
시작에 앞서
이번 포스팅에서는 스프링 배치 환경의 배치 서버에서 겪을 수 있는 마스터 DB의 부하 문제에 대해서 다뤄볼 예정입니다. 👀
실제로 스프링 배치 환경에서 개발을 하다보면 많은 사람들이 겪을만한 문제기 때문에, 이렇게 포스팅하게 되었습니다
우선 문제 상황을 설명하기 전에 어떤 환경인지 설명드리겠습니다.
DB : AWS RDS + Master/Slave기반의 클러스터
Batch : 스프링 배치 기반의 청크기반 배치 + 간단한 Tasklet기반 배치
문제 상황
우선 문제 상황을 간단히 설명하자면, Master DB서버가 부하를 너무 많이 받는다는 것입니다.
모든 배치 작업의 부하를 Master DB서버가 홀로 받고 있었고, 나머지 읽기전용 서버들은 일을 안하고 놀고 있었습니다.
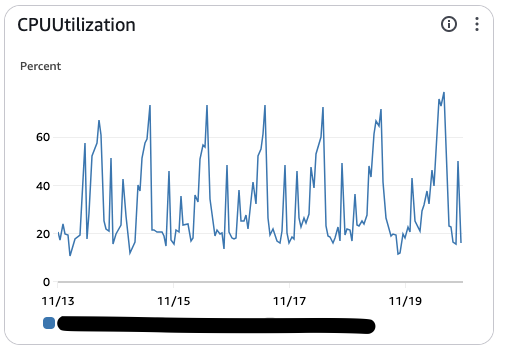
- 1번 이미지 : Master DB
- 2번 이미지 : Reader DB
보시는 바와 같이, 마스터 서버를 제외한 읽기서버 두대가 꽤나 놀고 있습니다.
서비스 특성상 대부분의 부하가 실시간 트래픽 보다는 무거운 배치 작업에서 나오는 트래픽이 주가 됐기 때문에 배치 작업에서 일을 못하는 읽기서버들은 평화로웠죠…
데이터 소스 이중화 설정을 하면 되는거 아닌가?
기존의 일반 서버들은 아래와 같은 방법으로 Lazy커넥션을 제공해서 해당 Transaction이 readOnly가 true/false 여부에 따라서 데이터소스를 구분해서 제공했습니다.
