LLM 호출 - 트랜잭션 분리 및 비동기 + 폴링으로 히카리 풀 및 톰캣 스레드 풀 고갈 문제 해결 (+ 블로킹 vs 논블로킹 성능 비교 테스트)
[개요]
본 프로젝트는 Spring Boot와 MySQL을 활용한 모의 면접 서비스입니다.
이 글은 모의 면접 진행 과정에서 LLM 호출로 인해 히카리 커넥션 풀과 톰캣 스레드 풀이 고갈되어 다른 API 응답이 수십 초 지연되는 문제를 해결한 과정을 다룹니다. 또한 트랜잭션 분리 과정에서 발생한 토큰 정합성 문제를 분산 락으로 해결한 방법에 대해서도 다룹니다.
마지막으로 비동기 방식에서 LLM 호출 시 블로킹 방식과 논블로킹 방식의 성능을 부하 테스트를 통해 비교 분석한 결과를 제시합니다.
[요약]
LLM 호출로 인한 히카리 커넥션 풀 고갈 문제는 트랜잭션 분리를 통해 해결했으나, 이로 인해 발생한 토큰 정합성 문제를 Redis 분산 락으로 해결했습니다. 톰캣 스레드 풀 고갈 문제는 비동기 처리와 폴링 방식을 도입하여 해결했습니다.
[문제 상황 1 : 히카리 커넥션 풀 고갈]
면접을 진행할 때 사용자의 답변을 받아, LLM으로부터 다음 꼬리 질문을 받습니다.
기존에는 트랜잭션 내부에서 LLM 호출이 이루어졌습니다. LLM 호출은 평균 수초에서 길게는 10초 이상 소요되는 특성상, 이 시간 동안 히카리 커넥션 풀을 지속적으로 점유하게 됩니다.
@Transactional
public Optional<InterviewProceedResponse> proceedInterview(...) {
// ...
decreaseTokenCount(memberId);
LLMResponse llmResponse = bedrockClient.requestToBedrock(questionAndAnswers);
// ...
}히카리 풀 크기는 성능 테스트를 통해 조정해봐도 큰 차이가 없어 기본값인 10개로 설정되어 있었습니다.
이러한 상황에서 동시에 여러 LLM 호출이 발생하면 모든 커넥션을 점유하게 되어, 다른 API의 응답 시간이 수 초 지연되거나 타임아웃으로 인해 실패하는 문제가 발생했습니다.
실제 테스트 결과, 다음과 같이 타임아웃 오류가 발생하는 것을 확인할 수 있었습니다.

✅ [해결 방안 1 : 트랜잭션 분리]
LLM 호출이 히카리 풀을 점유하면 해당 API뿐만 아니라 DB에 접근하는 모든 API가 지연되는 문제가 발생합니다.
이를 해결하기 위해 먼저 LLM 호출 부분을 트랜잭션 밖으로 분리하였습니다.
다음은 간략화한 코드입니다.
// InterviewFacadeService.java
public Optional<InterviewProceedResponse> proceedInterview(...) {
memberService.decreaseTokenCount(memberId);
LlmResponse llmResponse = bedrockClient.requestToBedrock(questionAndAnswers);
interviewService.saveFeedbackAndNextQeustion(...);
}
// MemberService.java
@Transactional
public void decreaseTokenCount(Long memberId) {
// ...
}
// InterviewService.java
@Transactional
interviewProceedService.saveFeedbackAndNextQeustion(...) {
// ...
}파사드 패턴을 통해 LLM 호출 이전과 이후로 트랜잭션을 분리하여 히카리 풀 점유 문제를 해결하였습니다.
하지만 새로운 문제가 발생했습니다. 이를 이해하기 위해서는 먼저 서비스의 배경에 대한 설명이 필요합니다.
[서비스 배경 설명]
LLM 호출 비용이 높기 때문에 토큰 방식을 도입하였습니다.
사용자는 각자 토큰을 보유하고 있으며, 인터뷰 진행 시 토큰을 소모하는 구조입니다.

[문제 상황 1-2 : 토큰 개수 정합성 불일치]
사용자가 동시에 다수의 요청을 보내더라도 중복 LLM 호출을 방지하기 위해, LLM 호출 전에 사용자의 토큰을 먼저 차감해야 했습니다.
예를 들어, 토큰이 1개만 남은 사용자가 동시에 100번 요청을 보낼 경우, 토큰을 사전에 차감하지 않으면 LLM 호출이 100번 모두 발생하게 됩니다.
따라서 인터뷰 진행 프로세스를 다음 순서로 구현하였습니다.
사용자 토큰 감소 → LLM 호출 → LLM 응답 저장
그런데 트랜잭션 분리로 인해 토큰 개수 정합성 문제가 발생했습니다.
사용자 토큰 감소는 성공했으나 LLM 호출이나 LLM 응답 저장에 실패하는 경우, 토큰 감소가 별도 트랜잭션으로 처리되어 롤백되지 않는 문제였습니다.
토큰 개수는 인터뷰 횟수와 직결되는 중요한 데이터이며, 향후 결제를 통한 토큰 구매 기능을 계획하고 있었기 때문에 인터뷰 진행 실패 시 토큰이 부당하게 차감되어서는 안 되었습니다.
