강의 동영상 Lecture 8: CNN Architectures
슬라이드 및 이미지 참고 slides
지난 시간에는 CNN이 어떻게 구성되어 있는지 살펴보았다.
(Convolution Layers, Pooling Layers, Fully-Connected Layers, Activation Function, Normalization)
이 시간에는 ImageNet Classification Challenge를 통해 CNN의 다양한 아키텍처를 살펴보고자 한다.
AlexNet
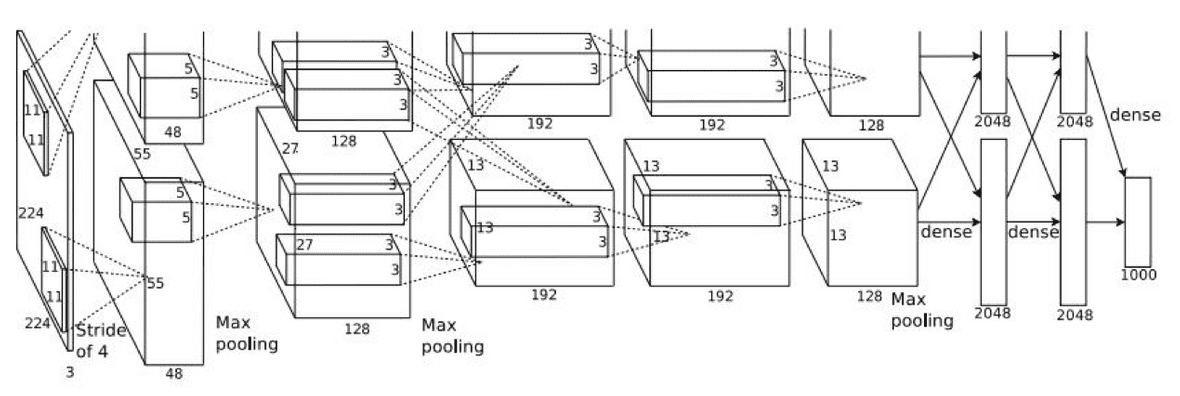
- 기존으로 non-딥러닝 모델을 능가하는 성능을 보여주었다.
- 최초로 딥러닝과 conv net을 적용하여 CNN으로 눈에 뛸 만한 성과를 낸 첫 CNN이다.
- 구조적으로 LeNet-5와 비슷하나 조금 더 많은 layer를 가진다는 차이가 있다.
- 2개로 분할하여 2개의 GPU에서 학습하였다.(GTX 580 GPU 2개, 각각 3GB의 메모리)
- LRN을 사용했으나, 이제 더이상 사용하지 않는다.
LRN(Local Response Normalization)
LRN을 검색해보면 측면을 억제한다고 나온다. 측면억제란 자신과 이웃 신경세포를 매개하는 중간신경세포를 통해 이웃에 있는 신경세포를 억제하려는 경향이다. AlexNet은 왜 측면억제를 사용했을까? 그 이유는 ReLU에 있다. ReLU는 양수의 방향으로는 입력값을 그대로 사용하는데, 이럴경우 conv나 pooling시 매우 높은 하나의 픽셀값이 주변의 픽셀에 영향을 미치게 된다. 이런 부분을 방지하기 위해 다른 Activation Map의 같은 위치에 있는 픽셀끼리 정규화를 해준다. 이것이 바로 AlexNet에서 사용되는 LRN이다.
구조
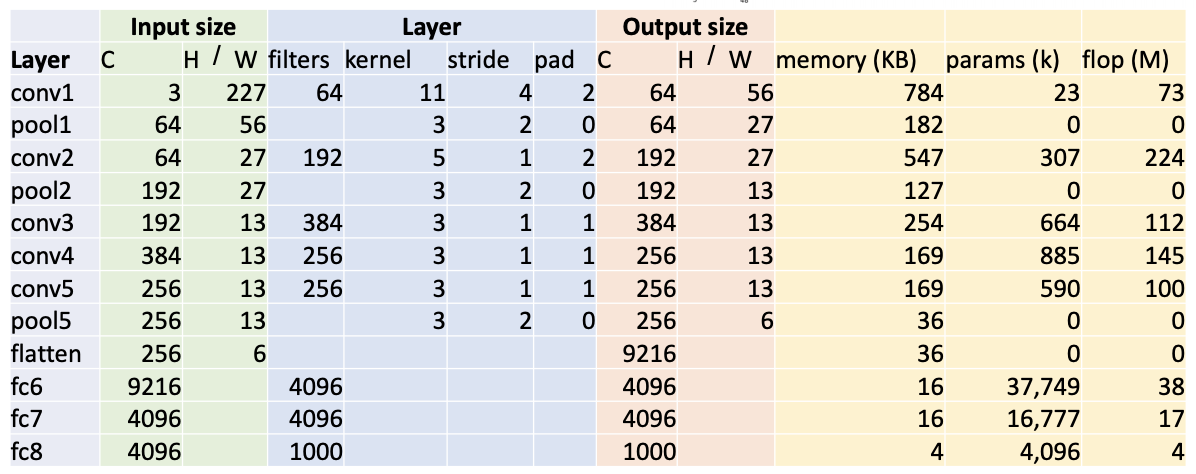
- 첫번째 레이어(conv1)의 output size는?
- filter가 64개이므로 output의 channel도 64개이다.
- H/W = (227-11+2*2)/4+1 = 56
- 첫번째 레이어(conv1)의 memory(KB)는?
- output의 개수 : 64*56 * 56 = 200,704
- 각 요소당 4bytes : 200,704 * 4 / 1024 = 784
- 1024bytes = 1KB
- 첫번째 레이어(conv1)의 parameter 수는?
- 필터 크기(11x11), 채널(depth, 3), 필터개수(64) : 11 * 11 * 3 * 64 = 23,232
- bias(64) : 23,232 + 64 = 23,296
- 첫번째 레이어(conv1)의 flop(M)은?
- flop: 1초당 부동소수점 연산 명령을 몇번 수행할 수 있는지, 컴퓨터의 연산속도를 나타내는 단위
- 72,855,552
- 두번째 레이어(pool1)의 output size는?
- pooling layer는 입력데이터의 채널수 그대로 출력데이터로 내보내기 때문에 채널수가 변하지 않는다.
- H/W = floor((H-K)/S+1) = floor((56-3)/2+1) = 27
- 두번째 레이어(pool1)의 params는?