return new LazyConnectionDataSourceProxy(replicationRoutingDataSource);하지만 이는 스프링 배치에서는 쉽지않죠.
그 이유는 스프링 배치의 트랜잭션 처리 방식에 대해서 알아야합니다.
스프링 배치의 트랜잭션 처리 방식
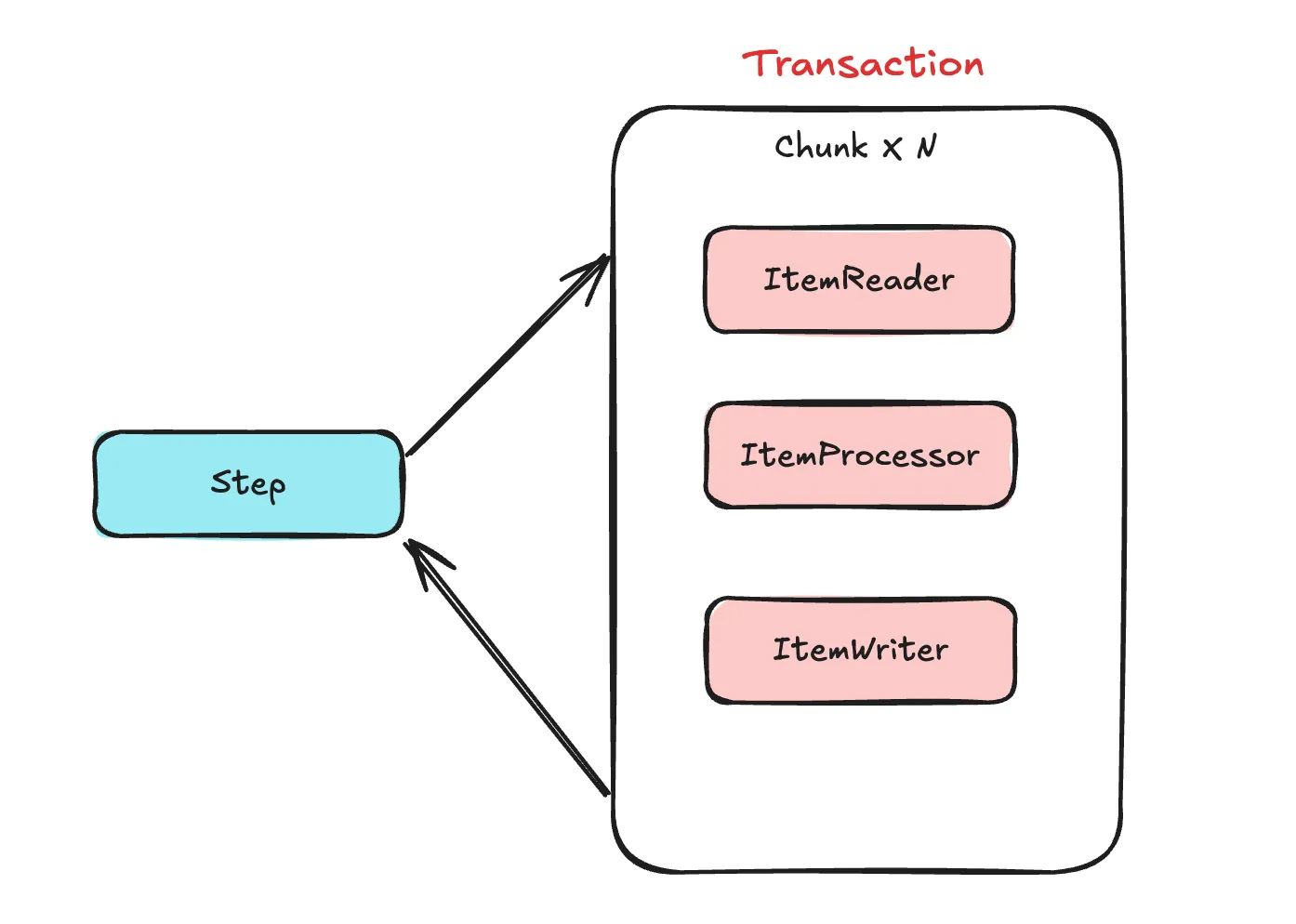
간단하게 도식화 해보자면 위 이미지와 같습니다.
청크 단위로 트랜잭션을 처리하고, 만약 Step구현체가 Tasklet기반의 구현체더라도 유사하게 Tasklet단위로 트랜잭션을 가져갑니다.
이렇게 트랜잭션 처리 설계가 된 이유에는 장애복구, 데이터 정합성, 대용량 작업 시 리소스 관리 등의 이유가 있으며, 아주 타당하고 좋은 설계입니다.
하지만 결국 이러한 특징 때문에 항상 Write작업이 껴있는 상황에서는 모든 트랜잭션은 Master DB를 바라볼 수 밖에없었고, 이는 곧 Master DB로 모든 부하가 몰리는 문제로 이어졌습니다.
ItemReader의 트랜잭션을 분리하자!
청크 기반의 배치 작업에서 주요 작업은 세 가지로 분류됩니다.
데이터 Read: ItemReader데이터 Process: ItemProcessor데이터 Write: ItemWriter
여기서 Write작업은 반드시 Master DB를 바라봐야하지만, Read작업은 굳이 Master DB에서 작업을 할 필요가 없다고 판단했습니다.
그리고 ItemReader를 별도의 읽기전용 DataSource에서 동작하도록 설정을 추가했습니다.
