAD, KorQuAD, NewsQA, Natural Questions이러한 dataset들은 Hugg
4.Generation-based MRC
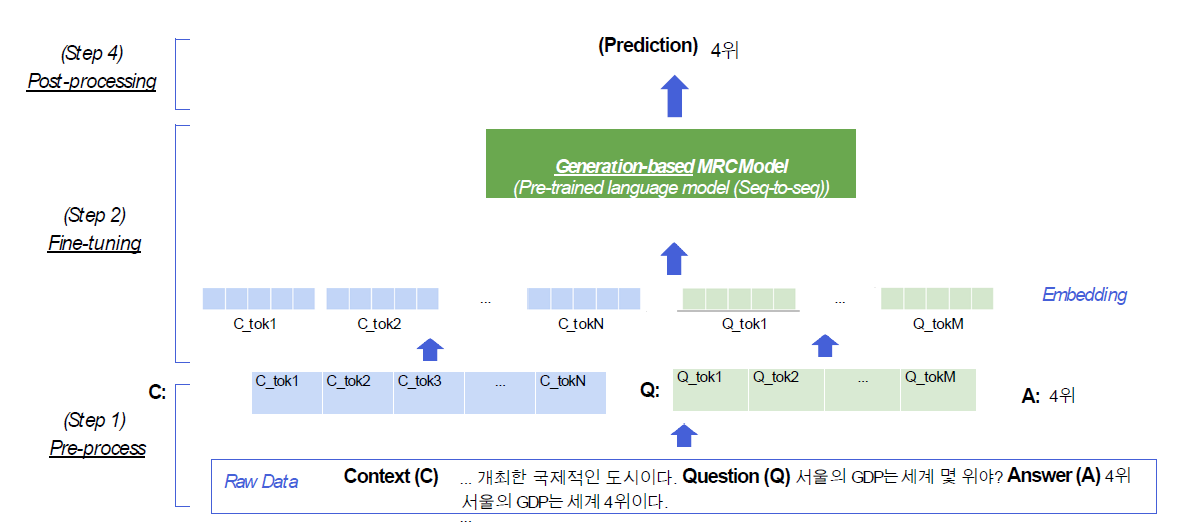
context와 question을 보고 답변을 생성하는 task.Extraction-based MRC가 context의 token별로 정답 확률을 추출했다면, Genration-based는 이름처럼 Generation task다.즉, Extraction-based MR
5.Passage Retrieval
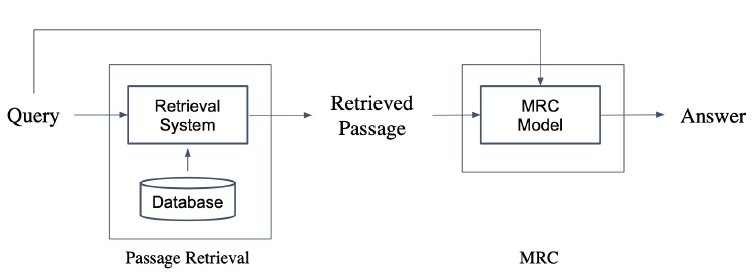
Passage Retrieval query에 맞는 문서(Passage)를 검색(Retrieval)하는 것.
6.Dense Embedding
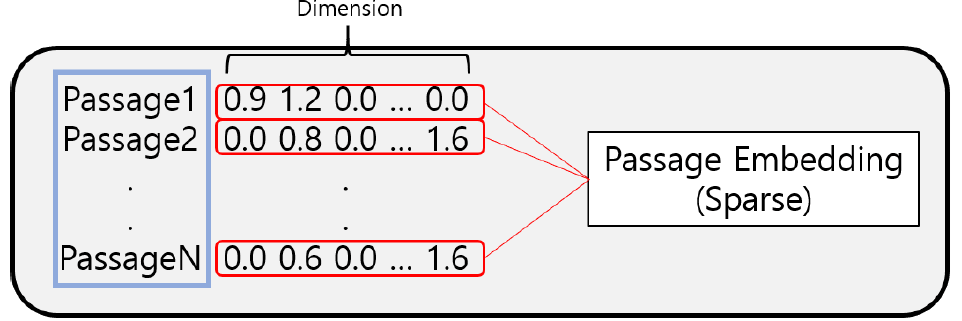
Passage Embedding 중 Spare Embedding은 보통 90% 이상의 벡터값들이 0이다.차원의 수가 매우 크다.compressed format으로 극복 가능유사성을 고려하지 못한다.매우 유사한 단어라도, character가 달라지면 전혀 다른 차원으로
7.Passage Retrieval - Scaling up
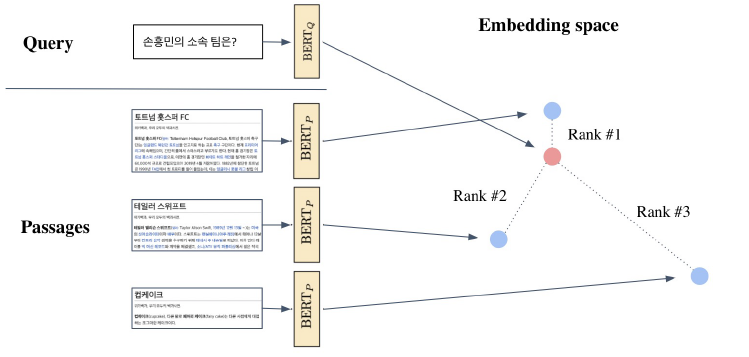
Passage retrieal and Similarity Search Approximating Similiarity Search FAISS
8.Linking MRC and Retrieval
