conv1D 모델
전체 코드는 이곳에서 확인가능하다.
데이터 분석
- 다운로드
wget https://aiffelstaticdev.blob.core.windows.net/dataset/speech_wav_8000.npz ~/aiffel/speech_recognition/data- 데이터 불러오기
import numpy as np
import os
data_path = os.getenv("HOME")+'/aiffel/speech_recognition/data/speech_wav_8000.npz'
speech_data = np.load(data_path)
print(speech_data) # <numpy.lib.npyio.NpzFile object at 0x7f38be4d5f90>
# 1초 길이의 오디오데이터 50620개로 이뤄져있고, 1개 당 8000개의 sample data를 가지고 있다.
print(speech_data["wav_vals"].shape) # (50620, 8000)
print(speech_data["label_vals"].shape) # (50620, 1)
print(len(speech_data["wav_vals"][0])) # 8000- 데이터를 무작위로 추출하여, 라벨과 맞는지 테스트
import IPython.display as ipd
import random
# 데이터 선택 (랜덤하게 선택)
rand = random.randint(0, len(speech_data["wav_vals"]))
print("rand num : ", rand)
sr = 8000 # 1초동안 재생되는 샘플의 갯수
data = speech_data["wav_vals"][rand]
print("Wave data shape : ", data.shape)
print("label : ", speech_data["label_vals"][rand])
ipd.Audio(data, rate=sr)
Train/Test 데이터셋 구성
- Text로 이루어진 라벨 데이터를 학습에 사용하기 위해서 index 형태로 바꿔준다.
# unknown, silence는 구분되지 않는 데이터의 라벨이다.
label_value = ['yes', 'no', 'up', 'down', 'left', 'right', 'on', 'off', 'stop', 'go', 'unknown', 'silence']
new_label_value = dict()
for i, l in enumerate(label_value):
new_label_value[l] = i
label_value = new_label_value
print(label_value)
# {'yes': 0, 'no': 1, 'up': 2, 'down': 3, 'left': 4, 'right': 5, 'on': 6, 'off': 7, 'stop': 8, 'go': 9, 'unknown': 10, 'silence': 11}- label data
speech_data["label_vals"]를 위에 생성해준 dictlabel_value에 해당하는 값으로 변경해준다. 예를들어 라벨이yes였던 걸0으로 바꿔주는 작업.
temp = []
for v in speech_data["label_vals"]:
temp.append(label_value[v[0]])
label_data = np.array(temp)
print(label_data) # array([ 3, 3, 3, ..., 11, 11, 11])- 학습을 위해 데이터 분리(train, test)
from sklearn.model_selection import train_test_split
sr = 8000
train_wav, test_wav, train_label, test_label = train_test_split(speech_data["wav_vals"],
label_data,
test_size=0.1,
shuffle=True)
print(train_wav.shape, test_wav.shape) # (45558, 8000) (5062, 8000)
train_wav = train_wav.reshape([-1, sr, 1]) # add channel for CNN
test_wav = test_wav.reshape([-1, sr, 1])
print(train_wav.shape, test_wav.shape) # (45558, 8000, 1) (5062, 8000, 1)- 하이퍼파라미터 설정
batch_size = 32
max_epochs = 10
# the save point - 후에 모델체크포인트 callback함수를 설정하거나 모델을 불러올 때 사용
checkpoint_dir = os.getenv('HOME')+'/aiffel/speech_recognition/models/wav'- 데이터 설정
map: dataset이 데이터를 불러올때마다 동작시킬 데이터 전처리 함수를 매핑해줌
import tensorflow as tf
def one_hot_label(wav, label):
label = tf.one_hot(label, depth=12)
return wav, label
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_wav, train_label))
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_wav, test_label))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)모델 구현
Audio 데이터는 1차원 데이터이기 때문에 Conv1D layer를 이용해서 모델을 구성
from tensorflow.keras import layers
input_tensor = layers.Input(shape=(sr, 1))
x = layers.Conv1D(32, 9, padding='same', activation='relu')(input_tensor)
x = layers.Conv1D(32, 9, padding='same', activation='relu')(x)
x = layers.MaxPool1D()(x)
x = layers.Conv1D(64, 9, padding='same', activation='relu')(x)
x = layers.Conv1D(64, 9, padding='same', activation='relu')(x)
x = layers.MaxPool1D()(x)
x = layers.Conv1D(128, 9, padding='same', activation='relu')(x)
x = layers.Conv1D(128, 9, padding='same', activation='relu')(x)
x = layers.Conv1D(128, 9, padding='same', activation='relu')(x)
x = layers.MaxPool1D()(x)
x = layers.Conv1D(256, 9, padding='same', activation='relu')(x)
x = layers.Conv1D(256, 9, padding='same', activation='relu')(x)
x = layers.Conv1D(256, 9, padding='same', activation='relu')(x)
x = layers.MaxPool1D()(x)
x = layers.Dropout(0.3)(x)
x = layers.Flatten()(x)
x = layers.Dense(256)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
output_tensor = layers.Dense(12)(x)
model_wav = tf.keras.Model(input_tensor, output_tensor)
optimizer=tf.keras.optimizers.Adam(1e-4) # 1e-4 : 0.0001
model_wav.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
metrics=['accuracy'])Model Checkpoint Callback
callback 함수가 무엇인가?
