주제 배경
이번에 티켓팅 프로젝트를 하면서 예매대기 기능과 랭킹 기능을 맡으며 스케줄러 모듈을 분리하여 서버를 별도로 구성하게 되었다
그리고 스케줄러 서버의 failover 를 구현하기 위해 두 대 이상의 서버를 띄우는 방향으로 스케줄러 서버를 설계했다
그런데 이는 문제가 있었다. 바로 스케줄러 서버는 분산 환경에서도 스케줄링 작업이 중복으로 실행되지 않게 동기화해줘야했다
이에 대해서 멘토님에게 조언을 구했고 리더 일렉션이라는 개념을 소개해주셨다.
리더 일렉션
리더 일렉션이란 클러스터링같은 분산시스템 환경에서 일관성과 안정성을 유지하기 위해
쓰이며 작업을 수행하거나 다른 노드들간의 동기화를 수행하는 리더 노드를 선출하는 개념이다
이 개념을 스케줄러 서버에 적용하면 여러개의 스케줄러 서버중 실제로 작업을 수행하는 리더 서버를 선출하는 방법이다.
주키퍼
이러한 리더 일렉션을 구현하는 기술로 주키퍼가 있었다. 하지만 프로젝트 규모에 비해 주키퍼를 적용하고 운영하는데 비용이 커서 주키퍼는 현재 프로젝트에 있어 오버엔지니어링이라고 생각했다. 그래서 다른 기술을 찾아보던 중 shedlock 이라는 기술을 발견했다
ShedLock
shedlock 은 분산 시스템에서 잠금 관리를 제공하여 여러 서버 간의 스케줄링 작업이 동기화되어 수행될 수 있도록 조절해주는 오픈소스 라이브러리다
shedlock 의 작동 방식은 아래와 같다
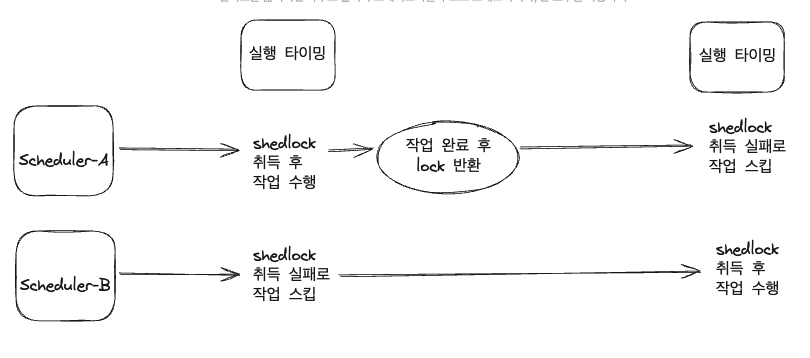
여러 스케줄러가 동시에 실행될 때 하나의 스케줄러가 스케줄러가 락을 잡고 작업을 수행한다. 그리고 락을 잡지 못한 다른 스케줄러들은 작업을 스킵하고 다시 스케줄링 시간을 기다린다.
