내장함수
단일행함수(문자함수, 와 다중행함수로 나뉜다.
문자 함수
- 대소문자 변환 함수
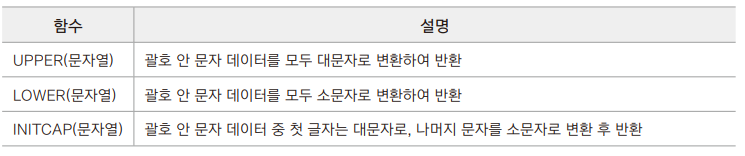
- 예제
SELECT ENAME, UPPER(ENAME), LOWER(ENAME), INITCAP(ENAME)
FROM EMP;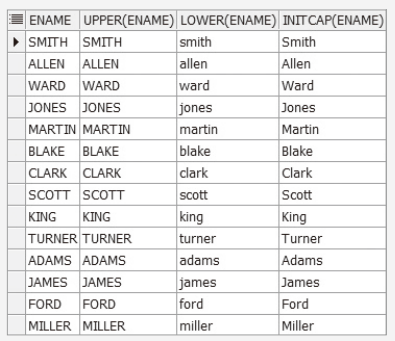
- 응용:일괄적으로 대문자, 혹은 소문자로 바꾸고 =이나 LIKE 등을 사용하여 비교한다.
- 예제1
SELECT *
FROM EMP
WHERE UPPER(ENAME) = UPPER('scott');- 예제2
SELECT *
FROM EMP
WHERE UPPER(ENAME) LIKE UPPER('%SCOTT%');
- LENGTH 함수: 문자열 길이 구함
- 예제1
SELECT ENAME, LENGTH(ENAME)
FROM EMP;*예제 2
SELECT ENAME, LENGTH(ENAME)
FROM EMP
WHERE LENGTH(ENAME)>=5;- LENGTHB 함수: 바이트 수를 반환
- 예제
SELECT LENGTH('한글'), LENGTHB('한글')
FROM DUAL;
//DUAL 테이블은 더미 테이블이다.- SUBSTR 함수: 문자열의 일부를 추출
SUBSTR(문자열 데이터, 시작위치, 추출길이)
//문자열의 시작 위치부터 추출길이만큼 추출
SUBSTR(문자열 데이터, 시작위치):
//문자열의 시작 위치부터 끝까지 추출
//시작 위치가 음수라면, 뒤에서부터 센다.- 예제
SELECT JOB, SUBSTR(JOB, 1, 2), SUBSTR(JOB, 3, 2), SUBSTR(JOB, 5)
FROM EMP;- 결과
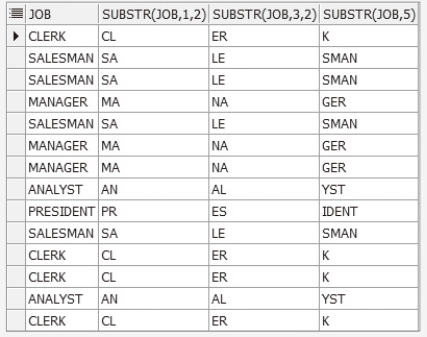
- INSTR 함수: 특정 문자의 위치(인덱스) 찾음
INSTR([대상 문자열 데이터(필수)],
[위치를 찾으려는 부분 문자(필수)],
[위치 찾기를 시작할 대상 문자열 데이터 위치(선택, 기본값은1)],
[시작 위치에서 찾으려는 문자가 몇 번째인지 지정(선택, 기본값은1)])
//인덱스는 1부터 시작. 띄어쓰기도 인덱스에 포함- 예제
SELECT INSTR('HELLO, ORACLE!', 'L') AS INSTR_1,
INSTR('HELLO, ORACLE!', 'L', 5) AS INSTR_2
INSTR('HELLO, ORACLE!', 'L', 2, 2) AS INSTR_3
FROM DUAL;- 결과

- REPLACE 함수 : 특정 문자를 다른 문자로 바꿈
REPLACE(
[문자열 데이터 또는 열 함수(필수)],
[찾는 문자(필수)],
[대체할 문자(선택/디폴트값은 삭제)]
)- 예제
SELECT '010-1234-5678' AS REPLACE_BEFORE,
REPLACE('010-1234-5678','-',' ') AS REPLACE_1,
REPLACE('010-1234-5678','-',) AS REPLACE_2,- 결과

- LPAD, RPAD 함수: 데이터의 빈 공간을 특정 문자로 채움(개인정보 등에 응용 가능)
LPAD([문자열 데이터 또는 열 이름(필수)], [데이터의 자릿수(필수)], [빈 공간에 채울 문자(선택/ 디폴트값 공백)])
RPAD([문자열 데이터 또는 열 이름(필수)], [데이터의 자릿수(필수)], [빈 공간에 채울 문자(선택/ 디폴트값 공백)])- 예제
SELECT 'Oracle',
LPAD('Oracle', 10, '#') AS LPAD_1,
RPAD('Oracle', 10, '*') AS RPAD_2,
LPAD('Oracle', 10, ) AS LPAD_1,
RPAD('Oracle', 10,) AS RPAD_2,
- 결과

- TRIM, LTRIM, RTRIM 함수: 데이터의 빈 공간을 특정 문자로 채움(개인정보 등에 응용 가능)

개발자지망생