❌ [해결 방안 1 : 보상 트랜잭션 적용]
LLM 호출이나 LLM 응답 저장이 실패할 경우, 보상 트랜잭션을 통해 토큰 개수를 다시 증가시키는 방법을 고려했습니다.
public Optional<InterviewProceedResponse> proceedInterview(...) {
memberService.decreaseTokenCount(memberId);
try {
LlmResponse llmResponse = bedrockClient.requestToBedrock(questionAndAnswers);
interviewService.saveFeedbackAndNextQeustion(...);
} catch (Excpetion e) {
memberService.increaseTokenCount(memberId);
}
}하지만 이 방식은 보상 트랜잭션 자체가 실패할 경우 여전히 토큰 개수 정합성이 깨질 수 있는 근본적인 한계가 있습니다.
✅ [해결 방안 2 : 분산 락을 통한 정합성 보장]
LLM 호출 이전에 토큰을 감소시킨 이유는 사용자의 동시 LLM 호출을 방지하기 위함이었습니다.
이를 Redis 분산 락으로 제어하고, 토큰 감소를 LLM 호출 이후로 변경하여 토큰 정합성 문제를 해결하였습니다.
public Optional<InterviewProceedResponse> proceedInterview(...) {
String lockKey = "interview:proceed:" + memberId;
boolean acquired = redisService.acquireLock(lockKey, Duration.ofSeconds(30));
if (!lockAcquired) {
throw new BadRequestException("이미 처리 중인 답변이 있습니다. 잠시 후 다시 시도해주세요.");
}
try {
LlmResponse llmResponse =
bedrockClient.requestToBedrock(questionAndAnswers);
interviewService.saveFeedbackAndNextQeustion(...); // 여기서 토큰 감소
// ...
} finally (Exception e) {
redisService.releaseLock(lockKey);
}
}분산 락을 통해 동일한 사용자가 동시에 여러 LLM 호출을 수행하지 못하도록 제어했습니다.
이 방식을 통해 LLM 호출 실패 시에도 토큰이 부당하게 차감되지 않으며, LLM 응답 저장과 토큰 감소가 하나의 트랜잭션으로 묶여 토큰 정합성이 보장됩니다.
[문제 상황 2 : 톰캣 스레드 풀 고갈]
히카리 풀 점유 문제는 해결되었지만, 톰캣 스레드 풀을 장시간 점유하는 새로운 문제가 발생했습니다.
프로덕션 서버의 CPU 코어가 2개인 환경에서 성능 테스트를 통해 톰캣의 max-threads 값을 30으로 설정한 상태였습니다.
실제로 LLM 호출 API를 동시에 100회 요청하는 테스트를 진행한 결과는 다음과 같습니다.
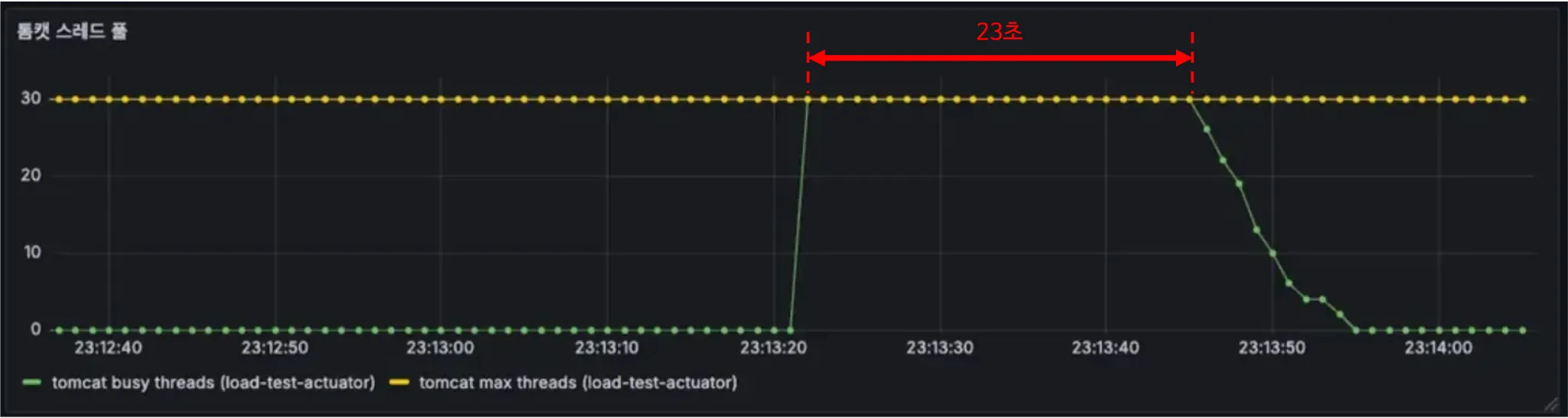
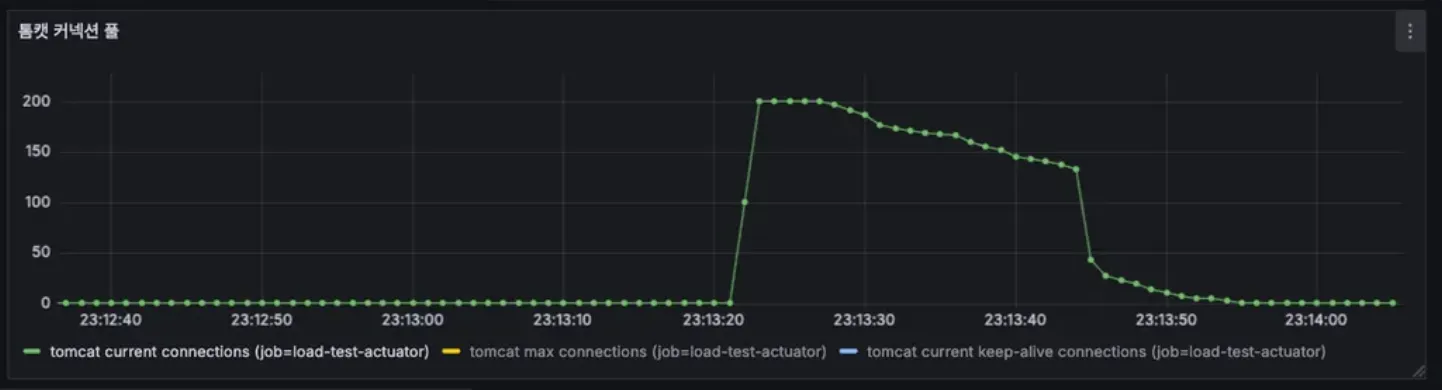
LLM 응답이 도착할 때까지 톰캣 스레드를 점유하여 약 23초 동안 스레드 풀 전체가 고갈되는 것을 확인할 수 있었습니다.