ItemReader 트랜잭션 분리를 위한 핵심 설정 및 사용법
저희는 편히 read작업을 하기 위해서 주로 QueryDSL을 이용했습니다. 그리고 이러한 JPA기반의 read작업에서 별도의 DataSource를 할당하기 위해선, 읽기전용 DataSource가 할당된 EntityManagerFactory가 필요했습니다.
아래는 EntityManagerFactory 설정 코드입니다.
/**
* 배치에서 사용하는 Master/Slave 전용 EntityManagerFactory
*/
@Configuration
@EnableConfigurationProperties(JpaProperties::class, HibernateProperties::class)
@EnableJpaRepositories(
basePackages = [PACKAGE],
entityManagerFactoryRef = MASTER_ENTITY_MANAGER_FACTORY,
transactionManagerRef = MASTER_TX_MANAGER
)
class BatchEntityManagerConfig(
private val jpaProperties: JpaProperties,
private val hibernateProperties: HibernateProperties,
private val metadataProviders: ObjectProvider<Collection<DataSourcePoolMetadataProvider>>,
private val entityManagerFactoryBuilder: EntityManagerFactoryBuilder
) {
companion object {
const val PACKAGE = "com.hello.batch"
const val MASTER_ENTITY_MANAGER_FACTORY = "entityManagerFactory"
const val READER_ENTITY_MANAGER_FACTORY = "readerEntityManagerFactory"
const val MASTER_TX_MANAGER = "batchTransactionManager"
}
@Primary
@Bean(name = [MASTER_ENTITY_MANAGER_FACTORY])
fun entityManagerFactory(dataSource: DataSource): LocalContainerEntityManagerFactoryBean {
return EntityManagerFactoryCreator(
properties = jpaProperties,
hibernateProperties = hibernateProperties,
metadataProviders = metadataProviders,
entityManagerFactoryBuilder = entityManagerFactoryBuilder,
dataSource = dataSource,
packages = PACKAGE,
persistenceUnit = "master"
).create()
}
@Bean(name = [READER_ENTITY_MANAGER_FACTORY])
fun readerEntityManagerFactory(
@Qualifier(SLAVE_DATASOURCE) dataSource: DataSource
): LocalContainerEntityManagerFactoryBean {
return EntityManagerFactoryCreator(
properties = jpaProperties,
hibernateProperties = hibernateProperties,
metadataProviders = metadataProviders,
entityManagerFactoryBuilder = entityManagerFactoryBuilder,
dataSource = dataSource,
packages = PACKAGE,
persistenceUnit = "slave"
).create()
}
@Primary
@Bean(name = [MASTER_TX_MANAGER])
fun batchTransactionManager(entityManagerFactory: LocalContainerEntityManagerFactoryBean): PlatformTransactionManager {
return JpaTransactionManager(
entityManagerFactory.`object` ?: throw IllegalArgumentException("EntityManagerFactory is NULL")
)
}
}(설정에 대한 자세한 내용에 대해서는 해당 글을 참고해주시면 좋을 것 같습니다)
코드의 핵심을 간단히 요약하자면
- MASTER_ENTITY_MANAGER_FACTORY
- 디폴트로 사용되는 Master DataSource가 할당된 EntityManagerFactory
- READER_ENTITY_MANAGER_FACTORY
- 읽기전용 작업에 사용되는 읽기전용 DataSource가 할당된 EntityManagerFactory
이제 사용법에 대해서 간단히 보겠습니다.
@Configuration
class TestStep(
@Qualifier(READER_ENTITY_MANAGER_FACTORY)
private val readEmf: EntityManagerFactory
) {
fun reader() : ItemReader<TestObject> {
return QueryDSLPagingItemReader(readEmf, Chunk.SIZE_100) {
//query
}
}
}간단하죠, 사용할 EntityManagerFactory를 사용하는 ItemReader구현체에 넣어주면 됩니다.
그런데 자체 구현해서 사용하던 QueryDSLPagingItemReader에도 문제가 있었습니다.