- pooling layer는 가중치가 없고, 그저 특정 영역에서 특정 값을 선택만 하면 되기 때문에 학습을 기다리는 파라미터가 없다. 즉 0.
- 두번째 레이어(pool1)의 flop(M)은?
- (64*27*27)*(3*3) = 419,904 = 0.4 MFLOP
- conv와 pool의 차이는 극대하게 차이나는 것을 볼 수 있다.
- flatten
- C*H*W = 256*6*6 = 9216
- conv layer 경우 채널 수는 항상 필터의 수와 같다.
- output = (W-K+2P)/S+1
- 도식에서 layer가 2개로 분할되어 진행이 되는데, 이는 당시 GPU의 성능이 좋지 못해(GTX 580, 3GB mem) 두 부분으로 나눠서 각각 GPU를 하나씩 사용해서 학습할 수 있도록 하였기 때문이다. conv1, conv2, conv4, conv5는 동일한 GPU의 feature map과 연결되어 있다. 그러나 conv3, FC6, FC7, FC8은 바로 전 단계의 모든 feature map과 연결(즉 2개로 분할된 각각의 레이어와 모두 communication)하여 진행했다.
각 계층마다 비교
ZFNet
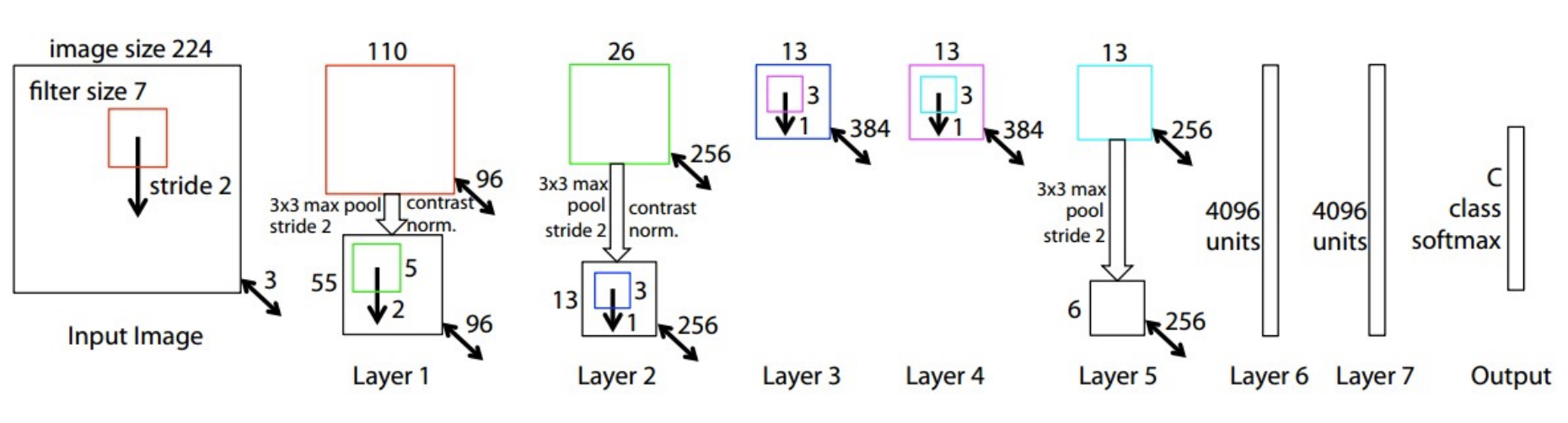
- AlexNet의 하이퍼파라미터를 개선한 모델
- 구조, 레이어 수는 같지만 stride size, filter수를 조절하여 error rate를 개선
- CONV1 : 11*11 stride 4 → 7*7 stride 2
- CONV3,4,5 : 384, 384, 256개의 필터 → 512, 1024, 512개의 필터
- 16.4% → 11.7%
VGGNet
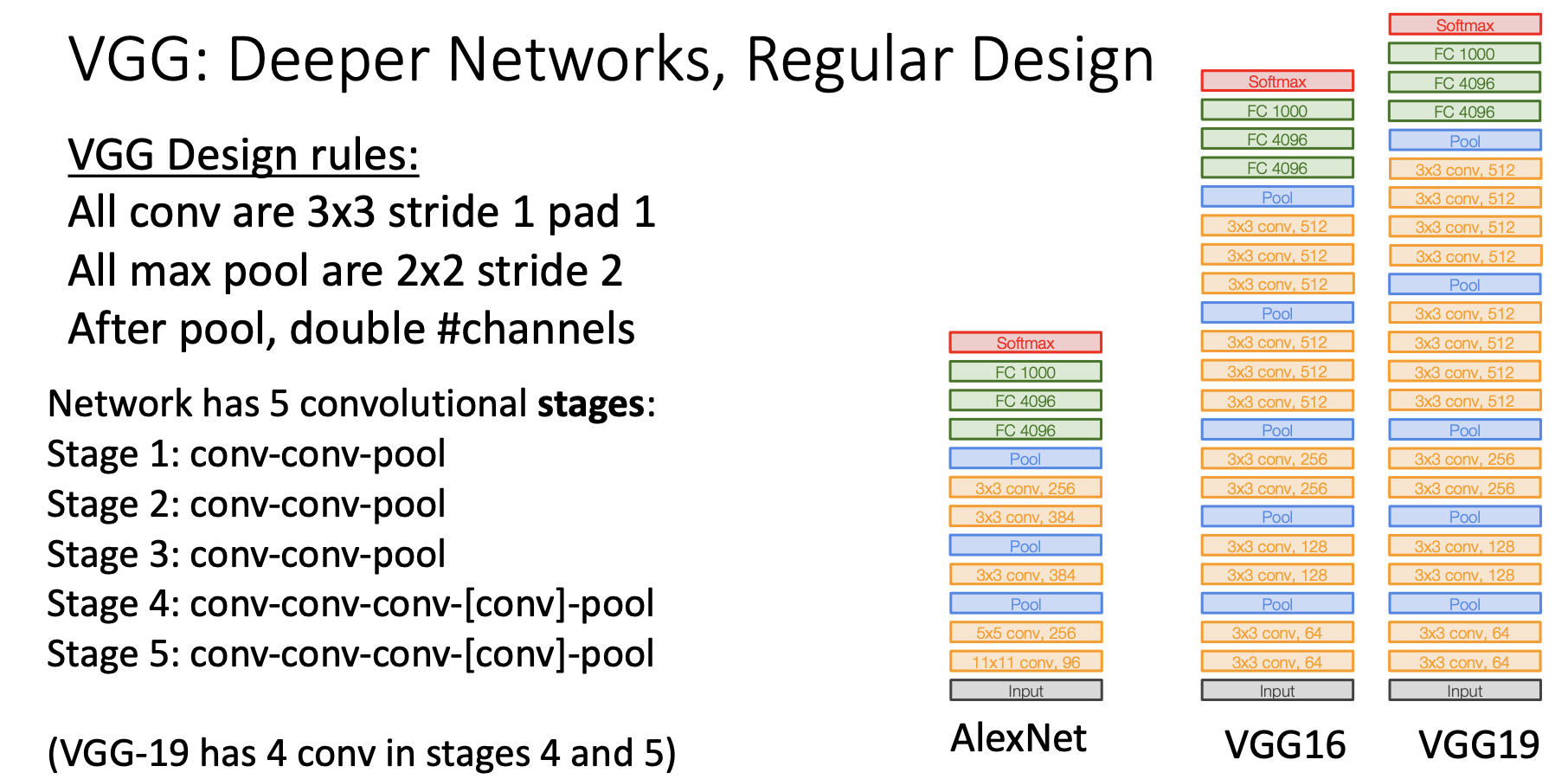
- 11.7% → 7.3%
- much deeper networks, much smaller filters
- filter : 3x3, stride: 1, padding: 1
- max pooling : 2x2, stride: 2
- local response normalization(LRN)이 없다.
