시퀀스 컨테이너
: 시퀀스 컨테이너(sequence container)는 데이터를 선형으로 저장하며, 특별한 제약이나 규칙이 없는 가장 일반적인 컨테이너로 삽입된 요소의 순서가 그대로 유지되는 것이 특징이다.
시퀀스 컨테이너의 종류
1. 백터(Vector)
일반화된 컨테이너 중에서 가장 많이 사용하며, 필요한 크기만큼 메모리를 자동으로 재할당하며 늘릴 수 있다.
템플릿 기반으로 요소의 타입에 무관하게 만들 수 있다.
백터 선언 문법
vector<템플릿인수> 객체이름(생성자인수);
을 이용하여 선언을 할 수 있는데 단순 선언 이외에도 아래와 같이 크기 지정도 가능하다.
백터의 사용 형태
vector<T> vec1; // 벡터 형식으로 타입이 T형인 백터 객체 선언
vector<int> vec1; // 타입이 int형인 백터 객체 생성
vector<int> vec1(5); // 백터의 크기를 미리 5로 지정 (하지만 동적 메모리이기에 추후 필요한 만큼 늘릴 수 있음)여기서 크기를 잘 해석해야한다. 위 코드에서 vector<int> vec1(5)는 int형이 아니라 vector라는 타입 안에 5개가 할당이 된 상태를 의미한다. 즉, 해당 코드에서 백터의 크기는 vector타입의 메모리 크기가 아닌 데이터 개수에 대한 크기인 것이다.
백터 사용 예시 코드
void main() {
vector<int> arr(5); // arr = 배열의 속성을 가진 vector의 객체 ex) arr = {0, 1, 2, 3, 4}가 가능
// vector에 5개의 정수값 넣기
for (int i = 0; i < arr.size(); i++) { // vector는 템플릿이지만 본질은 클래스 즉, 직접접근으로 접근이 가능한 아이들(ex. size())은 vector 클래스의 멤버 함수!
arr[i] = i;
}
// vector에 들어간 데이터 값 출력
for (int i = 0; i < arr.size(); i++) { // vector는 템플릿이지만 본질은 클래스 즉, 직접접근으로 접근이 가능한 아이들은 vector 클래스의 멤버!
cout << arr[i] << endl;
}
}2. 데크(Deque)
Deque 또는 Double-Ended Queue는 양쪽 끝에서 데이터를 삽입 및 삭제할 수 있는 시퀀스 컨테이너
데크의 사용 형태
deque<T> dq; // 데크의 형식으로 타입이 T형인 테크 객체 선언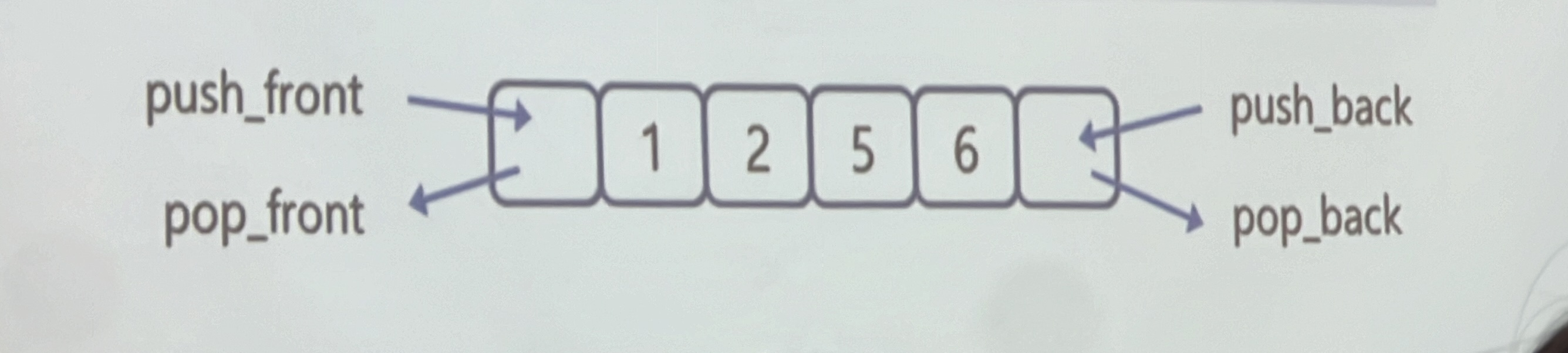
백터는 앞에서 데이터를 삽입하는 경우 뒤에 이미 존재하던 데이터가 뒤로 밀리는 반면, 데크는 데이터 위치의 이동 없이 앞/뒤로 삽입이 가능하다는 점이 Vector와의 차이점이다.