이를 검증하기 위해 DB 접근이 없어 평소 1ms 정도 소요되는 가벼운 API를 2초 후에 호출해본 결과, 약 22초간 대기하는 현상이 발생했습니다.
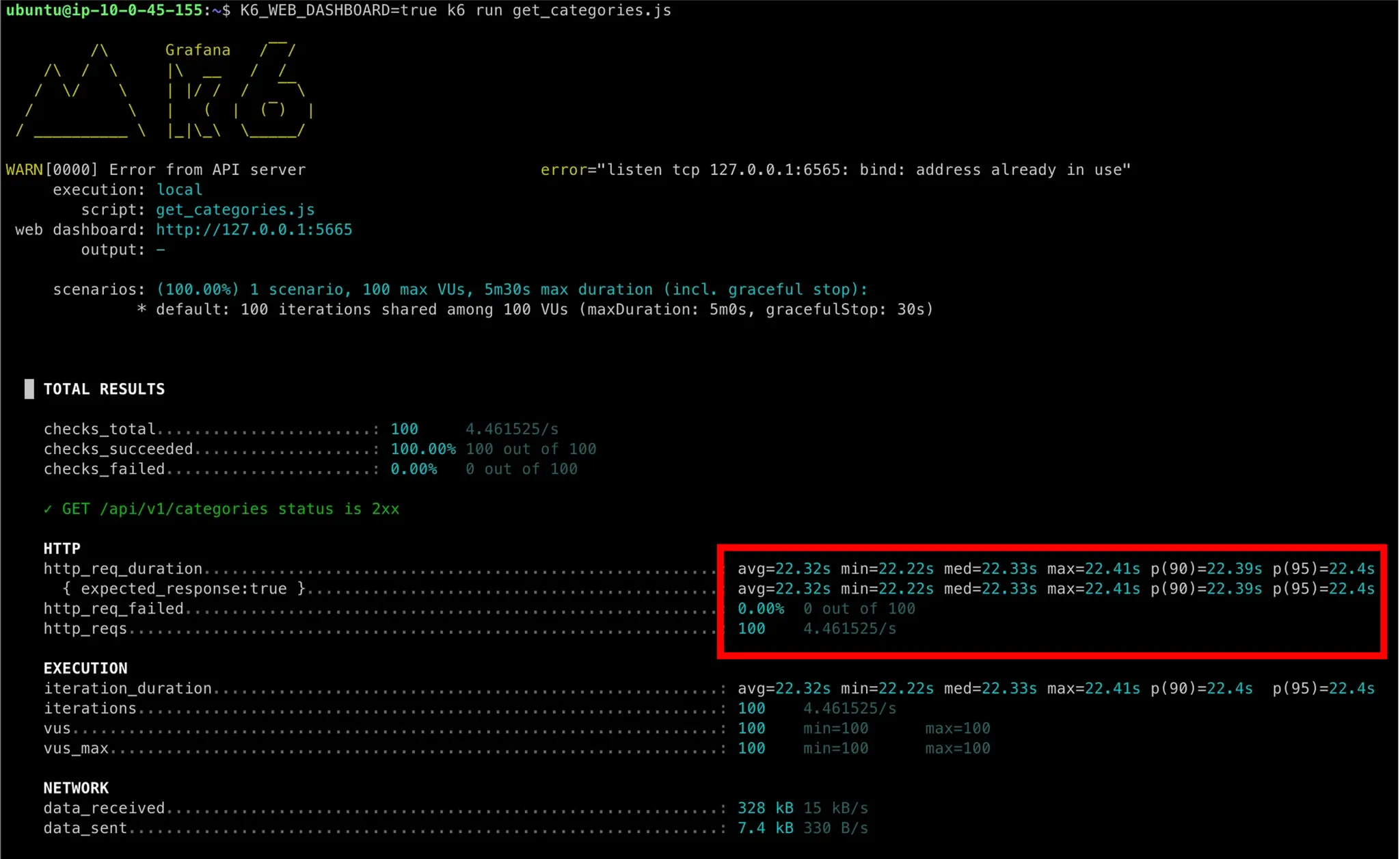
LLM 응답이 23초에 71번째로 도착하는 순간 톰캣 스레드 하나가 해제되고, 그때부터 대기 중이던 API가 처리되는 것을 확인할 수 있었습니다.
✅ [해결 방안 3 : @Async + 폴링]
톰캣 스레드 풀 점유를 방지하기 위해 LLM 호출을 비동기로 전환하기로 결정했습니다.
@Async를 활용하여 LLM 호출을 비동기로 처리하고 클라이언트에게 즉시 응답함으로써 톰캣 스레드 점유 문제를 해결했습니다.
또한 폴링 방식을 통해 클라이언트가 1초마다 LLM 응답 상태를 확인하고, 응답이 완료되면 면접의 다음 질문을 받아오도록 구현했습니다.