왜 작은 필터를 사용했을까?
필터의 크기가 작으면 파라미터의 수가 더 적기 때문에 큰 필터에 비해 레이어를 조금 더 많이 쌓을 수 있다. 즉, 작은 필터를 사용하면 depth를 더 키울 수 있는 것이다.
receptive field
filter가 한번에 볼 수 있는 입력의 sparical area
그럼 3x3, stride=1 인 conv를 3번 쌓게 되면 receptive field는 어떻게 될까?
정답은 7x7이다.
3x3→5x5→7x7
첫 번째 layer에서 하나의 픽셀은 CONV를 통해 3x3의 정보를 가지게 된다. 두 번째 레이어에서 하나의 픽셀은 3x3의 정보를 가진 상태에서 또다시 3x3의 CONV를 통해 5x5의 정보를 가진다. 이런식으로 3x3의 CONV를 3번 쌓게되면 7x7의 effective receptive field 가지게 된다.
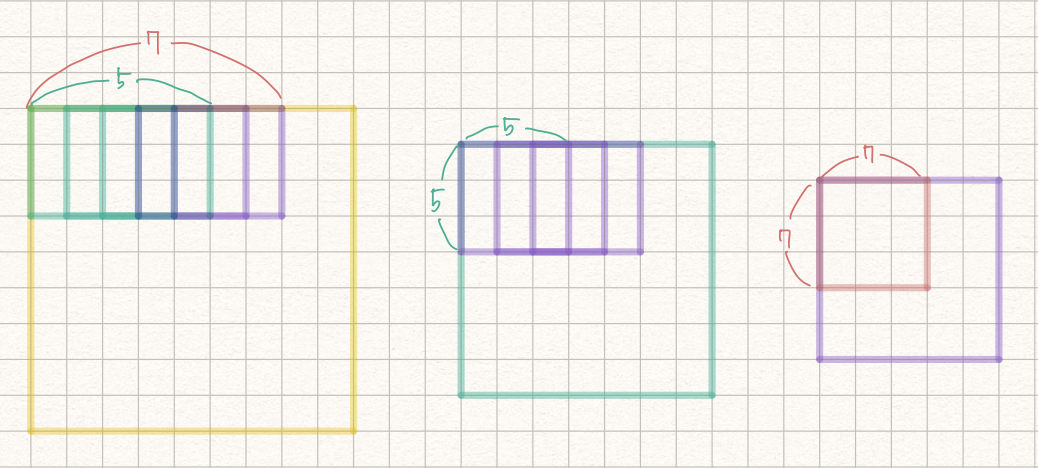
그럼 receptive field처럼 왜 더 깊게 쌓을까?
더 깊은 층을 쌓음으로써 비선형성을 추가하고, 파라미터 수를 감소시키기 때문이다.
파라미터의 개수는 필터 크기 x 입력의 depth x 필터 개수이다. 3x3일경우에는 3x3xCxC가 3번 쌓이기 때문에 이 된다. 7x7일 경우에는 이 되어 상당히 차이가 난다.
