
네트워크 장비
Repeater(중계기)
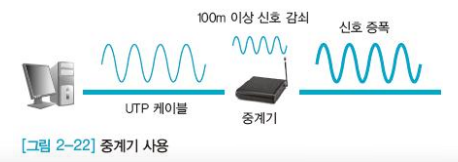
- 접속시스템의 수를 증가시키거나 네트워크 전송 거리를 연장하려고 사용하는 장치
- 장거리로 전송하면 신호가 약해지거나 감쇠되는데 중계기는 노드 사이의 케이블에서 신호를 증폭시켜 문제를 해결한다
- 1계층(Physical Layer)에서 사용된다
허브(hub)
- 여러대의 컴퓨터를 손쉽게 연결하는 장치
- 2계층(Data link Layer)에서 사용된다
더미허브
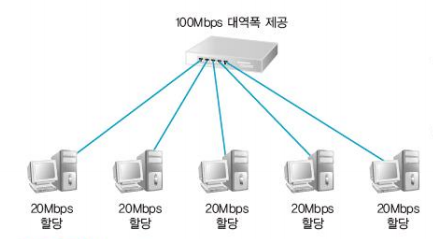

- 더미허브에 입력되는 모든 데이터를 연결된 모든 포트에 복제해서 한번에 보낸다 -> 느리다
- 특정 포트에만 연결된 pc에만 전송되는게 아니라 포트에 연결된 모든 pc에 전송된다 -> 정보의 노출 우려
- 실무에서는 잘 사용되지 않는다
스위치허브
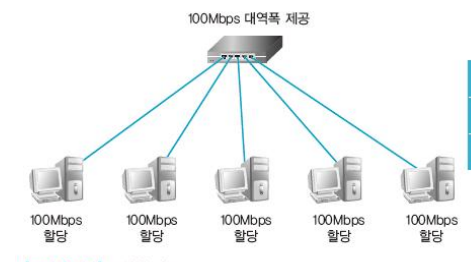
- 한번에 보내는게 아니라 하나씩 보낸다 = 빠르다(더미허브의 속도가 느려지는 단점 보완)
- 더미허브와 마찬가지로 정보의 노출 우려가 있다
스위치
- 컴퓨터에 할당되는 대역폭을 극대화 시켜준다
- 2계층(Data link Layer)에서 사용된다
- MAC Address Table을 가지고 있다
- PC1이 Broadcast(ARP)로 PC2의 MAC을 알아온 후 스위치에게 PC2의 MAC정보를 전달 -> MAC Table을 이용하여 해당 Ethernetport로 스위치해서 전달
- 모든 포트에 1/n로 전달하는 것이 아니라 특정 포트에만 전달하기에 속도 저하를 줄인다
- 정보의 노출 우려가 적다
-> 토폴로지 구성에 사용됨 = 네트워크 망 구성
📒 스위치는 보통 star구조에 사용 - 여러대의 스위치가 서로 연결되어있을 때 특정 스위치에 MAC Table에 없는, 즉 모르는 대역폭의 트래픽이 들어오면 다른 스위치에 물어보는데 이것은 불필요한 로직을 발생시킨다
(Ring 구조 무한루프= Broadcast storm)
-> VLAN : 각 스위치마다 임의로 IP주소를 설정해 스위치가 특정 대역폭만 사용하게 하여 만약 모르는 대역폭의 트래픽이 들어와도 다른 스위치에 물어보지 않는다.
-> STP프로토콜 설정을 통해 무한루프같은 불필요한 로직을 방지한다.
라우터
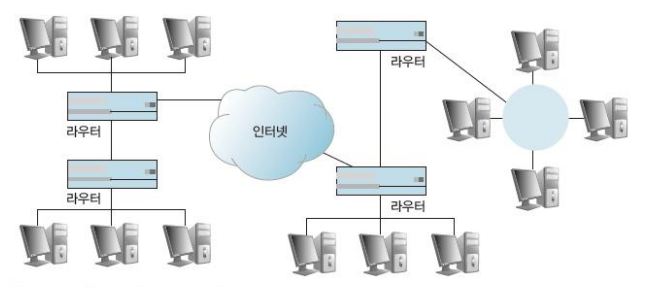
- 서로 구조가 다른 망을 연결할 수 있는 장비로 LAN,MAN,WAN을 구성하는데 사용된다.
- IP를 바탕으로 수신지까지 갈 수 있는 최적의 경로를 검사하여 효율적인 경로를 선택하는 라우팅 기능이있다.
-> 동적라우팅 : 주변 라우터와 상호작용을 통해 주기적으로 경로를 자동 갱신한다.
📒 RIP,OSPF,EIGRP,BGP 프로토콜이 있다.
