스프링 배치 공부를 하면서 FaultTolerantChunkProcessor를 공부하게되었고, 특히 Retry 쪽에서 여러가지를 테스트해보며 겪었던 이상한(?) 현상에 대한 경험을 공유해보자합니다.
FaultTolerant 란
- 청크 기반 스텝에서 Retry 기능과 Skip 기능을 제공하는
ChunkProvider와ChunkProcessor를 제공한다SimpleChunkProvider와SimpleChunkProcessor를 상속하여 구현되었다
- 편리하게 제공되는 api를 이용해서 다양한 설정, 정책을 쉽게 등록할 수 있다(limit, backoff, exceptionType…)
FaultTolerant의 주요 특징
- Skip의 최대 횟수는 전체 청크 프로세스에서 적용된다. 즉 limit이 3이라면, reader, processor, writer 포함 최대 3회다
- Retry는 각 컴포넌트별로 RetryTemplate이 적용된다. 즉 limit이 3이라면 reader, processor, writer 별 각각 최대 3회가 주어진다.
- Retry는
RetryContext라는걸 가지는데,RetryContext에는 Retry에 필요한 정책이나 현재 retry 횟수 등 Retry 작업에 필요한 다양한 정보를 가진다. - 그리고 각 컴포넌트별로 RetryContext는 독립적으로 가져간다
- Retry는
기이한 현상 발생
Retry 횟수를 간단하게 테스트하기 위해 아래 코드를 실행시켜봤어요
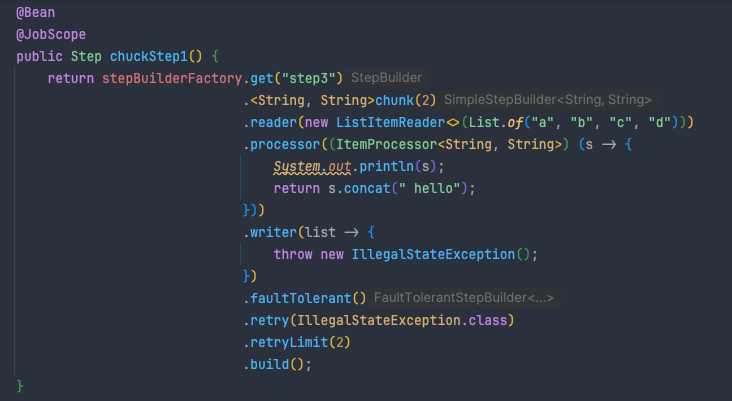
writer에서 예외를 발생시키고 retryLimit이 2이므로 아래와 같은 결과를 생각했습니다
a
b
a
b
a
b
exception!근데 얼래?
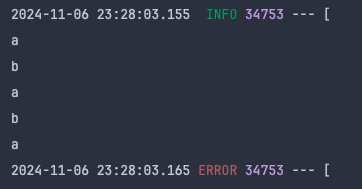
이런 결과가 나왔다. b가 출력이 안됐죠
디버깅 모드로 흐름을 돌려보니까 아래와 같았습니다(Reader는 생략)
Processor x 2 → Writer → Processor x 2 → Writer → Processor X 1
이상하죠?
왜 마지막 Processor는 한번밖에 실행이 안될까요?
너무 궁금해서 디버깅 모드로 파해쳐보기로 했습니다.
핵심 클래스 소개
FaultTolerant에서 핵심이 되는 클래스를 소개하겠습니다.
FaultTolerantChunkProcessor: 핵심 transform, write 로직이 모두 들어있음RetryTemplate: 핵심 Retry 처리가 들어있음
대부분 위 두 클래스를 핵심적으로 수행됩니다. 물론 중간에 건너가는 클래스도 많지만 핵심은 이 두 클래스인 것 같아요.
FaultTolerantChunkProcessor
FaultTolerantChunkProcessor 의 핵심 메소드는 ItemProcessor을 가지고 로직을 수행하는 transform() 메소드와 ItemWriter를 가지고 로직을 수행하는 write() 메소드가 있습니다.