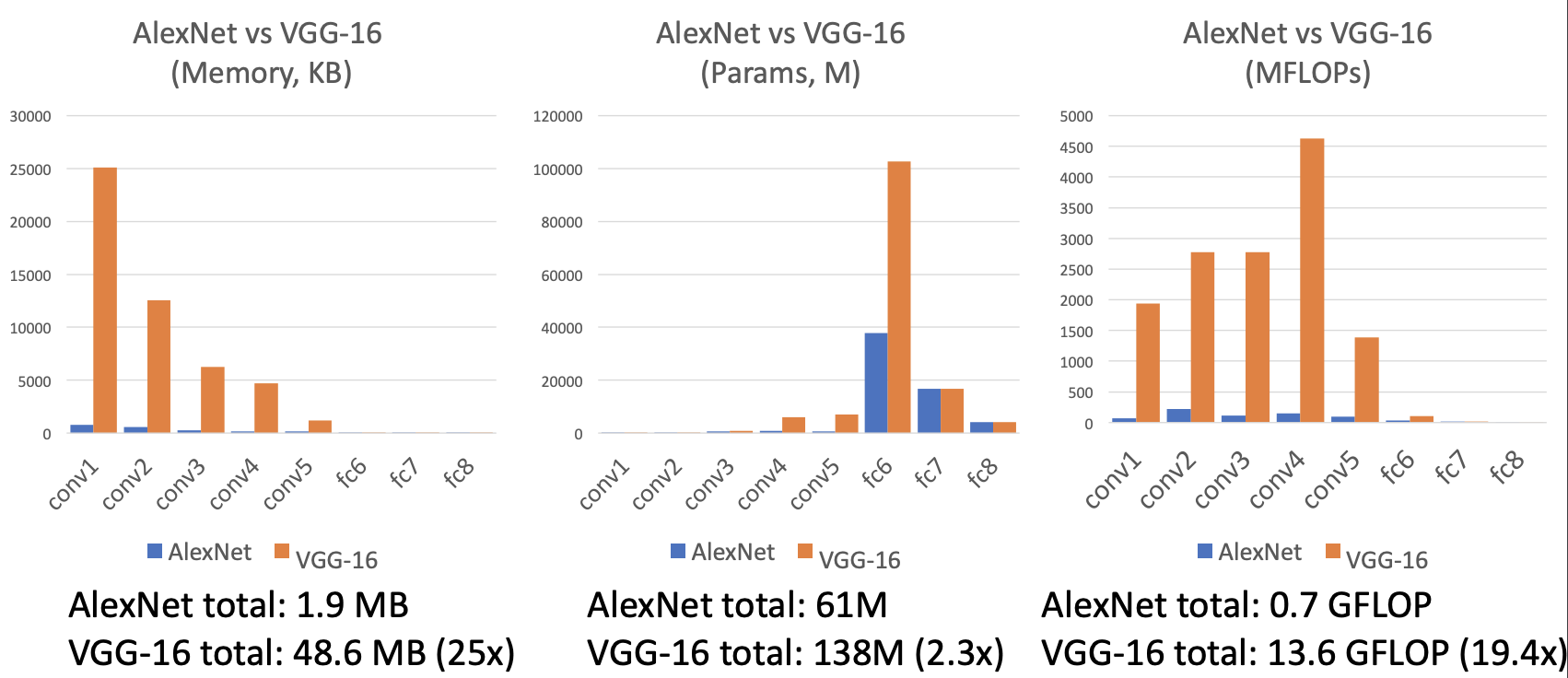
AlexNet vs VGG-16
GoogLeNet
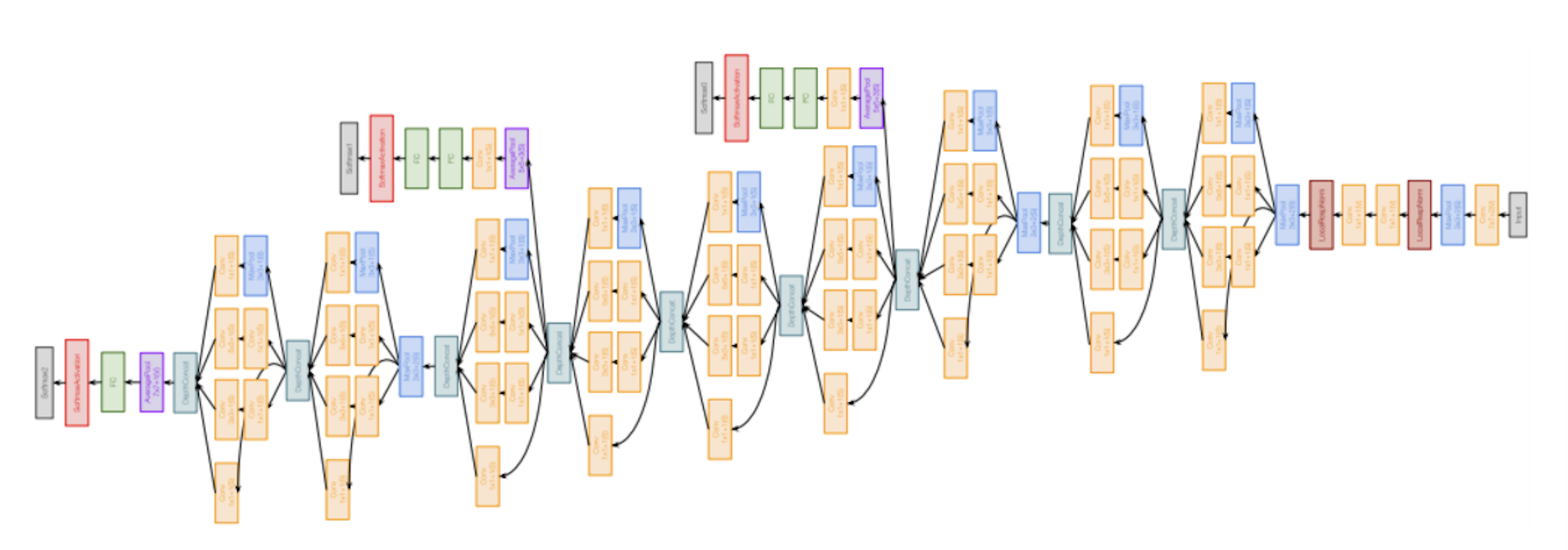
- 7.3% → 6.7%
- 22 Layers를 사용했는데, network가 더 깊어지면서 계산 효율이 증대되었다.
- Inception module을 여러개 쌓아서 만들었다.
- No FC layers(파라미터를 줄이기 위해)
- AlexNet보다 12배 적은 500만개의 파라미터를 가진다.
Inception module
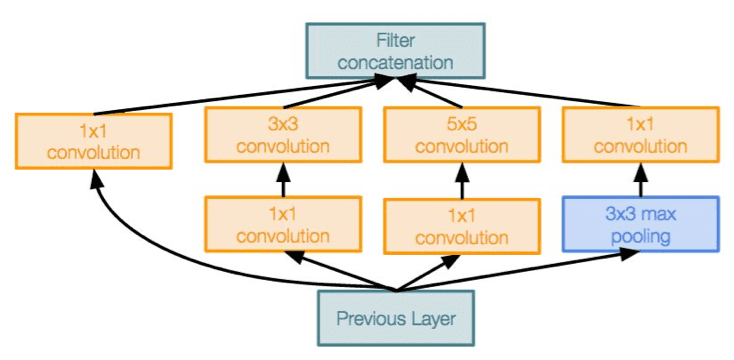
- 다양한 크기의 필터로 convoluntion을 병렬적으로 진행한 후, depth 방향으로 모두 합쳐버리는 개념
- 다양한 필터를 이용해서 다양한 특징 추출!
- 동일한 입력을 받는 서로 다른 필터들이 병렬로 존재한다.
- 각 레이어에서 나온 각각의 출력값들을 depth방향으로 합친다. 그렇게 합치면 하나의 tensor로 출력이 결정되고, 이 하나의 출력을 다음 레이어로 전달하는 것이다.
- 1x1 bottleneck layer : 채널의 차원수를 줄여줌으로 계산량을 조절할 수 있다.
