빈번한 조회수 업데이트 - Redis write back 패턴으로 조회 성능 개선 (+ fall back 처리)
[개요]
본 프로젝트는 Spring Boot와 MySQL을 활용한 모의 면접 서비스입니다.
이 글은 조회 API에서 조회수를 업데이트할 때 Redis write back 패턴으로 성능을 개선한 사례를 다룹니다. 또한 Redis 장애 상황에 대한 fallback 처리 방법도 함께 설명합니다.
[요약]
매번 DB에 증분 쿼리를 실행하는 대신 Redis에 조회수를 저장하고 주기적으로 DB와 동기화하는 write back 패턴을 도입했습니다. 그 결과 TPS를 84% 개선(186 TPS → 342 TPS)했습니다.
추가로 Redis timeout 설정과 장애 시 DB 직접 조회를 통한 fallback 처리로 조회 API의 안정성을 보장했습니다.
[조회 API 성능을 개선한 이유]
조회수 기능을 구현하는 과정에서 조회 API에 조회수를 업데이트 하는 로직이 필요했습니다. 단순히 다음과 같은 증분 쿼리를 사용해도 되지만 트래픽 급증 시 성능 저하 문제가 있을 수 있습니다.
(JPA의 Dirty Checking은 race condition 때문에 제외하였습니다.)
UPDATE interview SET view_count = view_count + 1 WHERE id = ?MySQL에서 UPDATE 문으로 인해 레코드 락이 걸리기 때문에 같은 interview에 대해 조회 트래픽이 급증하면 X 락 대기로 성능이 저하될 수 있습니다.
특히 조회 API에서 쓰기로 인한 성능 저하 문제는 피해야 한다고 생각했습니다.
[해결 방안]
✅ [Redis write back 패턴]
[Redis 기반 조회수 관리]
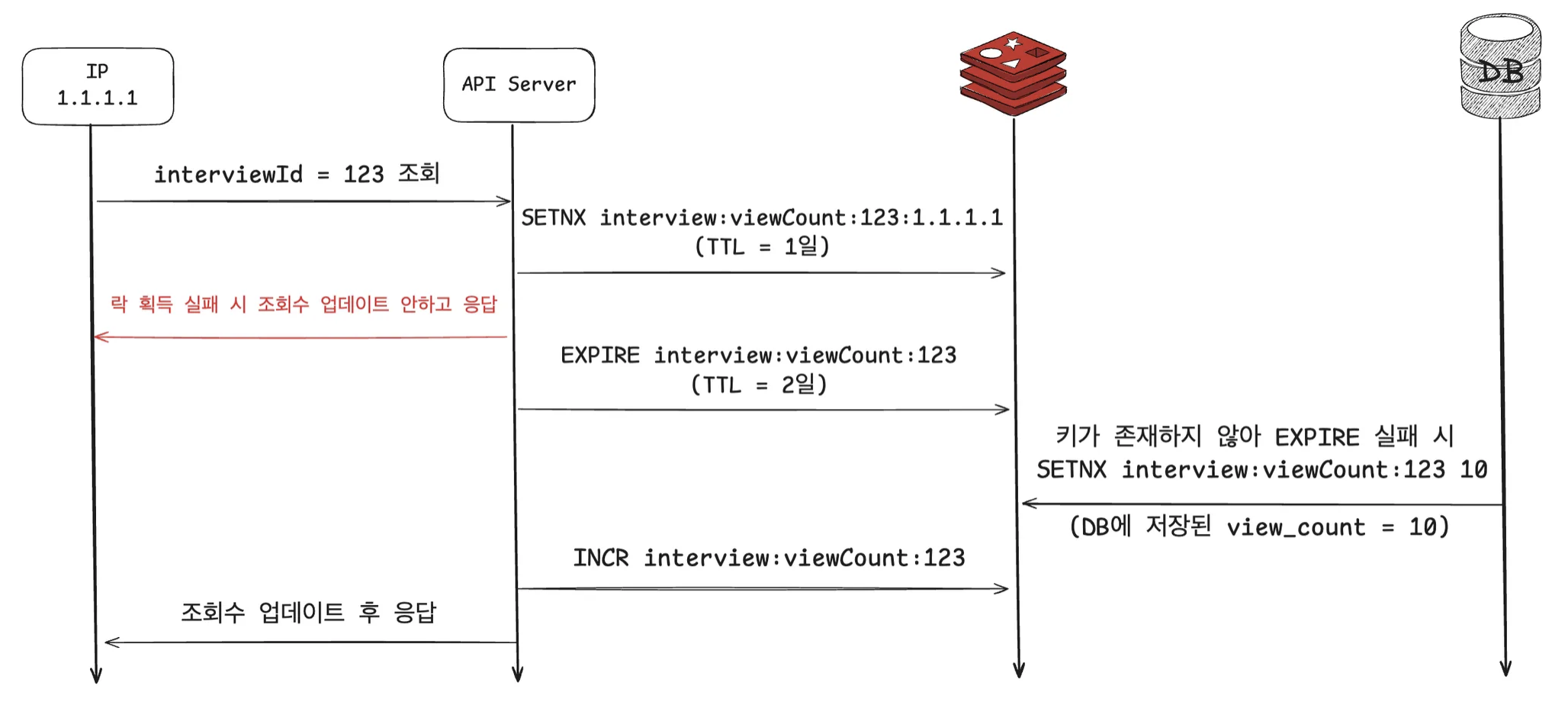
1. 중복 조회 방지
Key : interview:viewCount:{interviewId}:{clientIP}
TTL : 1일 (하루 후 재조회 시 카운트 증가)조회수 치팅 방지를 위해 분산 락으로 제어했습니다.