데크 사용 예시 코드
void main() {
deque<int> num; // 빈 데크 객체 생성
num.push_back(5); // 데이터 삽입 시, 뒤쪽에 충분한 메모리 공간이 없다면 공간을 생성 및 확보하여 데이터를 삽입해주는 역할
num.push_back(6);
for (int i = 0; i < num.size(); i++) {
cout << num[i] << endl;
}
}와 같이 따로 메모리 공간을 확보하지 않고 .push_back()으로 데이터를 입력하면
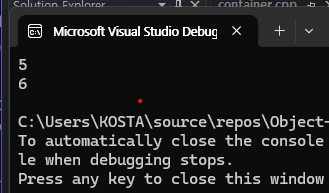
처럼 결과값에 5와 6입 삽입된다.
3. 리스트(List)
벡터와 달리 비연속 메모리에 데이터를 저장하고 저장된 데이터에 대한 순차적 액세스만 제공하는 이중 연결 리스트로 구현되어 있는 컨테이너
연결 리스트는 '노드'라는 것이 붙어 있어서 데이터가 물리적으로 인접해있지 않고, 논리적인 순서를 기억하므로 데이터 삽입, 삭제의 속도가 상대적으로 일정하다.
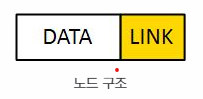
노드 구조
노드의 구조를 살펴보면 값을 저장하는 데이터 필드, 해당 노드와 연결된 다음 노드의 주소를 저장하는 포인터인 링크 필드가 있다.
리스트는 물리적으로 인접해있지 않다보니, 데이터 정보만이 아니라 앞,뒤 데이터의 위치 정보가 함께 필요하다. 따라서 리스트는 백터나 데크, 배열에 비해 앞,뒤 데이터의 주소값인 8byte 정도의 용량을 더 필요로 한다.
쉽게 예를 들자면, 백터나 데크, 배열은 시골 한 동네의 한 마을에 가족이 같이 모여 사는 거라면 리스트의 경우에는 나는 한국에, 이모는 캐나다에, 고모네는 영국에, 외삼촌은 프랑스에 살고 있어 온라인에서 모이기 위해 서로간의 화상통화 번호(= 컴퓨터 IP 주소)를 알아야 한다.
여기서 화상통화 번호에 해당하는 것이 바로 앞, 뒤 데이터의 주소값이다.
리스트의 사용 형태
list<T> lst; // 리스트의 형식으로 타입이 T형인 리스트 객체 선언
리스트 사용 예시 코드
void main() {
list<int> lst;
for (int i = 0; i < 5; i++) {
lst.push_back(i);
}
int i = 0;
list<int>::iterator it; // list라는 클래스에 소속되어 있는 iterator이며, 이걸 통해서 it라는 반복자 생성
for (it = lst.begin(), i = 0; it != lst.end(); it++) {
// it != lst.end()는 처음부터 끝까지 요소를 다 돌고 그 다음번 요소 (= 마지막 요소가 아니면) 반복문을 빠져나오는 조건을 의미
cout << *it << endl; // 결과값: "0, 1, 2, 3, 4"
};
}연결 리스트
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조
- 가변 크기를 가지는 자료구조로 연결 리스트(단순 연결/이중 연결) 사용
- 연결 리스트와 동적 배열은 용도가 같지만 구성 원래나 관리 방법은 질적으로 다름
배열과 연결 리스트의 차이
- 배열
- 인접한 메모리 영역에 연속적으로 배치
- 자신이 기억할 데이터 값만 갖는다
- 연결 리스트
- 요소들이 메모리 도처에 흩어져서 존재
- 데이터 외에 연결 상태에 대한 정보인 링크를 추가로 가져야 한다.