분리된 영속성 컨텍스트 문제
사실 이 문제는 JpaPagingItemReader를 사용할때도 마찬가지인 문제입니다.
기존 QueryDSLPagingItemReader 구현체는 JpaPagingItemReader 구현을 모방해 구현돼있어서, 아래와 같은 방식으로 구현돼있었습니다.
@Override
protected void doOpen() throws Exception {
super.doOpen();
entityManager = entityManagerFactory.createEntityManager(jpaPropertyMap);
if (entityManager == null) {
throw new DataAccessResourceFailureException("Unable to obtain an EntityManager");
}
// set entityManager to queryProvider, so it participates
// in JpaPagingItemReader's managed transaction
if (queryProvider != null) {
queryProvider.setEntityManager(entityManager);
}
}
@Override
protected void doClose() throws Exception {
entityManager.close();
super.doClose();
}해당 코드는 실제 JpaPagingItemReader 구현 코드입니다. 그리고 해당 코드에는 아래와 같은 특징이 있습니다.
doOpen(): 직접 EntityManager를 생성한다.doClose(): 생성한 EntityManager를 닫는다.
이렇게 되면 뭐가 문제일까요?
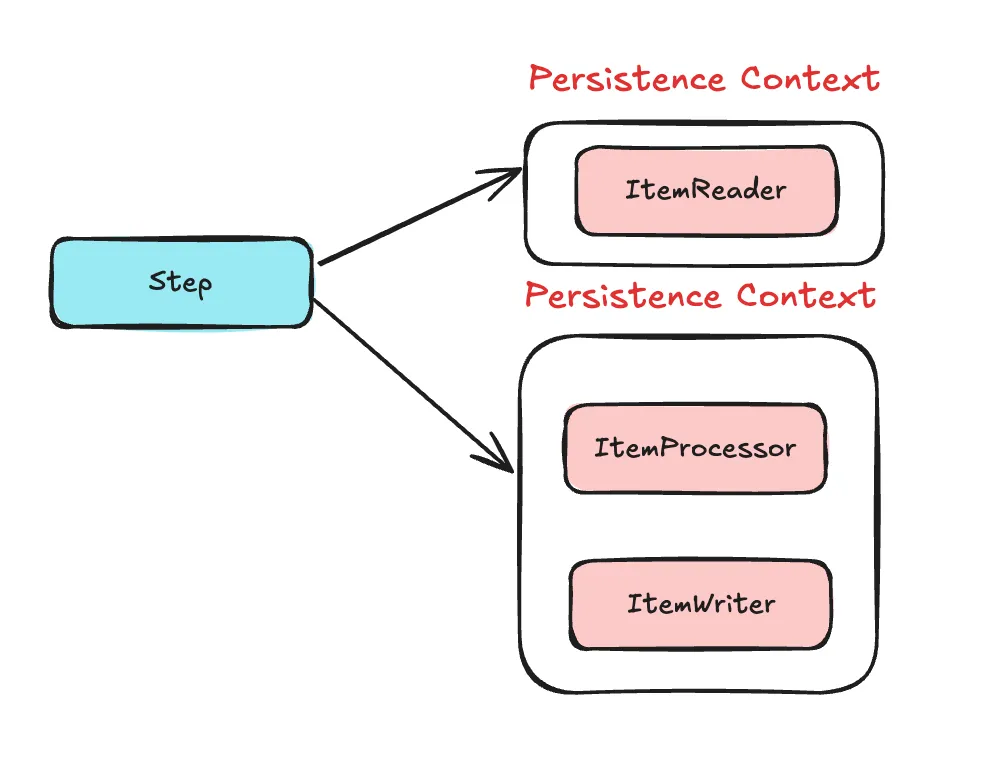
이미지에 나타냈듯이, 영속성 컨텍스트가 두개로 갈립니다.