2. 조회수 저장 및 증가
Key : interview:viewCount:{interviewId}
Value : 해당 면접의 조회수
Operation : INCR (원자적 연산으로 1씩 증가)
TTL : 2일레디스에서 조회수 값을 관리하고, 업데이트 시 INCR 를 통해 원자적으로 1씩 증가시킵니다.
TTL을 2일로 설정한 이유는 다음과 같습니다.
- 데이터 안정성: Redis는 휘발 가능성이 있기 때문에, 데이터 손실 방지를 위해 주기적으로 DB에 동기화 해야합니다.
- 메모리 효율성: 조회되지 않는 오래된 데이터가 메모리를 점유하는 것을 방지해야 합니다.
- 불필요한 DB 업데이트 방지: 매일 동기화하는 주기의 2배(2일)로 설정하여 중복 업데이트를 최소화합니다.
3. 동시성 처리 로직
1. EXPIRE interview:viewCount:{interviewId} 172800 // 2일 TTL 설정
2. EXPIRE 실패 시 → SETNX interview:viewCount:{interviewId} {DB_조회수}
3. INCR interview:viewCount:{interviewId}동시성 상황을 고려한 자세한 로직은 다음과 같습니다.
interview:viewCount:{interviewId}에 대해 TTL을 2일로 EXPIRE 합니다.- 다음 상황으로 인해 조회수가 1로 초기화 되는 것을 방지하고자 EXPIRE를 먼저 실행합니다.
- SETNX 실패 → key 만료 → INCR (key 가 없는 경우 1로 초기화)
- key가 존재하지 않아 EXPIRE에 실패하는 경우, DB에 저장된 조회수 값을 SETNX로 레디스에 저장합니다.
- race condition에 의해 값이 덮어 씌워지는 것을 방지하기 위함입니다.
- 이후 INCR 연산으로 조회수 값을 원자적으로 1 증가시킵니다.
[스케줄러를 이용한 주기적인 DB 동기화]
Redis는 인메모리 데이터베이스로 데이터 휘발성이 있어 주기적인 DB 동기화가 필요합니다. 사용자 트래픽이 가장 적은 새벽 5시에 @Scheduled를 통해 Redis의 조회수 데이터를 DB로 동기화하도록 구현했습니다.
@Scheduled(cron = "0 0 5 * * *", zone = "Asia/Seoul")
public void syncInterviewViewCounts() {
if (!redisService.acquireLock(LOCK_KEY, Duration.ofHours(6))) {
return;
}
List<String> keys = new ArrayList<>();
Map<Long, Long> interviewViewCounts = new HashMap<>();
int scanCount = 100;
try (Cursor<String> cursor = redisService.scanKeys("interview:viewCount:*", scanCount)) {
while (cursor.hasNext()) {
keys.add(cursor.next());
processBatchesIfReady(keys, interviewViewCounts);
}
putInterviewViewCounts(keys, interviewViewCounts);
batchUpdateInterviewViewCounts(interviewViewCounts);
} catch (Exception e) {
log.error("인터뷰 조회수를 DB에 반영하는 스케줄러 동작 중 에러 발생", e);
redisService.releaseLock(INTERVIEW_VIEW_COUNT_SCHEDULER_LOCK);
}
}다중 서버 환경에서 동일한 작업이 중복 실행되는 것을 방지하기 위해 Redis 분산락을 활용했습니다. 락을 먼저 획득한 서버만 스케줄러를 실행합니다.
조회수 값을 조회할 때 KEYS 명령어 대신 SCAN을 사용했습니다. 싱글 스레드로 동작하는 Redis 특성 상, KEYS는 O(N) 시간복잡도로 다른 작업을 밀리게 해 장애를 일으킬 수 있습니다. 따라서 SCAN을 이용하여 100개씩 나누어 조회해 다른 작업에 끼치는 영향을 최소화했습니다.
또한 DB에 업데이트 할 때 배치 업데이트를 적용했습니다. 개별 UPDATE 쿼리는 매번 네트워크 통신이 발생해 비효율적입니다. 배치 처리로 여러 쿼리를 한 번에 실행하여 성능을 최적화했으며, MySQL의 멀티 스레드 특성을 고려해 배치 사이즈를 Redis 보다 더 큰 1000개로 설정했습니다.