📕 BGP : 장비와 장비사이에 사용하는 라우팅 프로토콜
-> 정적라우팅 : 수동으로 경로를 입력한다
ROM : 전기신호가 끊겨도 정보가 유지된다
RAM : 전기신호가 끊기면 정보가 소실된다
ROUTER는 NVRAM을 탑재한 EEPROM을 가진다
RAM에 정보들을 NVRAM에 저장하면 EEPROM에 기억됨
- running-config : 동작중에 수정한것(runnig-config)는 RAM에 반영 , 껏다키면 사라짐. 따라서 저장하기위해서는 NVRAM에 반영해야함
- startup-config : 부팅했을때 RAM에는 아무정보가 없고 NVRAM에 있는 정보(Startup -config)가 RAM으로 반영된다
packet tracer
📒 패킷트레이서에서 라우터 누르고 CLI누르면 prompt창이 뜬다
Router> : user Exec mode
Router# : privileged Exec mode (enable로 접속)
Router(config)# : Global configuration mode(conf-t로 접속)
- Router(config-if)# : interface
-> ex) interface fastethernet 0/0
-> ip address 192.168.100.10 255.255.255.0
-> no shutdown
= 해당 인터페이스에 정적IP부여- Router(config-router)# router
-> ex) router rip (동적 라우팅)
-> version 2
-> network 192.168.10.0- ip route 네트워크ID, 마스크, next-hop (정적 라우팅)
-> 하나의 라우터가 통신가능한 모든 네트워크에 대해 다 설정해줘야 함- show ip interface brief : 인터페이스 상태 간략하게 보기
- show run : 지금까지 입력한 명령어 보기
- copy running-config startup-config : running-config정보를 startup-config에 저장 = 라우터를 껏다켜도 정보 유지
- 📒 tab키로 자동완성
클라우드 환경에서 라우팅(VPC)
게이트웨이
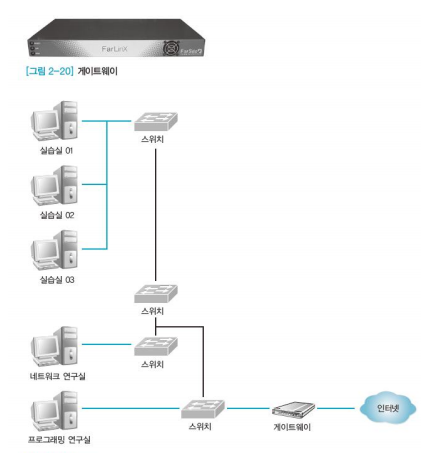
- 종류가 다른 두개 이상의 네트워크를 상호 접속하여 정보를 주고받을 수 있는 장비
- 브리지와 달리 서로 다른 프로토콜 통신망 간에도 프로토콜을 변환하여 정보를 주고받을 수 있다.
브리지
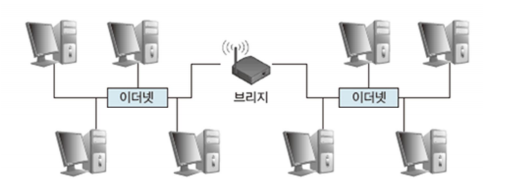
- 두 개 이상의 근거리 통신망을 연결하여 하나의 네트워크로 만들어 주는 장치로, 수신지 주소에 따라 특정 네트워크 트래픽만 통과시킬 수 있도록 설계된 특수한 형태의 스위치다.
- 근거리 통신망에서 하나의 노드가 데이터를 송신할때 다른 노드도 송신하면 충돌이 발생하는데 이처럼 네트워크에 노드수가 늘어나면 충돌 발생확률이 높아지고 통신속도도 저하되는데 이것을 브리지로 해결할 수 있다.
DNS
- 전세계 Domain요청을 하나의 네임서버에 요청하면 과부하 발생 - > 서버를 여러대로 나누어서 처리(로드밸런서 사용)
-
DNS작동 순서 : domain cache확인 -> hosts확인 -> 등록된 dns정보 확인 -> 없으면 외부로 질의한다(root,1차/2차dns)
-
실제 나의 PC의 domain cahche 확인
- ipconfig /displaydns
-
실제 hosts 확인
- window : C:\Windows\System32\drivers\etc\hosts
- linux/unix : /etc/hosts
-
등록된 DNS 정보 확인
- nslookup
- server
- server 8.8.8.8
=> dns를 8.8.8.8로 바꿔서 도메인이 있는지 확인
-
정방향 조회 : domain을 이용해서 ip를 호출
ex) nslookup yahoo.co.kr -
역방향 조회 : ip를 이용해서 domain을 호출
-
재귀 질의(쿼리) : 돌고 돌아(순환 질의) 찾은 도메인을 나이게 보여줌
= 우리 눈에는 재귀 질의만 보인다.
ex) nslookup yahoo.co.kr -
순환 질의(쿼리) : 도메인을 찾는 과정에서 해당 dns에 도메인 정보가 없다면 root에게 물어보고 root는 1차 dns에게 물어보고 1차 dns는 2차 dns에게 물어보는 이런 순환 형태를 말한다.
