
배경
이번 인터파크 티켓 클론 프로젝트를 하며 랭킹 구현을 맡게되었다.
이번 포스팅에서는 내가 공연 티켓 판매수에 대한 랭킹이라는 기능을 설계하고 구현하며 적용했던 캐싱 전략과 사용 방법들에 대해서 포스팅해보려한다
요구사항
- 공연들의 랭킹을 조회하는 기능이다
- 랭킹은 티켓 판매수를 기준으로 집계한다
- 랭킹은 공연의 카테고리별로 구분돼있으며 일간, 주간, 월간 랭킹으로 구분되어 제공된다
- 랭킹은 1시간 단위로 갱신된다
랭킹의 중요한 요구사항으로는 위 네가지가 있다
전략
캐시를 사용하는 이유
우선 요구사항을 보면 랭킹은 1시간 단위로 갱신된다
즉 한시간 동안은 모든 사용자는 같은 데이터를 봐야한다. 그러기 때문에 매번 최신 랭킹을 집계하는 방법은 옳지 않다. 정해진 시간에 랭킹을 집계하고, 집계한 랭킹 데이터를 한시간동안 읽게 만들어야한다
캐시 DB 없이도 현재 사용중인 RDB 에 테이블을 하나 추가해서 해당 요구사항을 충족시킬 수 있겠지만, DB 에 속해서 접근하여 데이터를 가져오는 것보다 캐시에서 데이터를 가져오는 방식이 DB 부하도 줄이고 성능적으로 좋기 때문에 캐시를 사용하기로했다
캐시 DB 선택
우선 랭킹이라는 기능은 분산 환경에서도 모든 사용자에게 똑같이 보여줘야하는 기능이기 때문에 로컬 캐시말고 글로벌 캐시를 이용해야했다. 그리고 글로벌 캐시로 많이 사용되고 좋은 성능과 다양한 자료구조를 지원하는 Redis 를 선택했다
읽기 전략
읽기 전략으로는 Look Aside 방식을 선택했다
가장 무난한 방법이고 Look Aside 방식의 단점인 캐시에 데어터가 없어 Cache miss 가 지속적으로 발생할 경우 DB 에 부하가 몰린다는 단점이 있는데, 나는 별도의 스케줄러를 이용해서 주기적으로 캐시 데이터를 갱신해주며 데이터 갱신과 함께 Cache Warming 작업을 수행해주기 때문에 해당 단점은 보완될거라고 생각했다
쓰기 전략
쓰기 전략은 기본적으로 스케줄러를 통한 주기적인 갱신을 기반으로 가져간다. 요구사항 자체가 정해진 시간마다 데이터를 업데이트 해줘야하기 때문이다.
그리고 만약 어플리케이션이 막 뜨면서 캐시에 데이터가 없고 스케줄러가 아직 작동되지 않아서 캐시에 데이터가 없는 경우에도 랭킹 서비스를 문제없이 이어나가야한다
이때를 대비하는 방식으로 Cache miss 가 발생했을 때 DB 에서 데이터를 조회하고 캐시를 갱신하는 방식인 Write Around 방식까지 추가했다
구현
Redis 설정
레디스 설정 코드다. 나는 RedisTemplate 를 직접 사용할 일이 있어서 RedisTemplate 을 등록했지만 스프링의 캐시 어노테이션으로만 활용한다면 CacheManager 를 등록해도된다
💡 주의점으론 나는 Redis 에 저장되는 데이터에 LocalDateTime 타입이 있는데, 이때 ObjectMapper 에 JavaTimeModule 을 등록해주지 않으면 에러를 맛볼 수 있다
@Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
public String host;
@Value("${spring.data.redis.port}")
public int port;
@Bean
public LettuceConnectionFactory lettuceConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
public ObjectMapper objectMapper() {
return new ObjectMapper().registerModule(new JavaTimeModule());
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer(objectMapper()));
return redisTemplate;
}
}랭킹 서비스
먼저 랭킹을 조회하는 서비스 로직을 구현했다
@Service
@RequiredArgsConstructor
public class RankingService {
private final ShowRepository showRepository;
@Transactional(readOnly = true)
public RankingResponse getShowRanking(RankingRequest rankingRequest) {
ShowCategory category = ShowCategory.of(rankingRequest.category());
LocalDateTime startAt = PeriodType.of(rankingRequest.period()).getStartAt();
LocalDateTime endAt = LocalDateTime.now();
List<ShowStatisticDto> showStatistic = showRepository.findShowStatistic(category, startAt, endAt);
return ShowMapper.toRankingResponse(showStatistic, startAt, endAt);
}
}처음엔 이 서비스 로직에 스프링에서 지원하는 @Cacheable 어노테이션을 활용하려했다.
근데 @Cacheable 어노테이션은 속성값인 value 를 통해서 캐시 키를 구분짓는데 현재 로직은 카테고리와 집계기간에 따라 랭킹을 구하는 로직이기 때문에 하나의 통일된 캐시 키로 캐시를 관리할 수 없기 때문에 해당 어노테이션을 활용하지 못했다
커스텀 AOP
@Cacheable 어노테이션을 활용할 수 없었기에 커스텀 어노테이션과 Aspect 를 구현해서 사용하려했다
먼저 랭킹 캐시에 이용되는 어노테이션을 만들고
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface CacheableRanking {
}그리고 Read Around 와 Write Around 방식을 수행해줄 Aspect 를 만들었다
@Aspect
@RequiredArgsConstructor
public class CacheRankingAspect {
private final RedisTemplate<String, Object> redisTemplate;
private final ObjectMapper objectMapper;
@Pointcut("@annotation(dev.hooon.common.aop.annotation.CacheableRanking)")
private void cacheableRankingAnnotation() {
}
private String generateCacheKey(RankingRequest rankingRequest) {
return "R_" + rankingRequest.category() + rankingRequest.period();
}
@Around("cacheableRankingAnnotation() && args(rankingRequest, ..)")