// InterviewFacadeService.java
public Optional<InterviewProceedResponse> proceedInterview(...) {
// .. 분산락 로직
try {
interviewViewCountService.proceedInterviewAsync(...);
redisService.setValue(key, "PENDING", Duration.ofSeconds(300));
// ...
return ...; // 빠르게 응답
} catch (Exception e) {
redisService.releaseLock(lockKey);
throw e;
}
}
// InterviewViewCountService.java
@Async("llmExeutor")
public void proceedInterviewAsync(...) {
try {
LlmResponse llmResponse =
bedrockClient.requestToBedrock(questionAndAnswers);
interviewService.saveFeedbackAndNextQeustion(...); // 여기서 토큰 감소
redisService.setValue(key, "COMPLETED", Duration.ofSeconds(300));
} catch (Exception e) {
redisService.setValue(key, "FAILED", Duration.ofSeconds(300));
log.error("Bedrock API 호출 실패 - questionId={}", questionId, e);
} finally {
redisService.releaseLock(lockKey);
}
}LLM 호출을 비동기로 처리하고, 처리 상태를 Redis에서 관리했습니다.
상태 관리를 Redis에서 하는 이유는 예외 발생 시 클라이언트가 상태를 확인할 수 있어야 하고, 서버가 다중화되어 있어 글로벌 캐시가 필요하기 때문입니다.
클라이언트는 폴링을 통해 LLM 응답 상태를 주기적으로 확인합니다.
비동기 전환 후 인터뷰 진행 API의 응답 시간은 다음과 같습니다.
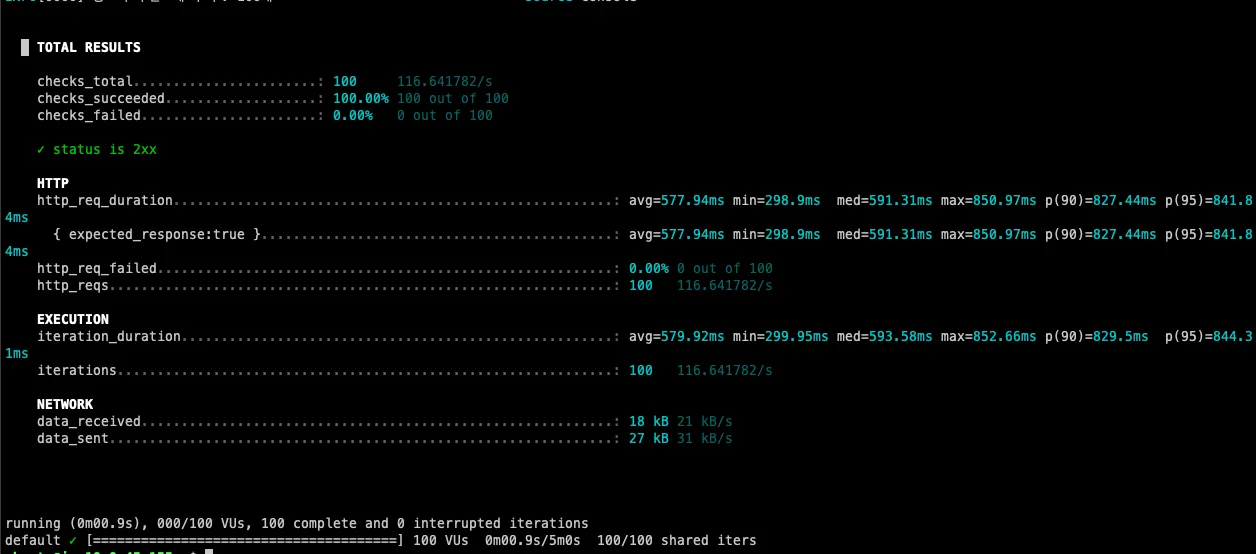
동시에 100개 요청 시 평균 600ms의 응답 시간을 보이며, 톰캣 스레드 풀을 장시간 점유하지 않아 다른 API가 수십 초간 대기하는 문제가 해결되었습니다.
[문제 상황 3 : 비동기 스레드 풀 크기로 인한 컨텍스트 스위칭 비용 증가]
비동기 스레드 풀 사용 시 새로운 문제점이 발견되었습니다.
LLM 호출에서 블로킹 I/O를 사용할 경우, 요청 하나당 비동기 스레드 하나를 점유하는 구조입니다.
따라서 동시에 최대 x개의 요청을 처리하려면 비동기 스레드 풀 크기를 x 이상으로 설정해야 하는데, 이는 thread-per-request 방식이기 때문입니다.
그런데 스레드 풀 크기가 CPU 코어 개수에 비해 과도하게 클 경우 컨텍스트 스위칭 비용이 증가하여 성능 저하가 발생할 수 있습니다. 이는 톰캣 스레드 풀 크기 조정 과정에서 직접 경험한 문제였습니다.
예를 들어 동시에 100개 요청을 처리하려면 비동기 스레드 풀 크기를 100 이상으로 설정해야 하는데, 현재 프로덕션 서버의 CPU 코어가 2개인 상황에서 스레드 풀 크기 100개는 과도한 컨텍스트 스위칭으로 인해 오히려 성능이 저하될 것으로 예상되었습니다.
❌ [해결 방안 4 : 논블로킹 비동기]
이 문제를 해결하기 위해 LLM 호출을 논블로킹 방식으로 처리하는 방법을 고려했습니다.
AWS Bedrock SDK에서 이벤트 루프 그룹을 활용한 논블로킹 방식을 지원하여 다음과 같이 구현했습니다.