= 재귀 질의 결과를 주기위해 열심히 찾는 과정(눈에 안보임)
ex) 만약 kt에게 yahoo.co.kr도메인을 물어봤다면 kt의 dns는 모르기때문에 root서버들에게 물어본다. root서버는 kr을 가진 1차네임서버(dns)에 물어본다. yahoo.co.kr을 찾은 dns는 결과를 요청자에게 전달한다
📒 PC나 DNS서버에서 도메인 요청이 들어올때마다 계속 순환질의를 하는 것은 낭비다 -> domain cache사용
📒 root네임서버는 1차네임서버(.kr, .com , .net)를 가지고 있다.
💡 nslookup naver.com하면 ip가 4개가 나오는데 이것은 dns를 여러개의 서버로 나누기 위함이다. 여러개의 서버에 트래픽을 LB가 균등하게 분산시킨다
많은 레거시 (온프레미스)환경의 회사가 DNS서버를 가지는 이유
- 복잡한 개별 주소 체계를 회사 이름 또는 서비스 종류에 따른 키워드로 네이밍을 할 수 있음
- 네트워크 별 요청 분리 및 커스텀 된 DNS운영 가능
- 네트워크 트래픽 다운사이징
-> 처음 요청할때 밖으로 나가서 Root네임서버로부터 순환질의를 한다. 이후 자체적인 DNS에 정적캐시로 일정기간동안 학습해서 가지고 있는다.
-> 이후 모든 DNS요청은 정적캐시기간동안 밖으로 나가지 않고 내부에서 처리가능 = 속도가 매우 빨라짐
📒 레거시 시스템(Legacy System) == 온프레미스(on-premise) <--> 클라우드
📒 레거시 시스템 = 지금 시스템 기준으로 옛날 시스템
클라우드 환경의 DNS 운영
- Iaas경우 내부 서버 운영 방식에 따른(클러스터, 이중화, 백업정책 등) DNS 서버 운영 가능
- Paas경우 대부분 web+db 형태의 단순 운영이다 보니 CSP에서 제공하는 외부 DNS서비스를 이용
디렉토리 서비스(LDAP,AD)
- 네트워크 망 분리 - 서로 다른 네트워크에 서버가 존재
📒 네트워크가 다르면 대역폭도 완전히 다르다 - 중앙집중적인 관리를 통해 내부 사용자가 적법한 권한을 부여받아서 자원(파일,디렉토리)에 접근하고 공유하는 서비스
- AD : MS
- LDAP : Linux
추가정보
- 호스팅 업체 : 서버 컴퓨터의 전체 또는 일정 공간을 이용할 수 있도록 임대해 주는 회사 , 비용을 지불하면 웹서비스 할 수 있게 해줌 (Pass랑 비슷)
📌 코드만 준비해가면 호스팅 업체에서 세팅 후 서비스 제공
EX) 작은 웹사이트 하나 운영하려하는데 항온항습기(HVAC 시스템)과 서버에 기타 이것저것 너무 많이 필요하다.
-> 호스팅업체는 환경을 구성, 세팅 후 가져온 코드만 연결해줌
💡 HVAC : Heating(난방), Ventilation(환기), Air Conditioning(공기 조화)
-
IDC : 서버, 네트워크,운영,모니터링, HVAC등을 다 지원해줌 (Iaas랑 비슷)
-
DR, DRP : BCP안에 기업이 재해 발생시 복구계획을 미리 짜놓는 것
-
SK IDC센터에 입주한 카카오 화재가 발생했을때
카카오도 DR플랜이 있긴했지만 한번도 경험해보지 못했기 때문에 실제 상황에 적용을 못시켰다 (화재는 산소제거로 해결) -
클러스터링 : 자원/작업을 묶어서 수행
-> 묶어서 수행하는 이유 : 재해복구 성능을 극대화하기 위해- 디스크 클러스터 : raid lvm
-> 직렬연결 : 현재 사용 x
-> 병렬 연결 : 여러 디스크의 모터들이 동시에 동작한다. 그러나 하나라도 죽으면 전체 다 죽는다.
-> raid : 클러스터 기술로 디스크를 묶어서 사용
-> lvm : 논리적인 디스크 공간을 붙여서 사용
=> 디스크 용량 늘림, 가용성을 높이고, 장애대응 - 랜카드 클러스터 : bonding, teaming, ether cahnnel
-> 높은 대역폭을 확보, 로드밸런스, Fail over로 통신유지 - CPU 클러스터 : HPC
->연산처리하는 기능을 묶어서 처리 = 슈퍼 컴퓨터 - 네트워크 클러스터 : L4스위치
- 디스크 클러스터 : raid lvm
-
L4스위치 : 이중화를 통해서 네트워크 HA(고가용성)를 구현하고 통신의 LB를 꾀함
ex) Active가 재해가 발생하면 fail over로 Passive로 트래픽 옮기고 극복할 때 까지 버팀 -> 복구가 되면 다시 원래로
fail back(돌아가기)한다.- 서버클러스터 : L4스위치로 구현된 공간에서 클러스터링 된다