그리고 이 현상에서 중요한 역할을 하는 Inner class가 하나 있습니다. 바로 UserData 클래스입니다
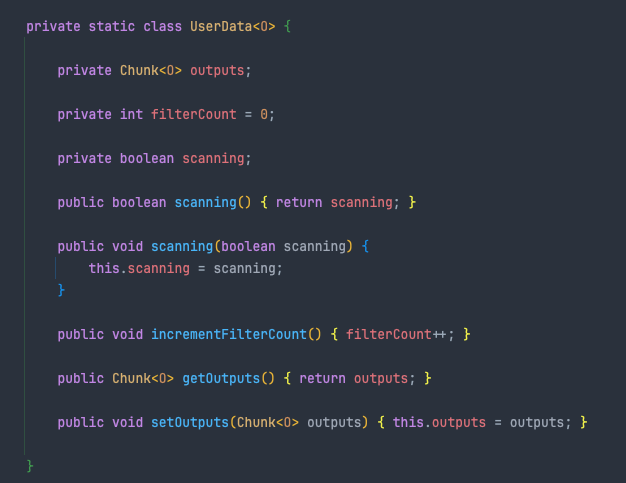
위치는 클래스 최하단에 존재하고 눈여겨볼 속성은 scanning이라는 불린 타입의 변수입니다. 일단 존재만 알아두시죠.
해당 UserData는 FaultTolerantChunkProcessor 안에서 생성되고 관리되며 transform(), write() 로직 모두에 사용됩니다.
그러면 이제 정확히 어떤 부분에서 이상 현상을 유발했는지 까보시죠
Retry 횟수 소진시 처리
당연하게도 Retry 횟수를 모두 소진하면 더이상 재시도를 수행하지 않습니다.
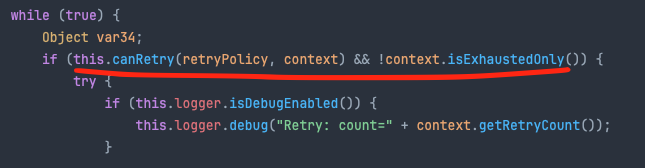
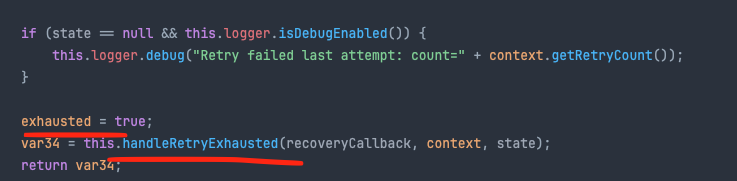
실제로 RetryTemplate에서 Retry 소진시 처리쪽 코드입니다.
첫번째 이미지에서 retry 횟수가 남아있으면 canRetry() 메소드에서 true가 나오게되고, 길어서 다 올리진 못했지만 if문 안쪽에 return 문이 있어서 while문을 빠져나갑니다.
하지만 retry 횟수를 모두 소진해서 canRetry() 메소드에서 false가 나오게되면 if문을 타지 못하고 두번째 이미지 코드를 타게됩니다.
결국 handleRetryExhuasted() 메소드를 통해서 예외가 던져집니다
네 굉장히 당연한 흐름입니다. 사실 문제는 이쪽이 아니고, 아까 위에서 소개했던
FaultTolerantChunkProcessor클래스입니다.
FaultTolerantChunkProcessor - write() 메소드의 retry 횟수 소진시 처리
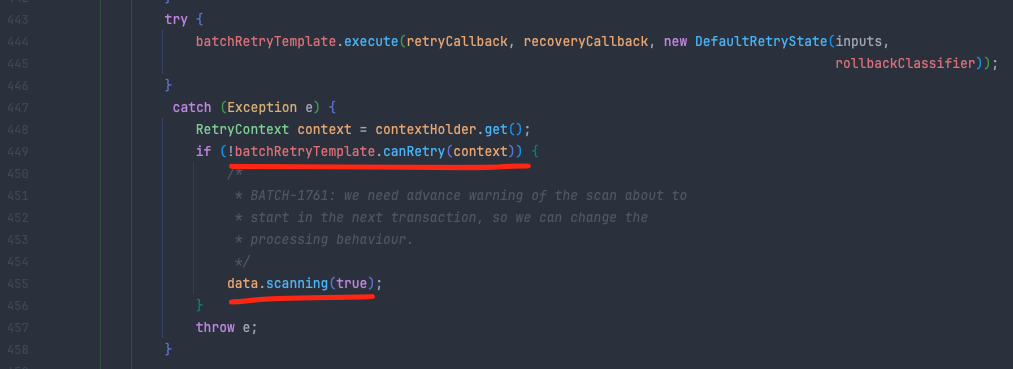
해당 코드는 FaultTolerantChunkProcessor 클래스의 write() 메소드의 핵심인 실제 execute() 쪽 코드입니다.
보면 예외가 발생시 catch 했을때, canRetry() 검사를 합니다. 그리고 false면 if문을 타게되죠
그리고 아까 말씀드렸던 scanning 변수를 true로 설정합니다. 그리고 true가 된 scanning은 transform() 작업에 영향을 주게됩니다.