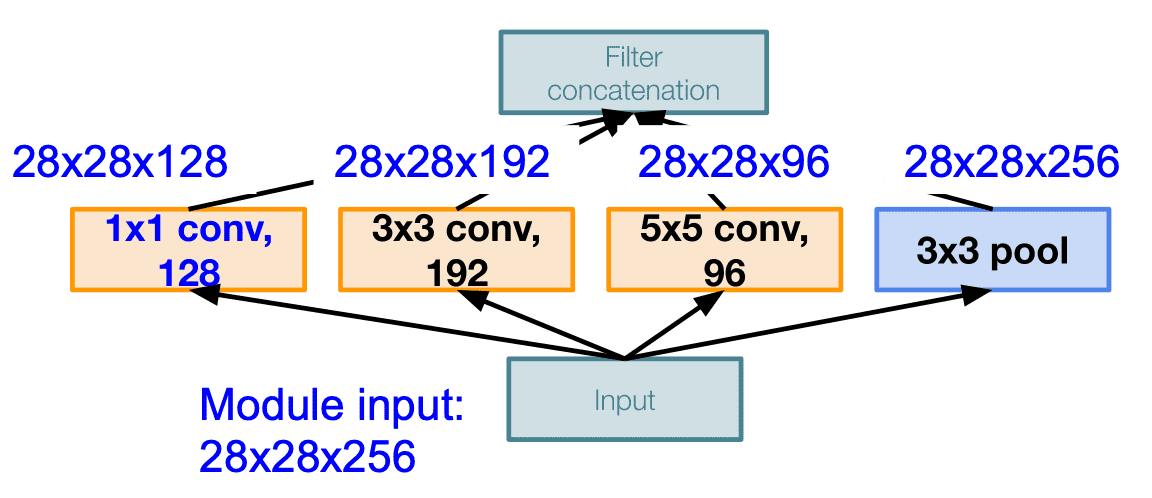
각각의 레이어가 평행하게 적용하여 최종적으로 모두 depth-wise하게 이어붙여 출력을 만들어내는 구조로 이렇게 했을 때의 문제점은 계산비용이 비싸다는 점이다. 위의 그림에서 각 필터들을 depth-wise하게 이어붙이면
- output :
- 연산량 operations
- [1*1 conv, 128] =
- [3*3 conv, 192] =
- [5*5 conv, 96] =
- 최종 = 854M
이는 너무나도 비싼 연산이 되는데, pooling layer 도 feature 의 depth 를 유지하기 때문에 결국 concatenation 을 하게 되면 depth 는 매 레이어마다 증가할 수 밖에 없게 된다. 그래서 이를 해결하기 위해 bottleneck layer 를 도입하게 된다.

56*56*64 의 input 에 대해 1*1 conv layer 인 32개의 필터를 적용시키면 56*56 의 공간은 유지되면서 채널(depth)이 32로 줄어드는 효과를 얻게 된다.
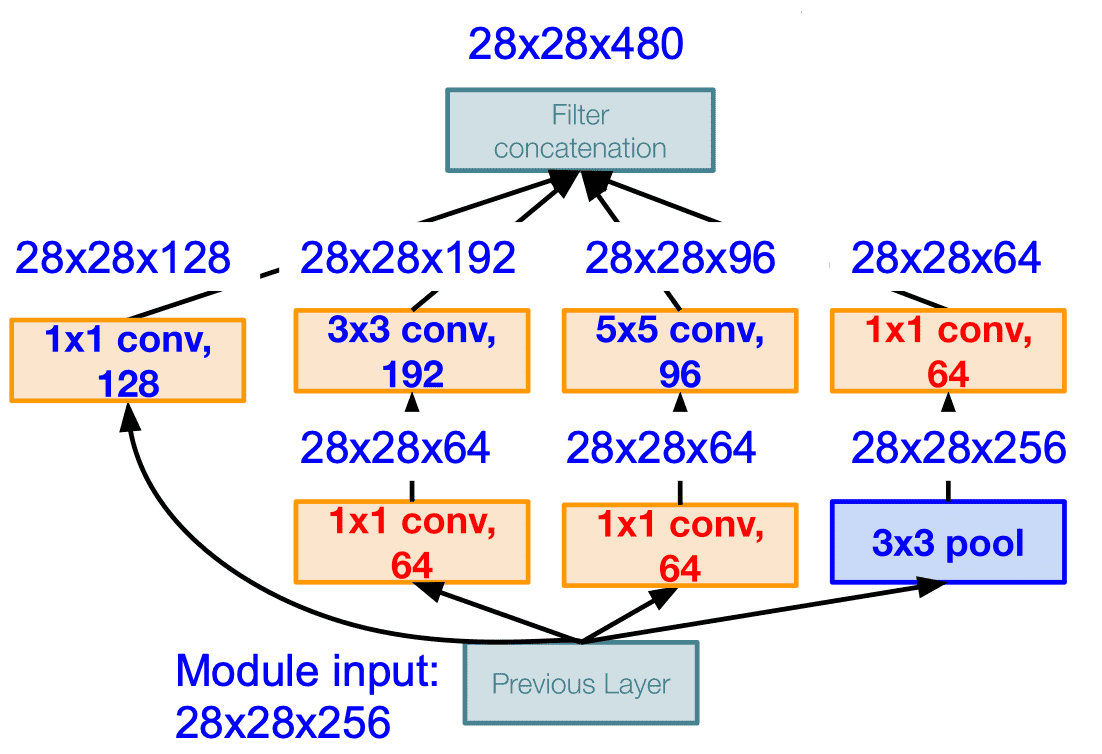
최종적으로 filter concatenation 을 하게 되면 28*28*480 으로 약 2/3 로 줄어들은 것을 확인할 수 있으며, 연산량을 모두 계산하면 358M 이 되어 절반 정도로 줄어들은 것을 볼 수 있다.
- [1*1 conv, 64] =
- [1*1 conv, 64] =
- [1*1 conv, 128] =
- [3*3 conv, 192] =
- [5*5 conv, 96] =
- [1*1 conv, 64] =
pooling layer 역시 depth 가 낮아지는 것 또한 확인할 수 있다.