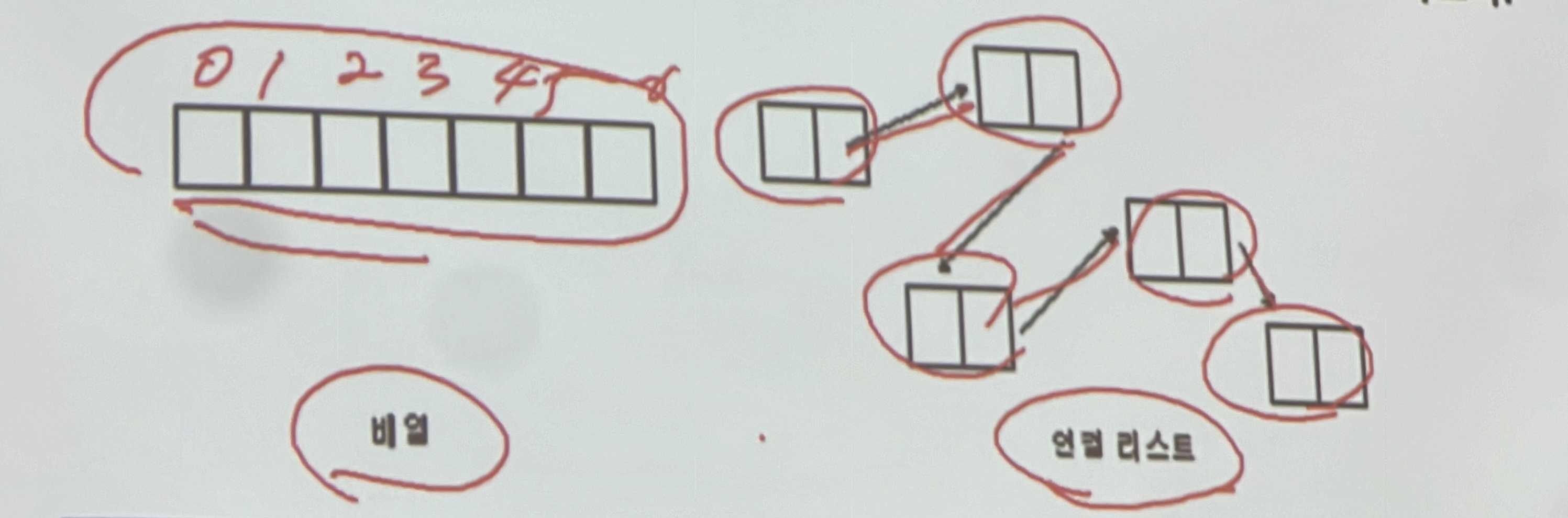
연결 리스트 특징
- 링크를 하나만 가지는 것을 단순 연결 리스트(Single Linked List), 두 개의 링크를 가지는 것을 이중 연결 리스트(Double Linked List)라고 한다.
- 노드를 구성하는 데이터와 링크는 타입이 다르므로 구조체로 정의
sturct Node
{
int value; // 데이터
Node *next; // 링크
}위 코드에서 value 멤버는 노드가 기억하는 정보의 실체인 데이터를 가리키며, next 멤버는 다음 노드에 대한 포인터를 가지는 링크를 의미한다.
1. 단일 연결 리스트
하나의 structure는 value와 next로 구성되고 총 8byte만큼의 크기(int value 값의 크기인 4 byte와 포인터 변수의 크기인 4 byte)를 가지게 되는데, next(포인터 변수)는 다음 노드의 주소값을 바라보고 있어야 한다.
따라서, 위에서 포인터 변수의 데이터 타입이 지금 Node인데 그 이유는 노드1의 next가 가리키고 있는 주소값이 노드2의 주소값이기 때문이다. 즉, 포인터 변수가 가리키고 있는 대상이 "노드"이기 때문이다.
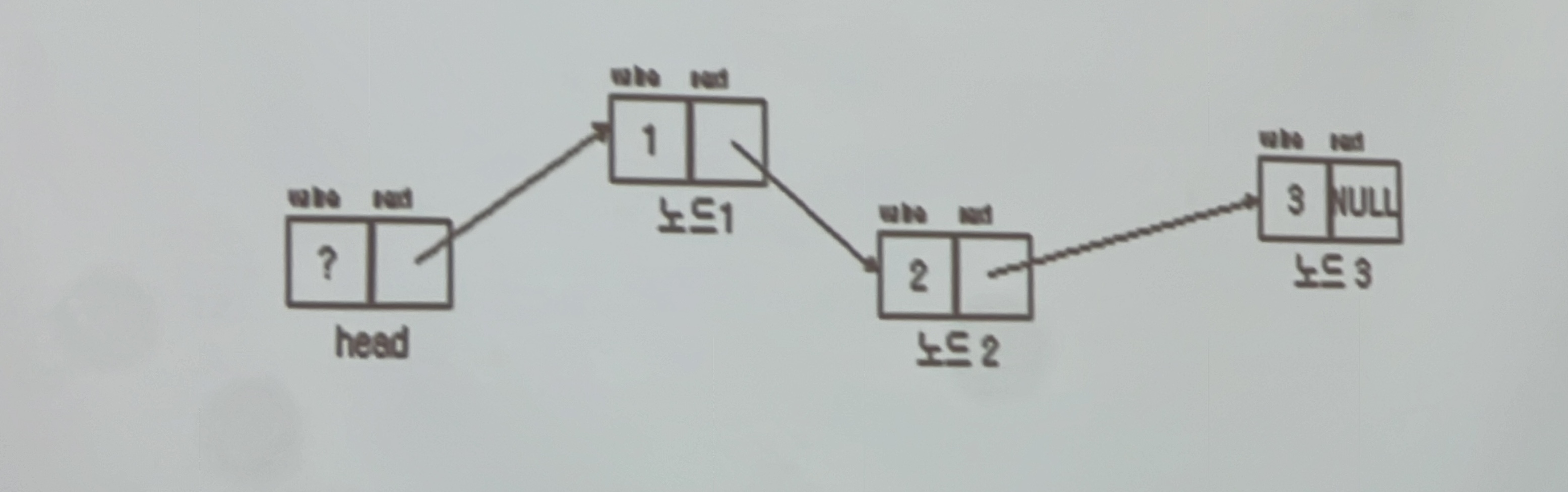
// 노드 구조체
struct Node {
int value;
Node* next;
};
// Entry Point 필요(기준점이 되는 head) → head에는 value값은 필요가 없지만 내가 원하는 값을 넣기위한 기준점으로 필요함.
// head의 next 포인터 변수가 Node1의 주소를 가리키면서 연결 리스트가 시작됨
Node* head;
void InintList() {
head = (Node*)malloc(sizeof(Node)); // head를 동적메모리로 메모리 생성
head->next = NULL; // head 초기화: (값은 필요 없기에 초기화 하지 않음)
};
Node* InsertNode(Node* pNow, Node *pTemp) {
Node* New = (Node*)malloc(sizeof(Node)); // 새로 추가할 노드(신규 데이터) 사이즈만큼의 노드 생성
*New = *pTemp;
New->next = pNow->next; // Now(head)의 주소값인 NULL을 New(Temp)의 주소값에 복사
pNow->next = New; // New의 주소값을 Now(head)의 next에 복사
return New;
}
void main() {
Node *Now; // 현재 노드 선언(구조체 포인터)
Node Temp; // 임시 노드 선언(구조체 변수)