작업을 마친 스케줄러는 락을 반환한다
그림에서 나타냈듯이 어떤 스케줄러가 작업을 수행하는지 보장해주지는 않지만 하나의 스케줄러만 작업을 수행할 수 있도록 동기화 시켜준다
ShedLock 설정
먼저 의존성을 추가한다
implementation 'net.javacrumbs.shedlock:shedlock-spring:5.1.0'
implementation 'net.javacrumbs.shedlock:shedlock-provider-redis-spring:5.1.0'shedlock 의 구현에는 반드시 저장소가 필요한데, 나는 현재 프로젝트에 Redis 가 사용되기도 하고 스케줄링을 동기화하는데 사용되기 때문에 데이터가 영속될 필요없어서 가벼운 인메모리 저장소인 Redis 을 선택했다(다른 저장소를 이용한 방법은 아래 깃허브주소로 들어가면 자세히 나온다)
@EnableSchedulerLock 어노테이션을 등록해준다(속성은 아래에서 자세히 설명하겠다)
Redis 를 사용한 LockProvider 를 설정한다 (Redis 를 등록하는 과정은 특별히 넣지 않았다)
@Configuration
@EnableScheduling
@EnableAsync
@EnableSchedulerLock(defaultLockAtLeastFor = "10s", defaultLockAtMostFor = "30s")
public class SchedulerConfig {
@Bean
public LockProvider lockProvider(RedisConnectionFactory redisConnectionFactory) {
String lockEnv = System.getProperty("spring.profiles.active");
return new RedisLockProvider(redisConnectionFactory, lockEnv);
}
@Bean("scheduler")
public TaskScheduler taskScheduler() {
ThreadPoolTaskScheduler executor = new ThreadPoolTaskScheduler();
executor.setPoolSize(5);
executor.setThreadNamePrefix("scheduler-thread-");
executor.initialize();
return executor;
}
}이제 최종적으로 스케줄러에 ShedLock 을 적용하면 끝이다
@Slf4j
@Component
@RequiredArgsConstructor
public class WaitingBookingScheduler {
private final WaitingBookingFacade waitingBookingFacade;
@Scheduled(cron = "0 0/10 * * * *")
@SchedulerLock(name = "wb_1", lockAtLeastFor = "9m", lockAtMostFor = "15m")
public void scheduleWaitingBookingProcess() {
waitingBookingFacade.processWaitingBooking();
}
@Scheduled(cron = "0/5 * * * * *")
@SchedulerLock(name = "wb_2", lockAtLeastFor = "4s", lockAtMostFor = "8s")
public void scheduleExpiredWaitingBookingProcess() {
log.info("start time : {}", LocalDateTime.now());
waitingBookingFacade.processExpiredWaitingBooking();
}
}shedlock 설정에는 세가지 핵심 설정이 있다
name- 락의 이름이며 기준으로 락이 적용된다. 즉 다른 스케줄링 작업끼리는 이름이 겹치면 안된다
lockAtLeastFor- 락을 잡고있는 최소 시간. 즉 이 시간만큼은 무조건 락을 잡고있는다
- 크론식을 사용한다면 최소 시간을 반복시간보다 같거다 크게 설정하면 스케줄러가 돌아야되는 시간에 락이 걸려있어서 작업이 한번 스킵되는 현상이 발생할 수 있으므로 반복 시간보다 작게 설정해야됨
lockAtMostFor- 락을 잡고있는 최대 시간. 즉 작업이 아무리 길어지더라도 해당 시간이 지나면 락을 풀어버린다
- 약
lockAtMostFor을 반복시간 보다 작게 설정하면 락을 반복시간에 도달하기 전에 풀어버려서 문제 생길 수 있지만 크론식으로 설정하면 특정 시간에 실행되는 구조라서 모든 스케줄러 시간이 동기화만 돼있다면 해당 설정으로 문제가 발생하진 않음
💡 만약
lockAtMostFor이나lockAtMostFor을 설정하지 않으면 위에 설정에서 설정한defaultLockAtLeastFor,defaultLockAtMostFor이 적용된다
shedlock 적용 후 동작 확인
docker 를 통해서 두개의 인스턴스를 올려서 테스트해봤다
5초 단위로 실행되는 스케줄러에 실행시간에 대한 로그를 찍어봤다

빨간 동그라미가 실행시간 중에 초를 표시한 부분인데 인스턴스 간의 중복없이 스케줄러 실행 시간에 하나의 스케줄러만 실행되는 것을 볼 수 있다
💡 여기서 하나의 서버를 다운시켜도 문제없이 다른 스케줄러 서버가 작업을 수행한다. 즉 스케줄러 서버의 failover 를 보장해준다
마치며
shedlock 을 통한 여러 서버 간의 스케줄링 작업이 동기화를 구현하며 스케줄러 서버의 failover 를 구현해봤다.
shedlock 이 처음에 생각했던 리더 일렉션의 개념과 일치하진 않지만 리더 일렉션의 목적인 스케줄러 서버의 failover 를 구현하는 것이라는 목적은 이뤘다. 그리고 shedlock 기술은 공부하고 적용하는데 큰 비용이 들지 않았기 때문에 그런점에 장점이 또 있는 것 같다
지금은 shedlock 을 통해 문제를 해결했지만 제대로된 리더 일렉션을 경험해보고 싶은 생각이 있다. 그래서 추후에 주키퍼에 대해 공부하고 주키퍼로 마이그레이션 해볼 생각이다 👍
참고 레퍼런스