@Transactional
public void batchUpdateInterviewViewCount(Map<Long, Long> interviewViewCounts, int batchSize) {
List<Entry<Long, Long>> entries = new ArrayList<>(interviewViewCounts.entrySet());
jdbcTemplate.batchUpdate(
"UPDATE interview SET view_count = ? WHERE id = ?",
entries,
batchSize,
(ps, entry) -> {
ps.setLong(1, entry.getValue());
ps.setLong(2, entry.getKey());
}
);
}[성능 테스트 결과]
다음 조건에서 K6를 활용해 테스트 했습니다.
프로덕션과 동일한 환경으로 서버 1 대에만 테스트를 진행하였고, 총 3번씩 테스트 했습니다.
- EC2 타입 : t4g.small
- 톰캣 스레드 : 30개
- max connections : 2000개
- 히카리 풀 : 10개
[Redis를 활용한 write back 패턴]

평균 342 TPS가 나왔습니다.
[DB에 직접 증분 쿼리를 날릴 때]

평균 186 TPS가 나왔습니다.
Redis를 활용한 방식이 약 84 % 정도 성능이 향상된 것을 볼 수 있습니다.
실제 프로덕션 환경에서는 다중 서버로 인해 히카리 커넥션 풀의 총합이 더 크므로, DB X 락으로 인한 대기 시간이 길어져 성능 차이는 더욱 클 것으로 예상됩니다.
✅ [Redis 장애 시 fall back 처리]
서비스 운영 중 Redis 장애를 경험한 적이 있습니다.
메모리, CPU 사용률과 슬로우 쿼리를 확인했지만 특별한 이상은 없어 순간적인 네트워크 장애로 추정됩니다.
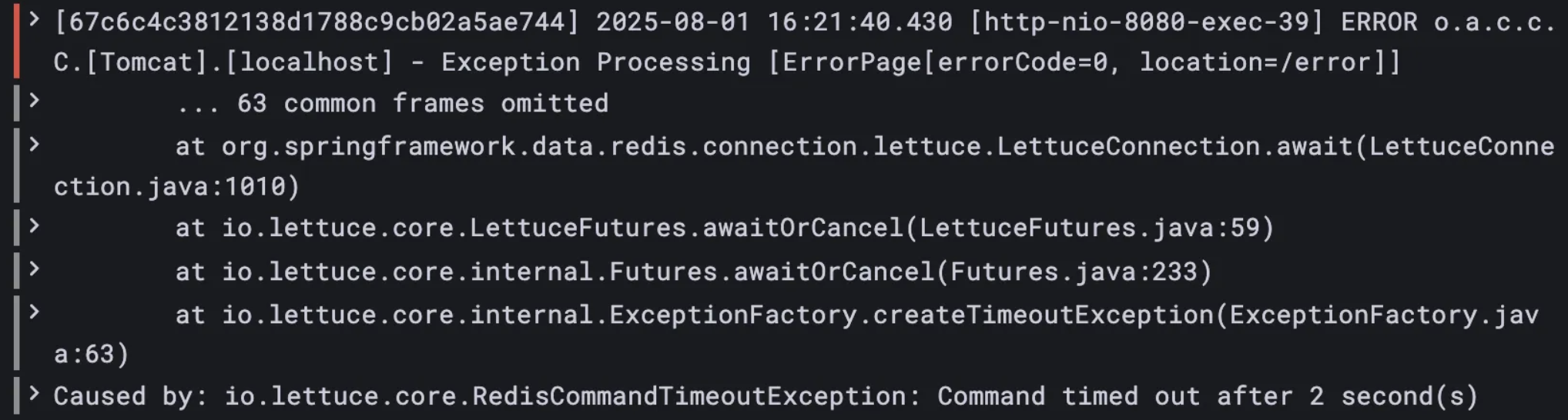
현재 구조에서는 Redis 장애 시 조회수 업데이트가 실패하면서 조회 API 전체가 실패하게 됩니다.
조회수 업데이트 때문에 조회 API가 실패해서는 안 된다고 판단하여, Redis 장애 시 DB에서 직접 조회수를 읽어오는 fallback을 구현했습니다.
최신 조회수는 아니지만 API 실패보다는 낫다고 판단했으며, Redis 장애가 빈번하지 않고 조회수는 정밀한 정합성이 필요하지 않는다는 특성을 고려했습니다.
해당 API 뿐만 아니라 조회수 값을 조회하는 모든 API에서 Redis 장애 시 DB로 fallback하도록 처리했습니다.
❌ [다른 해결 방안 : Kafka와 아웃박스 패턴을 이용한 조회수 업데이트]
Redis에 있는 조회수 값을 주기적으로 DB에 동기화 하더라도, Redis 자체에 장애가 발생하면 데이터 손실을 완전히 방지할 수 없습니다.
정합성과 성능을 모두 확보하려면 Kafka로 이벤트를 publish 하여 처리하도록 하고, publish 실패 시 아웃박스 테이블에 저장 후 재처리하여 데이터 손실을 최소화 할 수 있습니다.
이 방식이 Redis보다 훨씬 안정적이지만, 조회수는 이런 복잡한 아키텍처를 도입할 만큼 높은 정합성이 요구되는 데이터가 아니라고 판단하여 Redis write-back 패턴을 선택했습니다.