InintList();
Now = head;
Temp.value = 1;
// 노드 삽입
Now = InsertNode(Now, &Temp);
printf("%d\n", Now->value); // 출력값: 1
Temp.value = 2;
Now = InsertNode(Now, &Temp);
printf("%d\n", Now->value); // 출력값: 1, 2
Temp.value = 3;
Now = InsertNode(Now, &Temp);
printf("%d\n", Now->value); // 출력값: 1, 2, 3
}
노드 삭제 코드 예시
//
bool DeleteNode(Node* Target) { // Target = head의 next값을 받은 변수
Node* del;
del = Target->next;
if (del == NULL) {
return false;
}
Target->next = del->next;
free(del);
return true;
}
void main() {
Node *Now; // 현재 노드 선언(구조체 포인터)
Node Temp; // 임시 노드 선언(구조체 변수)
InintList();
Now = head;
Temp.value = 1;
for (int i = 0; i < 3; i++) {
Temp.value = 1 + i;
Now = InsertNode(Now, &Temp);
printf("%d\n", Now->value);
}
bool del = DeleteNode(head->next);
if (del) {
printf("삭제 성공\n");
}
for (Now = head->next; Now; Now = Now->next) {
printf("%d\n", Now->value);
};
UnInitList();
}
위 코드를 해석해보면 DeleteNode라는 함수에 전달한 인자값이 "Target"은 head->next의 값과 동일하다.
해당 값을 del이라는 포인터 변수에 담아주고, del값이 NULL이면 false를 리턴한다.
이걸 다시 풀어보면
DeleteNode(Node* Target) { // Target: head->next (head의 다음 노드 주소값)
Node* del // del: 포인터 변수
del = Target->next // head 다음 다음의 노드 주소값 (head->next의 ->next)
if(del == NULL) return false // head->next->next가 NULLhead->next->next 값이 NULL이라는 것은 결국 Target.next가 가리키는 노드가 마지막 노드라서 더이상 받을 주소값이 없다면 false를 리턴한다.