모델 학습을 진행하며, fit함수내 다양한 인자를 지정해 모니터하며 동작하게 설정할 수 있다. 아래 코드에서 콜백은 validation loss를 모니터하며, loss가 낮아지면 모델 파라미터를 저장하도록 구성되어 있다.
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_dir,
save_weights_only=True,
monitor='val_loss',
mode='auto',
save_best_only=True,
verbose=1)학습
메모리가 부족할 경우 batch_size를 줄여준다.
# fit함수는 학습결과를 리턴한다. 그 결과를 history_wav에 저장해준다.
history_wav = model_wav.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=len(train_wav) // batch_size,
validation_data=test_dataset,
validation_steps=len(test_wav) // batch_size,
callbacks=[cp_callback]
)학습결과 시각화
train_loss와 val_loss의 차이가 커진다면 overfitting일 수 있다.
import matplotlib.pyplot as plt
acc = history_wav.history['accuracy']
val_acc = history_wav.history['val_accuracy']
loss=history_wav.history['loss']
val_loss=history_wav.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()Evaluation 평가
model_wav.load_weights(checkpoint_dir)
results = model_wav.evaluate(test_dataset)
# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))model test
inv_label_value = {v: k for k, v in label_value.items()}
batch_index = np.random.choice(len(test_wav), size=1, replace=False)
batch_xs = test_wav[batch_index]
batch_ys = test_label[batch_index]
y_pred_ = model_wav(batch_xs, training=False)
print("label : ", str(inv_label_value[batch_ys[0]]))
ipd.Audio(batch_xs.reshape(8000,), rate=8000)
# 테스트셋의 라벨과 모델의 실제 prediction 결과 비교
if np.argmax(y_pred_) == batch_ys[0]:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + "(Correct!)")
else:
print("y_pred: " + str(inv_label_value[np.argmax(y_pred_)]) + "(Incorrect!)")Skip-Connection model로 적용
- skip-connection 활용
- skip-connection 참고 사이트
- skip-connection 참고 사이트 2
변경한 코드는 여기서 확인가능하다.
Spectrogram
위 코드는 1차원 시계열 데이터로 해석하는 waveform해석에 대한 코드였다.
사실 waveform은 여러 파형이 합성된 복합파이다. 그럼 다양한 파형들을 주파수 대역별로 나누어 별도로 해석할 수 있는 방법이 있지 않을까?
푸리에 변환 Fourier transform
푸리에 변환의 이해와 활용
임의의 입력 신호를 다양한 주파수를 갖는 주기함수들의 합으로 분해하여 표현하는 것
STFT(Short Time Fourier Transform)
시간의 길이를 나눠서 푸리에 변환을 하게 된다. 즉, 어떤 시간에 주파수가 변했는지를 체크하기 위함이다.
stft 기본 1
STFT 기본 2
import librosa
# 1차원의 Waveform 데이터를 2차원의 Spectrogram 데이터로 변환
def wav2spec(wav, fft_size=258): # spectrogram shape을 맞추기위해서 size 변형
D = np.abs(librosa.stft(wav, n_fft=fft_size))
return D
# 위에서 뽑았던 sample data
# data = speech_data["wav_vals"][rand]
spec = wav2spec(data)
print("Waveform shape : ",data.shape) # (8000,)
print("Spectrogram shape : ",spec.shape) # (130, 126)Waveform 데이터 대신 이 Spectrogram 포맷으로 모든 음성 데이터를 변환한 후 음성인식 모델을 학습시킨다면, 과연 Waveform과 비교했을 때 더 나은 성능을 기대할 수 있을까?
import librosa.display
librosa.display.specshow(librosa.amplitude_to_db(spec, ref=np.max), x_axis='time')
plt.title('Power spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.xticks(range(0, 1))
plt.tight_layout()
plt.show()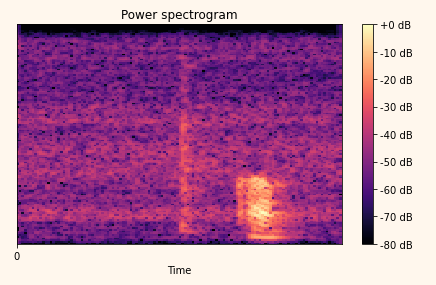
- tf.data.Dataset.from_tensor_slices()
- dataset에 데이터 불러오기
- Iterator(반복자) 생성하기

한 줄 소개가 자연스러워지는 그날까지