그에 따라 영속성 컨텍스트 1차 캐시를 공유하지 못하고, 만약 ItemReader에서 읽은 데이터를 변경감지를 통해 업데이트하는 작업이 있다면 write하는 부분에서 영속성 컨텍스트에 데이터가 존재하지 않기 업데이트 건 수 하나당 하나의 추가적인 select 쿼리가 발생합니다.
사실 읽기 트랜잭션과 쓰기 트랜잭션을 분리하는 목적에는 맞는 TO-BE 모델입니다.
하지만 모든 배치 작업이 분리된 트랜잭션을 원하지 않습니다.
결국 간단하고 변경감지로 구현된 배치도 존재했기에, 아래의 두 가지 모델을 충족해줄 수 있도록 ItemReader를 재구현이 필요했습니다.

커스텀 ItemReader 재구현
ItemReader 재구현에 목표는 크게 두 가지 입니다.
Master DB를 봐야할 때는 기존 트랜잭션의 영속성 컨텍스트를 따라간다.
읽기전용 DB를 봐야할 때는 별도의 트랜잭션과 영속성 컨텍스트를 가져간다.
바로 코드를 보겠습니다.
참고로 해당 코드에는 생성과 종료에 중점을 맞춰서 나타냈기 때문에, 자세한 read 구현은 빠져있습니다 👀
class QueryDSLPagingItemReader<T>(
private val entityManagerFactory: EntityManagerFactory?,
private var entityManager: EntityManager?,
private val isReadOnly: Boolean
) : AbstractPagingItemReader<T>() {
companion object {
//master EntityManger를 사용하는 경우
fun <T> ofMaster(
entityManager: EntityManager,
pageSize: Int
): QueryDSLPagingItemReader<T> {
return QueryDSLPagingItemReader(null, entityManager, pageSize, false)
}
//Reader EntityManger를 사용하는 경우
fun <T> ofReader(
entityManagerFactory: EntityManagerFactory,
pageSize: Int
): QueryDSLPagingItemReader<T> {
return QueryDSLPagingItemReader(entityManagerFactory, null, pageSize, true)
}
}
private constructor(
entityManagerFactory: EntityManagerFactory?,
entityManager: EntityManager?,
pageSize: Int,
isReadOnly: Boolean
) : this(entityManagerFactory, entityManager, isReadOnly) {
super.setName(ClassUtils.getShortName(QueryDSLPagingItemReader::class.java))
doOpen()
setPageSize(pageSize)
}
override fun doOpen() {
super.doOpen()
if (isReadOnly) {
entityManager = entityManagerFactory?.createEntityManager()
?: throw DataAccessResourceFailureException("Unable to obtain an EntityManager")
}
}
override fun doClose() {
if (isReadOnly) {
entityManager!!.close()
}
super.doClose()
}
override fun doReadPage() {
val tx = getTxOrNull()
<do query>
if (isReadOnly) {
tx?.commit()
}
}
private fun getTxOrNull(): EntityTransaction? {
if (isReadOnly) {
val tx = entityManager!!.transaction
tx.begin()
entityManager!!.clear()
return tx
}
return null
}
}코드의 핵심을 요약해보자면 다음과 같습니다.
[핵심 메소드]
doOpen(): isReadOnly 값이 true라면 사용할 EntityManager를 동적으로 생성합니다.doClose(): isReadOnly 값이 true라면 생성한 EntityManager를 종료합니다.doReadPage(): isReadOnly 값이 true라면 읽기전용 트랜잭션을 열고, 쿼리 수행 후에 트랜잭션을 커밋합니다.
여기서 중요한 포인트가 있는데요, 바로 아래 코드입니다.
entityManager!!.clear()
해당 코드가 없으면 한 스탭동안의 데이터가 영속성 컨텍스트 1차 캐시에 계속해서 쌓이게 되고, 대용량 데이터를 다루는 작업에서는 OutOfMemory가 발생할 수 있습니다.