Target->next = del->next // head->next->next와 del(Target->next)->next가 동일한 값
return true;따라서, del이 NULL값이 아니라는 것은 그 다음 노드가 존재한다는 것을 의미하고, 그럴 경우에는
Target->next(삭제할 노드의 다음 노드를 가리키는 주소값)에 del->next(삭제할 노드의 다음 다음번째 노드의 주소값)의 값을 담아주면서 뒤에 있는 노드들의 주소 값을 한칸씩 앞으로 당기면서 삭제할 노드의 연결을 변경해주면 된다.
2. 이중연결 리스트
단일 연결 리스트의 노드는 주소를 저장하는 next와 값을 저장하는 value만으로 이루어져 있었다면 이중 연결 리스트의 노드는 노드 이전의 주소를 저장하는 prev와 값을 저장하는 value, 그리고 다음 노드의 주소를 저장하는 next 3개로 구성되어져 있다.

따라서, 이중 연결 리스트는 양쪽 모두 삽입이 가능하다.
이미지 삽입
예를 들어 노드 3 다음에 노드 5를 삽입한다면 노드 3의 next는 노드 5의 prev에, 노드 5의 next는 노드 4의 prev로 여결해야한다.
이미지 삽입
4. 셋(Set)
동일한 타입의 데이터를 모아놓은 것
Set은 내부적으로 알아서 데이터를 오름차순 정렬 및 중복 데이터 제거를 시행하여 결과값을 반환한다.
- 백터와의 차이
- 데이터가 아무 위치에나 삽입되는 것이 아니라 정렬된 위치에 삽입
- 검색 속도가 빠름
- 데이터 자체를 키로 사용 가능 (=키가 중복되지 않는다)
set의 사용 형태
set<T> st;셋의 사용 형태는 일반 컨테이너와 동일하다.
Set 사용 예시 코드
// 정수형 저장 예시
void main() {
int arr[] = { 1, 2, 3, 2, 5, 6, 3 };
set<int> scon;
set<int>::iterator it;
// scon.insert(배열의 요소값);
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
scon.insert(arr[i]);
};
for (it = scon.begin(); it != scon.end(); it++) { // it = 포인터(즉, 주소값을 저장)
cout << *it << endl; // 포인터의 주소가 가리키고 있는 데이터의 실제 값
};
}
// 문자열 저장 예시
void main() {
const char* strtemp = "dkjfslejredf"; // 문자열은 아스키코드값을 기준으로 중복값 삭제 후 정렬
set<char> scon(&strtemp[0], &strtemp[11]);
set<char>::iterator it;
for (it = scon.begin(); it != scon.end(); it++) { // it = 포인터(즉, 주소값을 저장)
cout << *it << endl; // 포인터의 주소가 가리키고 있는 데이터의 실제 값
};
}5. 맵(Map)
두 개의 데이터가 하나의 쌍을 이루어 저장하는 컨테이너
- 맵의 특징
- 데이터가 정렬된 상태로 관리됨
- 검색 속도가 빠름
- 대량의 데이터를 검색할 경우, map을 사용하면 유리
- map은 데이터를 삽입할 때 내부적으로 데이터의 이동이 발생 => 내부적으로 재배열되기 때문에 데이터의 삽입 및 삭제 시 상대적으로 느려짐
Map의 사용 형태
Map<key, data> mp;- 맵의 첫번째 전달인자 key에는 숫자, 문자 타입 상관없이 들어올 수 있다.
- 맵의 두번재 전달인자 data는 key를 통해 가져올 데이터를 의미하는데, 또한 숫자나 문자 타입에 상관없이 들어올 수 있다.
예를 들어 이름이라는 키값에 나이라는 데이터를 넣으면 아래와 같다.
Map<string, int> person;
Person["홍길동"] = 43;
Person["김철수"] = 10;Map 사용 예제 코드
struct PhoneAddr {
string name;
int phonenum;
}arPerson[] = {
{"홍길동", 5678},
{"김철수", 4325},
{"이영희", 4825}
};
void main() {
map<string, int> person;
map<string, int>::iterator it;
string name;
for (int i = 0; i < sizeof(arPerson)/sizeof(arPerson[0]); i++) {
// person[키] = 데이터;
person[arPerson[i].name] = arPerson[i].phonenum;
}
// 이름을 기준으로 검색하여 출력
for (;;) {
cout << "이름 입력: ";
cin >> name;
if (name == "q") break;
it = person.find(name);
if (it == person.end()) { // map 안에 있는 데이터의 요소값 중에 일치하는것이 없다 => null 값만 존재
cout << "이름이 존재하지 않습니다." << endl;
}
else {
cout << name << "의 번호는" << it->second << "입니다." << endl; // first: key, second: value 의미
}
}
}