public Object getOrCacheRanking(ProceedingJoinPoint joinPoint, RankingRequest rankingRequest) throws Throwable {
String cacheKey = generateCacheKey(rankingRequest);
Object cacheValue = redisTemplate.opsForValue().get(cacheKey);
// 캐시에 데이터가 있으면 캐시 데이터 리턴
if (cacheValue != null) {
return objectMapper.convertValue(cacheValue, RankingResponse.class)
}
// 케시에 데이터가 없으면 실제 로직 호출 후 캐싱
Object rankingResponse = joinPoint.proceed();
redisTemplate.opsForValue().set(cacheKey, rankingResponse, Duration.ofMinutes(70));
return rankingResponse;
}
}이제 직접만든 @CacheableRanking 어노테이션을 랭킹 서비스로직에 붙이면 끝이었는데….
문제가 있었다
나는 쓰기 전략으로 Write Around 방식과 스케줄러로 주기적으로 캐시를 갱신해주는 방식을 사용한다고 했는데 스케줄러에서도 랭킹을 조회하기 위해 RankingService 를 사용한다
근데 RankingService 에는 캐시 프록시가 추가되어서 스케줄러에서 캐시를 갱신하려고 DB에서 랭킹을 조회하려는데 캐시에 있는 데이터를 읽어서 갱신해버리는 상황이 생기게 되었다 (현재 TTL 은 넉넉하게 1시간보다 긴 70분으로 설정한 상황)
순수 서비스 로직과 랭킹을 입힌 서비스 로직을 분리
결국 AOP 는 때내고 AOP 에서 수행하던 캐싱 로직이 추가된 퍼사드 클래스를 구현했다. 그리고 스케줄러에서는 순수한 RankingService 를 이용할 수 있게되었다
@Component
@RequiredArgsConstructor
public class RankingCacheFacade {
private final RankingService rankingService;
private final RedisTemplate<String, Object> redisTemplate;
private final ObjectMapper objectMapper;
private String generateCacheKey(RankingRequest rankingRequest) {
return String.join("_", List.of("R", rankingRequest.category(), rankingRequest.period()));
}
public RankingResponse getShowRankingWithCache(RankingRequest rankingRequest) {
String cacheKey = generateCacheKey(rankingRequest);
Object cacheValue = redisTemplate.opsForValue().get(cacheKey);
// 캐시에 데이터가 있으면 캐시 데이터 리턴
if (cacheValue != null) {
return objectMapper.convertValue(cacheValue, RankingResponse.class);
}
// 케시에 데이터가 없으면 실제 로직 호출 후 캐싱
RankingResponse rankingResponse = rankingService.getShowRanking(rankingRequest);
redisTemplate.opsForValue().set(cacheKey, rankingResponse, Duration.ofMinutes(70));
return rankingResponse;
}
}스케줄러를 통한 주기적 갱신
한시간마다 각 카테고리와 집계기간 별로 랭킹을 조회해서 캐시를 갱신한다
@Component
@RequiredArgsConstructor
public class RankingScheduler {
private final RankingService rankingService;
private final RedisTemplate<String, Object> redisTemplate;
private String generateCacheKey(RankingRequest rankingRequest) {
return String.join("_", List.of("R", rankingRequest.category(), rankingRequest.period()));
}
@Scheduled(cron = "0 0 0/1 * * *")
@SchedulerLock(name = "ranking_1", lockAtLeastFor = "10m", lockAtMostFor = "70m")
public void cacheEvictRanking() {
// category, periodType 을 통해 이중 반복문
Arrays.stream(ShowCategory.values())
.forEach(category -> Arrays.stream(PeriodType.values())
.forEach(periodType -> {
// category, periodType 별로 랭킹 조회
RankingRequest rankingRequest = new RankingRequest(category.name(), periodType.name());
RankingResponse rankingResponse = rankingService.getShowRanking(rankingRequest);
// 조회한 랭킹을 redis 캐시에 등록
String cacheKey = generateCacheKey(rankingRequest);
redisTemplate.opsForValue().set(cacheKey, rankingResponse);
}));
}
}결과 테스트
테스트는 동일 API 를 10번 호출하고 실행시간을 비교는 방식으로 진행했다. 그리고 쿼리를 날리는 시점에 DB 추가적인 로그를 남기도록 설정했다
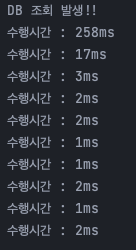
실행하면 결과는 아래처럼 첫 조회에 DB 조회가 발생하면 DB 조회 로그가 찍히며 응답시간이 258ms 가 걸리지만 아래부터는 캐시에서 조회하며 응답시간이 평균적으로 3ms 정도가 나오는 것을 볼 수 있다
마치며
Redis 를 활용한 캐싱을 이용해 공연 랭킹기능을 구현하는 과정에 대한 포스팅을 마쳤다 👏
지금까지 캐시는 단순히 조회 성능을 올리기위해서만 사용한다고 생각했다
하지만 이번 랭킹의 요구사항도 그렇고 캐싱을 공부하면서 캐싱이 단순히 조회 성능을 끌어올리기 위해서 쓰이는 것 이외에도 여러 상황에 유용하게 사용할 수 있다는 것을 알게되었다
확실히 기술을 아는 것도 중요하지만 직접 써보고 기술을 활용할 수 있는 시야를 넓히는게 중요한 것 같다 😎