// InterviewFacadeService.java
public Optional<InterviewProceedResponse> proceedInterview(...) {
// .. 분산락 로직
try {
CompletableFuture<ConverseResponse> completableFuture =
bedrockAsyncClient.requestToBedrock(questionAndAnswers);
completableFuture.thenAcceptAsync(
response -> callbackBedrock(...),
threadPoolTaskExecutor
).exceptionallyAsync(
ex -> handleBedrockException(...),
threadPoolTaskExecutor
);
redisService.setValue(key, "PENDING", Duration.ofSeconds(300));
// ...
return ...; // 빠르게 응답
} catch (Exception e) {
redisService.releaseLock(lockKey);
}
}CompletableFuture를 통해 LLM 응답 처리 및 Redis 상태를 "COMPLETED"로 업데이트하는 콜백과, 예외 발생 시 로그 기록 및 Redis 상태를 "FAILED"로 업데이트하는 예외 핸들러를 등록했습니다.
논블로킹 방식에서는 이벤트 루프 스레드가 다수의 LLM 호출을 처리하고, 응답 도착 시에만 비동기 스레드가 콜백 메서드를 실행합니다.
콜백 메서드 실행 시간은 LLM 호출 대기 시간보다 훨씬 짧기 때문에, 비동기 스레드 풀 크기를 CPU 코어 개수에 맞춰 작게 설정할 수 있습니다.
이를 통해 컨텍스트 스위칭 비용이 감소하여 훨씬 효율적인 성능을 보일 것으로 예상했습니다.
[성능 테스트 : 블로킹 vs 논블로킹]
논블로킹 방식의 성능 개선 효과를 검증하기 위해 성능 테스트를 진행했습니다.
K6를 활용하여 다음 조건에서 테스트를 수행했으며, 프로덕션과 동일한 환경에서 서버 1대를 대상으로 총 3회씩 테스트했습니다.
- EC2 타입 : t4g.small
- 톰캣 스레드 : 30개
- max connections : 2000개
- 히카리 풀 : 10개
- 블로킹 비동기 스레드 풀 : 100개
- 논블로킹 비동기 스레드 풀 : 20개
- 블로킹 비동기 HttpClient 커넥션 풀 : 1000개
- 논블로킹 비동기 HttpClient 커넥션 풀 : 1000개
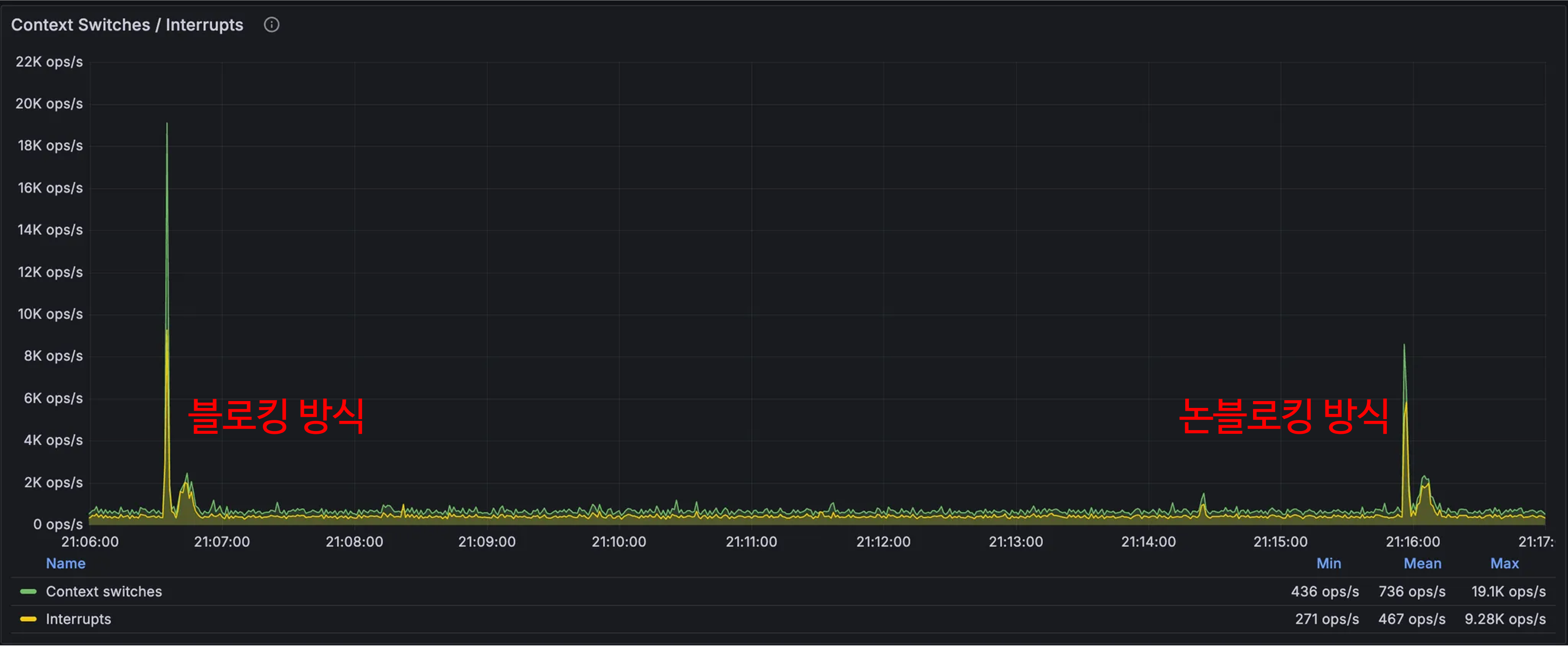
테스트 결과, 컨텍스트 스위칭 비용이 약 2배 정도 차이나는 것을 확인할 수 있었습니다.