구조
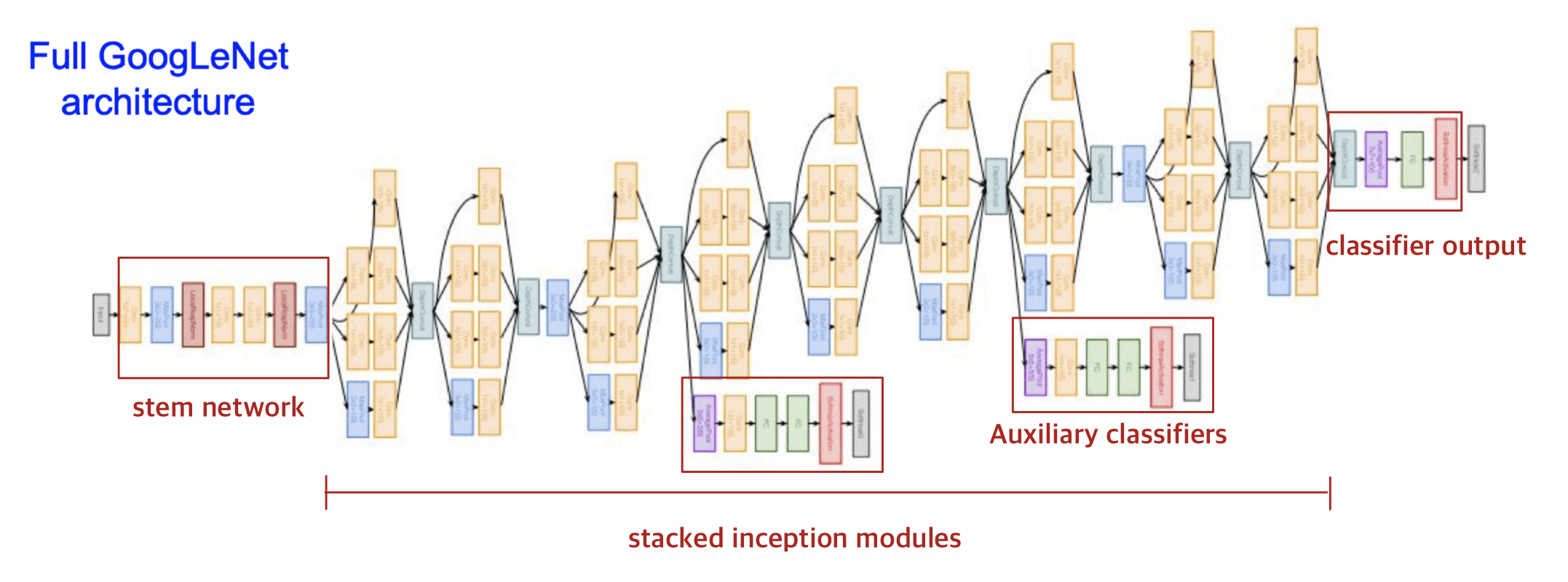
- stem network
- 전반적으로 다운샘플링
- 224 → 28
- Memory: 7.5 MB
- Params: 124K
- MFLOP: 418
- stacked inception modules
- classifier output
- FC layer 가 없다(계산이 많은 계층이기에 삭제함)
- 대신 global average pooling을 사용하여, spatial dimensions을 축소하고, 1개의 linear layer를 이용하여 클래스 스코어를 만들었다.
- Auxiliary classifiers
- 보조분류기에서도 softmax를 통해 1000개의 imageNet class를 구분하고, loss를 계산한다.
- 이렇게 하는 이유는 네트워크가 깊을 경우엔 gradient 신호가 점점 작아지게 되고 결국에는 0에 가까워질 수 있기 때문에 보조분류기를 통해 추가적인 gradient를 흘려준다.
ResNet
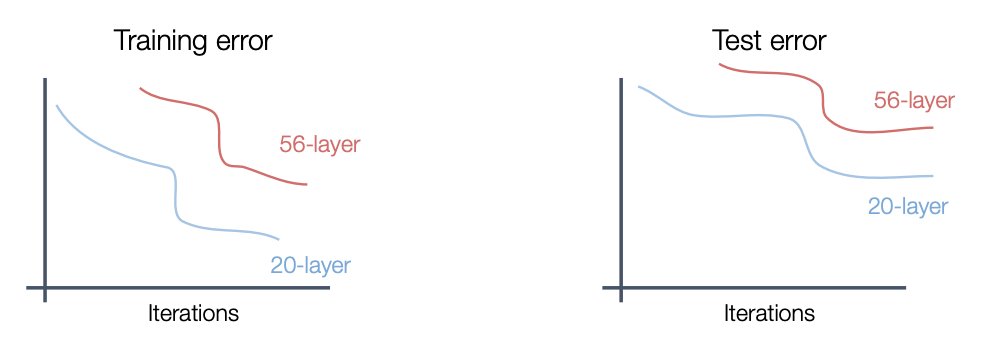
네트워크가 깊어지면 깊어질수록 위와 같은 문제가 발생할 수 있다. 실제로 ResNet개발자들이 VGGNet에 레이어를 더 깊게 쌓아본 결과로 training, test 2군데 다 56개의 레이어보다 20개의 레이어가 더 error가 낮게 나온 것으로 보아 overfitting은 아니라고 판단하였고, 깊은 모델일수록 기울기 손실 문제나 학습해야하는 파라미터수가 많아 optimization(최적화)하는데 어려움의 문제가 아닐까 하고 가설을 세워보았다. 그러고 나서 개발한 것이 Resdual Learning이다.
Residual layer
ResNet개발자들은 모델이 더 깊다면 적어도 얕은 모델만큼의 성능이 나와야하는 것이 아닌가라고 추론하였다. 그래서 우선 더 얕은 모델의 가중치를 깊은 모델의 일부 레이어에 복사하고 나머지 레이어는 input을 output으로 그대로 흘려보내는 방법(identity mapping)으로 구성하면 deeper model의 학습이 제대로 안되더라도 적어도 얕은 모델만큼의 성능은 보장된다.