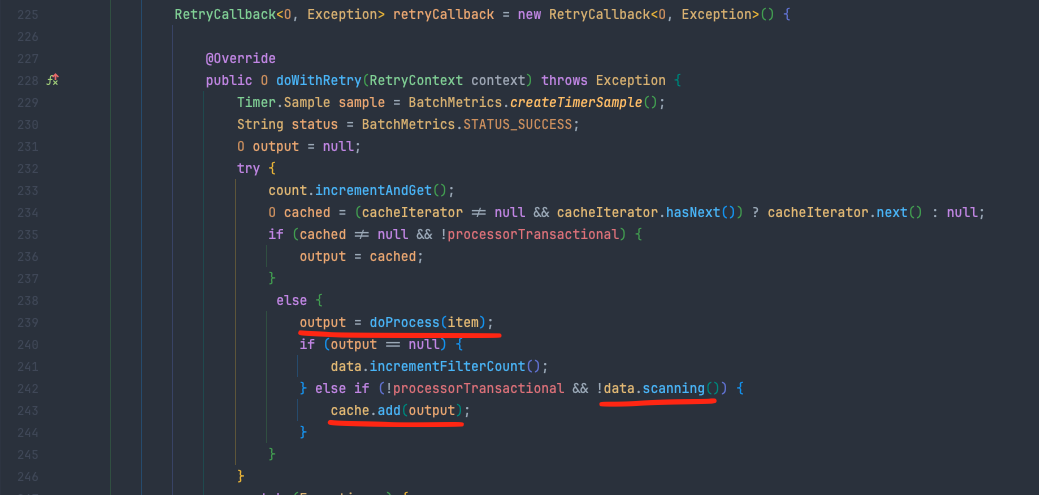
아래는 FaultTolerantChunkProcessor 클래스의 transform() 메소드 안에있는 process에 사용되는 retryCallback 메소드입니다.
보시면 scanning이 false이면 cache라는 리스트에 process 결과인 output을 쌓는걸 볼 수 있습니다.
아래는 transform() 메소드의 최종적으로 execute하는 부분입니다.
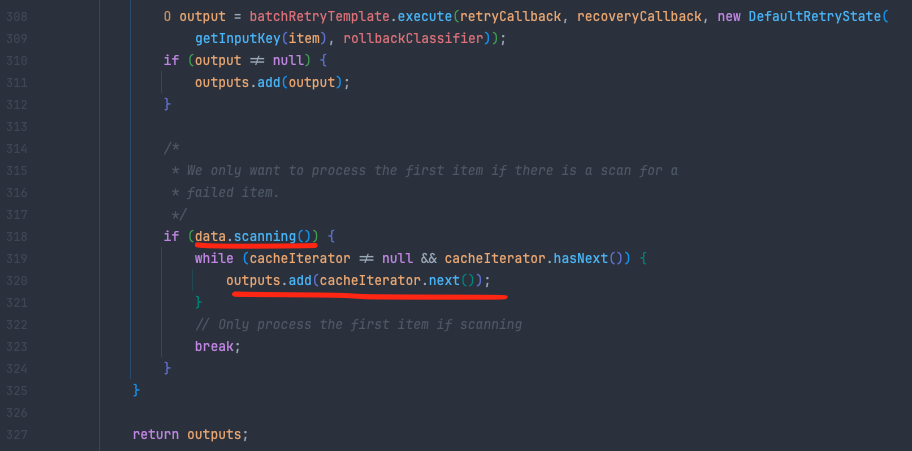
실제로 한번의 execute() 이후에 scanning이 true면 캐시에 있는 아이템을 결과에 쭉 쌓는걸 볼 수 있습니다.
친절하게 주석도 달려있죠? scanning이라면 첫번째 아이템만 process 하겠다고 적혀있습니다.
결론
그래서 결론적으로 a b a b 까지 정상 실행되고 writer에서 예외가 발생하면서 writer의 retry count가 소진되면서 scanning이 true로 바뀌고, 다음 process 작업은 첫번째 아이템만 수행되고 캐싱된 아이템을 채워서 종료시켜서 저는 a b a b a 라는 결과를 봤던거였습니다.
이런 흐름의 의도는 아무래도 writer에서
retry count가 소진돼서 예외를 던지는게 확정이니까, processor의 작업이 사실상 의미가 없어서, 불필요한process작업을 줄이고자 이렇게 구현한게 아닐까 생각이 듭니다