그러나 실제 응답 시간에는 큰 차이가 없었습니다.
로그를 통해 요청 시작부터 비동기 스레드 종료까지의 시간을 분석한 결과는 다음과 같습니다.
[블로킹]
- 평균: 8.8초
- 최소: 3.0초
- 최대: 17.8초
- 중앙값 (P50): 8.5초
- P95: 13.3초
- P99: 17.3초
[논블로킹]
- 평균: 9.23초
- 최소: 5.12초
- 최대: 15.65초
- 중앙값 (P50): 9.32초
- P95: 12.56초
- P99: 15.37초
블로킹 방식과 논블로킹 방식 간에 큰 성능 차이가 없었으며, 오히려 논블로킹 방식이 약간 더 느린 결과를 보였습니다.
추가로 비동기 스레드 풀 크기를 1000개로 늘리고 1000개 요청을 동시에 보내는 테스트도 진행했습니다. 이 경우 논블로킹 방식이 약간 더 빠른 성능을 보이기도 했지만, 여전히 의미 있는 차이는 없었습니다. 500개 요청으로 테스트해도 동일한 결과였습니다.
이러한 결과는 암달의 법칙으로 설명할 수 있습니다.
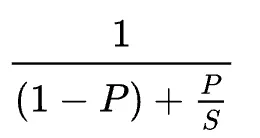
LLM 호출에서는 LLM 응답을 대기하는 시간이 전체 처리 시간의 대부분을 차지합니다. 따라서 컨텍스트 스위칭이 차지하는 비율(P)이 작아, 전체 성능에 미치는 개선 효과가 제한적일 수밖에 없습니다.