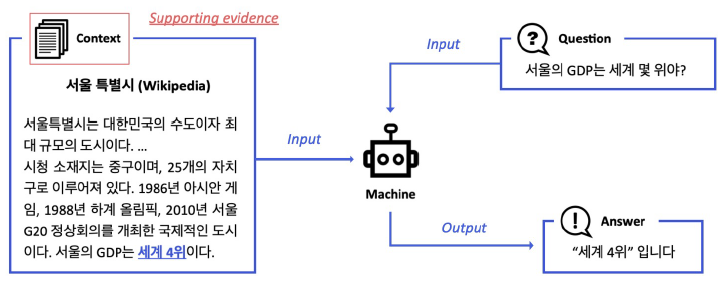
앞선 Passage retrieval과 다르게 웹 전체, 혹은 위키피디아 전체와 같이 광범위한 Domain에서 Passage retrieval을 수행해야 한다. Context가 따로 주어지지 않는다. World Knowledge에 기반해서 QA 진행Modern sear
9.Reducing Training Bias
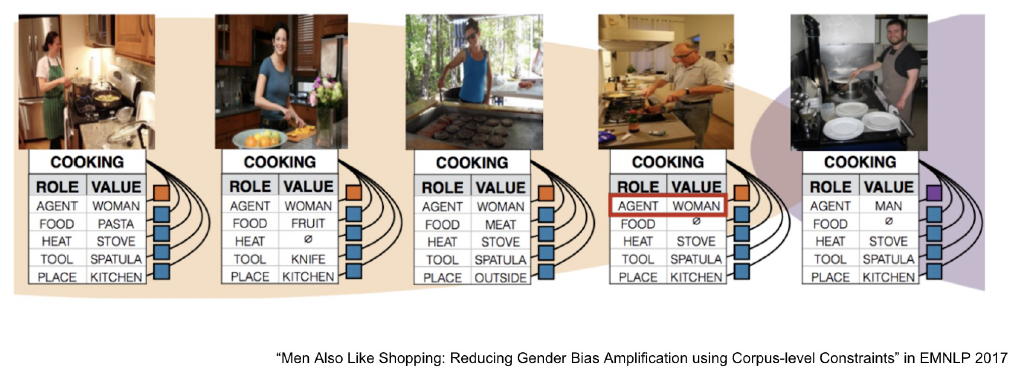
Bias는 지양대상이 아니다. 하지만 일부 bias로 인해 모델의 성능에 악영향을 끼치는 경우가 있고, 이러한 bias issue는 해결해야 한다.ML/DLinductive bias(ref)학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추
10.Negative in-batch
query batch는 기존대로 유지한다. passage batch가 달라진다.1개의 positive passage와 batch_size개의 negative passage로 총 batch_szie + 1 개의 데이터로 하나의 batch를 구성한다.passage batc
11.QA with Phrase Retrieval
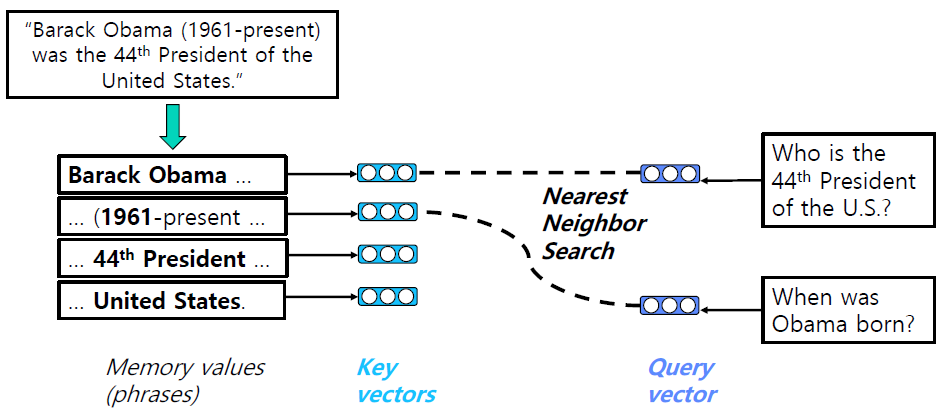
Error propagationReader가 아무리 뛰어나도 Retreiver가 제대로 된 context를 전달하지 못한다면 전체 프로세스의 성능이 떨어진다.Query-dependent encdoingquery에 따라 answer span의 encoding이 달라진다.