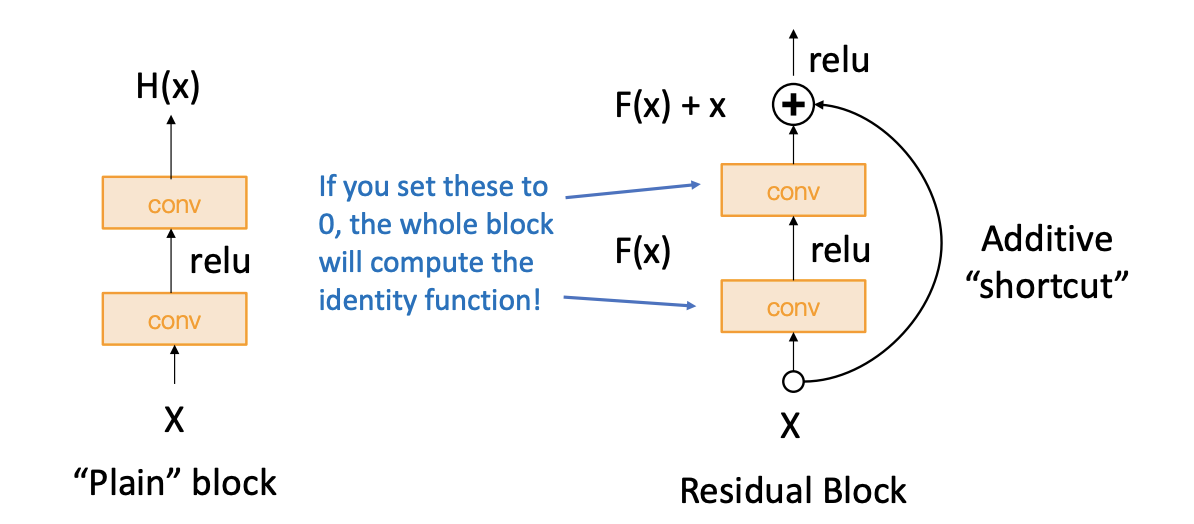
그래서 그 내용을 디자인한 모델 아키텍처는 위 그림과 같다.
H(x)를 직접 학습하는 대신에 H(x)-x를 학습할 수 있도록 만들어주는 것이다. 오른쪽의 skip connection은 가중치가 없으며 입력을 identity mappping으로 그래도 출력단으로 내보낸다. 그러면 실제 레이어는 변화량(delta)만 학습하면 된다. 그래서 최종 출력값은 input x + 변화량(residual)이 된다. 이 방법을 사용하면 학습이 더 쉬워진다. 예를들어 input=output이어야하는 상황이라면 레이어의 출력인 F(x)가 0이어야하므로(residual=0) 모든 가중치를 0으로 만들어주면 그만이다. 결론적으로 H(x)의 값을 훈련시키기 어려우니 F(x)+x를 통해 x의 변화량을 측정하는 것이 더 효율적이다라는 이야기이다. 그렇다면 이 아이디어가 아까 위에 나온 아이디어처럼 얕은 모델만큼의 성능은 보장될 수 있다. 만약 그전 얕은 모델 레이어의 가중치를 업로드하고 그 전보다 성능이 안 좋다면 나머지 레이어에 가중치가 0이 되어 얕은 모델의 성능은 나온다는 이야기이다.
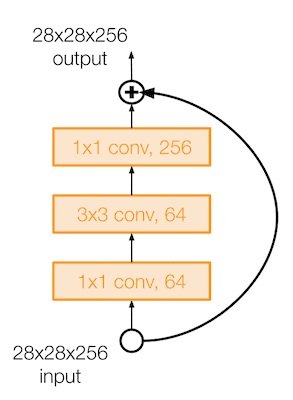
50보다 깊은 레이어를 가진 ResNet 은 GoogLeNet 처럼 bottleneck layer 를 이용한다. 이렇게 앞뒤로 1x1 conv layer 를 이용해 입/출력의 depth 는 유지하면서 계산에서는 효율적이게 만들었다.
구조

- 모든 residual block은 2개의 3*3 conv layer를 갖는다.
- 주기적으로 2배의 필터를 주고 stride 2를 이용해 공간적인 downsampling을 진행하도록 한다.