즉, LLM 응답 대기라는 순차적 처리 부분이 워낙 큰 비중을 차지하다보니, 병렬 처리 최적화를 통한 성능 향상이 미미하게 나타난 것으로 분석됩니다.
하지만 컨텍스트 스위칭이 다른 API에 미치는 영향은 다를 수 있기 때문에, 단순한 조회 API를 초당 100회씩 요청하는 상황에서 블로킹 방식과 논블로킹 방식을 각각 적용하여 테스트했습니다.
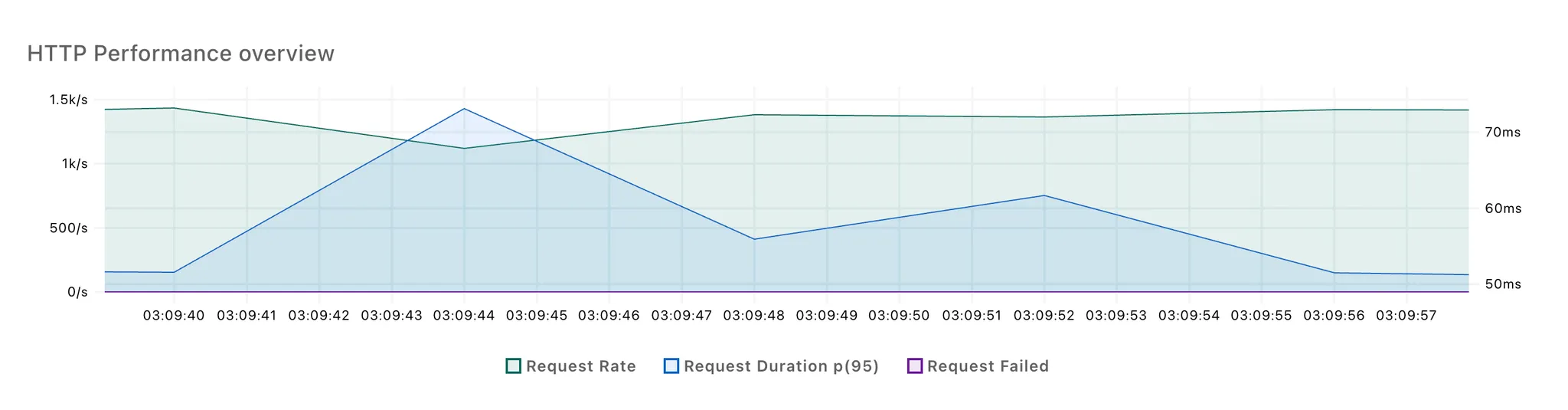
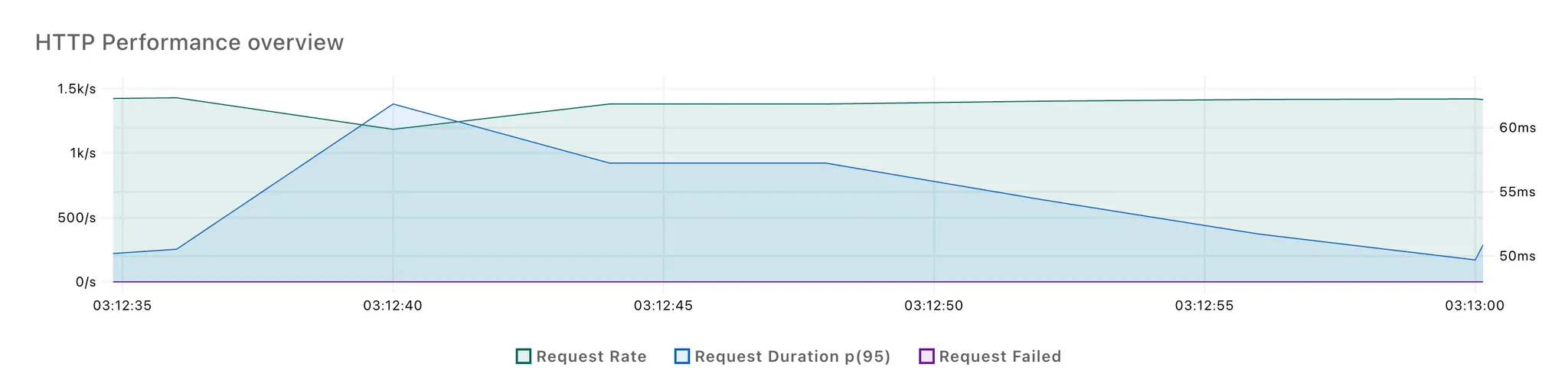
[블로킹 방식]
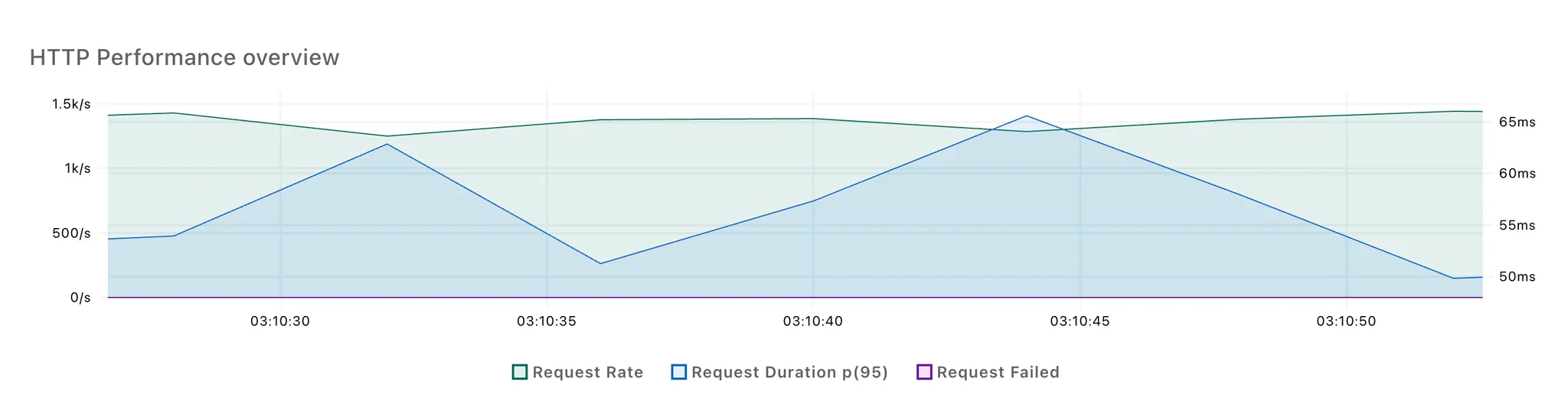
[논블로킹 방식]
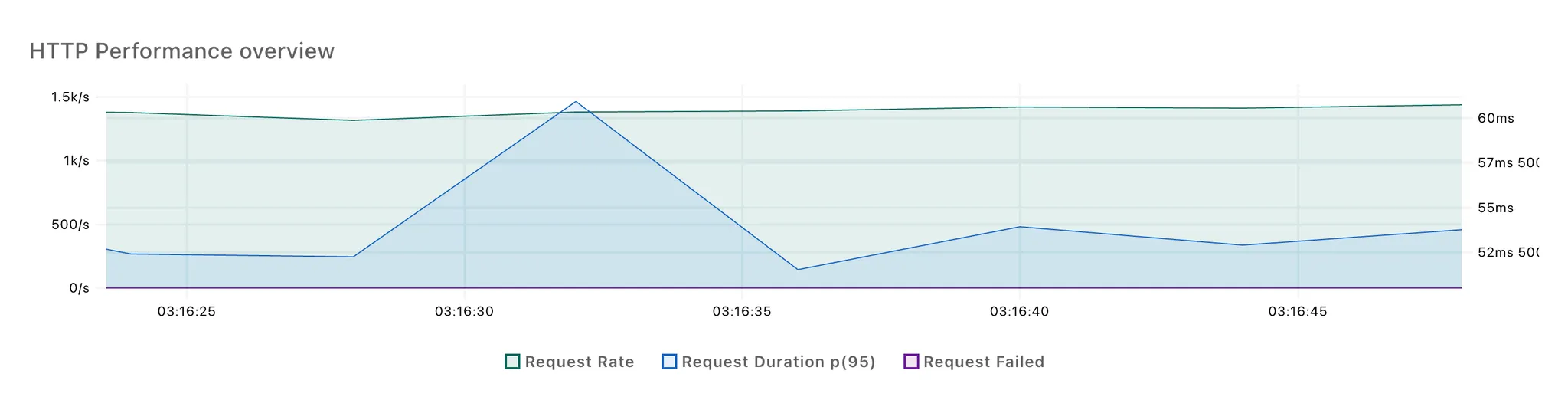
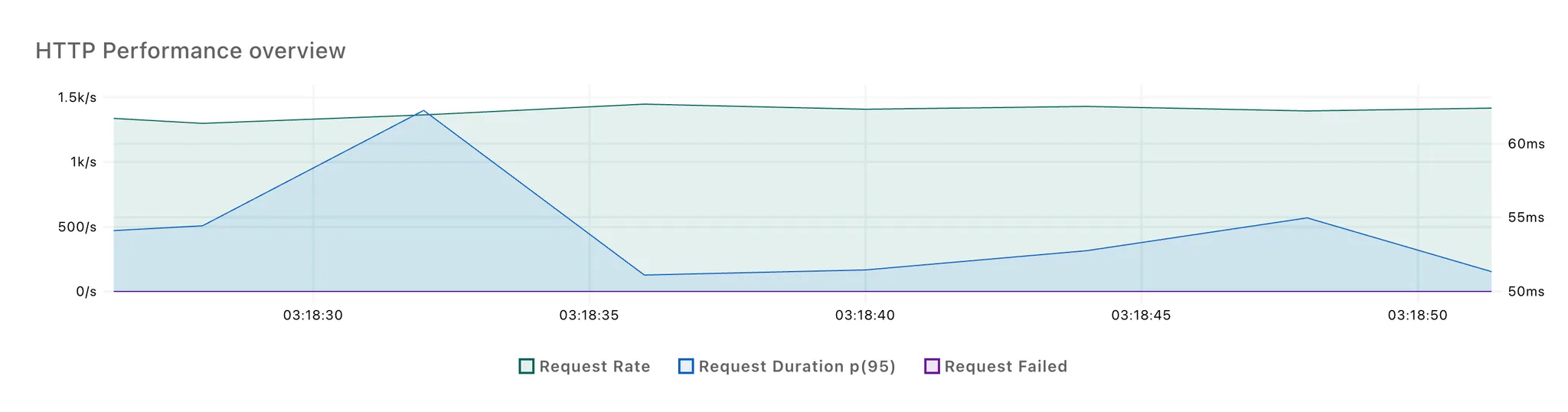
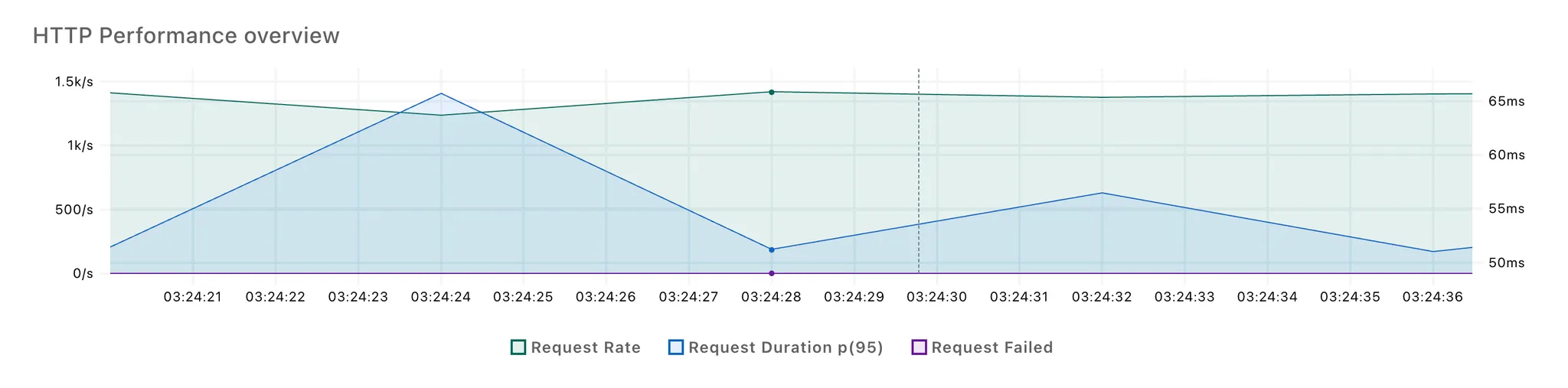
3회 반복 테스트 결과, 각각 2번의 응답 시간 스파이크가 발생했습니다. 첫번째 스파이크는 100개의 요청이 몰리면서 발생한 것으로 추정되고, 두번째 스파이크는 LLM 응답을 처리하면서 발생한 것으로 보입니다.
첫 번째 스파이크는 두 방식 간 차이가 적었고, 논블로킹 방식에서 두 번째 스파이크의 크기가 다소 작은 것을 확인할 수 있었습니다.