실제로 OutOfMemory가 발생하면 당해보니 서버가 다운되면서 에러 알림 기능도 동작을 안해서 암살을 당할 수 있으니 조심하세요 🥷
[팩토리 메소드]
ofMaster(): 실제 스프링 빈에 등록돼있는 EntityManager를 주입받고 isReadOnly 값을 false로 설정합니다.ofReader(): 동적으로 읽기전용 EntityManager를 생성하기 위해 읽기전용 DataSource가 설정된 EntityManagerFactory를 주입받고, isReadOnly를 true로 설정합니다.
사용법은 아래와 같습니다.
@Configuration
class TestStep(
//읽기전용 EntityManagerFactory
@Qualifier(READER_ENTITY_MANAGER_FACTORY)
private val readEmf: EntityManagerFactory,
//디폴트(Master) EntityManager
private val em: EntityManager
) {
/**
* 읽기 전용 ItemReader
*/
@Bean
@StepScope
fun reader(): ItemReader<TestObject> {
return QueryDSLPagingItemReader.ofReader(readEmf, Chunk.SIZE_100)
}
/**
* Master DB를 바라보는 ItemReader
*/
fun reader(): ItemReader<TestObject> {
return QueryDSLPagingItemReader.ofMaster(em, Chunk.SIZE_100)
}
}이제 적용만 남았습니다.
적용 시 주의할 점은 적용할 배치의 동작이 읽기 트랜잭션을 분리해도 되는지 안되는지만 잘 확인해주시면 됩니다 👀
적용 결과
이제 적용 결과를 보겠습니다 👀
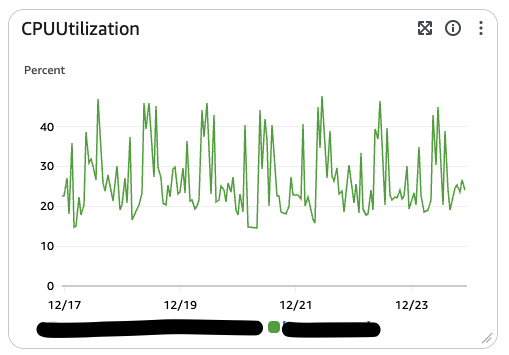
해당 옵션을 정확히 12/3 기점으로 추가했는데요,
피크타임 CPU 사용률이 약 70%정도에서 약 45%정도로 감소한걸 볼 수 있습니다! 👏
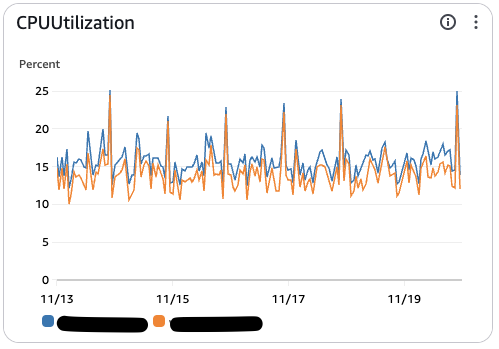
읽기전용 서버랑 함께 비교해서 보시죠
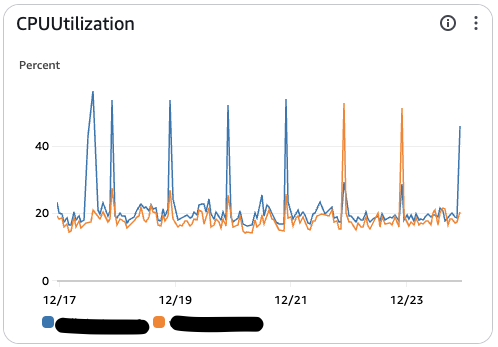
결과적으로 기존의 Master DB의 부하가 읽기서버와 분산되는 것을 볼 수 있고, 피크타임 CPU 사용률 약 25% 감소에 성공했습니다.
반대로 Reader DB의 CPU 사용률은 약 25% 끌어올리면서 제값을 하게 되었습니다.
긴 글 읽어주셔서 감사합니다 🙇♂️