- 시작할 때 7*7 conv layer를 이용한다.
- 마지막 conv layer 뒤에 global average pooling을 이용하여 pooling을 진행한다.
- no FC layer
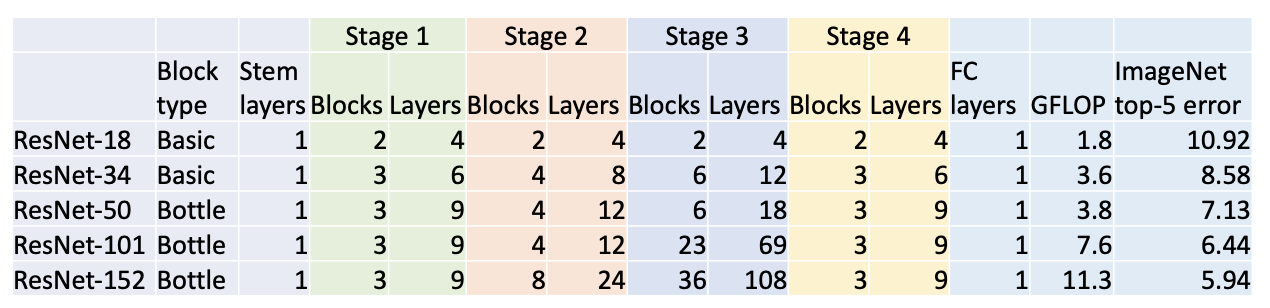
ResNet 여러 모델
activation func 위치

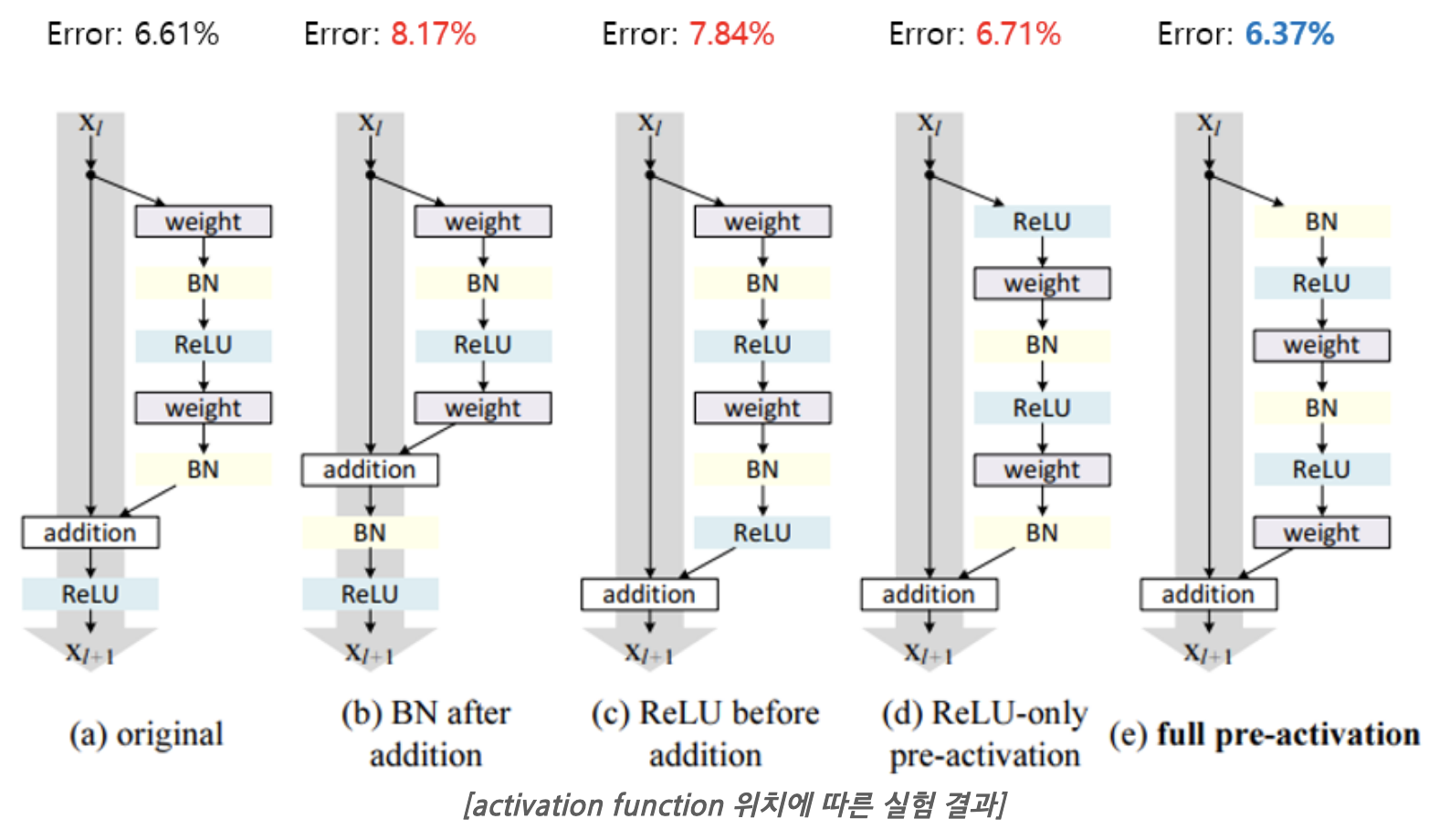
기존(a)에서 activation function의 위치를 다르게 하여 test를 진행하였다. 변형한 4가지 구조에서 full pre-activation 구조일 때 가장 test error가 낮았고, 전반적인 학습안정성도 좋아지는 결과를 보였다고 한다.
기존(a)은 BN을 거쳐 정규화가 되어도 shortcut과 더해지면서 다시 unnormalization된 채로 다음 conv연산에 전달되는 반면, full pre-activation(e)은 모든 conv연산에 normalized input이 전달되기 때문에 좋은 성능이 관찰되는 것이라고 분석하고 있다.
Comparing Complexity
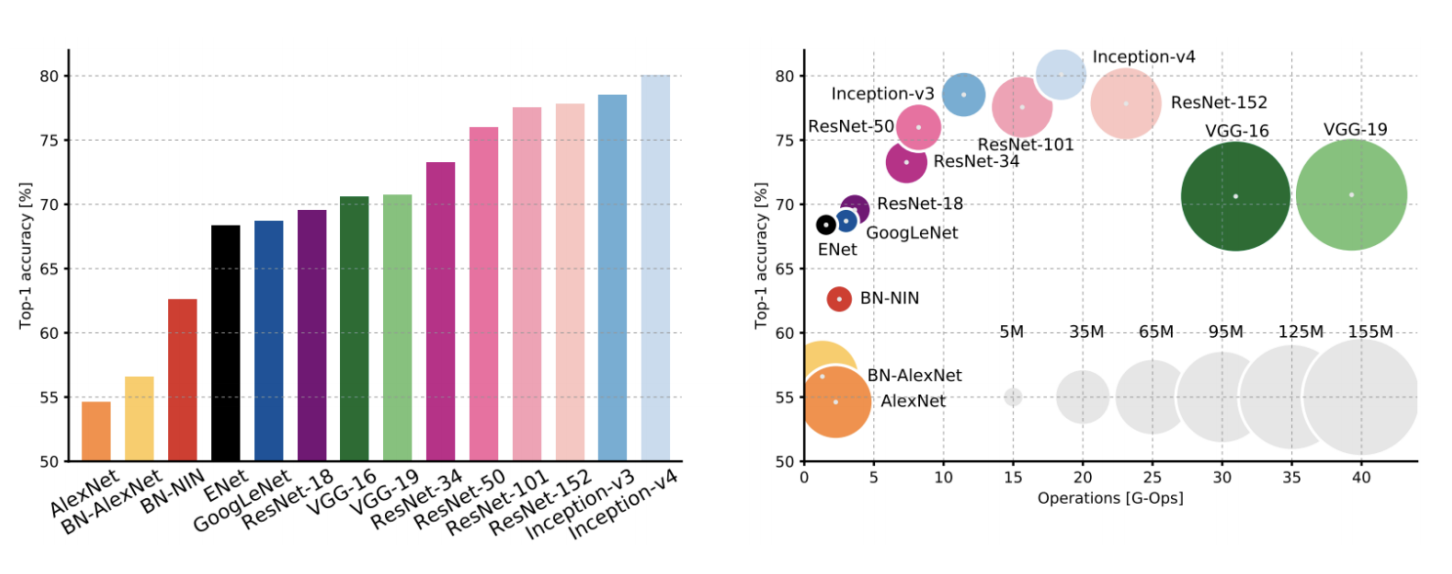
architectures의 정확도와 연산량의 trade off 관계를 정리해놓은 자료이다.
- incecption-v4 : ResNet + Inception
참고
https://www.youtube.com/watch?v=V7LiK4t80oo
https://cheong.netlify.app/machine-learning/2019-10-14---cs231n-cnn-architectures/
https://kangbk0120.github.io/articles/2018-01/inception-googlenet-review