논블로킹 방식을 사용해도 성능상 큰 이득을 얻을 수 없었기 때문에, 이벤트 루프 스레드 도입으로 인한 디버깅 및 추적의 복잡성을 감수하지 않고 블로킹 방식을 유지하기로 결정했습니다.
❌ [해결 방안 5 : 롱 폴링 or SSE or WebSocket]
LLM 비동기 요청에 대한 응답을 클라이언트에게 전달하는 방식으로는 폴링 외에도 롱 폴링, SSE, WebSocket 등의 방법이 있습니다.
롱 폴링과 SSE 방식은 기본적으로 톰캣 스레드를 지속적으로 점유하지만, DeferredResult를 활용하면 톰캣 스레드를 점유하지 않고도 응답을 전달할 수 있습니다. WebSocket은 기본적으로 톰캣 스레드를 지속 점유하지 않는 특성이 있습니다.
하지만 LLM 응답이 평균 8초 정도 소요되는 상황에서 1초마다 폴링하는 것은 서버에 큰 부담이 되지 않는다고 판단했습니다. 지속적으로 요청하는 것이 아니라 클라이언트에서 설정한 타임아웃 시간까지만 요청하기 때문입니다.
또한 1초 정도의 지연은 허용 가능한 수준이라고 판단했습니다. 8초의 처리 시간에서 최대 1초가 추가로 지연되더라도 사용자 경험상 큰 차이가 없을 것으로 예상했기 때문입니다.
따라서 구현이 간단하고 유지보수가 용이한 폴링 방식을 선택하기로 결정했습니다.
